Flink SQL:Queries(Pattern Recognition)
Pattern Recognition 模式识别
Streaming
It is a common use case to search for a set of event patterns, especially in case of data streams. Flink comes with a complex event processing (CEP) library which allows for pattern detection in event streams. Furthermore, Flink’s SQL API provides a relational way of expressing queries with a large set of built-in functions and rule-based optimizations that can be used out of the box.
搜索一组事件模式是一种常见的用例,尤其是在数据流的情况下。Flink附带了一个复杂事件处理(CEP)库,允许在事件流中进行模式检测。此外,Flink的SQL API提供了一种关系型的查询表达方式,其中包含大量内置函数和基于规则的优化,可以开箱即用。
In December 2016, the International Organization for Standardization (ISO) released a new version of the SQL standard which includes Row Pattern Recognition in SQL (ISO/IEC TR 19075-5:2016). It allows Flink to consolidate CEP and SQL API using the MATCH_RECOGNIZE clause for complex event processing in SQL.
2016年12月,国际标准化组织(ISO)发布了新版本的SQL标准,其中包括SQL中的行模式识别 (ISO/IEC TR 19075-5:2016)。它允许Flink使用MATCH_RECOGNIZE 子句合并CEP和SQL API,以便在SQL中进行复杂事件处理。
A MATCH_RECOGNIZE clause enables the following tasks:
MATCH_RECOGNIZE 子句支持以下任务:
- Logically partition and order the data that is used with the PARTITION BY and ORDER BY clauses.
对与PARTITION BY和ORDER BY子句一起使用的数据进行逻辑分区和排序。 - Define patterns of rows to seek using the PATTERN clause. These patterns use a syntax similar to that of regular expressions.
使用PATTERN子句定义要查找的行的模式。这些模式使用与正则表达式类似的语法。 - The logical components of the row pattern variables are specified in the DEFINE clause.
行模式变量的逻辑组件在DEFINE子句中指定。 - Define measures, which are expressions usable in other parts of the SQL query, in the MEASURES clause.
在MEASURES子句中定义度量值,这些度量值是SQL查询的其他部分中可用的表达式。
The following example illustrates the syntax for basic pattern recognition:
以下示例说明了基本模式识别的语法:
SELECT T.aid, T.bid, T.cid
FROM MyTable
MATCH_RECOGNIZE (
PARTITION BY userid
ORDER BY proctime
MEASURES
A.id AS aid,
B.id AS bid,
C.id AS cid
PATTERN (A B C)
DEFINE
A AS name = 'a',
B AS name = 'b',
C AS name = 'c'
) AS T
This page will explain each keyword in more detail and will illustrate more complex examples.
本页将更详细地解释每个关键字,并将说明更复杂的示例。
Flink’s implementation of the MATCH_RECOGNIZE clause is a subset of the full standard. Only those features documented in the following sections are supported. Additional features may be supported based on community feedback, please also take a look at the known limitations.
Flink对MATCH_RECOGNIZE子句的实现是完整标准的子集。仅支持以下章节中记录的功能。根据社区反馈,可能会支持其他功能,请查看已知的限制。
Introduction and Examples
Installation Guide
The pattern recognition feature uses the Apache Flink’s CEP library internally. In order to be able to use the MATCH_RECOGNIZE clause, the library needs to be added as a dependency to your Maven project.
模式识别功能在内部使用Apache Flink的CEP库。为了能够使用MATCH_RECOGNIZE子句,需要将库作为依赖项添加到Maven项目中。
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-cep</artifactId>
<version>1.15.2</version>
</dependency>
Alternatively, you can also add the dependency to the cluster classpath (see the dependency section for more information).
或者,您也可以将依赖项添加到集群类路径(有关详细信息,请参见依赖项部分)。
If you want to use the MATCH_RECOGNIZE clause in the SQL Client, you don’t have to do anything as all the dependencies are included by default.
如果要在SQL客户端中使用MATCH_RECOGNIZE子句,则无需执行任何操作,因为默认情况下包含所有依赖项。
SQL Semantics
Every MATCH_RECOGNIZE query consists of the following clauses:
每个MATCH_RECOGNIZE查询都包含以下子句:
- PARTITION BY - defines the logical partitioning of the table; similar to a GROUP BY operation.
PARTITION BY - 定义表的逻辑分区;类似于GROUP BY操作。 - ORDER BY - specifies how the incoming rows should be ordered; this is essential as patterns depend on an order.
ORDER BY -指定传入行的排序方式;这是至关重要的,因为模式取决于顺序。 - MEASURES - defines output of the clause; similar to a SELECT clause.
MEASURES -定义语句的输出;类似于SELECT子句。 - ONE ROW PER MATCH - output mode which defines how many rows per match should be produced.
ONE ROW PER MATCH - 输出模式,定义每个匹配应该产生多少行。 - AFTER MATCH SKIP - specifies where the next match should start; this is also a way to control how many distinct matches a single event can belong to.
AFTER MATCH SKIP - 指定下一个匹配的开始位置;这也是一种控制单个事件可以属于多少不同匹配的方法。 - PATTERN - allows constructing patterns that will be searched for using a regular expression-like syntax.
PATTERN - 允许构建类似正则表达式的语法进行搜索的模式。 - DEFINE - this section defines the conditions that the pattern variables must satisfy.
DEFINE - 定义模式变量必须满足的条件。
Attention Currently, the MATCH_RECOGNIZE clause can only be applied to an append table. Furthermore, it always produces an append table as well.
注意目前,MATCH_RECOGNIZE子句只能应用于追加表。此外,它还总是生成一个追加表。
Examples
For our examples, we assume that a table Ticker has been registered. The table contains prices of stocks at a particular point in time.
对于我们的示例,我们假设表Ticker已经注册。该表包含特定时间点的股票价格
The table has a following schema:
该表具有以下schema:
Ticker
|-- symbol: String # symbol of the stock 股票的符号
|-- price: Long # price of the stock
|-- tax: Long # tax liability of the stock 股票的纳税义务
|-- rowtime: TimeIndicatorTypeInfo(rowtime) # point in time when the change to those values happened
For simplification, we only consider the incoming data for a single stock ACME. A ticker could look similar to the following table where rows are continuously appended.
为了简化,我们只考虑单个股票ACME的传入数据。股票价格报收机可能类似于下表,其中行被持续追加。
symbol rowtime price tax
====== ==================== ======= =======
'ACME' '01-Apr-11 10:00:00' 12 1
'ACME' '01-Apr-11 10:00:01' 17 2
'ACME' '01-Apr-11 10:00:02' 19 1
'ACME' '01-Apr-11 10:00:03' 21 3
'ACME' '01-Apr-11 10:00:04' 25 2
'ACME' '01-Apr-11 10:00:05' 18 1
'ACME' '01-Apr-11 10:00:06' 15 1
'ACME' '01-Apr-11 10:00:07' 14 2
'ACME' '01-Apr-11 10:00:08' 24 2
'ACME' '01-Apr-11 10:00:09' 25 2
'ACME' '01-Apr-11 10:00:10' 19 1
The task is now to find periods of a constantly decreasing price of a single ticker. For this, one could write a query like:
现在的任务是找到一个股票价格不断下降的时期。为此,可以编写如下查询:
SELECT *
FROM Ticker
MATCH_RECOGNIZE (
PARTITION BY symbol
ORDER BY rowtime
MEASURES
START_ROW.rowtime AS start_tstamp,
LAST(PRICE_DOWN.rowtime) AS bottom_tstamp,
LAST(PRICE_UP.rowtime) AS end_tstamp
ONE ROW PER MATCH
AFTER MATCH SKIP TO LAST PRICE_UP
PATTERN (START_ROW PRICE_DOWN+ PRICE_UP)
DEFINE
PRICE_DOWN AS
(LAST(PRICE_DOWN.price, 1) IS NULL AND PRICE_DOWN.price < START_ROW.price) OR
PRICE_DOWN.price < LAST(PRICE_DOWN.price, 1),
PRICE_UP AS
PRICE_UP.price > LAST(PRICE_DOWN.price, 1)
) MR;
The query partitions the Ticker table by the symbol column and orders it by the rowtime time attribute.
该查询按symbol列对Ticker表进行分区,并按行时间属性对其排序。
The PATTERN clause specifies that we are interested in a pattern with a starting event START_ROW that is followed by one or more PRICE_DOWN events and concluded with a PRICE_UP event. If such a pattern can be found, the next pattern match will be seeked at the last PRICE_UP event as indicated by the AFTER MATCH SKIP TO LAST clause.
PATTERN子句指定我们对一个模式感兴趣,该模式有一个起始事件START_ROW,其后是一个或多个PRICE_DOWN事件,并以PRICE_UP事件结束。如果可以找到这样的模式,下一个模式匹配将会在AFTER MATCH SKIP TO LAST子句所示的最后一个PRICE_UP事件上被找到。
The DEFINE clause specifies the conditions that need to be met for a PRICE_DOWN and PRICE_UP event. Although the START_ROW pattern variable is not present it has an implicit condition that is evaluated always as TRUE.
DEFINE子句指定PRICE_DOWN和PRICE_UP事件需要满足的条件。尽管START_ROW模式变量不存在,但它有一个隐式条件,其求值始终为TRUE。
A pattern variable PRICE_DOWN is defined as a row with a price that is smaller than the price of the last row that met the PRICE_DOWN condition. For the initial case or when there is no last row that met the PRICE_DOWN condition, the price of the row should be smaller than the price of the preceding row in the pattern (referenced by START_ROW).
模式变量PRICE_DOWN定义为价格小于满足PRICE_ DOWN条件的最后一行的价格的行。对于初始情况,或者当没有满足PRICE_DOWN条件的最后一行时,该行的价格应该小于模式中前一行的价格(由START_ROW引用)。
A pattern variable PRICE_UP is defined as a row with a price that is larger than the price of the last row that met the PRICE_DOWN condition.
模式变量PRICE_UP定义为价格大于满足PRICE_DOWN条件的最后一行的价格的行。
This query produces a summary row for each period in which the price of a stock was continuously decreasing.
此查询为股票价格持续下降的每个期间生成一个摘要行。
The exact representation of the output rows is defined in the MEASURES part of the query. The number of output rows is defined by the ONE ROW PER MATCH output mode.
输出行的精确表示在查询的MEASURES部分中定义。输出行数由“ONE ROW PER MATCH”输出模式定义。
symbol start_tstamp bottom_tstamp end_tstamp
========= ================== ================== ==================
ACME 01-APR-11 10:00:04 01-APR-11 10:00:07 01-APR-11 10:00:08
The resulting row describes a period of falling prices that started at 01-APR-11 10:00:04 and achieved the lowest price at 01-APR-11 10:00:07 that increased again at 01-APR-11 10:00:08.
结果行描述了从2011年4月1日10:00:04开始的一段价格下跌时期,并在2011年4月1日的10:00:07达到最低价格,之后在2011年4月1日的10:00:08再次上涨。
Partitioning
It is possible to look for patterns in partitioned data, e.g., trends for a single ticker or a particular user. This can be expressed using the PARTITION BY clause. The clause is similar to using GROUP BY for aggregations.
可以在分区数据中查找模式,例如,单个股票或特定用户的趋势。这可以使用PARTITION BY子句来表示。该子句类似于使用GROUP BY进行聚合。
It is highly advised to partition the incoming data because otherwise the MATCH_RECOGNIZE clause will be translated into a non-parallel operator to ensure global ordering.
强烈建议对传入数据进行分区,否则MATCH_RECOGNIZE子句将被转换为非并行运算符,以确保全局排序。
Order of Events
Apache Flink allows for searching for patterns based on time; either processing time or event time.
Apache Flink允许基于时间的搜索模式;处理时间或事件时间。
In case of event time, the events are sorted before they are passed to the internal pattern state machine. As a consequence, the produced output will be correct regardless of the order in which rows are appended to the table. Instead, the pattern is evaluated in the order specified by the time contained in each row.
在事件时间的情况下,在将事件传递到内部模式状态机之前,会对事件进行排序。因此,无论行被附加到表中的顺序如何,生成的输出都是正确的。相反,将按照每行中包含的时间指定的顺序计算模式。
The MATCH_RECOGNIZE clause assumes a time attribute with ascending ordering as the first argument to ORDER BY clause.
MATCH_RECOGNIZE子句假定时间属性以升序作为ORDER BY子句的第一个参数。
For the example Ticker table, a definition like ORDER BY rowtime ASC, price DESC is valid but ORDER BY price, rowtime or ORDER BY rowtime DESC, price ASC is not.
对于示例Ticker表,定义如ORDER BY rowtime ASC, price DESC有效,但ORDER BY price, rowtime or ORDER BY rowtime DESC, price ASC无效。
Define & Measures
The DEFINE and MEASURES keywords have similar meanings to the WHERE and SELECT clauses in a simple SQL query.
DEFINE和MEASURES关键字与简单SQL查询中的WHERE和SELECT子句具有相似的含义。
The MEASURES clause defines what will be included in the output of a matching pattern. It can project columns and define expressions for evaluation. The number of produced rows depends on the output mode setting.
MEASURES子句定义了匹配模式输出中包含的内容。它可以投影列并定义表达式以进行计算。生成的行数取决于输出模式设置。
The DEFINE clause specifies conditions that rows have to fulfill in order to be classified to a corresponding pattern variable. If a condition is not defined for a pattern variable, a default condition will be used which evaluates to true for every row.
DEFINE子句指定了行必须满足的条件,才能被分类到相应的模式变量。如果没有为模式变量定义条件,则将使用默认条件,该条件对每一行的求值都为true。
For a more detailed explanation about expressions that can be used in those clauses, please have a look at the event stream navigation section.
有关可以在这些子句中使用的表达式的更详细解释,请查看事件流导航部分。
Aggregations
Aggregations can be used in DEFINE and MEASURES clauses. Both built-in and custom user defined functions are supported.
聚合可以用在DEFINE和MEASURES子句中。支持内置和自定义用户定义函数。
Aggregate functions are applied to each subset of rows mapped to a match. In order to understand how those subsets are evaluated have a look at the event stream navigation section.
聚合函数应用于映射到匹配的行的每个子集。为了了解如何评估这些子集,请查看事件流导航部分。
The task of the following example is to find the longest period of time for which the average price of a ticker did not go below certain threshold. It shows how expressible MATCH_RECOGNIZE can become with aggregations. This task can be performed with the following query:
下面的例子的任务是找出一个股票收报机的平均价格没有低于某个阈值的最长时间段。它展示了MATCH_RECOGNIZE在聚合中的可表达性。可以使用以下查询执行此任务:
SELECT *
FROM Ticker
MATCH_RECOGNIZE (
PARTITION BY symbol
ORDER BY rowtime
MEASURES
FIRST(A.rowtime) AS start_tstamp,
LAST(A.rowtime) AS end_tstamp,
AVG(A.price) AS avgPrice
ONE ROW PER MATCH
AFTER MATCH SKIP PAST LAST ROW
PATTERN (A+ B)
DEFINE
A AS AVG(A.price) < 15
) MR;
Given this query and following input values:
给定此查询和以下输入值:
symbol rowtime price tax
====== ==================== ======= =======
'ACME' '01-Apr-11 10:00:00' 12 1
'ACME' '01-Apr-11 10:00:01' 17 2
'ACME' '01-Apr-11 10:00:02' 13 1
'ACME' '01-Apr-11 10:00:03' 16 3
'ACME' '01-Apr-11 10:00:04' 25 2
'ACME' '01-Apr-11 10:00:05' 2 1
'ACME' '01-Apr-11 10:00:06' 4 1
'ACME' '01-Apr-11 10:00:07' 10 2
'ACME' '01-Apr-11 10:00:08' 15 2
'ACME' '01-Apr-11 10:00:09' 25 2
'ACME' '01-Apr-11 10:00:10' 25 1
'ACME' '01-Apr-11 10:00:11' 30 1
The query will accumulate events as part of the pattern variable A as long as the average price of them does not exceed 15. For example, such a limit exceeding happens at 01-Apr-11 10:00:04. The following period exceeds the average price of 15 again at 01-Apr-11 10:00:11. Thus the results for said query will be:
只要事件的平均价格不超过15,查询将累积事件作为模式变量A的一部分。例如,这种超出限制的情况发生在2011年4月1日10:00:04。以下时段在2011年4月1日的10:00:11再次超过15的平均价格。因此,所述查询的结果将是:
symbol start_tstamp end_tstamp avgPrice
========= ================== ================== ============
ACME 01-APR-11 10:00:00 01-APR-11 10:00:03 14.5
ACME 01-APR-11 10:00:05 01-APR-11 10:00:10 13.5
Aggregations can be applied to expressions, but only if they reference a single pattern variable. Thus SUM(A.price * A.tax) is a valid one, but AVG(A.price * B.tax) is not.
聚合可以应用于表达式,但仅当它们引用单个模式变量时。因此,SUM(A.price * A.tax)是有效的,而AVG(A.price * B.tax)则不是。
DISTINCT aggregations are not supported.不支持DISTINCT聚合。
Defining a Pattern
The MATCH_RECOGNIZE clause allows users to search for patterns in event streams using a powerful and expressive syntax that is somewhat similar to the widespread regular expression syntax.
MATCH_RECOGNIZE子句允许用户使用功能强大且富有表现力的语法来搜索事件流中的模式,该语法与广泛使用的正则表达式语法有些相似。
Every pattern is constructed from basic building blocks, called pattern variables, to which operators (quantifiers and other modifiers) can be applied. The whole pattern must be enclosed in brackets.
每个模式都是由称为模式变量的基本构建块构建的,可以对其应用运算符(量词和其他修饰符)。整个模式必须用括号括起来。
An example pattern could look like:
示例模式如下:
PATTERN (A B+ C* D)
One may use the following operators:
可以使用以下运算符:
- Concatenation - a pattern like (A B) means that the contiguity is strict between A and B. Therefore, there can be no rows that were not mapped to A or B in between.
串联 - 类似(A B)的模式意味着A和B之间的连续性是严格的。因此,其中不可能存在未映射到A或B的行。 - Quantifiers - modify the number of rows that can be mapped to the pattern variable. 量词-修改可以映射到模式变量的行数。
* — 0 or more rows
+ — 1 or more rows
? — 0 or 1 rows
{ n } — exactly n rows (n > 0)
{ n, } — n or more rows (n ≥ 0)
{ n, m } — between n and m (inclusive) rows (0 ≤ n ≤ m, 0 < m)
{ , m } — between 0 and m (inclusive) rows (m > 0)
Patterns that can potentially produce an empty match are not supported. Examples of such patterns are PATTERN (A*), PATTERN (A? B*), PATTERN (A{0,} B{0,} C*), etc.
不支持可能产生空匹配的模式。这种模式的示例是PATTERN (A*), PATTERN (A? B*), PATTERN (A{0,} B{0,} C*)等。
Greedy & Reluctant Quantifiers 贪婪与不情愿量词
Each quantifier can be either greedy (default behavior) or reluctant. Greedy quantifiers try to match as many rows as possible while reluctant quantifiers try to match as few as possible.
每个量词可以是贪婪的(默认行为),也可以是不情愿的。贪婪的量词试图匹配尽可能多的行,而不情愿的量词尝试匹配尽可能少的行。
In order to illustrate the difference, one can view the following example with a query where a greedy quantifier is applied to the B variable:
为了说明差异,可以通过查询查看以下示例,其中贪婪量词应用于B变量:
SELECT *
FROM Ticker
MATCH_RECOGNIZE(
PARTITION BY symbol
ORDER BY rowtime
MEASURES
C.price AS lastPrice
ONE ROW PER MATCH
AFTER MATCH SKIP PAST LAST ROW
PATTERN (A B* C)
DEFINE
A AS A.price > 10,
B AS B.price < 15,
C AS C.price > 12
)
Given we have the following input:
鉴于我们有以下输入:
symbol tax price rowtime
======= ===== ======== =====================
XYZ 1 10 2018-09-17 10:00:02
XYZ 2 11 2018-09-17 10:00:03
XYZ 1 12 2018-09-17 10:00:04
XYZ 2 13 2018-09-17 10:00:05
XYZ 1 14 2018-09-17 10:00:06
XYZ 2 16 2018-09-17 10:00:07
The pattern above will produce the following output:
上述模式将产生以下输出:
symbol lastPrice
======== ===========
XYZ 16
The same query where B* is modified to B*?, which means that B* should be reluctant, will produce:
将B*修改为B*?的相同查询?,这意味着B*应该是不情愿的
symbol lastPrice
======== ===========
XYZ 13
XYZ 16
The pattern variable B matches only to the row with price 12 instead of swallowing the rows with prices 12, 13, and 14.
模式变量B仅匹配价格为12的行,而不是吞下价格为12、13和14的行。
It is not possible to use a greedy quantifier for the last variable of a pattern. Thus, a pattern like (A B*) is not allowed. This can be easily worked around by introducing an artificial state (e.g. C) that has a negated condition of B. So you could use a query like:
不可能对模式的最后一个变量使用贪婪的量词。因此,不允许类似 (A B*)的模式。通过引入一个具有否定条件B的人工状态(例如C),可以很容易地解决这个问题。因此,可以使用如下查询:
PATTERN (A B* C)
DEFINE
A AS condA(),
B AS condB(),
C AS NOT condB()
Attention The optional reluctant quantifier (A?? or A{0,1}?) is not supported right now.
注意可选的不情愿量词 (A?? or A{0,1}?)目前不支持。
Time constraint 时间限制
Especially for streaming use cases, it is often required that a pattern finishes within a given period of time. This allows for limiting the overall state size that Flink has to maintain internally, even in case of greedy quantifiers.
特别是对于流式用例,通常要求模式在给定的时间段内完成。这允许限制Flink必须在内部维护的总体状态大小,即使是贪婪的量词。
Therefore, Flink SQL supports the additional (non-standard SQL) WITHIN clause for defining a time constraint for a pattern. The clause can be defined after the PATTERN clause and takes an interval of millisecond resolution.
因此,Flink SQL支持额外的(非标准SQL)WITHIN子句来定义模式的时间约束。该子句可以在PATTERN子句之后定义,并采用毫秒分辨率的间隔。
If the time between the first and last event of a potential match is longer than the given value, such a match will not be appended to the result table.
如果潜在匹配的第一个和最后一个事件之间的时间长于给定值,则不会将此类匹配附加到结果表中。
Note It is generally encouraged to use the WITHIN clause as it helps Flink with efficient memory management. Underlying state can be pruned once the threshold is reached.
注意:通常建议使用WITHIN子句,因为它有助于Flink进行有效的内存管理。一旦达到阈值,就可以修剪基础状态。
Attention However, the WITHIN clause is not part of the SQL standard. The recommended way of dealing with time constraints might change in the future.
注意然而,WITHIN子句不是SQL标准的一部分。建议的处理时间限制的方法将来可能会改变。
The use of the WITHIN clause is illustrated in the following example query:
以下示例查询中说明了WITHIN子句的用法:
SELECT *
FROM Ticker
MATCH_RECOGNIZE(
PARTITION BY symbol
ORDER BY rowtime
MEASURES
C.rowtime AS dropTime,
A.price - C.price AS dropDiff
ONE ROW PER MATCH
AFTER MATCH SKIP PAST LAST ROW
PATTERN (A B* C) WITHIN INTERVAL '1' HOUR
DEFINE
B AS B.price > A.price - 10,
C AS C.price < A.price - 10
)
The query detects a price drop of 10 that happens within an interval of 1 hour.
查询检测到在1小时间隔内发生的价格下降10。
Let’s assume the query is used to analyze the following ticker data:
让我们假设该查询用于分析以下股票数据:
symbol rowtime price tax
====== ==================== ======= =======
'ACME' '01-Apr-11 10:00:00' 20 1
'ACME' '01-Apr-11 10:20:00' 17 2
'ACME' '01-Apr-11 10:40:00' 18 1
'ACME' '01-Apr-11 11:00:00' 11 3
'ACME' '01-Apr-11 11:20:00' 14 2
'ACME' '01-Apr-11 11:40:00' 9 1
'ACME' '01-Apr-11 12:00:00' 15 1
'ACME' '01-Apr-11 12:20:00' 14 2
'ACME' '01-Apr-11 12:40:00' 24 2
'ACME' '01-Apr-11 13:00:00' 1 2
'ACME' '01-Apr-11 13:20:00' 19 1
The query will produce the following results:
查询将产生以下结果:
symbol dropTime dropDiff
====== ==================== =============
'ACME' '01-Apr-11 13:00:00' 14
The resulting row represents a price drop from 15 (at 01-Apr-11 12:00:00) to 1 (at 01-Apr-11 13:00:00). The dropDiff column contains the price difference.
结果行表示价格从15 (at 01-Apr-11 12:00:00)下降到1 (at 01-Apr-11 13:00:00)。dropDiff列包含价差。
Notice that even though prices also drop by higher values, for example, by 11 (between 01-Apr-11 10:00:00 and 01-Apr-11 11:40:00), the time difference between those two events is larger than 1 hour. Thus, they don’t produce a match.
请注意,尽管价格也下降了更高的值,例如,下降了11 (between 01-Apr-11 10:00:00 and 01-Apr-11 11:40:00),但这两个事件之间的时间差大于1小时。因此,它们不会产生匹配项。
Output Mode
The output mode describes how many rows should be emitted for every found match. The SQL standard describes two modes:
输出模式描述了对于每个找到的匹配应该发出多少行。SQL标准描述了两种模式:
- ALL ROWS PER MATCH
每个匹配的所有行 - ONE ROW PER MATCH.
每个匹配一行。
Currently, the only supported output mode is ONE ROW PER MATCH that will always produce one output summary row for each found match.
目前,唯一支持的输出模式是ONE ROW PER MATCH,它将始终为每个找到的匹配生成一个输出摘要行。
The schema of the output row will be a concatenation of [partitioning columns] + [measures columns] in that particular order.
输出行的模式将是按特定顺序的[partitioning columns] + [measures columns]的串联。
The following example shows the output of a query defined as:
以下示例显示了定义的查询的输出:
SELECT *
FROM Ticker
MATCH_RECOGNIZE(
PARTITION BY symbol
ORDER BY rowtime
MEASURES
FIRST(A.price) AS startPrice,
LAST(A.price) AS topPrice,
B.price AS lastPrice
ONE ROW PER MATCH
PATTERN (A+ B)
DEFINE
A AS LAST(A.price, 1) IS NULL OR A.price > LAST(A.price, 1),
B AS B.price < LAST(A.price)
)
For the following input rows:
对于以下输入行:
symbol tax price rowtime
======== ===== ======== =====================
XYZ 1 10 2018-09-17 10:00:02
XYZ 2 12 2018-09-17 10:00:03
XYZ 1 13 2018-09-17 10:00:04
XYZ 2 11 2018-09-17 10:00:05
The query will produce the following output:
查询将生成以下输出:
symbol startPrice topPrice lastPrice
======== ============ ========== ===========
XYZ 10 13 11
The pattern recognition is partitioned by the symbol column. Even though not explicitly mentioned in the MEASURES clause, the partitioned column is added at the beginning of the result.
模式识别由symbol列分区。尽管在MEASURES子句中没有明确提及,但分区列还是添加在结果的开头。
Pattern Navigation 模式航行
The DEFINE and MEASURES clauses allow for navigating within the list of rows that (potentially) match a pattern.
DEFINE和MEASURES子句允许在(可能)匹配模式的行列表中航行。
This section discusses this navigation for declaring conditions or producing output results.
本节讨论用于声明条件或生成输出结果的航行。
Pattern Variable Referencing
A pattern variable reference allows a set of rows mapped to a particular pattern variable in the DEFINE or MEASURES clauses to be referenced.
模式变量引用允许引用一组映射到DEFINE或MEASURES子句中特定模式变量的行。
For example, the expression A.price describes a set of rows mapped so far to A plus the current row if we try to match the current row to A. If an expression in the DEFINE/MEASURES clause requires a single row (e.g. A.price or A.price > 10), it selects the last value belonging to the corresponding set.
例如,如果我们试图将当前行与A匹配,表达式A.price描述了一组映射到A的行加上当前行。如果DEFINE/MEAURES子句中的表达式需要单行(例如A.price或A.price>10),它将选择属于相应集合的最后一个值。
If no pattern variable is specified (e.g. SUM(price)), an expression references the default pattern variable * which references all variables in the pattern. In other words, it creates a list of all the rows mapped so far to any variable plus the current row.
如果未指定模式变量(e.g. SUM(price)),表达式将引用默认模式变量*,该变量引用模式中的所有变量。换句话说,它创建了一个列表,其中包含迄今为止映射到任何变量的所有行以及当前行。
Example
For a more thorough example, one can take a look at the following pattern and corresponding conditions:
对于更彻底的示例,可以查看以下模式和相应的条件:
PATTERN (A B+)
DEFINE
A AS A.price >= 10,
B AS B.price > A.price AND SUM(price) < 100 AND SUM(B.price) < 80
The following table describes how those conditions are evaluated for each incoming event.
下表描述了如何为每个传入事件评估这些条件。
The table consists of the following columns:
该表由以下列组成:
- # - the row identifier that uniquely identifies an incoming row in the lists [A.price]/[B.price]/[price].
#-[A.price]/[B.price]/[price]列表中输入行的唯一行标识符。 - price - the price of the incoming row.
price-传入行的价格。 - [A.price]/[B.price]/[price] - describe lists of rows which are used in the DEFINE clause to evaluate conditions.
[A.price]/[B.price]/[price]-描述DEFINE子句中用于评估条件的行列表。 - Classifier - the classifier of the current row which indicates the pattern variable the row is mapped to.
分类器-当前行的分类器,指示该行映射到的模式变量。 - A.price/B.price/SUM(price)/SUM(B.price) - describes the result after those expressions have been evaluated.
A.price/B.price/SUM(price)/SUM(B.price) - 描述这些表达式求值后的结果。
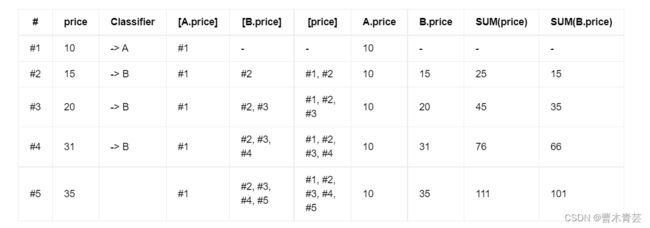
As can be seen in the table, the first row is mapped to pattern variable A and subsequent rows are mapped to pattern variable B. However, the last row does not fulfill the B condition because the sum over all mapped rows SUM(price) and the sum over all rows in B exceed the specified thresholds.
如表所示,第一行映射到模式变量A,随后的行映射到模式变量B。但是,最后一行不满足B条件,因为所有映射行的总和SUM(price)和B中所有行的总和超过了指定的阈值。
Logical Offsets
Logical offsets enable navigation within the events that were mapped to a particular pattern variable. This can be expressed with two corresponding functions:
逻辑偏移允许在映射到特定模式变量的事件中航行。这可以用两个相应的函数表示:
| Offset functions | Description |
|---|---|
| LAST(variable.field, n) | Returns the value of the field from the event that was mapped to the n-th last element of the variable. The counting starts at the last element mapped. 返回映射到变量最后第n个元素的事件的字段值。计数从映射的最后一个元素开始。 |
| FIRST(variable.field, n) | Returns the value of the field from the event that was mapped to the n-th element of the variable. The counting starts at the first element mapped. 返回映射到变量第n个元素的事件的字段值。计数从映射的第一个元素开始。 |
Examples
For a more thorough example, one can take a look at the following pattern and corresponding conditions:
对于更彻底的示例,可以查看以下模式和相应的条件:
PATTERN (A B+)
DEFINE
A AS A.price >= 10,
B AS (LAST(B.price, 1) IS NULL OR B.price > LAST(B.price, 1)) AND
(LAST(B.price, 2) IS NULL OR B.price > 2 * LAST(B.price, 2))
The following table describes how those conditions are evaluated for each incoming event.
下表描述了如何为每个传入事件评估这些条件。
The table consists of the following columns:
该表由以下列组成:
- price - the price of the incoming row.
price-传入行的价格。 - Classifier - the classifier of the current row which indicates the pattern variable the row is mapped to.
分类器-当前行的分类器,指示该行映射到的模式变量。 - LAST(B.price, 1)/LAST(B.price, 2) - describes the result after those expressions have been evaluated.
LAST(B.price, 1)/LAST(B.price, 2) - 描述这些表达式计算后的结果。

It might also make sense to use the default pattern variable with logical offsets.
使用带有逻辑偏移的默认模式变量也可能有意义。
In this case, an offset considers all the rows mapped so far:
在这种情况下,偏移量考虑到迄今为止映射的所有行:
PATTERN (A B? C)
DEFINE
B AS B.price < 20,
C AS LAST(price, 1) < C.price
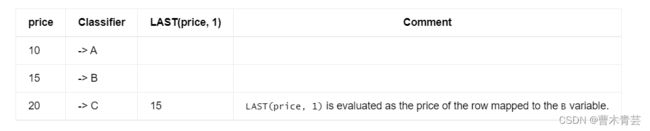
If the second row did not map to the B variable, we would have the following results:
如果第二行没有映射到B变量,我们将得到以下结果:

It is also possible to use multiple pattern variable references in the first argument of the FIRST/LAST functions. This way, one can write an expression that accesses multiple columns. However, all of them must use the same pattern variable. In other words, the value of the LAST/FIRST function must be computed in a single row.
也可以在FIRST/LAST函数的第一个参数中使用多个模式变量引用。这样,可以编写访问多个列的表达式。但是,它们都必须使用相同的模式变量。换句话说,LAST/FIRST函数的值必须在一行中计算。
Thus, it is possible to use LAST(A.price * A.tax), but an expression like LAST(A.price * B.tax) is not allowed.
因此,可以使用LAST(A.price * A.tax),但不允许使用类似LAST(A.price * B.tax)的表达式。
After Match Strategy
The AFTER MATCH SKIP clause specifies where to start a new matching procedure after a complete match was found.
AFTER MATCH SKIP子句指定在找到完全匹配后在何处开始新的匹配过程。
There are four different strategies:
有四种不同的策略:
- SKIP PAST LAST ROW - resumes the pattern matching at the next row after the last row of the current match.
SKIP PAST LAST ROW - 在当前匹配的最后一行之后的下一行恢复模式匹配。 - SKIP TO NEXT ROW - continues searching for a new match starting at the next row after the starting row of the match.
SKIP TO NEXT ROW - 继续搜索从匹配开始行后的下一行开始的新的匹配。 - SKIP TO LAST variable - resumes the pattern matching at the last row that is mapped to the specified pattern variable.
SKIP TO LAST variable - 在映射到指定模式变量的最后一行恢复模式匹配。 - SKIP TO FIRST variable - resumes the pattern matching at the first row that is mapped to the specified pattern variable.
SKIP TO FIRST variable - 在映射到指定模式变量的第一行的恢复模式匹配。
This is also a way to specify how many matches a single event can belong to. For example, with the SKIP PAST LAST ROW strategy every event can belong to at most one match.
这也是一种指定单个事件可以属于多少场匹配的方法。例如,使用“SKIP PAST LAST ROW”策略,每个事件最多只能属于一场匹配。
Examples
In order to better understand the differences between those strategies one can take a look at the following example.
为了更好地理解这些策略之间的差异,我们可以看看下面的例子。
For the following input rows:
对于以下输入行:
symbol tax price rowtime
======== ===== ======= =====================
XYZ 1 7 2018-09-17 10:00:01
XYZ 2 9 2018-09-17 10:00:02
XYZ 1 10 2018-09-17 10:00:03
XYZ 2 5 2018-09-17 10:00:04
XYZ 2 10 2018-09-17 10:00:05
XYZ 2 7 2018-09-17 10:00:06
XYZ 2 14 2018-09-17 10:00:07
We evaluate the following query with different strategies:
我们使用不同的策略评估以下查询:
SELECT *
FROM Ticker
MATCH_RECOGNIZE(
PARTITION BY symbol
ORDER BY rowtime
MEASURES
SUM(A.price) AS sumPrice,
FIRST(rowtime) AS startTime,
LAST(rowtime) AS endTime
ONE ROW PER MATCH
[AFTER MATCH STRATEGY]
PATTERN (A+ C)
DEFINE
A AS SUM(A.price) < 30
)
The query returns the sum of the prices of all rows mapped to A and the first and last timestamp of the overall match.
查询返回映射到A的所有行的价格之和以及整个匹配的第一个和最后一个时间戳。
The query will produce different results based on which AFTER MATCH strategy was used:
根据使用的AFTER MATCH策略,查询将产生不同的结果:
AFTER MATCH SKIP PAST LAST ROW #
symbol sumPrice startTime endTime
======== ========== ===================== =====================
XYZ 26 2018-09-17 10:00:01 2018-09-17 10:00:04
XYZ 17 2018-09-17 10:00:05 2018-09-17 10:00:07
The first result matched against the rows #1, #2, #3, #4.
第一个结果与行#1、#2、#3、#4匹配。
The second result matched against the rows #5, #6, #7.
第二个结果与行#5、#6、#7匹配。
AFTER MATCH SKIP TO NEXT ROW #
symbol sumPrice startTime endTime
======== ========== ===================== =====================
XYZ 26 2018-09-17 10:00:01 2018-09-17 10:00:04
XYZ 24 2018-09-17 10:00:02 2018-09-17 10:00:05
XYZ 25 2018-09-17 10:00:03 2018-09-17 10:00:06
XYZ 22 2018-09-17 10:00:04 2018-09-17 10:00:07
XYZ 17 2018-09-17 10:00:05 2018-09-17 10:00:07
Again, the first result matched against the rows #1, #2, #3, #4.
同样,第一个结果与行#1、#2、#3、#4匹配。
Compared to the previous strategy, the next match includes row #2 again for the next matching. Therefore, the second result matched against the rows #2, #3, #4, #5.
与之前的策略相比,下一个匹配再次包括第2行,用于下一个搜索。因此,第二个结果与行#2、#3、#4、#5匹配。
The third result matched against the rows #3, #4, #5, #6.
第三个结果与行#3、#4、#5、#6匹配。
The forth result matched against the rows #4, #5, #6, #7.
第四个结果与行#4、#5、#6、#7匹配。
The last result matched against the rows #5, #6, #7.
最后一个结果与行#5、#6、#7匹配。
AFTER MATCH SKIP TO LAST A #
symbol sumPrice startTime endTime
======== ========== ===================== =====================
XYZ 26 2018-09-17 10:00:01 2018-09-17 10:00:04
XYZ 25 2018-09-17 10:00:03 2018-09-17 10:00:06
XYZ 17 2018-09-17 10:00:05 2018-09-17 10:00:07
Again, the first result matched against the rows #1, #2, #3, #4.
同样,第一个结果与行#1、#2、#3、#4匹配。
Compared to the previous strategy, the next match includes only row #3 (mapped to A) again for the next matching. Therefore, the second result matched against the rows #3, #4, #5, #6.
与上一个策略相比,下一个匹配只包括第3行(映射到A),再次用于下一次匹配。因此,第二个结果与行#3、#4、#5、#6匹配。
The last result matched against the rows #5, #6, #7.
最后一个结果与行#5、#6、#7匹配。
AFTER MATCH SKIP TO FIRST A #
This combination will produce a runtime exception because one would always try to start a new match where the last one started. This would produce an infinite loop and, thus, is prohibited.
这种组合将产生运行时异常,因为总是会尝试在上一个匹配开始的地方开始新的匹配。这将产生无限循环,因此被禁止。
One has to keep in mind that in case of the SKIP TO FIRST/LAST variable strategy it might be possible that there are no rows mapped to that variable (e.g. for pattern A*). In such cases, a runtime exception will be thrown as the standard requires a valid row to continue the matching.
必须记住,在SKIP TO FIRST/LAST variable策略的情况下,可能没有映射到该变量的行(例如模式A*)。在这种情况下,将引发runtime异常,因为标准要求存在有效行才能继续匹配。
Time attributes
In order to apply some subsequent queries on top of the MATCH_RECOGNIZE it might be required to use time attributes. To select those there are available two functions:
为了在MATCH_RECOGNIZE之上应用一些后续查询,可能需要使用时间属性。要选择这些功能,有两个可用功能:
| Function | Description |
|---|---|
| MATCH_ROWTIME([rowtime_field]) | Returns the timestamp of the last row that was mapped to the given pattern. The function accepts zero or one operand which is a field reference with rowtime attribute. If there is no operand, the function will return rowtime attribute with TIMESTAMP type. Otherwise, the return type will be same with the operand type. The resulting attribute is a rowtime attribute that can be used in subsequent time-based operations such as interval joins and group window or over window aggregations. 返回映射到给定模式的最后一行的时间戳。该函数接受零个或一个操作数,该操作数是具有rowtime属性的字段引用。如果没有操作数,函数将返回TIMESTAMP类型的rowtime属性。另外,返回类型将与操作数类型相同。生成的属性是一个rowtime属性,可用于后续基于时间的操作,如间隔联接和分组窗口或over窗口聚合。 |
| MATCH_PROCTIME() | Returns a proctime attribute that can be used in subsequent time-based operations such as interval joins and group window or over window aggregations. 返回一个proctime属性,该属性可用于后续基于时间的操作,如间隔联接和分组窗口或over窗口聚合。 |
Controlling Memory Consumption 控制内存消耗
Memory consumption is an important consideration when writing MATCH_RECOGNIZE queries, as the space of potential matches is built in a breadth-first-like manner. Having that in mind, one must make sure that the pattern can finish. Preferably with a reasonable number of rows mapped to the match as they have to fit into memory.
当编写MATCH_RECOGNIZE查询时,内存消耗是一个重要的考虑因素,因为潜在匹配的空间是以宽度优先的方式构建的。考虑到这一点,必须确保模式能够完成。最好有合理数量的行映射到匹配项,因为它们必须适合内存。
For example, the pattern must not have a quantifier without an upper limit that accepts every single row. Such a pattern could look like this:
例如,模式不能有没有接受每一行的上限的量词。这样的模式可能如下:
PATTERN (A B+ C)
DEFINE
A as A.price > 10,
C as C.price > 20
The query will map every incoming row to the B variable and thus will never finish. This query could be fixed, e.g., by negating the condition for C:
查询将把每个传入行映射到B变量,因此永远不会完成。这个查询可以被修复,例如,通过否定C的条件:
PATTERN (A B+ C)
DEFINE
A as A.price > 10,
B as B.price <= 20,
C as C.price > 20
Or by using the reluctant quantifier:
或者使用不情愿的量词:
PATTERN (A B+? C)
DEFINE
A as A.price > 10,
C as C.price > 20
Attention Please note that the MATCH_RECOGNIZE clause does not use a configured state retention time. One may want to use the WITHIN clause for this purpose.
注意请注意,MATCH_RECOGNIZE子句不使用配置的状态保留时间。为此,可能需要使用WITHIN子句。
Known Limitations
Flink’s implementation of the MATCH_RECOGNIZE clause is an ongoing effort, and some features of the SQL standard are not yet supported.
Flink对MATCH_RECOGNIZE子句的实现是一项持续的工作,SQL标准的一些特性还不受支持。
Unsupported features include:
不支持的功能包括:
- Pattern expressions:模式表达式:
** Pattern groups - this means that e.g. quantifiers can not be applied to a subsequence of the pattern. Thus, (A (B C)+) is not a valid pattern.
Pattern groups - 这意味着例如量词不能应用于模式的子序列。因此,(A (B C)+)不是有效的模式
** Alterations - patterns like PATTERN((A B | C D) E), which means that either a subsequence A B or C D has to be found before looking for the E row.
Alterations - 像PATTERN((A B | C D) E)这样的模式,这意味着在查找E行之前必须找到子序列AB或CD。
** PERMUTE operator - which is equivalent to all permutations of variables that it was applied to e.g. PATTERN (PERMUTE (A, B, C)) = PATTERN (A B C | A C B | B A C | B C A | C A B | C B A).
PERMUTE operator -它等效于应用于变量的所有排列,例如PATTERN (PERMUTE (A, B, C)) = PATTERN (A B C | A C B | B A C | B C A | C A B | C B A)。
** Anchors - ^, $, which denote beginning/end of a partition, those do not make sense in the streaming context and will not be supported.
Anchors - ^,$,表示分区的开始/结束,这些在流上下文中没有意义,也不受支持。
** Exclusion - PATTERN ({- A -} B) meaning that A will be looked for but will not participate in the output. This works only for the ALL ROWS PER MATCH mode.
Exclusion - PATTERN ({- A -} B)表示将查找A,但不会参与输出。这仅适用于ALL ROWS PER MATCH模式。
** Reluctant optional quantifier - PATTERN A?? only the greedy optional quantifier is supported.
不情愿的可选量词 - PATTERN A??只支持贪婪的可选量词。 - ALL ROWS PER MATCH output mode - which produces an output row for every row that participated in the creation of a found match. This also means: ALL ROWS PER MATCH output mode - 为参与创建找到的匹配的每一行生成一个输出行。这也意味着:
** that the only supported semantic for the MEASURES clause is FINAL
MEASURES子句唯一支持的语义是FINAL
** CLASSIFIER function, which returns the pattern variable that a row was mapped to, is not yet supported.
CLASSIFIER函数返回一行映射到的模式变量,但尚不受支持。 - SUBSET - which allows creating logical groups of pattern variables and using those groups in the DEFINE and MEASURES clauses.
SUBSET - 允许创建模式变量的逻辑组,并在DEFINE和MEASURES子句中使用这些组。 - Physical offsets - PREV/NEXT, which indexes all events seen rather than only those that were mapped to a pattern variable (as in logical offsets case).
物理偏移量-PREV/NEXT,它索引所有看到的事件,而不仅仅是映射到模式变量的事件(如逻辑偏移量情况)。 - Extracting time attributes - there is currently no possibility to get a time attribute for subsequent time-based operations.
提取时间属性-目前无法为后续基于时间的操作获取时间属性。 - MATCH_RECOGNIZE is supported only for SQL. There is no equivalent in the Table API.
仅SQL支持MATCH_RECOGNIZE。表API中没有等效项。 - Aggregations:
distinct aggregations are not supported.