pandas数据清洗:drop函数案例详解、dropna函数案例详解、drop_duplicates函数案例详解
pandas数据清洗:drop函数、dropna函数、drop_duplicates函数详解
- 1 drop函数简介
-
- 1.1 构建学习数据
- 1.2 删除行两种方法
- 1.3 删除列两种方法
- 2 dropna函数简介
-
- 2.1 构建学习数据
- 2.2 删除空值3种方法
- 3 drop_duplicates函数简介
-
- 3.1 构建学习数据
- 3.2 去重方法
- 3.3 reset_index函数重新设置索引
1 drop函数简介
drop函数:用来删除数据表格中的列数据或行数据
df.drop(labels=None,axis=0
,index=None
,columns=None
,inplace=False)
| 参数 | 简介 |
|---|---|
| labels | 以列表形式赋值,待删除的行名或列名,与axis参数一起使用 |
| axis | 确定删除行还是列,0为行,1为列 |
| index | 以列表形式赋值,删除第几行;不与labels和axis参数连用 |
| columns | 以列表形式赋值,删除第几列;不与labels和axis参数连用 |
| inplace | 是否用新生成的列表替换原列表 |
1.1 构建学习数据
df = pd.DataFrame(np.arange(16).reshape(4, 4),
columns=['A', 'B', 'C', 'D'])
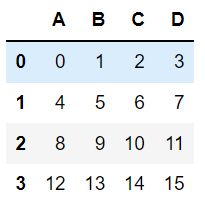
1.2 删除行两种方法
方法一:使用index参数 []内是索引名,不是序号,要注意!
df.drop(index=[0,1],inplace=False)
方法二:使用labels和axis参数
df.drop(labels=[0,1],axis=0,inplace=False)
两者效果一样

1.3 删除列两种方法
方法一:使用columns参数
df.drop(columns=['A','B'],inplace=False)
方法二:使用labels和axis参数
df.drop(labels=['A','B'],axis=1,inplace=False)
两者效果一样

2 dropna函数简介
dropna函数:用来删除数据表格中的空值数据
df.dropna(axis=0
,how='any'
,subset=None
,inplace=False)
| 参数 | 简介 |
|---|---|
| axis | 数据删除维度 |
| how | any:删除带有nan的行;all:删除全为nan的行 |
| subset | 删除指定列空值数据 |
| inplace | 是否用新生成的列表替换原列表 |
2.1 构建学习数据
df = pd.DataFrame({"name": ['Alfred', 'Batman', np.nan],
"toy": [np.nan, 'Batmobile', np.nan],
"born": [pd.NaT, pd.Timestamp("1940-04-25"),
pd.NaT]})
df
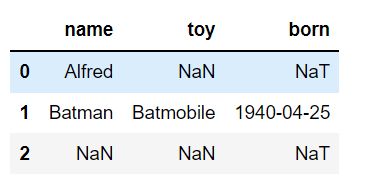
2.2 删除空值3种方法
方法一:删除带空值的行
df.dropna(axis='index',how='any',inplace=False) #任何出现空值的行

方法二:删除带空值的列
df.dropna(axis='columns',how='all',inplace=False) # 全部为空值的列
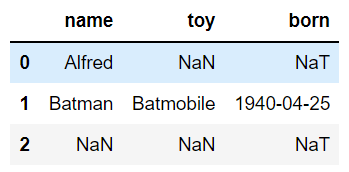
方法三:删除指定列存在空值的行
方法三:删除指定列存在空值的行
df.dropna(axis='index',subset=['name'],how='any',inplace=False) # 仅删除name列存在空值的行

3 drop_duplicates函数简介
drop_duplicates函数:用来去除数据表格中的重复数据
df.drop_duplicates(subset= None
,keep = 'first'
,inplace = False
)
| 参数 | 简介 |
|---|---|
| subset | 以列表形式赋值,需去重的列 |
| keep | “first”:仅保留第一次出现的重复行;“last”:仅保留最后一次出现的重复行;False:删除全部重复行 |
| inplace | 是否用新生成的列表替换原列表 |
3.1 构建学习数据
import numpy as np
import pandas as pd
df = pd.DataFrame({'第一列':[1,1,3,4,5,3,4,5]
,'第二列':[1,1,20,20,30,40,50,50]
,'第三列':[1,1,20,20,200,600,500,600]
,'第四列':[1,1,'s','d','a','b','s','a']})
df
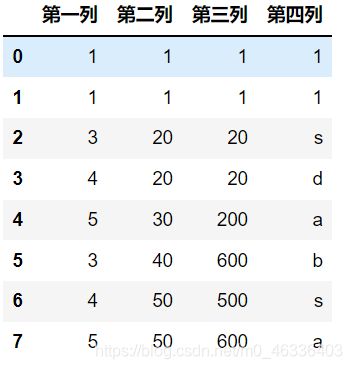
3.2 去重方法
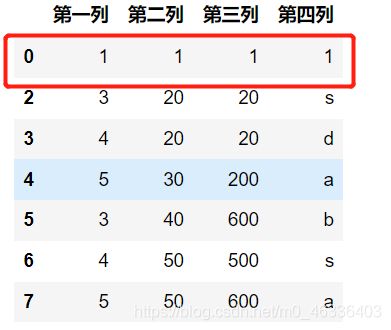
方法一:对整个表格,所有数据完全相同的行进行去重,并保留第一次出现的行
df.drop_duplicates(subset=None
,keep='first'
,inplace=False)
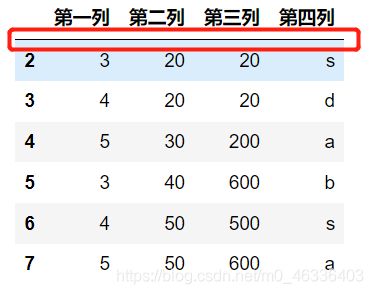
方法二:删除所有重复的行
df.drop_duplicates(subset=None
,keep='first'
,inplace=False)
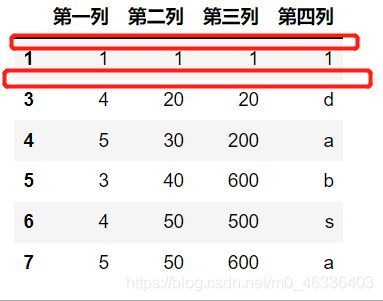
方法三:对指定列进行去重
df.drop_duplicates(subset=['第二列','第三列']
,keep='first'
,inplace=False)
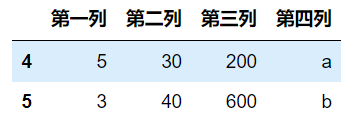
3.3 reset_index函数重新设置索引
a = df.drop_duplicates(subset=['第二列'],keep=False,inplace=False)
a
不想保留原来的index,使用参数 drop=True
a.reset_index(drop=False)
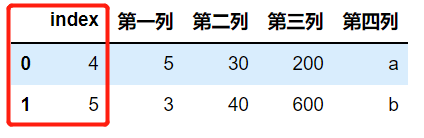
以上就是pandas数据清洗,增删改查中删的主要内容,又成功了一大步!
================================================================下面点个赞,加个收藏⭐,方便下次使用啊!