flink源码阅读---单作业单集群作业提交流程
flink on yarn 模式支持两种部署方式:
1. 多作业但集群
2. 单作业但集群
本文主要介绍单作业单集群下作业提交流程:
核心组件:
Job CLI: 即flink run,非 detatched 模式下的客户端进程,用以获取 yarn Application Master 的运行状态并将日志输出掉终端
Job Manager[JM]: 负责作业的运行计划ExecutionGraph的生成,物理计划生成和作业调度
TaskManager[TM]:负责被分发 task 的执行、心跳/状态上报、资源管理
启动方式:
启动Flink Yarn Session有2种模式:分离模式、客户端模式
通过-d指定分离模式,即客户端在启动Flink Yarn Session后,就不再属于Yarn Cluster的一部分。如果想要停止Flink Yarn Application,需要通过yarn application -kill 命令来停止。
作业提交整体流程:
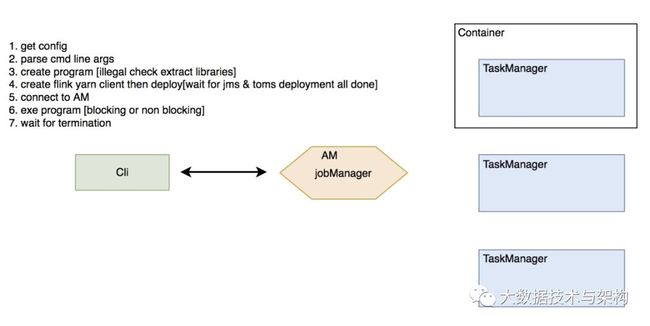
提交流程详细分析:
启动命令:
./bin/flink run -m yarn-cluster -yn 2 -j flink-demo-1.0.0-with-dependencies.jar —ytm 1024 -yst 4 -yjm 1024 —yarnname
flink 在收到这样一条命令后会首先通过 Cli 获取 flink 的配置,并解析命令行参数。
程序入口
CliFrontend.java 是 flink 提交作业的入口
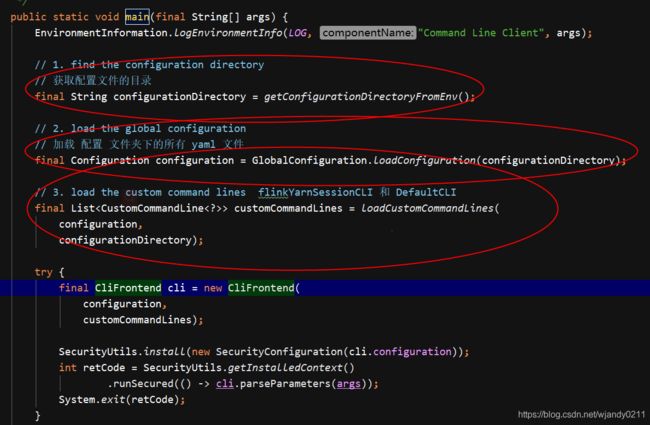
解析参数,并路由到 run方法
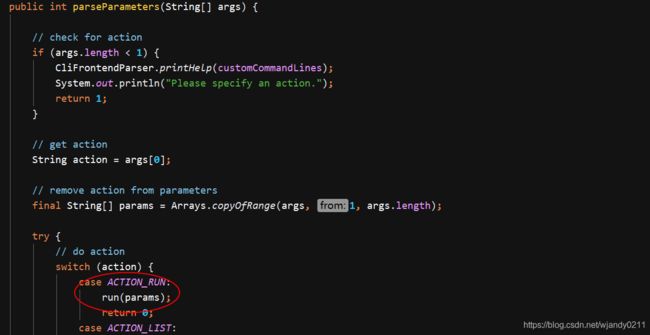
解析参数,构建program, 获取当前集群模式入口即:FlinkYarnSessionCli 和 DefaultCli
其中FlinkYarnSessionCli是flink yarn session 模式,DefaultCli为standalone模式

flink集群构建:
flink 通过 两个不同的 CustomCommandLine 来实现不同集群模式的解析,分别是 FlinkYarnSessionCli和 DefaultCLI 解析命令行参数:

final CustomCommandLine customCommandLine = getActiveCustomCommandLine(commandLine);
那么什么时候解析成 Yarn Cluster 什么时候解析成 Standalone 呢?由于FlinkYarnSessionCli被优先添加到customCommandLine,所以会先触发下面这段逻辑:
public boolean isActive(CommandLine commandLine) {
String jobManagerOption = commandLine.getOptionValue(addressOption.getOpt(), null);
boolean yarnJobManager = ID.equals(jobManagerOption);
boolean yarnAppId = commandLine.hasOption(applicationId.getOpt());
return yarnJobManager || yarnAppId || (isYarnPropertiesFileMode(commandLine) && yarnApplicationIdFromYarnProperties != null);
}从上面可以看出如果用户传入了 -m参数或者application id或者配置了yarn properties 文件,则启动yarn cluster模式,否则是Standalone模式的集群
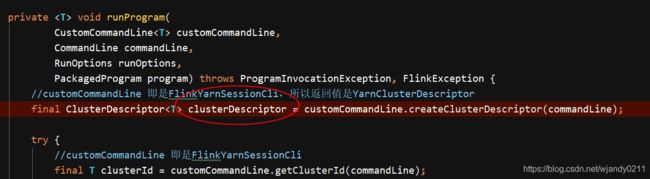
最后获取YarnClusterDescriptor,YarnClusterDescriptor来描述yarn集群的部署配置,具体对应的配置文件为flink-conf.yaml
flink集群部署:
flink通过YarnClusterDescriptor来描述yarn集群的部署配置,具体对应的配置文件为flink-conf.yaml。
获取YarnClusterDescriptor

初始化JobGraph:
部署集群:

大致过程:
-
check yarn 集群队列资源是否满足请求
-
设置 AM Context、启动命令、submission context
-
通过 yarn client submit am context
-
将yarn client 及相关配置封装成 YarnClusterClient 返回
真正在 AM 中运行的主类是 YarnApplicationMasterRunner,它的 run方法做了如下工作:
-
启动JobManager ActorSystem
-
启动 flink ui
-
启动YarnFlinkResourceManager来负责与yarn的ResourceManager交互,管理yarn资源
-
启动 actor System supervise 进程
到这里 JobManager 已经启动起来
这样一个 flink 集群便构建出来了。下面附图解释下这个流程:
-
flink cli 解析本地环境配置,启动 ApplicationMaster
-
在 ApplicationMaster 中启动 JobManager
-
在 ApplicationMaster 中启动YarnFlinkResourceManager
-
YarnFlinkResourceManager给JobManager发送注册信息
-
YarnFlinkResourceManager注册成功后,JobManager给YarnFlinkResourceManager发送注册成功信息
-
YarnFlinkResourceManage知道自己注册成功后像ResourceManager申请和TaskManager数量对等的 container
-
在container中启动TaskManager
-
TaskManager将自己注册到JobManager中
flink作业提交执行:
作业的执行其实只是调用了用户jar包的主函数,真正的触发生成过程由用户代码的执行来完成。
获取Environment
val env = StreamExecutionEnvironment.getExecutionEnvironment,这段代码会获取客户端的环境配置,它首先会转到这样一段逻辑:
//StreamExecutionEnvironment 1256
public static StreamExecutionEnvironment getExecutionEnvironment() {
if (contextEnvironmentFactory != null) {
return contextEnvironmentFactory.createExecutionEnvironment();
}
// because the streaming project depends on "flink-clients" (and not the other way around)
// we currently need to intercept the data set environment and create a dependent stream env.
// this should be fixed once we rework the project dependencies
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
ExecutionEnvironment.getExecutionEnvironment();获取环境的逻辑如下:
//ExecutionEnvironment line1137
public static ExecutionEnvironment getExecutionEnvironment() {
return contextEnvironmentFactory == null ?
createLocalEnvironment() : contextEnvironmentFactory.createExecutionEnvironment();
}这里的contextEnvironmentFactory是一个静态成员,早在ContextEnvironment.setAsContext(factory)已经触发过初始化了,其中包含了如下的环境信息:
//ContextEnvironmentFactory line51
public ContextEnvironmentFactory(ClusterClient client, List jarFilesToAttach,
List classpathsToAttach, ClassLoader userCodeClassLoader, int defaultParallelism,
boolean isDetached, String savepointPath)
{
this.client = client;
this.jarFilesToAttach = jarFilesToAttach;
this.classpathsToAttach = classpathsToAttach;
this.userCodeClassLoader = userCodeClassLoader;
this.defaultParallelism = defaultParallelism;
this.isDetached = isDetached;
this.savepointPath = savepointPath;
} 其中的 client 就是上面生成的 YarnClusterClient,
用户在执行val env = StreamExecutionEnvironment.getExecutionEnvironment这样一段逻辑后会得到一个StreamContextEnvironment,其中封装了 streaming 的一些执行配置 【buffer time out等】,另外保存了上面提到的 ContextEnvironment 的引用。
到这里关于 streaming 需要的执行环境信息已经设置完成。
StreamGraph 的生成:
接下来用户代码执行到DataStream
public DataStreamSource addSource(SourceFunction function, String sourceName, TypeInformation typeInfo) {
if (typeInfo == null) {
if (function instanceof ResultTypeQueryable) {
typeInfo = ((ResultTypeQueryable) function).getProducedType();
} else {
try {
typeInfo = TypeExtractor.createTypeInfo(
SourceFunction.class,
function.getClass(), 0, null, null);
} catch (final InvalidTypesException e) {
typeInfo = (TypeInformation) new MissingTypeInfo(sourceName, e);
}
}
}
boolean isParallel = function instanceof ParallelSourceFunction;
clean(function);
StreamSource sourceOperator;
if (function instanceof StoppableFunction) {
sourceOperator = new StoppableStreamSource<>(cast2StoppableSourceFunction(function));
} else {
sourceOperator = new StreamSource<>(function);
}
return new DataStreamSource<>(this, typeInfo, sourceOperator, isParallel, sourceName);
} 简要总结下上面的逻辑:
-
获取数据源 source 的 output 信息 TypeInformation
-
生成 StreamSource sourceOperator
-
生成 DataStreamSource【封装了 sourceOperator】,并返回
-
将 StreamTransformation 添加到算子列表 transformations 中【只有 转换 transform 操作才会添加算子,其它都只是暂时做了 transformation 的叠加封装】
-
后续会在 DataStream 上做操作