Kubernetes(v1.21.10)集群安装
视频中安装的是v1.20.9,我们安装kubernetes的v1.21.10版本。
1. 环境规划
1. 集群类型
- Kubernetes 集群大致分为两类:一主多从和多主多从。
- 一主多从(单 master ):一个 Master 节点和多台 Node 节点,搭建简单,但是有单机故障风险,适合用于测试环境。
- 多主多从(高可用):多台 Master 节点和多台 Node 节点,搭建麻烦,安全性高,适合用于生产环境。
- 单 master 的架构图:

- 高可用集群的架构图:

为了测试方便,本次搭建是一主两从类型的集群。
2. 安装方式
Kubernetes 有多种部署方式,目前主流的方式有 kubeadm 、minikube 、二进制包。
- ① minikube:一个用于快速搭建单节点的 Kubernetes 工具。
- ② kubeadm:一个用于快速搭建Kubernetes 集群的工具(可以用于生产环境)。
- ③ 二进制包:从官网上下载每个组件的二进制包,依次去安装(建议生产环境使用)。
本次我们以 kubeadm 的方式安装Kubernetes。
3. 主机规划
| 角色 | IP地址 | 操作系统 | 配置 | hostname |
|---|---|---|---|---|
| Master | 192.168.187.105 | CentOS 7.9,基础设施服务器 | 2核CPU,4G内存,50G硬盘 | k8s-master |
| Node1 | 192.168.187.106 | CentOS 7.9,基础设施服务器 | 2核CPU,4G内存,50G硬盘 | k8s-node1 |
| Node2 | 192.168.187.107 | CentOS 7.9,基础设施服务器 | 2核CPU,4G内存,50G硬盘 | k8s-node2 |
4. 搭建流程
- ① 准备 3 台机器,要求网络互通(如果是云服务器,要求私网互通;如果是虚拟机,要求网络互通)。
- ② 在 3 台机器上安装 Docker 容器化环境。
- ③ 安装 Kubernetes :
- 3 台机器安装核心组件:kubeadm(创建集群的引导工具)、kubelet 、kubectl(程序员使用的命令行)。
- kubelet 可以直接通过容器化的方式创建出 Kubernetes 的核心组件,如:Controller Manager、Scheduler 等。
- 由 kubeadm 引导创建 Kubernetes 集群。
2. kubernetes安装
1. Kubernetes 和 Docker 之间的版本对应关系
https://github.com/kubernetes/kubernetes/tree/master/CHANGELOG
从文档中,我们可以知道 Docker 的版本是 v20.10 ,对应的 Kubernetes 的版本是 v1.21 。
2. 前置条件
-
一台兼容的 Linux 主机。Kubernetes 项目为基于 Debian 和 Red Hat 的 Linux 发行版以及一些不提供包管理器的发行版提供通用的指令
-
每台机器 2 GB 或更多的 RAM (如果少于这个数字将会影响你应用的运行内存)
-
2 CPU 核或更多
-
集群中的所有机器的网络彼此均能相互连接(公网和内网都可以)
- 设置防火墙放行规则
-
节点之中不可以有重复的主机名、MAC 地址或 product_uuid。请参见这里了解更多详细信息。
- 设置不同hostname
-
开启机器上的某些端口。请参见 这里 了解更多详细信息。
- 内网互信
-
禁用交换分区。为了保证 kubelet 正常工作,你 必须 禁用交换分区。
- 永久关闭
-
如果是虚拟机则需要让三台机器互通,最简单的做法就是关闭防火墙。
# 1 关闭firewalld服务
[root@master ~]# systemctl stop firewalld
[root@master ~]# systemctl disable firewalld
# 2 关闭iptables服务
[root@master ~]# systemctl stop iptables
[root@master ~]# systemctl disable iptables
- 如果是云厂商提供的云服务器则需要让三台机器的私有 IP 互通,需要让私有网络在同一网段,还需要设置安全组策略放行执行的端口。
3. 准备环境
3.1 检查系统环境
- 查看当前系统的版本
# 安装kubernetes集群要求Centos版本要在7.5或之上
[root@master ~]# cat /etc/redhat-release
Centos Linux 7.5.1804 (Core)
- 查看当前的系统内核
[root@k8s-master ~]# uname -sr
Linux 3.10.0-1160.el7.x86_64
默认的 3.10.0 实在是太低了。
K8S安装必须升级内核版本到4.4以上。本次升级是直接升级到5.4。
# 更新yum源(不用执行)
[root@master ~]# yum -y update
#载入公钥
[root@master ~]# rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
#安装 ELRepo 最新版本
[root@master ~]# yum install -y https://www.elrepo.org/elrepo-release-7.el7.elrepo.noarch.rpm
#列出可以使用的 kernel 包版本
[root@master ~]# yum list available --disablerepo=* --enablerepo=elrepo-kernel
# 安装指定的 kernel 版本(这里的版本有kernel-lt和kernel-ml两种,建议采用lt长期支持版本)
[root@master ~]# yum -y --enablerepo=elrepo-kernel install kernel-lt
kernel-lt 和 kernel-ml 二者的区别:
kernel-ml软件包是根据Linux Kernel Archives的主线稳定分支提供的源构建的。 内核配置基于默认的RHEL-7配置,并根据需要启用了添加的功能。 这些软件包有意命名为kernel-ml,以免与RHEL-7内核发生冲突,因此,它们可以与常规内核一起安装和更新。
kernel-lt包是从Linux Kernel Archives提供的源代码构建的,就像kernel-ml软件包一样。 不同之处在于kernel-lt基于长期支持分支,而kernel-ml基于主线稳定分支。
在 ELRepo中有两个内核选项,一个是kernel-lt(长期支持版),一个是 kernel-ml(主线最新版本),采用长期支持版本(kernel-lt),更加稳定一些。
# 查看系统上可用的内核
[root@k8s-master ~]# awk -F\' '$1=="menuentry " {print $2}' /etc/grub2.cfg
CentOS Linux (5.4.237-1.el7.elrepo.x86_64) 7 (Core)
CentOS Linux (3.10.0-1160.el7.x86_64) 7 (Core)
CentOS Linux (0-rescue-e307321b3aed4c66b0e2d472430792b5) 7 (Core)
# 设置默认的内核版本
[root@k8s-master ~]# vim /etc/default/grub
# 将GRUB_DEFAULT=saved改为GRUB_DEFAULT=0,保存退出vim
GRUB_TIMEOUT=5
GRUB_DISTRIBUTOR="$(sed 's, release .*$,,g' /etc/system-release)"
GRUB_DEFAULT=0 # 修改此处,原来是 saved
GRUB_DISABLE_SUBMENU=true
GRUB_TERMINAL_OUTPUT="console"
GRUB_CMDLINE_LINUX="crashkernel=auto rd.lvm.lv=centos/root rd.lvm.lv=centos/swap rhgb quiet"
GRUB_DISABLE_RECOVERY="true"
# 重新创建内核配置
[root@k8s-master ~]# grub2-mkconfig -o /boot/grub2/grub.cfg
Generating grub configuration file ...
Found linux image: /boot/vmlinuz-5.4.237-1.el7.elrepo.x86_64
Found initrd image: /boot/initramfs-5.4.237-1.el7.elrepo.x86_64.img
Found linux image: /boot/vmlinuz-3.10.0-1160.el7.x86_64
Found initrd image: /boot/initramfs-3.10.0-1160.el7.x86_64.img
Found linux image: /boot/vmlinuz-0-rescue-e307321b3aed4c66b0e2d472430792b5
Found initrd image: /boot/initramfs-0-rescue-e307321b3aed4c66b0e2d472430792b5.img
done
#重启系统使内核生效:
[root@k8s-master ~]# reboot
#启动完成查看内核版本是否更新:
[root@k8s-master ~]# uname -sr
Linux 5.4.237-1.el7.elrepo.x86_64
3.2 设置主机名
# Centos7.5版本命令:需要编辑 /etc/hostname 进行修改
# Centos7.9版本命令:
hostnamectl set-hostname <hostname>
# 示例:
hostnamectl set-hostname k8s-master
hostnamectl set-hostname k8s-node1
hostnamectl set-hostname k8s-node2
3.3 主机名解析
- 为了方便后面集群节点间的直接调用,需要配置一下主机名解析,企业中推荐使用内部的 DNS 服务器。
cat >> /etc/hosts << EOF
127.0.0.1 $(hostname)
192.168.187.105 k8s-master
192.168.187.106 k8s-node1
192.168.187.107 k8s-node2
EOF
3.4 时间同步
- Kubernetes 要求集群中的节点时间必须精确一致,所以在每个节点上添加时间同步
[root@k8s-master ~]# yum install ntpdate -y
[root@k8s-master ~]# ntpdate time.windows.com
3.5 关闭 SELinux
# 查看 SELinux 是否开启
[root@k8s-master ~]# getenforce
Enforcing
# 永久关闭 SELinux,需要重启
[root@k8s-master ~]# sudo sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/config
# 关闭当前会话的 SELinux ,重启之后无效
[root@k8s-master ~]# setenforce 0
3.6 关闭swap分区
# 关闭当前会话的swap,重启之后无效
[root@k8s-master ~]# swapoff -a
# 永久关闭swap,需要重启
[root@k8s-master ~]# sed -ri 's/.*swap.*/#&/' /etc/fstab
# 查看swap是否关闭
[root@k8s-master ~]# free -m
3.7 将桥接的IPv4流量传递到iptables的链
- 修改 /etc/sysctl.conf 文件:
# 如果有配置,则修改
sed -i "s#^net.ipv4.ip_forward.*#net.ipv4.ip_forward=1#g" /etc/sysctl.conf
sed -i "s#^net.bridge.bridge-nf-call-ip6tables.*#net.bridge.bridge-nf-call-ip6tables=1#g" /etc/sysctl.conf
sed -i "s#^net.bridge.bridge-nf-call-iptables.*#net.bridge.bridge-nf-call-iptables=1#g" /etc/sysctl.conf
sed -i "s#^net.ipv6.conf.all.disable_ipv6.*#net.ipv6.conf.all.disable_ipv6=1#g" /etc/sysctl.conf
sed -i "s#^net.ipv6.conf.default.disable_ipv6.*#net.ipv6.conf.default.disable_ipv6=1#g" /etc/sysctl.conf
sed -i "s#^net.ipv6.conf.lo.disable_ipv6.*#net.ipv6.conf.lo.disable_ipv6=1#g" /etc/sysctl.conf
sed -i "s#^net.ipv6.conf.all.forwarding.*#net.ipv6.conf.all.forwarding=1#g" /etc/sysctl.conf
一定注意粘贴执行后看一下 别串行执行。
# 可能没有,追加
echo "net.ipv4.ip_forward = 1" >> /etc/sysctl.conf
echo "net.bridge.bridge-nf-call-ip6tables = 1" >> /etc/sysctl.conf
echo "net.bridge.bridge-nf-call-iptables = 1" >> /etc/sysctl.conf
echo "net.ipv6.conf.all.disable_ipv6 = 1" >> /etc/sysctl.conf
echo "net.ipv6.conf.default.disable_ipv6 = 1" >> /etc/sysctl.conf
echo "net.ipv6.conf.lo.disable_ipv6 = 1" >> /etc/sysctl.conf
echo "net.ipv6.conf.all.forwarding = 1" >> /etc/sysctl.conf
- 加载 br_netfilter 模块
modprobe br_netfilter
- 持久化修改(保留配置包本地文件,重启系统或服务进程仍然有效)
sysctl -p

3.8 开启 ipvs
- 在 Kubernetes 中 service 有两种代理模型,一种是基于 iptables ,另一种是基于 ipvs 的。ipvs 的性能要高于 iptables 的,但是如果要使用它,需要手动载入 ipvs 模块。
- 在三台机器安装 ipset 和 ipvsadm:
yum -y install ipset ipvsadm
- 在三台机器执行如下脚本:
cat > /etc/sysconfig/modules/ipvs.modules <<EOF
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack
EOF
- 授权、运行、检查是否加载
[root@k8s-master ~]# chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep -e ip_vs -e nf_conntrack_ipv4
ip_vs_sh 16384 0
ip_vs_wrr 16384 0
ip_vs_rr 16384 0
ip_vs 155648 6 ip_vs_rr,ip_vs_sh,ip_vs_wrr
nf_conntrack 147456 4 xt_conntrack,nf_nat,xt_MASQUERADE,ip_vs
nf_defrag_ipv6 24576 2 nf_conntrack,ip_vs
libcrc32c 16384 4 nf_conntrack,nf_nat,xfs,ip_vs
3.9 重启三台机器
reboot
4. 安装docker
4.1 卸载旧版本
yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-engine
4.2 初始化一些插件
yum install -y yum-utils \
device-mapper-persistent-data \
lvm2
4.3 docker安装地址
yum-config-manager \
--add-repo \
https://download.docker.com/linux/centos/docker-ce.repo
4.4 安装docker
yum -y install docker-ce-3:20.10.8-3.el7.x86_64 docker-ce-cli-1:20.10.8-3.el7.x86_64 containerd.io
4.5 启动docker
systemctl start docker
4.6 设置开机自启
systemctl enable docker
4.7 配置docker镜像加速
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://076wf9i1.mirror.aliyuncs.com"]
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart docker
5. 添加阿里云的kubernetes的yum源
所有机器执行以下操作
cat <<EOF | sudo tee /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
exclude=kubelet kubeadm kubectl
EOF
6. 安装 kubelet 、kubeadm 和 kubectl
yum install -y kubelet-1.21.10 kubeadm-1.21.10 kubectl-1.21.10 --disableexcludes=kubernetes
# 设置开机自启动
systemctl enable --now kubelet
kubelet 现在每隔几秒就会重启,因为它陷入了一个等待 kubeadm 指令的死循环。
7. 查看kubernetes所需的镜像
[root@k8s-master ~]# kubeadm config images list
I0319 19:48:00.296372 2583 version.go:254] remote version is much newer: v1.26.3; falling back to: stable-1.21
k8s.gcr.io/kube-apiserver:v1.21.14
k8s.gcr.io/kube-controller-manager:v1.21.14
k8s.gcr.io/kube-scheduler:v1.21.14
k8s.gcr.io/kube-proxy:v1.21.14
k8s.gcr.io/pause:3.4.1
k8s.gcr.io/etcd:3.4.13-0
k8s.gcr.io/coredns/coredns:v1.8.0
8. 下载kubernetes需要的镜像
sudo tee ./images.sh <<-'EOF'
#!/bin/bash
images=(
kube-apiserver:v1.21.10
kube-proxy:v1.21.10
kube-controller-manager:v1.21.10
kube-scheduler:v1.21.10
coredns:1.8.0
etcd:3.4.13-0
pause:3.4.1
)
for imageName in ${images[@]} ; do
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/$imageName
done
EOF
chmod +x ./images.sh && ./images.sh
- 查看下载的7个镜像
docker images

9. 初始化master主节点
由于默认拉取镜像地址k8s.gcr.io国内无法访问,这里需要指定阿里云镜像仓库地址
# 云服务
kubeadm init \
--apiserver-advertise-address=192.168.187.105 \
--control-plane-endpoint=k8s-master \
--image-repository registry.cn-hangzhou.aliyuncs.com/google_containers \
--kubernetes-version v1.21.10 \
--service-cidr=10.96.0.0/16 \
--pod-network-cidr=192.168.0.0/16
# 虚拟机
kubeadm init \
--apiserver-advertise-address=192.168.187.105 \
--control-plane-endpoint=k8s-master \
--image-repository registry.cn-hangzhou.aliyuncs.com/google_containers \
--kubernetes-version v1.21.10 \
--service-cidr=10.96.0.0/16 \
--pod-network-cidr=10.244.0.0/16
注意:
- apiserver-advertise-address 一定要是主机的 IP 地址。
- apiserver-advertise-address 、service-cidr 和 pod-network-cidr 不能在同一个网络范围内。
- 不要使用 172.17.0.1/16 网段范围,因为这是 Docker 默认使用的。
- pod-network-cidr如果使用是云服务器,则不用修改使用默认的192.168.0.0/16。
- pod-network-cidr如果使用是虚拟机,则需要修改使用10.244.0.0/16。同时后面配置calico网络的时候记得也需要修改。
日志如下:
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of control-plane nodes by copying certificate authorities
and service account keys on each node and then running the following as root:
kubeadm join k8s-master:6443 --token pqppjo.qlouwiy0ygfdjici \
--discovery-token-ca-cert-hash sha256:539049e44482a263ae12503b2feda041746f6886c16ca459b17d998a4c942de8 \
--control-plane
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join k8s-master:6443 --token pqppjo.qlouwiy0ygfdjici \
--discovery-token-ca-cert-hash sha256:539049e44482a263ae12503b2feda041746f6886c16ca459b17d998a4c942de8
- 根据日志操作。在master进行如下操作:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
- 默认的 token 有效期为 24 小时,当过期之后,该 token 就不能用了,这时可以使用如下的命令创建 token
# 获取新令牌
kubeadm token create --print-join-command
# 生成一个永不过期的token
kubeadm token create --ttl 0 --print-join-command
高可用部署方式,也是在这一步的时候,使用添加主节点的命令即可。
10. 初始化Node节点
- 根据日志提示操作,在 两个从节点 上执行如下命令:
kubeadm join k8s-master:6443 --token pqppjo.qlouwiy0ygfdjici \
--discovery-token-ca-cert-hash sha256:539049e44482a263ae12503b2feda041746f6886c16ca459b17d998a4c942de8
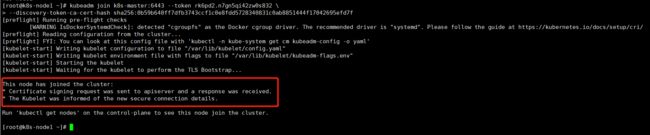
- 查看集群所有节点(需要在master主节点执行)
kubectl get nodes
此时我们会发现Status的状态为NotReady,原因是没有安装网络组件。

11. 安装网络组件
网络插件地址:https://kubernetes.io/docs/concepts/cluster-administration/addons/
Kubernetes 支持多种网络插件,比如 flannel、calico、canal 等,任选一种即可,本次选择 calico官网(在主节点上执行),网络不行,请点击这里 calico.yaml
calico与k8s对应关系
curl https://projectcalico.docs.tigera.io/v3.19/manifests/calico.yaml -O
备注:为什么使用 3.19,原因在这里。
注意:如果是使用虚拟机安装的k8s,需要与**pod-network-cidr**保持一致。
calico.yaml默认CIDR为192.168.0.0/16,需要将注释放开并将value: "10.244.0.0/16"

# 运行
kubectl apply -f calico.yaml

- 查看部署网络插件进度
kubectl get pods -A

注意:这里的status状态都要是running运行中才可以。
12. 查看节点状态
在Master节点上查看节点的状态
kubectl get nodes
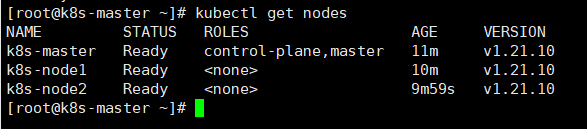
此时的Status状态都是Ready了。
13. 设置 kube-proxy 的 ipvs 模式
在 Master节点设置 kube-proxy 的 ipvs 模式
kubectl edit cm kube-proxy -n kube-system
apiVersion: v1
data:
config.conf: |-
apiVersion: kubeproxy.config.k8s.io/v1alpha1
bindAddress: 0.0.0.0
bindAddressHardFail: false
clientConnection:
acceptContentTypes: ""
burst: 0
contentType: ""
kubeconfig: /var/lib/kube-proxy/kubeconfig.conf
qps: 0
clusterCIDR: 10.244.0.0/16
configSyncPeriod: 0s
conntrack:
maxPerCore: null
min: null
tcpCloseWaitTimeout: null
tcpEstablishedTimeout: null
detectLocalMode: ""
enableProfiling: false
healthzBindAddress: ""
hostnameOverride: ""
iptables:
masqueradeAll: false
masqueradeBit: null
minSyncPeriod: 0s
syncPeriod: 0s
ipvs:
excludeCIDRs: null
minSyncPeriod: 0s
scheduler: ""
strictARP: false
syncPeriod: 0s
tcpFinTimeout: 0s
tcpTimeout: 0s
udpTimeout: 0s
kind: KubeProxyConfiguration
metricsBindAddress: ""
mode: ""
nodePortAddresses: null
minSyncPeriod: 0s
syncPeriod: 0s
ipvs:
excludeCIDRs: null
minSyncPeriod: 0s
scheduler: ""
strictARP: false
syncPeriod: 0s
tcpFinTimeout: 0s
tcpTimeout: 0s
udpTimeout: 0s
kind: KubeProxyConfiguration
metricsBindAddress: ""
mode: "ipvs" # 修改此处
...
ESC,之后输入 /mode回车,在按i, 进行修改。
- 删除 kube-proxy ,让 Kubernetes 集群自动创建新的 kube-proxy
kubectl delete pod -l k8s-app=kube-proxy -n kube-system
14. 让 Node 节点也能使用 kubectl 命令
默认情况下,只有 Master 节点才有 kubectl 命令,但是有些时候我们也希望在 Node 节点上执行 kubectl 命令
# 在两个从节点上执行如下命令
mkdir -pv ~/.kube
touch ~/.kube/config
在主节点执行如下命令
# 192.168.187.106
scp /etc/kubernetes/admin.conf [email protected]:~/.kube/config
# 192.168.187.107
scp /etc/kubernetes/admin.conf [email protected]:~/.kube/config
15. kubernetes安装nginx
# 部署nginx
[root@master ~]# kubectl create deployment nginx --image=nginx:1.14-alpine
# 暴露端口
[root@master ~]# kubectl expose deployment nginx --port=80 --type=NodePort
#查看服务状态
[root@master ~]# kubectl get pods,svc
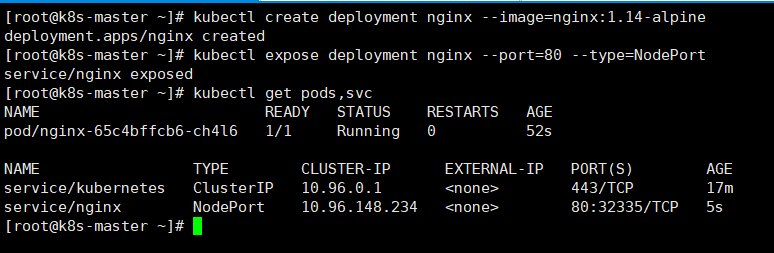
此时用过浏览器访问可以看到Nginx页面。

13. 部署dashboard
1. 部署
kubernetes官方提供的可视化界面
https://github.com/kubernetes/dashboard
# 下载
wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.3.1/aio/deploy/recommended.yaml
# 运行
kubectl apply -f recommended.yaml
网络不行,请点击这里,recommended.yaml。

2. 设置访问端口
kubectl edit svc kubernetes-dashboard -n kubernetes-dashboard
type: ClusterIP 改为 type: NodePort
添加固定端口 nodePort: 31080

kubectl get svc -A |grep kubernetes-dashboard
## 找到端口,在安全组放行
访问: https://集群任意IP:端口 https://192.168.187.105:31460

- 问题1:
此时我们发现Status状态变为CrashLoopBackOff
![]()
# 查看日志
kubectl logs -f -n kubernetes-dashboard kubernetes-dashboard-67484c44f6-plxhh
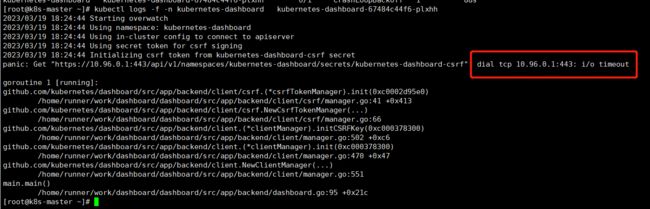
- 问题2:
在谷歌浏览器访问地址的出现以下错误。

解决办法:
解决办法就是在当前页面用键盘输入 thisisunsafe ,不是在地址栏输入,就直接敲键盘就行了,页面即会自动刷新进入网页。
3. 创建访问账号
创建访问账号,准备一个yaml文件; vi dash.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin-user
namespace: kubernetes-dashboard
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: admin-user
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: kubernetes-dashboard
kubectl apply -f dash.yaml
4. 令牌访问
- 获取访问令牌
kubectl -n kubernetes-dashboard describe secret $(kubectl -n kubernetes-dashboard get secret | grep admin-user | awk '{print $1}')
eyJhbGciOiJSUzI1NiIsImtpZCI6IkdXMGx6Yl91Q2NlTktrMFNBTGF1NjJxcS10alUtTnNncG9uc21QRXBwQjQifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJhZG1pbi11c2VyLXRva2VuLTk2ZHh2Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQubmFtZSI6ImFkbWluLXVzZXIiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC51aWQiOiJkOGJiNmY3Ny02NDNhLTRiNWEtODVlOC05ZWVkNTQ2NDExNGMiLCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6a3ViZXJuZXRlcy1kYXNoYm9hcmQ6YWRtaW4tdXNlciJ9.tx1qonWnTOt6hVO6u2NFjL19rDzcJcVu6eJpxn-RKmvKj8f3JmfKnq_9SDmLFZc1mKlvuaaM-BC5_vt66w3tQ0NJXmTMia7Mnco_qfTzfGOrHt3u7C-DX_WS7y6W3Ys952WfYaXujb5B2cqTM6TOpgojsv9u4lZchorGlbCcx8YXi8hYai9vWF-TWKEPdWcg1TELzcROmyvg6HB6JFEmC1oF1lyAezdEy6sZrNDIj--3ZljoKVm23AOig4w6bwZ31Eae-Ed5EBXPGxoDKvjwoQFDbsPN1-oSmZICmaC4wE-GEXrRrJBCsoyNQHuI5YsNJVMxkBS1b8mX61LUPpHF0w
5. 界面

