datax 定时执行多个job_从DataX学插件式架构设计

前言
DataX是阿里巴巴开源的离线多数据源同步工具,被应用到阿里内部多个数据产品如Dataworks中。开源版本落后内部版本年余的时间,但是整体框架和思想没有变化。内部版本改进整体上属于锦上添花的功能,如修复了一些bug,提升了部分reader/writer的性能,支持流式数据统计的能力等。熟悉整套架构的思路和方法后,自己动手,丰衣足食,也按需增添自己的能力。
完整分析DataX代码实现不是一篇文章可以承载的,所以本文的思路在于学习方法论的东西。想象DataX面临的场景:实现从一个数据源导入到另一个数据源的流程。在不同环境里,这个流程在业务上是相似的(数据的抽取->处理->写入),但是细节上有差异。按照低内聚高耦合原则,设计者就要考虑将未来的变化点封装在独立的模块里,新需求不会对原来的代码有伤筋动骨的改动。于是就引出了“插件式”架构的概念,这个思想在浏览器如Chrome和IDE如Eclipse里广泛应用,因此得名。“插件”就是变化点,当使用者需要新功能的时候,只要下载并安装相应的插件,而不用下载一个新版本的浏览器或者IDE,应用本身就可以做的比较小,只包含必要的功能(Office系列就是个反例)。作为框架开发者,设计好插件格式,开发完几个常用的插件之后,就可以把精力放在框架性能和fix bug上,而不用被那些重复性质的“脏活累活”牵扯精力。
插件式架构设计,需要考虑的东西有
- 能力如何封装和暴露:对使用者,如何让他们简单的就可以使用datax的能力;对开发者,如何方便的接入框架,扩展能力。
- 边界在哪里:哪些能力由框架实现,哪些能力归插件实现的。
- 隔离性怎么做:如何将外部的能力接入到框架内部,同时不破坏框架的稳定性。
回到DataX,其设计思路是非常清晰的:首先是配置和逻辑分离,配置放在json文件里,启动的时候传给进程。配置分系统参数(core.json,plugin.json)和任务参数(job.json),系统参数可以被覆盖。进程启动式扫描配置和插件目录,加载相应的插件。其次,将逻辑分成reader/writer和框架两部分,read/writer是可以交出去的部分,也是变化点(异构数据源访问和数据处理),框架负责调度处理和流控。
开始分析
启动脚本分析
DataX以python脚本启动java进程的方式运行,相比shell方式,增大了运维负担,毕竟多数Linux主机需要额外安装python。
python bin/datax.py example.jsonexample.json里包含任务的配置,参见
{
"job": {
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"column": [],
"sliceRecordCount": ""
}
},
"writer": {
"name": "streamwriter",
"parameter": {
"encoding": "",
"print": true
}
}
}
],
"setting": {
"speed": {
"channel": ""
}
}
}
}启动脚本datax.py分析来看,其主要功能是:
- 准备配置参数
- 将配置参数作为启动参数传给java进程
前者在generateJobConfigTemplate里
def 解析json文件,并将其转成业务参数,传给java进程。
后者在buildStartCommand里,原始模版是
ENGINE_COMMAND = "java -server ${jvm} %s -classpath %s ${params} com.alibaba.datax.core.Engine -mode ${mode} -jobid ${jobid} -job ${job}" % (DEFAULT_PROPERTY_CONF, CLASS_PATH)可以看到是个经典的启动配置,入口主函数是com.alibaba.datax.core.Engine,对JVM默认参数不满意可以在启动的时候调整。
调试
datax的编译和调试十分友好:下载源码之后,本地编译,通过maven-assembly-plugin插件将结果输出到target/datax目录下。将datax.py里221行注释去掉,变成
print startCommand即可打印启动参数,配置文件是现成的。执行
python ./bin/datax.py ./job/job.json即可输出。本机输出如下:
'java -server -Xms1g -Xmx1g -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/Users//code/DataX/target/datax/datax/log
-Xms1g -Xmx1g -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/Users//code/DataX/target/datax/datax/log
-Dloglevel=info -Dfile.encoding=UTF-8 -Dlogback.statusListenerClass=ch.qos.logback.core.status.NopStatusListener
-Djava.security.egd=file:///dev/urandom -Ddatax.home=/Users//code/DataX/target/datax/datax
-Dlogback.configurationFile=/Users//code/DataX/target/datax/datax/conf/logback.xml -classpath
/Users//code/DataX/target/datax/datax/lib/*:. -Dlog.file.name=x_datax_job_job_json com.alibaba.datax.core.Engine
-mode standalone -jobid -1 -job /Users//code/DataX/target/datax/datax/job/job.json'上面几行是jvm启动参数(VM options),最后一行是程序启动参数(program arguments),将其配置在Intellij IDE的EditConfiguration里,再启动程序即可debug。
运行时分析
DataX的的概念和运行逻辑在 插件开发宝典 中有详细的描述,建议先读完文档再接着看。通过代码阅读,对其内容有更加深刻的认识,先看下几个概念:
- Job: Job是DataX用以描述从一个源头到一个目的端的同步作业,是DataX数据同步的最小业务单元。比如:从一张mysql的表同步到odps的一个表的特定分区。
- Task: Task是为最大化而把Job拆分得到的最小执行单元。比如:读一张有1024个分表的mysql分库分表的Job,拆分成1024个读Task,用若干个并发执行。
- TaskGroup: 描述的是一组Task集合。在同一个TaskGroupContainer执行下的Task集合称之为TaskGroup
- JobContainer: Job执行器,负责Job全局拆分、调度、前置语句和后置语句等工作的工作单元。类似Yarn中的JobTracker
- TaskGroupContainer: TaskGroup执行器,负责执行一组Task的工作单元。
程序入口是Engine类的main函数,接收的参数有任务配置,任务id和执行模式,entry函数里将系统参数与任务参数组合在一起。start函数进入JobContainer类,主要功能都在这个类的start函数里实现,看源码的时候我主要想了解它是如何做到这几件事情的:
- 框架与插件之间逻辑的切换和连接
- 如何加载插件资源到框架的
- 任务是如何执行的
- 数据从Reader同步到Writer的
分别解答如下:
- 框架与插件之间逻辑的切换和连接:模版(Template)模式
通过模版模式在主类里定义好流程顺序,然后由派生类加载自定义逻辑。DataX里有两个流程:Job负责资源的准备,任务信息的配置。Task则负责任务逻辑的执行。两个流程均由模版模式定义,在JobContainer类的start函数中定义的流程为:init() -> prepare() -> split() -> schedule() -> post(),task的流程定义在ReaderRuner和WriterRuner两个类中:init() -> prepare() -> startRead/startWrite()-> post(),均表示 “初始化 -> 事前 -> 事中 -> 事后” 的流程。每种数据源都需要重载Reader/Writer里里面包含里Job和Task的定义。不是所有流程都要重载,最主要的是init,startRead/startWrtier几个函数。

2. 如何加载插件资源到框架的
插件配置文件里有类名和名称信息
{
"name": "mysqlwriter",
"class": "com.alibaba.datax.plugin.writer.mysqlwriter.MysqlWriter",
"description": "Use Jdbc connect to database, execute insert sql.",
"developer": "alibaba"
}在JobContainer的init函数里,通过JarLoader从路径加载类定义并示例化,为了防止多个类加载冲突,每次加载都要使用自定义的classLoader。
3. 任务是如何执行的
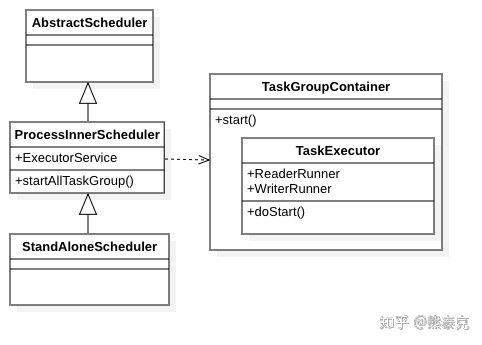
在schedule流程里会创建一个固定线程池Executors.newFixedThreadPool,将拆分好任务转成TaskGroupContainerRunner提交到线程池中执行。每个TaskGroupContainerRunner里有一个TaskGroupContainer,这是任务运行时最重要的类:任务执行对主流程在这个里面。这个线程里会为每个任务new一个TaskExecutor对象,其中包含了一个ReaderRunner和WriterRunner(因为是1:1关系),看名称就知道会启动两个线程,分别读取和写入数据,两个线程之间的通讯方式见下。
4. 数据从Reader同步到Writer的:通过线程之间的共享内存
在插件的Reader里将数据写入到RecordSender中,而在Writer中则从RecordReceiver中读取数据,这两个都是接口,实际实现BufferedRecordExchanger同时继承自这两个接口,然后有自己的实现,调用Channel接口。Channel接口的实现管理数据是缓冲到内存还是持久化。在生成ReaderRunner和WriterRunner的时候,传入同一个channel的实现MemoryChannel,Reader将数据写入内存,Writer从内存中读取数据。

总结看来,DataX的架构设计非常直接,没有用到什么复杂高深的技巧,可以称为大巧不工。
未解决的问题
DataX采用的是单机单进程运行的方式,同步完毕则进程结束,整体更偏工具属性。分布式精细化的东西做的不多,比如整个框架如果是一直在跑,持续提供服务,用户提交的代码,执行完毕结果输出之后果把资源回收,多租户可以向一个中心服务提交任务,这就有了serverless的味道了。需要考虑资源隔离共享,启动速度等一系列问题。
DataX在国外用的不是很普遍,原因不细表。类似的数据同步工具有Sqoop和Kettle,有时间研究下。
后记
使用datax已有一段时间,写作本文却迁延多日,一些概念以为理解清楚了,表述的时候发现细节还是不清楚。从会用到能讲之间,还有一段需要努力的距离,对此要做到心中有数。把知识按照按照学习长短分类,可以大致分为三类:
一天的知识:学习时间在一天内的知识,通常就是一篇文章的长度,讲解一些概念或者算法。来自搜索引擎,微信,公众号等,采集的过程是用眼睛读,读完通常的结论是:我懂了。但是如果要跟别人解释,或者实际用的时候,发现还是有不得劲的地方。
一月的知识:学习时间需要若干周的时间,需要精心准备,反复记忆的东西。常见于学习一本书,一门课程和一门语言。整个过程是个水磨功夫,用眼睛看已经不够了这样学到的知识通常是比较牢靠的,但如果没有抓到其中的精髓,或者后面的巩固提高,很多会随着时间淡忘。比如考完试之后一两个月就忘差不多了,一门语言学完之后不用很快也就忘了。
一年的知识,这些知识往往就不是“学”出来的了,而是经年累月的实践,踩坑获得教训,或者是某天顿悟获得。通过反复的锤炼,知识之间建立了牢固的链接,形成了“元知识”,“方法论”。遇到问题的时候可以从现有知识出发,通过推导得到新知识。
这里有个误区,就是花一个月掌握了几十个一天的知识,并不等于掌握了月级别的知识。以面试找工作为例,有大量的文章和公众号,处于吸引流量的考虑,往往大量推荐各种“一天的知识”,如果花费了大量时间记忆这些“知识”,面试的时候发现很难兜住面试官的问题。要么是有印象,记不住,要么是对来龙去脉不清楚。究其根由,在于现代软件业的发展已经十分发达,通过“封装”,将复杂的实现细节隐藏在接口后面,目的是降低使用的难度。而对于那些公号作者来说,候选者这么多,随便一个应用选一个点戳下去,就能炮制好几篇文章。这些知识并非不重要,但选择的时候要有判断力,世上知识那么多,全部学是学不过来的。择吸收进自己的知识体系里,思考新场景里的应用可能。如果吸收不了,放弃也好过死记硬背。退一步说,也要考虑稀缺性问题:公众号流量那么大,看的人多,大家都背下来也体现不出你的优势。如果工作中真要用到这方面的知识,留个心眼到时候翻出这篇公号文章再学一遍也行是不是?
一天的知识浅薄,一年的知识可遇而不可求,可以从一月的知识开始,比如学习一个完整的课程。学习的时候不能只靠眼睛,而要动手记录甚至实际操练。对学习时间要有产出的评估,比如花了一周时间学习这个东西,产出是什么?是一篇文章,还是一次分享,还是应用到了产品中?学习目的是将新知识与已有的知识体系连接起来,拓展知识的边界。这样学起来虽然慢,但是知识掌握的牢靠,从长时间尺度看有事半功倍之效果。一月的知识学起来是比较痛苦和费事儿的,一方面要选好精力的投入点,与长久目标吻合,劳逸结合。另一方面,要一鱼多吃,与过去掌握的知识进行比较,将其提升为元知识,对知识破碎重组,触类旁通,这样才对得起付出的时间。平常对于刷公众号不要有太多期望,看成对自己已有知识的一个比对校验,或者学习新知识的线索,是个比较平和的心态。