Python学习之字符串常用方法
目录
1、join()函数拼接:sep.join(iterable)
2、大小写的转换:
(1)方法upper():将小写字母化为大写字母。
(2)方法lower():将大写字母化为小写字母。
(3)方法title():所有单词的首字母是大写,其余均为小写
(4)方法capitalize():将字符串的第一个字符转换为大写。
(5)方法swapcase():将字符串中大写转换成小写,小写转换成大写。
3、 常用的检索方法:
(1)方法count():统计字符串里指定子字符出现的次数。(区分大小写)
(2)方法find():查找某字符串里是否包含被查询的子字符串。
(3)方法index():查找某字符串里是否包含被查询的子字符串。
(4)方法startswith():查询字符串是否以指定子字符串开头
(5)方法endswith():查询字符串是否以指定子字符串结尾
4、字符串的分割:
(1)方法split():通过指定分割符对字符串进行切片,拆分字符串。(在没有指定分割符时默认空白字符串切片,切割后是个列表)
(2)方法splitliness():只能通过行界符对字符串进行切片,拆分字符串。(不能指定分割符对字符串进行切片,切割后是个列表)
(3)方法partition():从str出现的第一个位置起,把字符串string分成一个3元素的元组。(切割后是个元组)
5、字符串的修剪:
(1)方法strip():移除字符串头尾指定的字符(默认为空白或换行符)或字符序列。
(2)方法lstrip():移除字符串头部指定的字符(默认为空白或换行符)或字符序列。
(3)方法rstrip():移除字符串尾部指定的字符(默认为空白或换行符)或字符序列。
6、三种常见的字符串的格式化:
(1)%-formatting
(2)str.format()
(3)f-string
1、join()函数拼接:sep.join(iterable)
释:以sep作为分隔符,将iterable中所有的元素合并为一个新的字符串。
list_val = ['www','baidu','com']
str_val = '.'.join(list_val)
print(str_val)
tuple = ('User','andy','code')
str_val = '/'.join(tuple)
print(str_val)
运行结果: 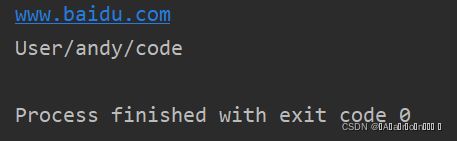
2、大小写的转换:
(1)方法upper():将小写字母化为大写字母。
(2)方法lower():将大写字母化为小写字母。
(3)方法title():所有单词的首字母是大写,其余均为小写
(4)方法capitalize():将字符串的第一个字符转换为大写。
(5)方法swapcase():将字符串中大写转换成小写,小写转换成大写。
str1 = 'I love Python'
str2 = str1.upper()
str3 = str1.lower()
str4 = str1.title()
str5 = str1.capitalize()
str6 = str1.swapcase()
print(str2,str3,str4,str5,str6,sep = '\n')运行结果: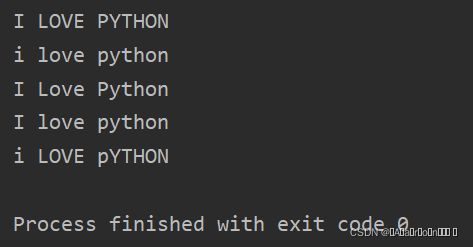
3、 常用的检索方法:
(1)方法count():统计字符串里指定子字符出现的次数。(区分大小写)
str.count(“被检索的字符串”,检索的起始位置,检索的结束位置)
注意:起始位置和结束位置可省略,默认为第一个字符到最后一个字符,第一个字符索引值为0。
str = "LoveYouPython"
print(str.count("o"))
print(str.count("O")) 运行结果: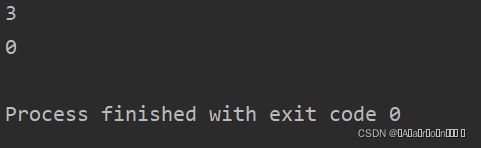
(2)方法find():查找某字符串里是否包含被查询的子字符串。
str.find(“被检索的字符串”,检索的起始位置,检索的结束位置)
注意:如果找到被查询的第一个子字符串,此方法返回该字符串的索引,否则返回-1,代表没有找到该字符串。
str = "LoveYouPython"
print(str.find("o"))
print(str.find("O")) 运行结果: 
(3)方法index():查找某字符串里是否包含被查询的子字符串。
str.index(“被检索的字符串”,检索的起始位置,检索的结束位置)
注意:如果找到被查询的第一个子字符串,此方法返回该字符串的索引,否则返回异常,代表没有找到该字符串。
str = "LoveYouPython"
print(str.index("o")) 运行结果: 
str = "LoveYouPython"
print(str.index("O"))运行结果:报错
(4)方法startswith():查询字符串是否以指定子字符串开头
str.startswith(“被检索的字符串”,检索的起始位置,检索的结束位置)
注意:如果找到了返回True,否则返回False。
str = "LoveYouPython"
print(str.startswith("L"))
print(str.startswith("o")) 运行结果: 
(5)方法endswith():查询字符串是否以指定子字符串结尾
str.endswith(“被检索的字符串”,检索的起始位置,检索的结束位置)
注意:如果找到了返回True,否则返回False。
str = "LoveYouPython"
print(str.endswith("n"))
print(str.endswith("o"))
运行结果: 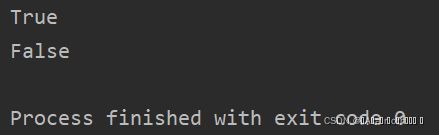
4、字符串的分割:
(1)方法split():通过指定分割符对字符串进行切片,拆分字符串。(在没有指定分割符时默认空白字符串切片,切割后是个列表)
str.split(“分割符”,分割次数)

(2)方法splitliness():只能通过行界符对字符串进行切片,拆分字符串。(不能指定分割符对字符串进行切片,切割后是个列表)

(3)方法partition():从str出现的第一个位置起,把字符串string分成一个3元素的元组。(切割后是个元组)
str.partition(string_pre_str,str,string_post_str)

str1 = "我 爱\t你\nPy\rthon"
print(str1.split())
str2 = "我老爱你了老Py老thon"
print(str2.split("老",2))
str3 = "我 爱\r你\nPy\r\nthon"
print(str3.splitlines())
str4 = "LoveYouPython"
print(str4.partition("o"))运行结果:
5、字符串的修剪:
(1)方法strip():移除字符串头尾指定的字符(默认为空白或换行符)或字符序列。
str.strip([chars]) chars:移除字符串头尾指定的字符序列
注意:该方法只能删除开头或是结尾的字符,不能删除中间部分的字符。
str = " Love Python\n\t\r "
print(str.strip()) 运行结果:
(2)方法lstrip():移除字符串头部指定的字符(默认为空白或换行符)或字符序列。
str.lstrip([chars]) chars:移除字符串头部指定的字符序列
注意:该方法只能删除开头的字符,不能删除中间和结尾部分的字符。
str = " Love Python\n\t\r "
print(str.lstrip()) 运行结果: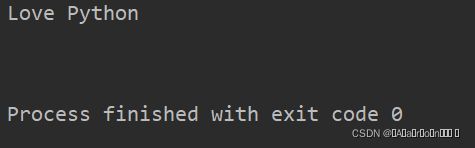
(3)方法rstrip():移除字符串尾部指定的字符(默认为空白或换行符)或字符序列。
str.rstrip([chars]) chars:移除字符串尾部指定的字符序列
注意:该方法只能删除结尾的字符,不能删除中间和开头部分的字符。
str = " Love Python\n\t\r "
print(str.rstrip())运行结果: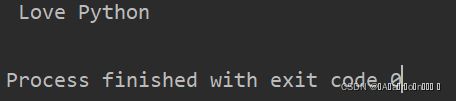
6、三种常见的字符串的格式化:
(1)%-formatting
name = 'Aaron'
login_time = 10
cost = 258.88
print('你好%s,欢迎登录!这是您登录的第%d次。您本次消费%.2f元' % (name,login_time,cost))
# 字典的情况
data = {'name':'Aaron','login_time':10,'cost':258.88}
tuple_value = (data['name'],data['login_time'],data['cost'])
print('你好%s,欢迎登录!这是您登录的第%d次。您本次消费%.2f元' % tuple_value) 运行结果: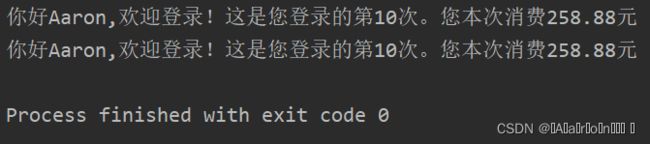
(2)str.format()
通过{}和:来代替以前的%
可以接受不限个参数,位置可以不按顺序。
name = 'Aaron'
login_time = 10
cost = 258.8890
print('你好{},欢迎登录!这是您登录的第{}次。您本次消费{:.2f}元。'.format(name,login_time,cost))
print('你好{},欢迎登录!这是您登录的第{}次。您本次消费{:.2f}元。恭喜{}成为vip。'.format(name,login_time,cost,name))
print('你好{0},欢迎登录!这是您登录的第{1}次。您本次消费{2:.2f}元。恭喜{0}成为vip。'.format(name,login_time,cost))
print('你好{name},欢迎登录!这是您登录的第{log_time}次。您本次消费{cost:.2f}元。恭喜{name}成为vip。'.format(name=name,log_time=login_time,cost=cost))
# 字典的情况
data = {'name':'Aaron','login_time':10,'cost':258.88}
print('你好{},欢迎登录!这是您登录的第{}次。您本次消费{}元'.format(data['name'],data['login_time'],data['cost']))运行结果: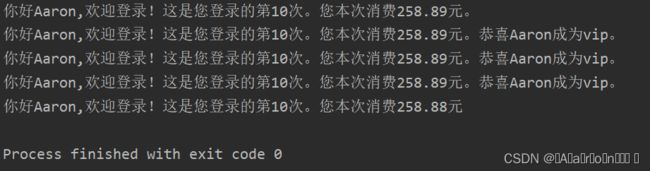
(3)f-string
f或F修饰符引领的字符串(f’xxx’或F’xxx’)
以大括号{}标明被替换的字段
name = 'Aaron'
login_time = 10
cost = 258.8890
print(f'你好{name},欢迎登录!这是您登录的第{login_time}次。您本次消费{cost:.2f}元。')
print(f'你好{name},欢迎登录!这是您登录的第{login_time}次。您本次消费{cost:.2f}元。恭喜{name}成为vip。')
# 字典的情况
data = {'name':'Aaron','login_time':10,'cost':258.88}
print(f'你好{name},欢迎登录!这是您登录的第{login_time}次。您本次消费{cost:.2f}元。恭喜{name}成为vip。')运行结果: