字符串算法(Python Code)
字符串算法
-
- 1.判断字符串有无重复字符
- 2. 反转字符串
- 3. 替换字符串中的空格
- 4. 压缩字符串
- 5. 判断两字符串的字符集是否相同
- 6. 旋转词
- 7. 将字符串中按单词翻转
- 8. 去掉字符串中连接出现的k次的0
- 9. 神奇的回文数
- 10. 字符串匹配之RabinKarp
- 11. 字符串匹配之KMP
1.判断字符串有无重复字符
str = 'good'
print(len(str))
def compare():
for i in range(len(str)):
for j in range(i):
if (str[j] == str[i]):
return True
return False
print(compare())
#输出结果
True
2. 反转字符串
法一:
使用逆向切片 [::-1]
法二:
此Python代码段使用两个内置函数reserved()和join()来反转字符串。
string = "abcdefghijk"
print("".join(reversed(string)))
#reversed 的作用是返回一个 逆序序列 的迭代器
#join 在此处的作用是 将迭代器 转化为 字符串
#输出 kjihgfedcba
法三:
最笨的办法。python 循环
def reverse_a_string(string):
a_list = [] # a new list
index = len(string) # total length of a string, last index
while index: # loop from the last index to the beginning index
index -= 1 # index = index - 1 , reverse one by one
a_list.append(string[index]) # append to the list
return "".join(a_list) # join everything.
result = reverse_a_string("abcdefghijk")
print(result) # kjihgfedcba
3. 替换字符串中的空格
replace(‘a’,‘b’) 把a 替换成 b
4. 压缩字符串
题目描述:
字符串压缩。利用字符重复出现的次数,编写一种方法,实现基本的字符串压缩功能。比如,字符串aabcccccaaa会变为a2b1c5a3。
def comparessString(s):
if len(s) == 0:
return s
count = 1
tmp = s[0]
res = ""
for i in range(1, len(s)):
if s[i] == tmp:
count += 1
if s[i] != tmp:
res = res + str(tmp) + str(count)
count = 1
tmp = s[i]
res = res + str(tmp) + str(count)
if len(res) < len(s):
return res
else:
return s
s = 'aabbccddd'
print(comparessString(s))
#输出结果 a2b2c2d3
#输入案例 s = 'asdddsdadsadas'
#输出结果 asdddsdadsadas
5. 判断两字符串的字符集是否相同
def compare(str1,str2):
helper=[0]*256 # 建立一个辅助列表 初始值都为0 因为ASCII的值为 0-256 所以就列表长度为 257
for i in range(len(str1)):
helper[ord(str1[i])] = 1 #遍历 str1 将字母转化为ASCII (helper[ASCII]) 并将 该位置赋值为1
for j in range(len(str2)): #遍历 str2 同样的操作 判断 helper[ASCII] 位置是否为 0 0说明 str2 中出现了与 str1 不同的字符集 返回 False 否则 返回True
if(helper[ord(str2[j])] == 0):
return False
return True
str1='aabbcdA'
str2='Aabbcd'
print(compare(str1,str2))
#运行结果
True
6. 旋转词
题目描述:
如果将一个 str1 从任意的位置切分开,分成两部分,将后面一部分放置在前面, 再组合起来成为 str2,构成了旋转词。
例如:str1 = “apple”,str2 = “leapp”,两个词就是旋转词。
代码实现:
def is_rotation(str1, str2):
if str1 == "" or str2 == "" or len(str1) != len(str2):
return False
str_double = str1 + str1
if str2 in str_double:
return True
else:
return False
7. 将字符串中按单词翻转
def string_reverse(s):
list= s.split() # python 中字符串无法修改,要转为list
return ' '.join(list[::-1])# 将反转后的列表转为 str
s = 'I love Python!'
print('逐字符翻转', s[::-1])
print('逐单词翻转', string_reverse(s))
8. 去掉字符串中连接出现的k次的0
在python 的字符串中
可以调用 find() 函数来匹配 需要寻找的字符串
find() 可以返回 所匹配的字符串 第一次出现的位置
str = 'abcdefabcd'
print(str.find('abcd')
#输出结果为 0 若没有找到则输出为 -1
a = 'A0000A00' k = int(input()) print(a.find('0'*k)) print(a.replace('0'*k,'123'))
9. 神奇的回文数
1.整数转字符串,通过下标对比确定该整数是否为回文数
str_x = str(x)
for i in range(0,int(len(str_x)/2)):
if str_x[i] != str_x[-i-1]:
return False
return True
2.字符串翻转
str_x = str(x)
return str_x == str_x[::-1]
3.数学计算的方法
if x<0:
return False
temp_x = x;
palindromeNum = 0
while temp_x != 0:
palindromeNum = palindromeNum*10 + temp_x%10
temp_x /= 10
return palindromeNum == x
10. 字符串匹配之RabinKarp
def search(a, b):
"""
判断a是不是b的子串
>>>search( "AABA", "ACAADAABAAAAABABAA")
>>>True
"""
hashA, hashB = 0, 0
# 将字母转化为 26进制编码 hash函数:
aN = [ord(c)-ord('A')+1 for c in a] # ord 函数将 字母转化为对应的 ASCII 值
bN = [ord(c)-ord('A')+1 for c in b]
m, n = len(aN), len(bN)
for i in range(m): #计算字串对应的 hash 值
hashA = 26*hashA + aN[i]
hashB = 26*hashB + bN[i]
for j in range(m-1, n):
if j > m-1:
hashB -= bN[j-m]*(26**(m-1))
hashB = hashB*26 + bN[j] # 减去bN[j-m]的贡献(也就是hashB的首位),对剩下的值乘以26,最后再加上bN[j](也就是新算进去的hashB的末位)的贡献
if hashB == hashA: #hash值 相等 再比较字符串是否相等。
if a == b[j-m+1:j+1]:
return True
return False
search( "AABA", "ACAADAABAAAAABABAA")
11. 字符串匹配之KMP
建议学习其他大佬的讲解:
KMP算法-python
第一步先构造 pnext 临时数组:
构造方法如下:
假定给出的字符串为 abcabgac

然后 判断 数组此时 j 和 i 的值是否相等 如果相等 pnext = pnext[j] + 1 然后 j++ ,i++
如果 j 和 i 的值不相等时候,如果j =0 pnext [i] =0
如果j!=0 j = pnext[j-1] 然后回到最初的步骤。
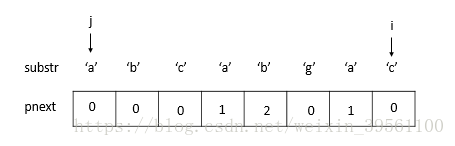
临时数组的 目的 是为了找到 即是前缀也是后缀的子串。临时数组构造好 之后就可继续执行的我们的KMP算法
第二步:
进行 str 与substr 的对比 令i指向str的第一个字符,j指向substr第一个字符。
如果 i = j i++ j++
如果不等 j !=0 j=pnext[j-1] i 不变 然后进行 最初步骤
j = 0 i++ 然后进行 最初步骤
这一过程存在两种方法中止,即i或者j不能再加1(加1就会发生越界的时候)。假设str的长度为n,substr的长度为m。当j==m时,说明找到了子串,否则没有找到。
def KMP_algorithm(string, substring):
'''
KMP字符串匹配的主函数
若存在字串返回字串在字符串中开始的位置下标,或者返回-1
'''
pnext = gen_pnext(substring)
n = len(string)
m = len(substring)
i, j = 0, 0
while (i<n) and (j<m):
if (string[i]==substring[j]):
i += 1
j += 1
elif (j!=0):
j = pnext[j-1]
else:
i += 1
if (j == m):
return i-j
else:
return -1
def gen_pnext(substring):
"""
构造临时数组pnext
"""
index, m = 0, len(substring)
pnext = [0]*m
i = 1
while i < m:
if (substring[i] == substring[index]):
pnext[i] = index + 1
index += 1
i += 1
elif (index!=0):
index = pnext[index-1]
else:
pnext[i] = 0
i += 1
return pnext
if __name__ == "__main__":
string = 'abcxabcdabcdabcy'
substring = 'abcdabcy'
out = KMP_algorithm(string, substring)
print(out)
借鉴其他大佬的博客:https://blog.csdn.net/weixin_39561100/article/details/80822208?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164302006416780366589944%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=164302006416780366589944&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduend~default-2-80822208.pc_search_insert_ulrmf&utm_term=KMP%E7%AE%97%E6%B3%95+python&spm=1018.2226.3001.4187
如有侵权,请告知删除。