Python爬虫—scrapy框架配置及实用案例
1、搭建scrapy爬虫框架
- 下载 Twisted
pip install Twisted -i https://pypi.douban.com/simple
- 下载 pywin32
pip install pywin32 -i https://pypi.douban.com/simple
- 下载 scrapy
pip install scrapy -i https://pypi.douban.com/simple
2、创建爬虫项目
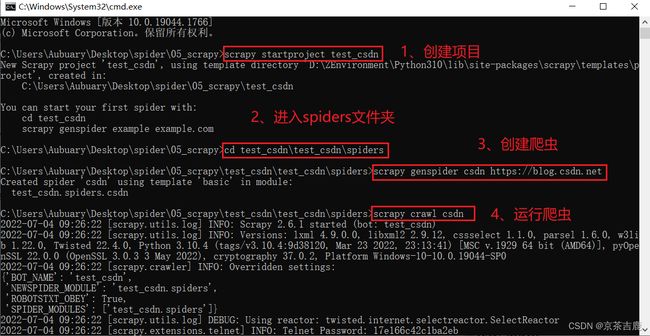
- scrapy startproject 项目名称
- cd 项目名称\项目名称\spiders
- scrapy genspider 爬虫名 爬取的网址
- scrapy crawl 爬虫名
示例:
3、项目结构和基本方法
scrapy项目结构

response的属性和方法
- response.text 获取响应的字符串数据
- response.body 获取响应的二进制数据
- response.xpath 直接使用xpath方法解析response中的内容
- response.extract() 提取selector对象的属性值
- response.extract_first() 提取selector列表的第一个数据
4、应用实例
4.1、爬取当当网书籍信息
说明:
(1)、yield
(2)、管道封装
(3)、多条管道下载
(4)、多页数据下载
定义数据结构 items.py
import scrapy
class ScrapyDangdangItem(scrapy.Item):
# 要下载的数据
src = scrapy.Field()
name = scrapy.Field()
price = scrapy.Field()
定义爬虫文件 dangdang.py
import scrapy
from scrapy_dangdang.items import ScrapyDangdangItem
class DangdangSpider(scrapy.Spider):
name = 'dangdang'
# 如果是多页下载 那么需要调整的是allowed_domains的范围 一般情况下只写域名
allowed_domains = ['category.dangdang.com']
start_urls = ['http://category.dangdang.com/cp01.01.02.00.00.00.html']
base_url = 'http://category.dangdang.com/pg'
page = 1
def parse(self, response):
li_list= response.xpath('//div/ul[@class="bigimg"]//li')
for li in li_list:
src = li.xpath('.//img/@data-original').extract_first()
if src:
src = src
else:
src = li.xpath('.//img/@src').extract_first()
name = li.xpath('.//img/@alt').extract_first()
price = li.xpath('.//p[3]//span[1]/text()').extract_first()
book = ScrapyDangdangItem(src=src,name=name,price=price)
# 获取一个book 就将book交给 pipelines
yield book
if self.page < 100:
self.page += 1
url = self.base_url + str(self.page) +'-cp01.01.02.00.00.00.html'
# url -> 请求地址 callback -> 要执行的函数
yield scrapy.Request(url=url,callback=self.parse)
开启管道 settings.py
# 65 行左右
ITEM_PIPELINES = {
'scrapy_dangdang.pipelines.ScrapyDangdangPipeline': 300,
'scrapy_dangdang.pipelines.ScrapyDangdangImgPipeline': 301,
}
管道 pipelines.py
import urllib.request
class ScrapyDangdangPipeline:
# 在爬虫文件执行前执行
def open_spider(self,spider):
self.fp = open('book.json','w',encoding='utf-8')
# item就是yield后面的book对象
def process_item(self,item,spider):
self.fp.write(str(item))
return item
# 在爬虫文件执行后执行
def clode_spider(self,spider):
self.fp.close()
class ScrapyDangdangImgPipeline:
def process_item(self,item,spider):
url = 'http:' + item.get('src')
filename = './books/' + item.get('name') + '.jpg'
urllib.request.urlretrieve(url=url,filename=filename)
return item
4.2、爬取电影天堂电影信息
说明:
(1)、多级页面的数据下载
不遵守 robots 协议 settings.py
# 20 行左右
ROBOTSTXT_OBEY = False
定义数据结构 items.py
import scrapy
class ScrapyMovieItem(scrapy.Item):
name = scrapy.Field()
src = scrapy.Field()
定义爬虫文件 movie.py
import scrapy
from scrapy_movie.items import ScrapyMovieItem
class MovieSpider(scrapy.Spider):
name = 'movie'
allowed_domains = ['www.ygdy8.net']
start_urls = ['https://www.ygdy8.net/html/gndy/china/index.html']
def parse(self, response):
a_list = response.xpath('//b//a[2]')
for a in a_list:
name = a.xpath('./text()').extract_first()
href = a.xpath('./@href').extract_first()
# 第二页的地址
url = 'https://www.ygdy8.net' + href
# 对第二页的链接进行访问
yield scrapy.Request(url=url,callback=self.parse_second,meta={'name':name})
def parse_second(self,response):
src = response.xpath('//img/@src').extract_first()
# 接收请求的 meta 的参数值
name = response.meta['name']
movie = ScrapyMovieItem(src=src,name=name)
yield movie
开启管道 settings.py
# 65 行左右
ITEM_PIPELINES = {
'scrapy_movie.pipelines.ScrapyMoviePipeline': 300,
}
管道 pipelines.py
class ScrapyMoviePipeline:
def open_spider(self,spider):
self.fp = open("movie.json","w",encoding="utf-8")
def process_item(self, item, spider):
self.fp.write(str(item))
return item
def close_spider(self,spider):
self.fp.close()