计算机组成原理——存储系统(下)(双口RAM&Cache的映射及替换算法&Cache写策略)
文章目录
- 一、双口RAM与多模块存储器
-
- 1.存取周期
- 2.双口RAM
- 3.多体并行存储器
- 4.应该取几个“体”?
- 5.多模块存储器
- 二、Cache的基本概念和原理
-
- 1.存储系统存在的问题
- 2.Cache的工作原理
- 3.局部性原理
- 4.性能分析
- 5.有待解决的问题
- 三、Cache和主存的映射方式
-
- 1.全相联映射(随意放)
- 2.直接映射(只能放固定位置)
- 3.组相连映射
- 四、Cache替换算法
-
- 1.替换算法解决的问题
- 2.随机算法(RAND,random)
- 3.先进先出算法(FIFO,first in first out)
- 4.近期最少使用(LRU,Least Recently Used)
- 5.最近不经常使用(LFU,Least Frequently Used)
- 五、Cache写策略
-
- 1.问题:CPU修改了cache中的数据副本,如何确保主存中数据母本的一致性?
- 2.写命中
- 3.写不命中
- 4.多级cache
- 六、虚拟存储系统
-
- 1.页式存储
- 2.虚拟存储器
- 总结
一、双口RAM与多模块存储器
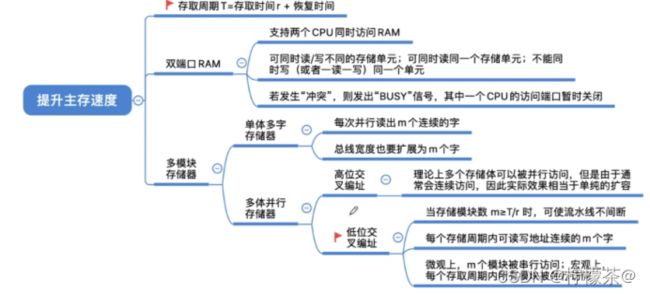
1.存取周期
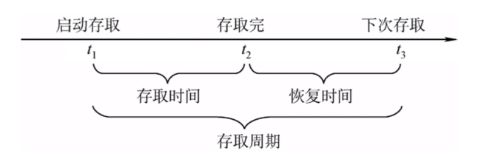
(1)存取周期:可以连续读/写的最短时间间隔
(2)注:DRAM芯片的恢复时间比较长,有可能是存取时间的几倍(SRAM的恢复时间较短)
(3)目前问题
①多核CPU都要访存,怎么办?
②CPU的读写速度比主存快很多,主存恢复时间太长怎么办?
2.双口RAM
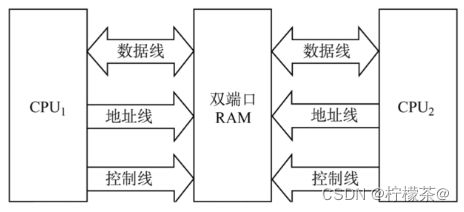
(1)作用:优化多核CPU访问一根内存条的速度
(2)需要有两组完全独立的数据线、地址线、控制线。CPU、RAM中也要有更复杂的控制电路
(3)两个端口对同一主存操作有以下4种情况:
①两个端口同时对不同的地址单元存取数据。
②两个端口同时对同一地址单元读出数据。
③两个端口同时对同一地址单元写入数据。(发生写入错误)
④两个端口同时对同一地址单元,一个写入数据,另一个读出数据。(发生读出错误)
(4)解决方法:置“忙”信号为0,由判断逻辑决定暂时关闭一个端口(即被延时),未被关闭的端口正常访问,被关闭的端口延长一个很短的时间段后再访问。
(5)对比操作系统“读者-写者问题”
3.多体并行存储器

(1)读写问题
①每个存储体存取周期为T存取时间为r,假设T=4r
②连续访问:00000,,00001,00010,00011,00100
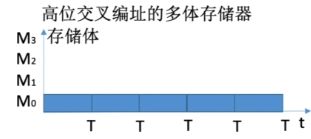
③高位交叉:连续取n个存储字→耗时nT
④低位交叉:连续取n个存储字→耗时T+(n-1)r
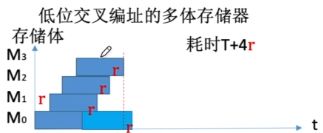
⑤低位比高位性能效率更高
4.应该取几个“体”?
(1)采用“流水线”的方式并行存取(宏观上并行,微观上串行)
(2)宏观上,一个存储周期内,m体交叉存储器可以提供的数据量为单个模块的m倍。
(3)两种描述
①存取周期为T,存取时间为r,为了使流水线不间断,应保证模块数m≥T/r
②存取周期为T,总线传输周期为r,为了使流水线不间断,应保证模块数m≥T/r
5.多模块存储器
(1)多体并行存储器
①每个模块都有相同的容量和存取速度。
②各模块都有独立的读写控制电路、地址寄存器和数据寄存器。它们既能并行工作,又能交叉工作。
(2)单体多字存储器
①每个存储单元存储m个字,总线宽度也为m个字
②一次并行读出m个字
③每次只能同时取m个字,不能单独取其中某个字,指令和数据在主存内必须是连续存放的
二、Cache的基本概念和原理

1.存储系统存在的问题
(1)双端口RAM、多模块存储器提高存储器的工作速度
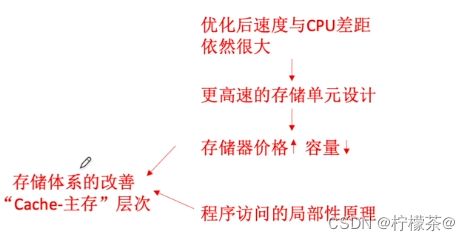
2.Cache的工作原理
(1)无Cache时

(2)有Cache
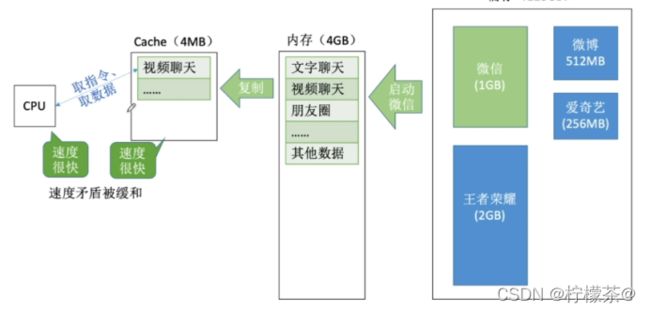
注:实际上,Cache被集成在CPU内部Cache用SRAM实现,速度快,成本高
3.局部性原理
(1)空间局部性:在最近的未来要用到的信息(指令和数据),很可能与现在正在使用的信息在存储空间上是邻近的。Eg:数组元素、顺序执行的指令代码
(2)时间局部性:在最近的未来要用到的信息,很可能是现在正在使用的信息。Eg:循环结构的指令代码
(3)基于局部性原理,不难想到,可以把CPU目前访问的地址“周围”的部分数据放到Cache中
4.性能分析
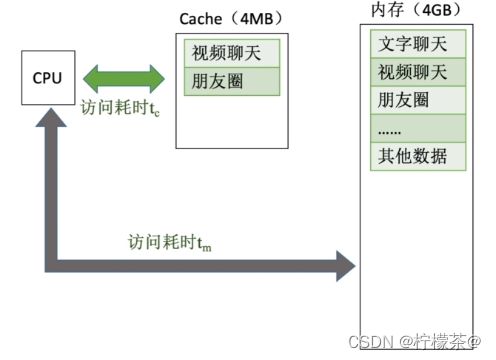
(1)设tc为访问一次Cache所需时间,tm为访问一次主存所需时间
(2)命中率H:CPu欲访问的信息已在Cache中的比率
(3)缺失(未命中)率M=1-H
(4)Cache—主存系统的平均访问时间t
①t = Htc+ (1 -H)(tc+ tm),先访问Cache,若cache未命中再访问主存
②T=Htc+(1 -H)tm,同时访问Cache和主存,若cache命中则立即停止访问主存
(5)例:假设Cache的速度是主存的5倍,且Cache的命中率为95%则采用Cache后,存储器性能提高多少(设Cache和主有同时被访问,若Cache命中则中断访问主存)?
①设Cache的存取周期为t,则主存的存取周期为5t
②若Cache和主存同时访问,命中时访问时间为t,未命中时访问时间为5t平均访问时间为0.95×t+0.05×5t=1.2t,故性能为原来的5t/1.2t=4.17倍
③若先访问cache再访问主存,命中时访问时间为t,未命中时访问时间为t+5t平均访问时间为T=0.95×t +0.05×6t= 1.25t,故性能为原来的4倍
5.有待解决的问题
(1)基于局部性原理,不难想到,可以把CPU目前访问的地址“周围”的部分数据放到cache中。如何界定“周围”?
(2)将主存的存储空间“分块”,如:每1KB为一块。主存与Cache之间以“块”为单位进行数据交换

(3)注:操作系统中,通常将主存中的“一个块”也称为“一个页/页面/页框”,Cache中的“块”也称为“行”
(4)注意:每次被访问的主存块,一定会被立即调入Cache
三、Cache和主存的映射方式

1.全相联映射(随意放)
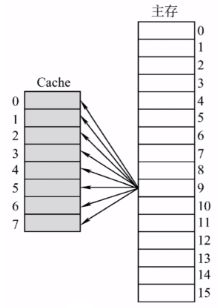
(1)主存块可以放在Cache的任意位置
(2)假设某个计算机的主存地址空间大小为256MB,按字节编址,其数据Cache有8个Cache行(与主存块大小相等),行长为64B。

(3)如何访存
①CPU访问主存地址1…1101001110:
②主存地址的前22位,对比Cache中所有块的标记;
③若标记匹配且有效位=1,则Cache命中,访问块内地址为001110的单元。
④若未命中或有效位=0,则正常访问主存
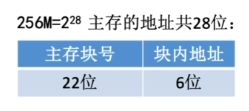
2.直接映射(只能放固定位置)
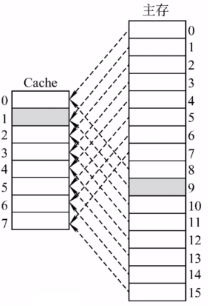
(1)每个主存块只能放到一个特定的位置:Cache块号=主存块号% Cache总块数
(2)假设某个计算机的主存地址空间大小为256MB,按字节编址,其数据Cache有8个Cache行(与主存块大小相等),行长为64B。


(3)缺点:其他地方有空闲Cache块,但是8号主存块不能使用
(4)若cache总块数=2^n,则主存块号末尾n位直接反映它在Cache中的位置,将主存块号的其余位作为标记即可
(5)如何访存
①CPU访问主存地址0…01000 001110 :根据主存块号的后3位确定cache行
②若主存块号的前19位与Cache标记匹配且有效位=1,则Cache命中,访问块内地址为001110的单元。
③若未命中或有效位=0,则正常访问主存
3.组相连映射
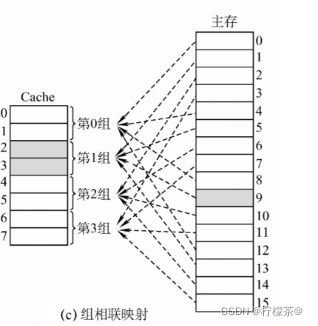
(1)Cache块分为若干组,每个主存块可放到特定分组中的任意一个位置
(2)组号=主存块号%分组数

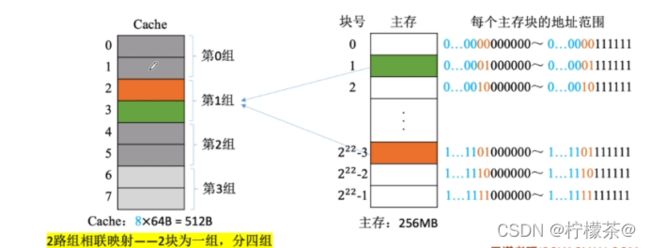
(3)主存块号%2^2,相当于留下最后两位块号
(4)如何访存
①CPU访问主存地址1…1101001110 ,根据主存块号的后2位确定所属分组号
②若主存块号的前20位与分组内的某个标记匹配且有效位=1,则cache命中,访问块内地址为001110的单元。
③若未命中或有效位=0,则正常访问主存
四、Cache替换算法
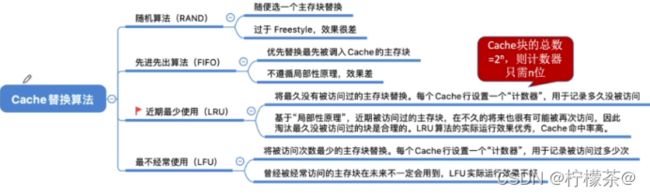
1.替换算法解决的问题
(1)全相联映射:Cache完全满了才需要替换,需要在全局选择替换哪一块
(2)直接映射:如果对应位置非空,则毫无选择地直接替换
(3)组相连映射:分组内满了才需要替换,需要在分组内选择替换哪一块
(4)故只有全相联映射和组相连映射需要进行选择替换
2.随机算法(RAND,random)
(1)若cache已满,则随机选择一块替换。
(2)设总共有4个cache块,初始整个Cache为空。采用全相联映射,依次访问主存块{1,2,3,4,1,2,5,1,2,3,4,5}
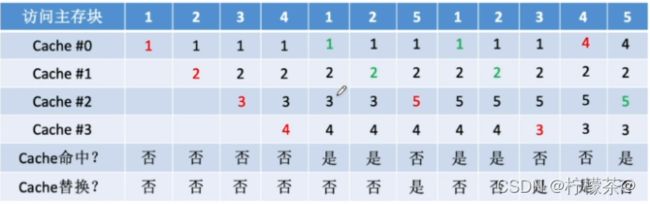
(3)实现简单,但完全没考虑局部性原理,命中率低,实际效果很不稳定
3.先进先出算法(FIFO,first in first out)
(1)若cache已满,则替换最先被调入Cache的块
(2)设总共有4个cache块,初始整个Cache为空。采用全相联映射,依次访问主存块{1,2,3,4,1,2,5,1,2,3,4,5}
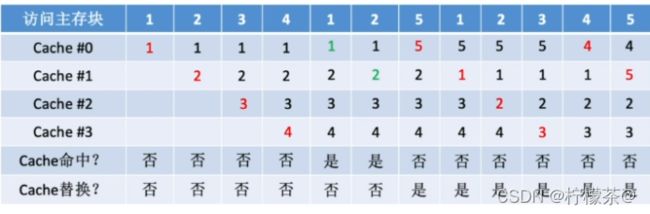
(3)实现简单,最开始按#0#1#2#3放入Cache,之后轮流替换#0#1#2#3,FIFO依然没考虑局部性原理,最先被调入Cache的块也有可能是被频繁访问的
(4)抖动现象:频繁的换入换出现象(刚被替换的块很快又被调入)
4.近期最少使用(LRU,Least Recently Used)
(1)为每一个Cache块设置一个“计数器”,用于记录每个cache块已经有多久没被访问了。当cache满后替换“计数器”最大的
(2)设总共有4个cache块,初始整个Cache为空。采用全相联映射,依次访问主存块{1,2,3,4,1,2,5,1,2,3,4,5}
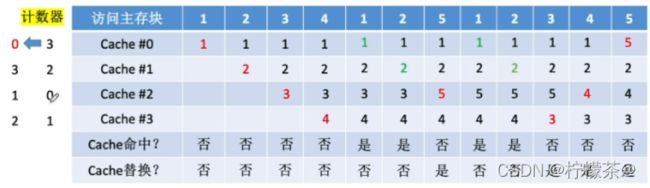
(3)计数器规则
①命中时,所命中的行的计数器清零,比其低的计数器加1,其余不变
②未命中且还有空闲行时,新装入的行的计数器置0,其余非空闲行全加1;
③未命中且无空闲行时,计数值最大的行的信息块被淘汰,新装行的块的计数器置0,其余全加1。
(4)Cache块的总数=2^n,则计数器只需n位。且Cache装满后所有计数器的值一定不重复
(5)基于“局部性原理”,近期被访问过的主存块,在不久的将来也很有可能被再次访问,因此淘汰最久没被访问过的块是合理的.LRU算法的实际运行效果优秀,cache命中率高。
(6)若被频繁访问的主存块数量>Cache行的数量,则有可能发生“抖动
5.最近不经常使用(LFU,Least Frequently Used)
(1)为每一个Cache块设置一个“计数器”,用于记录每个cache块被访问过几次。当Cache满后替换“计数器”最小的
(2)设总共有4个cache块,初始整个Cache为空。采用全相联映射,依次访问主存块{1,2,3,4,1,2,5,1,2,3,4,5}

(3)新调入的块计数器=0,之后每被访问一次计数器+1。需要替换时,选择计数器最小的一行,若有多个计数器最小的行,可按行号递增、或FIFO策略进行选择
(4)曾经被经常访问的主存块在未来不一定会用到(如:微信视频聊天相关的块),并没有很好地遵循局部性原理,因此实际运行效果不如LRU
五、Cache写策略
1.问题:CPU修改了cache中的数据副本,如何确保主存中数据母本的一致性?
2.写命中
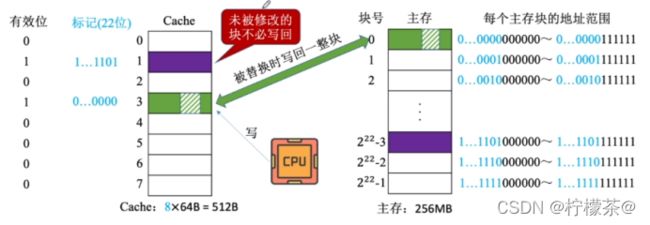
(1)写回法(write-back)——当CPU对Cache写命中时,只修改Cache的内容,而不立即写入主存,只有当此块被换出时才写回主存
①设置脏位,表示是否被修改过
②减少了访存次数,但存在数据不一致的隐患。
(2)全写法(写直通法,write-through)——当CPU对Cache写命中时,必须把数据同时写入Cache和主存,一般使用写缓冲(write buffer)
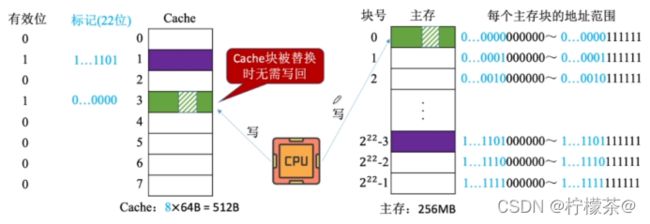
①访存次数增加,速度变慢,但更能保证数据一致性
②优化:增加写缓冲(SRAM实现的FIFO队列),在专门的控制电路下逐一写回
③使用写缓冲,CPU写的速度很快,若写操作不频繁,则效果很好。若写操作很频繁,可能会因为写缓冲饱和而发生阻塞
3.写不命中
(1)写分配法(write-allocate):当CPU对Cache写不命中时,把主存中的块调入Cache,在Cache中修改。通常搭配写回法使用。
(2)非写分配法(not-write-allocate):当CPU对Cache写不命中时只写入主存,不调入Cache。搭配全写法使用。
4.多级cache
(1)现代计算机常采用多级cache,离CPU越近的速度越快,容量越小离CPU越远的速度越慢,容量越大
六、虚拟存储系统
1.页式存储

(1)页式存储系统:一个程序(进程)在逻辑上被分为若干个大小相等的“页面”,“页面”大小与“块”的大小相同。每个页面可以离散地放入不同的主存块中。
(2)虚地址vs实地址

①逻辑地址(虚地址):程序员视角看到的地址
②物理地址(实地址):实际在主存中的地址
③程序员视角:
1)整个程序共4KB=212B,地址范围:000000000000~111111111111
2)操作系统负责将程序员指明的逻辑地址映射为物理地址,重点在于把逻辑页号映射到主存块号
④操作系统会建立页表
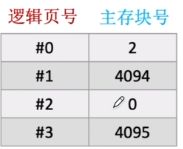
(3)CPU执行的机器指令中,使用的是“逻辑地址”,因此需要通“页表”将逻辑地址转为物理地址。
(4)页表的作用:记录了每个逻辑页面存放在哪个主存块中(页表数据在主存里)
(5)地址交换过程
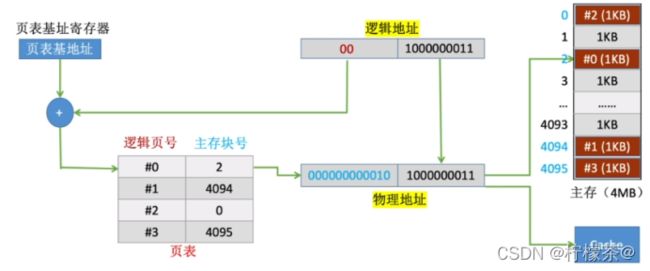
①逻辑地址将逻辑地址拆分为(逻辑页号+页内地址)
②页表基地址指明了页表在主存中的存放地址
③用主存块号拼接页内地址得到最终的地址,进行访问
(6)地址交换过程(增加TLB)
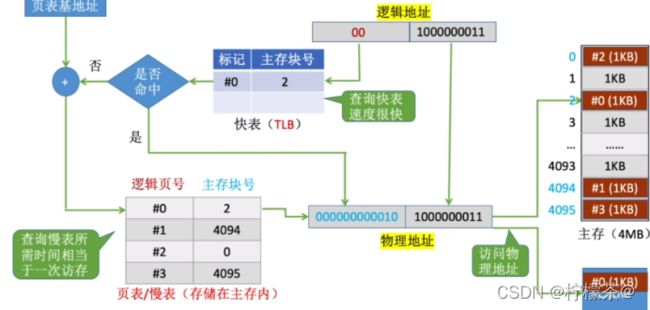
①注意区别:快表中存储的是页表项的副本;Cache中存储的是主存块的副本
②快表是一种“相联存储器”,可以按内容寻访
2.虚拟存储器
(1)页式虚拟存储器
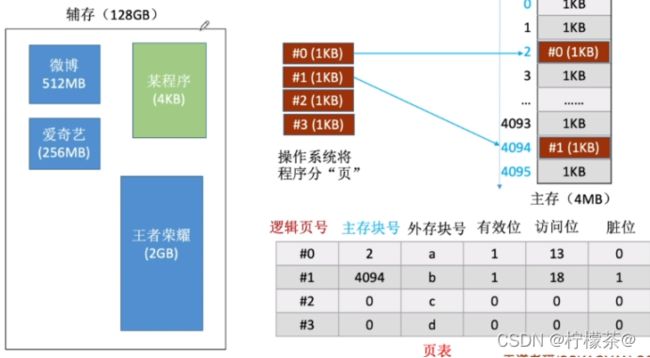
①整体类似于之前介绍的页式存储器
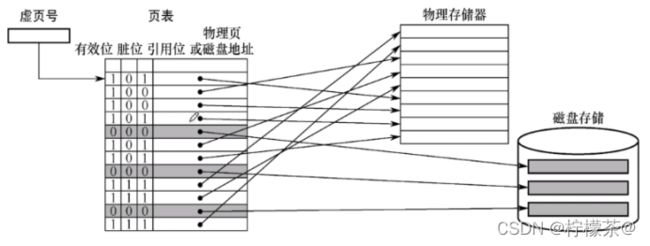
②有效位:这个页面是否已调入主存
③脏位:这个页面是否被修改过
④引用位:用于“页面置换算法”,比如,可以用来统计这个页面被访问过多少次
⑤物理页:即主存块号
⑥磁盘地址:即这个页面的数据在磁盘中的存放位置
⑦物理存储器:主存
⑧根据虚页号查询页表
(2)段氏虚拟存储器
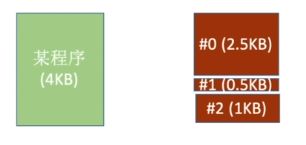
①段式虚拟存储器――按照功能模块拆分
②如:#0段是自己的代码,#1段是库函数代码,#2段是变量
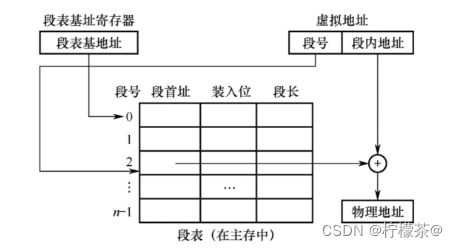
③此处详细内容将在操作系统中重点介绍,此处不做赘述
(3)段页式虚拟存储器
①把程序按逻辑结构分段,每段再划分为固定大小的页,主存空间也划分为大小相等的页,
②程序对主存的调入、调出仍以页为基本传送单位。
③每个程序对应一个段表,每段对应一个页表。
④虚拟地址:段号+段内页号+页内地址
总结
在存储系统中,应重点理解Cache的作用及其结构,分清Cache的多种映射方式,顺应的理解其不同替换算法,了解如何实现Cache写策略,分析高/低位交叉编址。
重点理解Cache的整体功能作用及结构,是本章重难点。
如有问题,欢迎指正!