参数检验和非参数检验(结合SPSS分析)
文章目录
- 假设检验
-
- 参数检验
-
- 平均值检验
- 单样本t检验
- 两独立样本t检验
- 配对样本t检验
- 非参数检验
-
- 卡方检验
- 单样本K-S检验
- 两独立样本的非参数检验
- 多个独立样本的非参数检验
- 两配对样本检验
- 多匹配样本的非参数检验
假设检验
概念:是一种根据样本数据来推断总体的分布或均值、方差等总体统计参数的方法。
根据样本来推断总体的原因:
-
总体数据不可能全部收集到。如:质量检测问题
-
收集到总体全部数据要耗费大量的人力和财力
假设检验包括:
-
参数检验
-
非参数检验
基本原理:利用小概率原理进行反证明。小概率事件在一次实验中不可能发生。
基本步骤:
-
根据检验的目标,对有待推断的总体参数或分布作一个零假设 H 0 H_0 H0
-
构造检验统计量,且该统计量服从某种已知分布.(卡方分布、t分布、F分布)
-
利用收集到的样本数据和基本假设计算检验统计量的值,并得到相应的相伴概率P值,即:检验统计量在某个特定的极端区域取值在 H 0 H_0 H0成立时的概率.
-
给定显著性水平,如果概率P值小于用户给定的显著性水平 α \alpha α(一般取0.05或0.01),则拒绝零假设 H 0 H_0 H0而接受备择假设 。否则,不拒绝零假设 H 0 H_0 H0 (类似一种反证法)。显著性水平指的是零假设正确却被错误拒绝的概率,一般取0.01或0.05,即零假设正确且正确接受的概率为99%或95%
参数检验
参数检验方法
- 平均值检验
- 单样本t检验
- 两独立样本t检验
- 两配对样本t检验
平均值检验
计算一个或多个自变量类别中因变量的子组平均值与相关的单变量统计,也可以通过比较两个样本的均值来判断两个总体的均值是否相等。零假设:两个样本的均值,没有显著差异。
实例
问题:判断男女生数学成绩的均值是否具有显著差异
操作:
点击>分析>比较平均值>平均值

将性别拖到自变量列表,数学成绩拖到因变量列表。
点击选项按钮,勾选Anova表和eta、线性相关度检验
(如果自变量的个数少于3或者含有字符串,则无法进行线性相关度检验,因此此选项也可不必勾选)
分析结果:
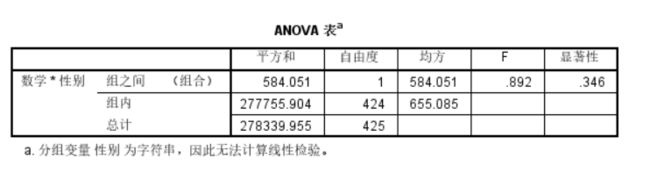
从ANOVA表中可以看出,显著性为0.36,大于0.05,说明男生和女生之间的数学成绩均值没有显著差异。
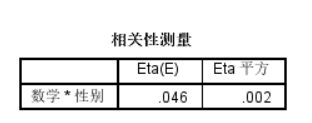
从相关性测量表中看出Eta的平方为0.02
单样本t检验
H 0 H_0 H0: u = u 0 u=u_0 u=u0,总体均值与检验值之间不存在显著差异.
构造检验统计量.从样本均值的分布出发,即:~ N ( u 0 , σ 2 / n ) N(u_0,\sigma^2/n) N(u0,σ2/n).于是:
-
总体方差未知时构造t统计量 t = D ‾ S / n t=\frac{\overline D}{S/\sqrt{n}} t=S/nD
-
D = X − u 0 D=X- u_0 D=X−u0
-
t统计量服从n-1个自由度的t分布
计算t统计量和对应的相伴概率P(绝对值大于等于 α \alpha α的双侧概率)
结论: P ≤ α P\leq\alpha P≤α,则拒绝 H 0 H_0 H0,认为总体均值与检验值之间有显著差异. P > α P>\alpha P>α,不能拒绝 H 0 H_0 H0,认为总体均值与检验值之间没有显著差异
两独立样本t检验
含义: 在两个样本相互独立的前提下,检验两个样本的总体均值是否存在显著差异。零假设:两个样本数据的均值不存在显著差异。
例如:男生和女生的计算机平均成绩有显著差异吗?
要求:
-
两样本必须相互独立,即:抽取其中一批样本对抽取另一批样本没有任何影响.(如:北京周岁儿童与上海儿童的平均身高)
-
两总体服从正态分布
基本思路:
-
零假设 H 0 : u 1 − u 2 = 0 H_0:u_1-u_2=0 H0:u1−u2=0,两总体均值无显著差异。
-
构造检验统计量.从两样本均值差的分布出发,即:~ N ( u 1 − u 2 , σ x 1 − x 2 2 ) . N(u_1-u_2,\sigma^2_{x_1-x_2} ). N(u1−u2,σx1−x22).于是两总体均方差未知时构造t统计量:
-
两总体均值差的抽样分布标准差:
- 方差相等:用合并方差
- 方差不等:
- 计算t统计量和对应的相伴概率P (绝对值大于等于该值的双侧概率)
利用方差齐性(Levene)F检验确定两总体方差是否齐性。给定零假设 H 0 H_0 H0:两总体方差无显著差异。
首先计算每个个案与所属组均值之差并取绝对值.然后对其进行单因素方差分析.
如果已假设方差齐性行 F检验的 P ≤ α P\leq\alpha P≤α,则拒绝F检验的 H 0 H_0 H0,认为方差不齐性;其次看未假设方差齐性(Unequal)行的t检验概率.如果 ≤ α \leq\alpha ≤α,则拒绝t检验的 H 0 H_0 H0,认为两总体均值有显著差异;如果 > α >\alpha >α,则不拒绝t检验的 H 0 H_0 H0
如果F检验的 P > α P >\alpha P>α,则不能拒绝F检验的 H 0 H_0 H0,认为方差齐性;其次看已假设方差齐性(equal)行的t检验概率,t检验概率如果 ≤ α \leq\alpha ≤α,则拒绝t检验的 H 0 H_0 H0,认为两总体均值有显著差异;如果 > α >\alpha >α,则不拒绝t检验的 H 0 H_0 H0
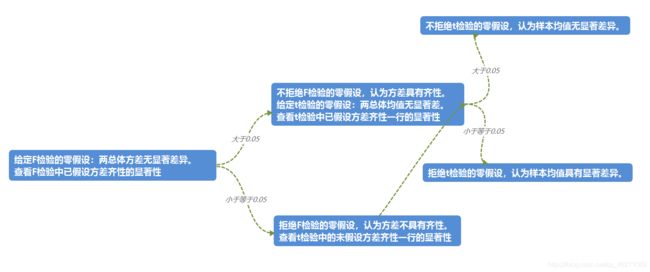
实例:
问题:判断男女生数学成绩是否具有显著差异
SPSS操作:
点击>分析>比较平均值>独立样本T检验
点击>定义组
分析结果:

在“列表方差相等性检验”框中,显著性为0.256,大于0.05,两组的总体方差齐性,则选择“已假设方差齐性”这一行的t检验结果。在“平均值相等性的t检验”中显著性(双尾)为0.346,大于0.05,说明两组数据的均值不存在显著差异。
配对样本t检验
含义: 根据配对样本对两总体均值是否有显著差异进行推断。零假设:两个配对样本数据的均值不存在显著差异。
例如: 某种减肥茶是否有效
要求:
-
两样本数据必须两两配对,即:样本个数相同,个案顺序相同.如:减肥茶的效果、不同广告形式对销售额的影响.(控制了个案自身的影响)
-
两总体服从正态分布
非参数检验
卡方检验
目的:通过样本数据的分布来检验总体分布与期望分布或某一理论是否一致,零假设是样本的总体与期望没有显著差异。
基本思想:如果从一个随机变量X中随机抽取若干个样本均值,当这些样本落在 X X X的 k k k个互不相关的子集中的观察频数服从一个多项分布,当k趋于无穷时,这个多项分布服从卡方分布。
卡方检验的零假设是:两个变量之间没有显著差异。若两种检验(皮尔逊卡方、似然比)的渐进显著性水平(双向)都小于0.05,则拒绝零假设,若两种检验的双向显著性水平都大于0.05,则不能拒绝零假设。
即:若卡方的渐进显著性小于0.05,表明变量之间有显著差异,若卡方的渐进显著性大于0.05,表明变量之间没有显著差异。
基本方法:
-
根据已知总体的构成比计算出样本中各类别的期望频数,计算实际观察频数与期望频数的差距,即:计算卡方值 χ 2 = ∑ i = 1 k ( 观测频数 − 预测频数 ) 2 预测频数 \chi^2=\sum_{i=1}^{k}\frac{(\text{观测频数}-\text{预测频数})^2}{\text{预测频数}} χ2=∑i=1k预测频数(观测频数−预测频数)2
-
卡方值越小,则实际频数和期望频数相差越小.如果P大于显著性水平 α \alpha α,不能拒绝 H 0 H_0 H0,认为总体分布与已知分布无显著差异。
单样本K-S检验
**目的:**利用样本数据推断总体是否服从某个理论分布(正态分布、均匀分布、指数分布和泊松分布)。
例如:周岁儿童的身高是否服从正态分布
基本假设: H 0 H_0 H0:总体分布与指定的理论分布无显著差异(总体服从指定的分布)
基本方法:
-
根据用户指定检验的总体分布,构造出一理论的频数分布,并计算相应的累计频率.
-
与样本在相同点的累计频率进行比较.如果相差较小,则认为样本所代表的总体符合指定的总体分布.
实例:
问题:判断班里语文成绩是否服从正态分布或泊松分布
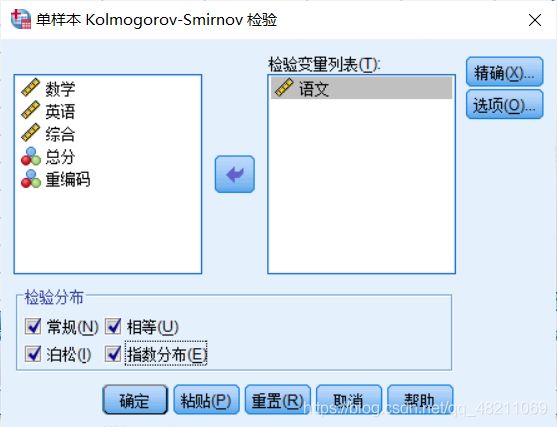
SPSS操作:
点击>分析>非参数检验>旧对话框>1-样本K-S检验
勾选常规、泊松按钮
(如下图所示:常规是指正态分布,相等是指均匀分布)
分析结果:
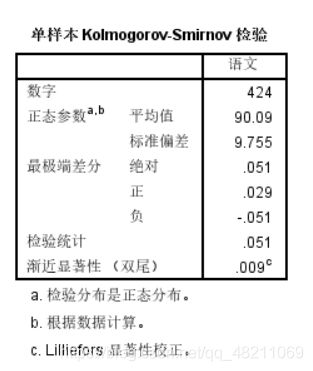
正态分布检验统计量为0.051,渐进显著性为0.009,小于0.05,拒绝零假设,认为班上语文成绩不服从正态分布。
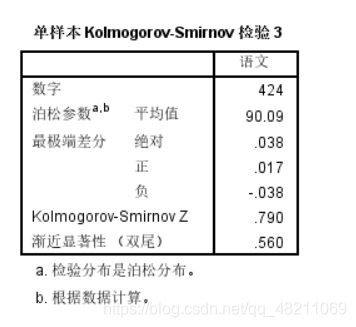
泊松分布检验统计量为0.038,渐进显著性为0.560,大于0.05,不能拒绝零假设,认为班上以为成绩服从泊松分布。
两独立样本的非参数检验
目的:由独立样本数据推断两总体的分布是否存在显著差异(或两样本是否来自同一总体)。
例如:两种不同生产工艺产品使用寿命分布的差异性
基本假设: H 0 H_0 H0:两总体分布无显著差异(两样本来自同一总体)
基本方法:
- 曼-惠特尼U检验(Mann-Whitney U):平均秩检验
-
将两样本数据混合并按升序排序
-
求出其秩
-
对两样本的秩分别求平均
-
如果两样本的平均秩大致相同,则认为两总体分布无显著差异
- k-s检验(保证有较大的样本数)
-
将两样本混合并按升序排序
-
分别计算两个样本在相同点上的累计频数和累计频率
-
两个累计频率相减
-
如果差距较小,则认为两总体分布无显著差异
- 游程检验(Wald-Wolfowitz runs)
-
将两样本混合并按升序排序
-
计算分组标志序列的游程数
-
如果游程数较大,则说明是由于两类样本数据充分混合的结果,即:认为两总体分布无显著差异.
-
如果两样本中有相同的样本值,则会使游程数发生变化.系统会作出提示.
多个独立样本的非参数检验
目的:检验多个独立样本之间是否具有相同分布,零假设是多个独立样本来自的总体分布无显著差异
基本方法:
- Kruskal-Wallis H检验(推广的平均秩检验)
-
将多个样本数混合并按升序排序,求出其秩
-
对多个样本的秩分别求平均秩序
-
如果各样本的平均秩大致相等,渐进显著性大于0.05,则认为多个总体分布无显著差异
- 相同中位数检验(median)
-
判断多个总体是否是具有相同的中位数
-
将多个样本数混合并按升序排序
-
求出混合样本序列的中位数
-
如果各独立样本中大于此中位数的个案数和小于此中位数的个案数大致相同,渐进显著性大于0.05,则认为总体有相同的中位数。
- Jonckheere-Terpstra检验(适用于行和列皆有序的R*C列联表)
- 计算统计量的值J
- 跟读统计量J值得到p值
- 将p值与给定的显著性水平进行比较。若p值小于显著性水平,则拒绝零假设,接受备择假设。
两配对样本检验
基本方法:
- 变化显著性检验(McNemar)(要求数据只能是二分值)
-
将研究对象作为自身的对照者检验其“前后”的变化是否显著
- 例如:领导培训前后,群众对他们的评价
-
关心的是发生变化的两格中的频数变化.如果频数变化相当,则认为无显著变化.
- 正负符号检验(sign)
-
将样本2的各样本值减去样本1的各样本值.如果差值为正,则记为正号;如果差值为负,则记为负号
-
如果正号的个数与负号的个数相当,则认为无显著变化.否则,认为有显著变化
-
例如:采用新训练方法前后的最好成绩比较
3.符号平均秩检验(wilcoxon)
正负符号检验只考虑了两总体数据变化的性质,而没有注意其变化的程度.符号平均秩检验注意到了这点
-
将样本2的各样本值减去样本1的各样本值.如果差值为正,则记为正号;如果差值为负,则记为负号.
-
将差值按升序排序,并求其秩.分别计算正号秩和负号秩总和
-
如果正秩和负秩相当,认为正负变化程度相当,两总体无显著差异.
多匹配样本的非参数检验
基本方法
- 推广的平均秩检验(双向Friedman检验)
-
将每个个案的变量值数据按升序排序,并求其秩
-
求各样本的平均秩
-
如果平均秩相当,则认为各总体分布无显著差异
2.谐同系数检验(Kendall W检验)
-
谐同系数检验方法与推广的平均秩检验方法相同
-
主要用在分析评判者的评判标准是否一致和公平
-
通过谐同系数W进行判定.W表示了横向各样本数据之间相关的强弱程度,取值在0和1之间.越接近1,则表示相关性越强,即:评判者的评判标准一致
参考书目:
《SPSS22.0统计分析·从入门到精通》