redis 10.主从复制(主从复制原理、一主两从、去中心化,主节点shutdown从节点上位)
文章目录
-
- 1. 主从复制概念
- 2. 一主两从
- 3. 一主二从 shutdown
-
- 3.1 一主二从,从节点shutdown
- 3.2 一主二从,主节点shutdown
- 4. 主从复制原理
- 5. 去中心化,slave作为下一个slave的master
- 6. 反客为主
- 7. 复制延时
1. 主从复制概念
主节点数据更新后,根据配置和策略, 自动同步到从节点的master/slaver机制,Master以写为主,Slave以读为主

2. 一主两从
前提:
拷贝并重命名多个redis.conf文件供redis-server启动,include参数配置 公有的redis.conf((写绝对路径))
设置Pid文件名字 pidfile
指定端口port
修改Log文件名字
修改dump.rdb名字dbfilename
开启daemonize yes
Appendonly 关掉或者改名字
(1) 新建redis6379.conf
include /myredis/redis.conf
pidfile /var/run/redis_6379.pid
port 6379
dbfilename dump6379.rdb
logfile "/myredis/redis6379.log"

(2) 新建redis6380.conf
include /myredis/redis.conf
pidfile /var/run/redis_6380.pid
port 6380
dbfilename dump6380.rdb
masterauth 123456
logfile "/myredis/redis6380.log"
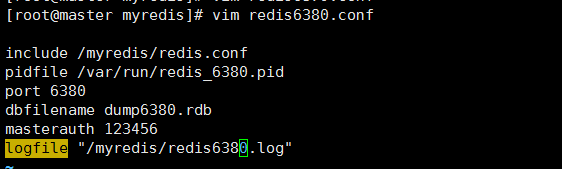
(3) 新建redis6381.conf
include /myredis/redis.conf
pidfile /var/run/redis_6381.pid
port 6381
dbfilename dump6381.rdb
masterauth 123456
logfile "/myredis/redis6381.log"

启动三台redis服务器,查看进程
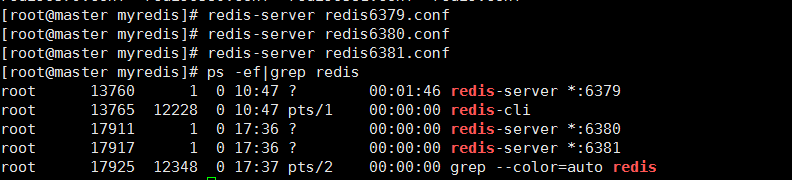
查看三台主机运行情况
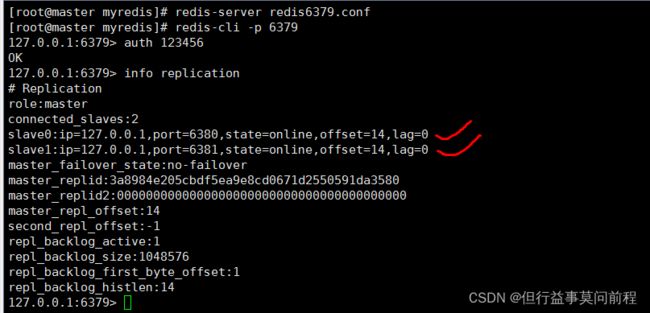
info replication
打印主从复制的相关信息
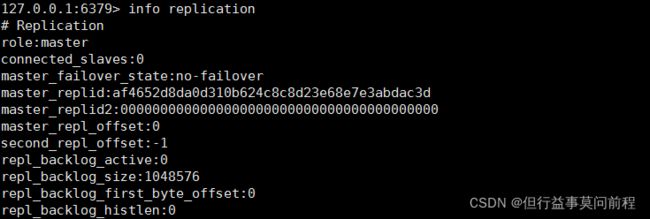
配从(库)不配主(库)
slaveof <ip><port>
成为某个实例的从服务器
1、在6380和6381上执行: slaveof 127.0.0.1 6379
![]()
![]()
6379端口代表的redis称为主节点
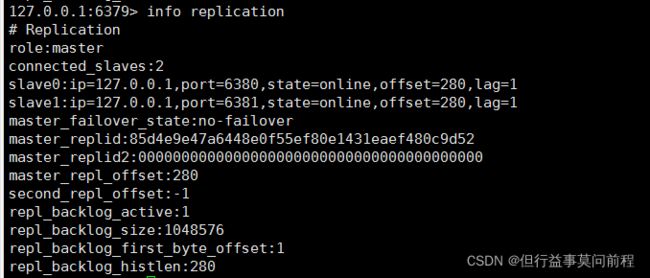
2、在主机上写,在从机上可以读取数据
![]()
![]()
![]()
在从机上写数据报错
![]()
3、主机挂掉,重启就行,一切如初
4、从机重启需重设:slaveof 127.0.0.1 6379
可以将配置增加到文件中。永久生效。
3. 一主二从 shutdown
3.1 一主二从,从节点shutdown
2个从节点原有的数据
![]()
一个从节点shutdown,之后在主节点修改数据

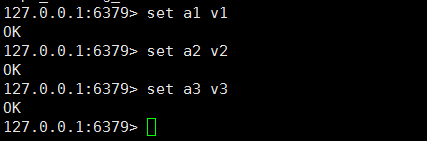
重新启动shutdown的从节点
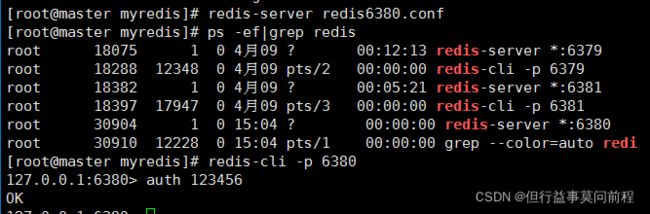
shutdown后重新启动的从节点变为了独立的主节点

重新添加到主从集群中

重新添加到集群中后,发现从节点数据完全从主节点复制过来了

总结:
从节点shutdown后,重启不会重新加入到集群中,需要执行slaveof命令,且数据会完全从主节点复制
3.2 一主二从,主节点shutdown
主节点shutdown
![]()
2个从节点,获悉到主节点状态为down,但不会上位
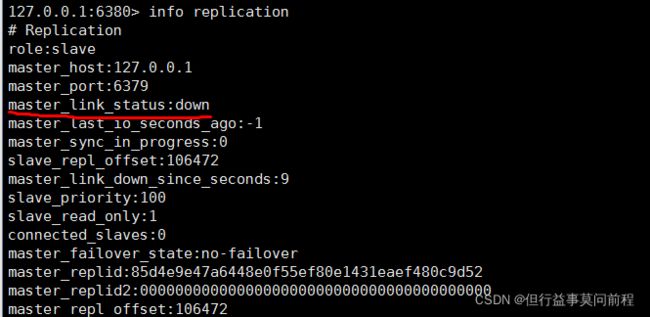
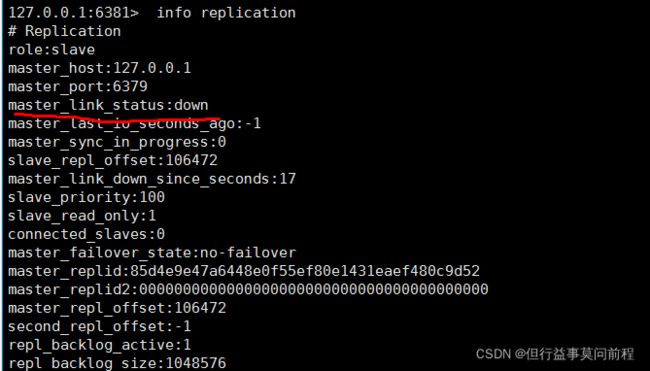
主节点重新上线,任然为集群中的主节点
4. 主从复制原理
Slave启动成功连接到master后会发送一个sync命令
Master接到命令启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令, 在后台进程执行完毕之后,master将传送rdb文件到slave,以完成一次完全同步
全量复制:master 开启一个后台保存进程,以便于生产一个 RDB 文件。同时它开始缓冲所有从客户端接收到的新的写入命令。当后台保存完成时, master 将数据集文件传输给 slave, slave将之保存在磁盘上,然后加载文件到内存。再然后 master 会发送所有缓冲的命令发给 slave。这个过程以指令流的形式完成并且和 Redis 协议本身的格式相同。
增量复制:当一个 master 实例和一个 slave 实例连接正常时, master 会发送一连串的命令流来保持对 slave 的更新,以便于将自身数据集的改变复制给 slave :包括客户端的写入、key 的过期或被逐出等等。
当 master 和 slave 之间的连接断开之后,因为网络问题或者是主从意识到连接超时, slave 重新连接上 master 并会尝试进行部分重同步:这意味着它会尝试只获取在断开连接期间内丢失的命令流。当无法进行部分重同步时, slave 会请求进行复制。这会涉及到一个更复杂的过程,例如 master 需要创建所有数据的快照,将之发送给 slave ,之后在数据集更改时持续发送命令流到 slave 。

每一个 Redis master 都有一个 replication ID :这是一个较大的伪随机字符串,标记了一个给定的数据集。每个 master 也持有一个偏移量,master 将自己产生的复制流发送给 slave 时,发送多少个字节的数据,自身的偏移量就会增加多少,目的是当有新的操作修改自己的数据集时,它可以以此更新 slave 的状态。复制偏移量即使在没有一个 slave 连接到 master 时,也会自增,所以基本上每一对给定的 Replication ID, offset 都会标识一个 master 数据集的确切版本。
当 slave 连接到 master 时,它们使用 PSYNC 命令来发送它们记录的旧的 master replication ID 和它们至今为止处理的偏移量。通过这种方式, master 能够仅发送 slave 所需的增量部分。但是如果 master 的缓冲区中没有足够的命令积压缓冲记录,或者如果 slave 引用了不再知道的历史记录(replication ID),则会转而进行一个全量重同步:在这种情况下, slave 会得到一个完整的数据集副本,从头开始。
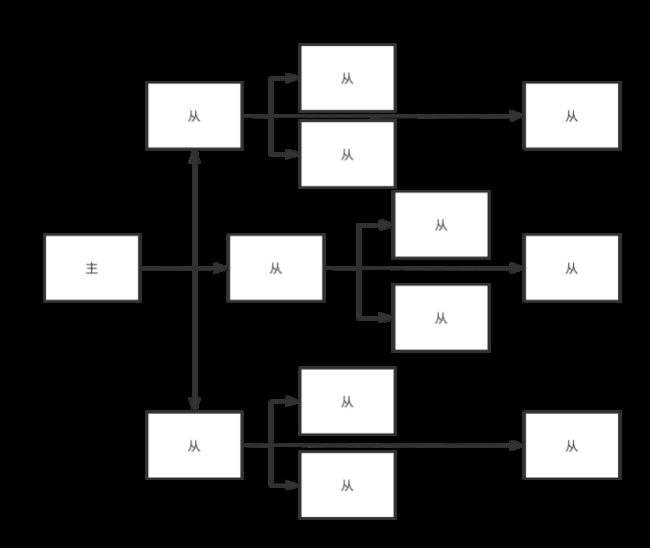
5. 去中心化,slave作为下一个slave的master
上一个Slave可以是下一个slave的Master,Slave同样可以接收其他 slaves的连接和同步请求,那么该slave作为了链条中下一个的master, 可以有效减轻master的写压力,去中心化降低风险。
用
slaveof <ip><port>
中途变更转向:会清除之前的数据,重新建立拷贝最新的
风险是一旦某个slave宕机,后面的slave都没法备份;
主机挂了,从机还是从机,无法写数据
如:
修改从节点,为slave的从节点,6381的主节点为6380
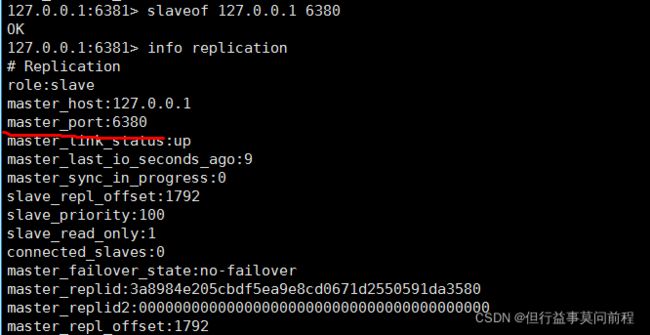
主节点6379下仅剩下一个slave

6. 反客为主
当一个master宕机后,后面的slave可以立刻升为master,其后面的slave不用做任何修改。
slaveof no one
将从机变为主机
如:
6379下线
![]()

6380从节点变为主节点

7. 复制延时
由于所有的写操作都是先在Master上操作,然后同步更新到Slave上,所以从Master同步到Slave机器有一定的延迟,当系统很繁忙的时候,延迟问题会更加严重,Slave机器数量的增加也会使这个问题更加严重