java代码开发规范
Java代码开发规范
1、工程结构
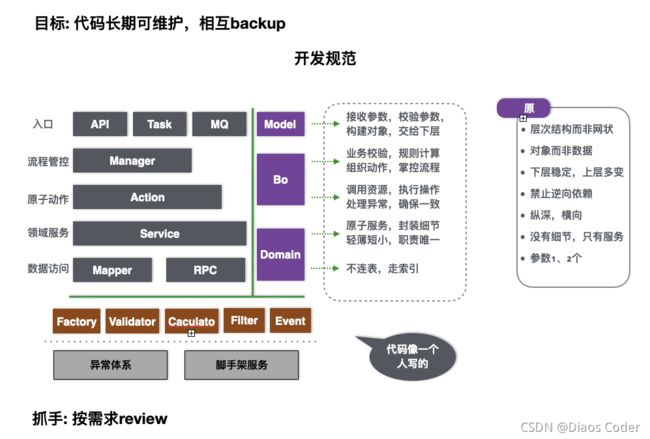
工程分为三个module :sdk、biz、api
api依赖biz biz依赖sdk
1.1.api
api功能主要是与外部的交互部分,包括向前端提供的接口,向外部提供的RPC服务的实现等。
包分类
主要包括的package包括但不限于:

1.2.biz
业务核心部分,承接上下,联通api层与数据库、外部服务等。

1.3.sdk
对外提供rpc服务的接口、dto以及枚举等,具体实现会放在api层
remote包统一使用 1.0-SNAPSHOT 作为包管理。
remote向外提供的接口一律只增不删不改,等到接口上线之后,确认老接口已经无流量后,才能进行删除。
2、整洁的代码
2.1代码整洁之道
写简洁易懂的代码,推荐阅读《代码整洁之道》
2.2一些需要强调的命名点
2.2.1 DTO
DTO,全称为Data Transfer Object, 顾名思义,只是作为数据参数对象来使用,在我们的系统当中,DTO只作为系统之间RPC调用时传递的对象。在系统内部,例如由上层api层传向下层action层时候,应当转为系统内部的一个领域对象。
2.2.2 一些难以汇聚成一个领域对象的散装参数
对于系统中数据的传递时,有时候一些参数难以用一个领域对象来进行概括的时候,例如一些面向动作的参数
代码块
java
public class DepositReceiveParam {
private String outBizId;
private FinanceOutBizTypeEnum financeOutBizTypeEnum;
/**
* 收款面向客户与否
*/
private Boolean isCustomer;
/**
* 面向客户的话,关注此字段
*/
private Integer customerId;
/**
* 面向门店的话,关注此字段
*/
private List poiDepositReceiveParams;
/**
* 实际支付金额
*/
private BigDecimal actualPayment;
/**
* 支付中心流水号
*/
private String tradeNo;
/**
* 实际支付时间
*/
private Integer payTime;
/**
* 支付方式
*/
private PlatformEnum platformEnum;
/**
* 备注信息
*/
private String comment;
}
这样一个充值的动作,难以定义其领域对象,因为其是面向过程的。这个时候可以使用Param的命名形式来进行命名。
3、场景case
这里会列举一些典型的场景,以代码的形式具体说明.
3.1 Controller的场景
Controller的用处是与前端进行接口上的交互,总体流程来说就是
请求→ 根据请求获取(改变)数据→ 组装Model → 返回前端
则Controller需要做的事情,就是将这个流程体现出来
一个典型的GET请求
代码块
java
@RequestMapping(value = "getOrder", method = RequestMethod.GET)
public Map getScheme(String orderId) {
if (StringUtils.isBlank(orderId)) {
throw new InvalidParamException("orderId不能为空");
}
Order order = orderService.getById(orderId);
OrderModel orderModel = orderFactory.create(order);
return ResponseTool.success(order);
}
这是一个根据合同id获取对应的方案的接口,则主流程就是
前端用orderId请求
根据orderId去Service层获取方案
将orderDo送入Factory中,组装成前端需要的Model
返回给前端
Controller层的逻辑很简单,主流程很清晰,一眼就能看出来是在做什么。
如果需要传入多个参数,则可以考虑使用一个Model来包装起来,避免太多参数的情况
而Order和OrderModel的区别是什么呢?
3.1.1领域模型与Model的区别
领域模型对应的是一张表,一个业务上的领域。在交易过程中中,Order则就对应的是一个订单,会落地到数据库的Order表中。
然而在与前端交互的过程中,需要呈现给用户的,则不仅仅是一个order所承载的信息。因为对于用户来说,他需要看到自己的订单,也许要看到订单的支付信息,这些额外的信息,就不是由order来承载的,这些额外的信息的获取,也不是一个Controller的主流程所需要关心的部分,所以就会提出来,放在Factory中
3.2 Factory的场景
接着上面说,则一个Order → OrderModel的Factory
OrderFactory
代码块
java
public OrderModel create(Order order) {
OrderModel model = new OrderModel();
//填充基本信息
fillBaseInfo(model, order);
fillPayResult(model);
fillAddress(model);
return model;
}
在Factory中,主要的工作就是组装一个Model出来
传入参数一般为一个Domain或者List的形式
同样,需要将主流程提取出来
代码中主流程很容易就能看出来,
填充基本信息
组装支付信息
组装地址信息
返回
对于一些填充的细节,则需要遵守一些效率上的规定,例如不能循环调用远程服务,走批量接口等,不能循环读库等
3.3 Service的场景
Service则代表一次原子操作,例如一次对表的插入,一次更新,一次条件查询等
OrderService
代码块
java
public List getByUserId(Integer userId) {
OrderExample example = new OrderExample();
example.createCriteria().andUserIdEqualTo(userId).andStatusIn(xxxx);
return orderMapper.selectByExample(example);
}
public void save(Order order) {
order.setCreateTime(DateUtil.unixTime());
order.setCreatorId(UserUtils.getUser() == null ? 0 : UserUtils.getUser().getId());
orderMapper.insertSelective(scheme);
}
3.4 Action的场景
Action则是对一系列原子操作的组合,也是一个完整的业务操作,一次完整的事务,Action也包含业务校验
ModifyTaskClassAction
public void doAction(ModifyTaskParam param) {
log.info("开始处理修改任务分类");
TaskClass taskClass = taskClassDao.getById(param.getTargetTask().getTask().getTaskClass());
validateTaskClassExist(taskClass);
validateTaskClassExist(taskClass, param.getTargetTask().getTask().getProject());
// validateIsNotChildTask(taskClass);
validateIsNotSection(taskClass);
log.info("修改任务分类校验通过");
fillTaskClass(param, taskClass);
resetStatus(param, taskClass);
transactionSynchronizer.sendEventAfterCommit(buildTaskClassChangeEvent(param, taskClass));
}
Actioin中,依然传入参数一般为一个领域对象,入参禁止为Model、DTO,model的作用于起于api止于api,在api层接收到了DTO后,应该转为一个系统内部的领域对象来使用
3.5 Remote的场景
RemotePoiServiceWrapper
代码块
java
public Integer getShopIdByPoiId(Integer poiId) {
try {
Integer shopId = remoteResvPoiService.getShopIdByPoiId(poiId);
LOGGER.info("getShopIdByPoiId get shopId={} by poiId={}", shopId, poiId);
return shopId;
} catch (Exception e) {
LOGGER.error("getShopIdByPoiId error get shopId by poiId={}", poiId, e);
throw new RpcException(e);
}
}
3.6 Event的场景
这是一个比较特殊的形式,指在程序内发送事件。什么时候应该用Event-Listener来组织代码呢?我觉得主要有两个地方
流程长,分支多,入口点多
这主要就可以参考老sc的上单流程。
录单 → 提交方案 → 确认方案 → 充值 → 声讯复核 → 上线 → 同步阿波罗
这样一个复杂的长链条,每一个流程都有依赖的地方,可能在每一个流程点上停止与开始,这个时候,就可以使用Event的形式来进行组织。
每一个流程都以Event来传递,则任意路口只需要向外发出一个上一流程完成的事件,就可以无缝进行下一个流程。
非主流程
对于一些非主流程的操作,例如产品化后,产品结算的时候,同步写一份数据到点评M3库中,供数据分析使用,而并无其他作为。则其作为产品结算的非主流程,其优先级不高,直接写在一个Action中不太美观,可以拆分为一个Event去处理
3.7 Validator的场景
代码块
Plain Text
@Service
public class PrepayParamValidator {
private static final Logger LOGGER = LoggerFactory.getLogger(PrepayParamValidator.class);
public void validate(PrepayParamDTO prepayParamDTO) {
if (prepayParamDTO.getCustomerId() == null) {
LOGGER.error("no customer id for param={}", prepayParamDTO);
throw new InvalidParamExceptoin("无客户id");
}
if (StringUtils.isBlank(prepayParamDTO.getTradeNo())) {
LOGGER.error("no tradeNo for param={}", prepayParamDTO);
throw new InvalidParamExceptoin("无流水号");
}
if (prepayParamDTO.getAmount() == null) {
LOGGER.error("no amount for param={}", prepayParamDTO);
throw new InvalidParamExceptoin("无充值金额");
}
if (StringUtils.isBlank(prepayParamDTO.getOperator())) {
LOGGER.error("no Operator for param={}", prepayParamDTO);
throw new InvalidParamExceptoin("无操作人");
}
if (prepayParamDTO.getPlatformEnum() == null) {
LOGGER.error("no platform for param={}", prepayParamDTO);
throw new InvalidParamExceptoin("无操作平台");
}
}
}
这是一个典型的抛异常形式的validator,在发现某个参数出错之后,直接抛出异常,并带上对应的错误信息。这样相较于返回布尔值的validator来说,所携带的信息量更大。
切记:Validator当中应该只有一个validate方法,不应该出现其他的方法。
4、日志规范
api出入口必须加日志
核心流程(action、manager)必须加日志
外部调用request、response必须加日志
5、异常规范
6、数据库规范
一、基础规范
1.1、命名规范
1.1.1、库名、表名、字段名必须使用小写字母或数字,不可以数字开头。多个单词或数字间用“_”分割,但禁止下划线间只是数字如resv_01_deposit。
举例:一般形式如resv_deposit;如有数字分表时使用通常如resv_deposit_01。
1.1.2、 库名、表名、字段名禁⽌超过32个字符。须见名知意。不要使用复数。
1.1.3、库名、表名、字段名禁⽌止使⽤用MySQL保留字。常用保留字如desc。
1.1.4、临时库、表名必须以tmp为前缀,并以⽇日期为后缀。
1.1.5、 备份库、表必须以bak为前缀,并以日期为后缀。
1.1.6、索引命名,主键索引使用pk_字段名;唯一索引使用uk_字段名;普通索引使用idx_字段名。
1.2、使用规范
1.2.1、库、表、字段建议加好注释,明确表达其的意思,特别是表及字段。
1.2.2、库中不要保存大数据,如图片、文件。
1.2.3、尽量不在数据库层面做运算,复杂运算移到程序端cpu
1.2.4、拒绝大sql、大的事物、大的批量。
1.2.5、线上连线上、线下连线下环境隔离。
二、库表规范
2.1、库表规范
2.1.1、控制库中表的数量,单库不应该超过百张表。
2.1.2、控制表中数据量,通常上千万数据应考虑分表。
2.1.3、字符集选择:通常采用UTF8,如果支持表情则使用UTF8MB4。
2.1.4、存储引擎的选择InnoDB
InnoDB:支持事物、支持行级锁可以高并发、5.6以上支持全文索引
MySAM:mysql默认引擎。不支持事物、支持表级锁不支持行级锁、支持全文索引。
2.1.5、完整性
2.1.5.1、建立表的实体完整性。
每个表要都含有主键。
2.1.5.2、不建议建立参照完整性,即外键。
参照完整性父子表间的完整性约束,导致父子表操作相互影响带来较大的维护代价降低了可用性。
2.1.5.3、不建议用户定义完整性。
不便于修改维护,可以在业务上实现。
2.1.6、慎用触发器。
触发器存在较大的性能开销、触发器多级触发也不好控制维护。也非常容易被遗忘。
2.1.7、关于范式根据情况而定,没有正确必须与否。需要则适当冗余以提高性能。
注意点:冗余的字段应该是不易变的字段否则难于维护一致
2.1.8、一表一实体。意义明确也方便扩展。
2.1.9、表根据情况可以预留字段。因为大表新加字段比较困难。
三、字段规范
3.1、选择合适的字段类型。定义字段考虑:选择正确的数据类型; 选择合适的精度。
3.1.1、更小的数据类型。更少的空间、cpu、缓存能够带来更好的性能。
3.1.2、越简单越好。能用数值型的就不要用字符型的。如数值比较要比字符比较性能好。
3.2、数值型
3.2.1、正整数采用无符号整数。避免负数、同时扩大了范围。
3.2.2、小数使用decimal,decimal是精确的小数。而float和double是非精确的可以用于近似值存在精度损失的问题。
3.3.、日期型
统一使用unix时间戳。int存储。时间戳不怕时区的问题。int数值型计算等性能也更好。
3.4、字符型
3.4.1、char用于存储固定长度字符。如果长度固定如保存md5可以考虑使用性能要好于varchar。
3.4.2、varchar是不固定长度字符。5.0.3之前的版本只可以保存255个,之后最大存储65535即63K的内容。varchar会用1字节或2字节存储字符串的长度。varchar(n<=255)实际占用n+1否则占用n+2个。
3.4.3、避免使用text和blob类型的。占用空间大;不能检索完整长度也不能排序使用索引。如果需要拆出到单独的表来存储。
3.5、逻辑是非的使用is_xxx的表示。采用unsigned tinyint存储。
3.6、字段避免使用NULL。特别是要索引的字段,因为null字段索引需要额外空间处理、不能使用复核索引。
3.7、不允许使用enum。插入非法值时会插入null。
四、索引规范
4.1、基本规范
4.1.1、不能过多,单表5个。过多对插入、更新带来过多性能开销。
4.1.2、组合索引字段不超过5个。
4.1.3、对字符串建立前缀索引。mysql从字符串左端开始处理字符串。前缀满足区分度情况下使索引边的更小,可以更多的放到内存减少IO等。但不能order by。所以不要对数值型建立前缀索引。
4.1.4、不在索引列上做计算。不能使用索引导致全表扫描。
4.1.5、禁止使用做模糊或全模糊匹配导致不能使用索引。可以支持xxx%的模糊查询。
4.1.6、组合索引要注意最左比配原则。区分度高的字段在左边。
4.1.7、不要对选择度低的字段建立索引。选择度=非重复行数|总数 ,越高越好。
4.1.8、避免索引的重复索引
4.1.9、避免冗余的索引
4.1.10、利用覆盖索引。
覆盖索引:包含所有满足需要查询数据的索引叫覆盖索引。mysql使用b-tree索引来覆盖查询使用where中的列使用到索引且满足最左前缀,同时返回的列也在索引中。
4.2、主键索引
innodb对主键建立聚簇索引。其他索引属于辅助索引,期内保存着主键。辅助索引获取到数据需要一次辅助索引查询还需要一次主键索引得到数据。
4.2.1、必须有主键。不然也会默认有。
4.2.2、主键建议选择自增的。或者外部的方式生成数值型的主键。
4.2.3、不用字符类型做主键。字符串较长导致辅助索引较大。
4.2.4、主键索引不要更新。否则导致辅助索引的更新。
4.3、不使用外键索引。参照完整性做父子表间的完整性约束,导致父子表操作相互影响带来较大的维护代价降低了可用性。
五、SQL规范
5.0、基础规范
5.0.1、拒绝大的SQL。大的SQL可以进行拆分。大的SQL对资源利用率低。多个小sql缓存命中率高、利用多CPU、如有锁减小锁的粒度。
5.0.2、拒绝大的事务。与事务无关的操作不要放在事务内。保持事务短小。
5.0.3、不使用存储过程。存储过程难于调试扩展也没有移植性。
5.0.4、减少使用运存函数。
5.0.5、高并发数据库避免join
5.0.6、使用预编译语句。比传递sql更高效。一次解析多次使用。避免sql注入。
5.1、select语句优化
5.1.1、查询需要的列。避免select * 的方式。select * 基本上不能使用到覆盖索引、返回多余的数据增加IO、网络、CPU等资源、
5.1.2、不要使用count(列名/常数)代替count()。count()是标准统计行数语法,统计与null无关。count(列名/常数)不会统计null列
5.1.3、count(distinct 列)统计非null得非重复行数。count(distinct 列1,列2)如果一列为null,另一列值不同也是0。
5.1.4、注意sum类聚合函数NPE问题。如果为null sum返回的是null。
5.2、where优化
5.2.1、使用ISNULL()判断是否为null值。NULL与任何值的比较都为NULL。
5.2.2、in 操作控制数量,建议1000个以内或更少。
5.2.3、同字段or操作改为in操作。or是O(n),in是O(logn);不同字段的or可以使用unio
5.2.4、保持一个range查询。多个范围查询对索引利用率不高。
5.2.5、多个is null操作索引利用率也不高
5.2.6、同数据类型间进行比较,避免隐式的类型转换。
5.2.7、避免使用负向查询。not in 、not like、!= 等等。
5.3、order by优化
5.3.1、order by利用索引前提是where和order by 条件要符合最左前缀条件同时where语句中的条件是等值条件。
5.4.、group by优化
group by是分组+排序的事项方式
5.4.1、group by如果不需要排序可是指定order by null
5.4.2、使用索引要满足最左前缀
5.5.、limit优化
limit 10000,10实现方式是查询出10010行数据并丢弃前10000行数据
5.5.1、避免limit获取大量数据。需要则进行一定的优化。
如可以先查询出ID,在用in操作。如果有连续性则使用范围查询。
5.6、join优化
mysql join算法使用的是nested loop join算法,通过驱动表的结果集作为循环数据的基础同下一张表进行循环过滤得到结果。
5.6.1、避免join,更要避免大表的join。
5.6.2、小表驱动大表进行查询。查询的列最好要命中index。
5.6.3、不需要去重则使用union all替代union。union有去重开销。
5.7、更新操作优化
5.7.1、大批量更新操作避免高峰期
5.7.2、大批量更细操作打散。避免同步的延迟等。
六、程序事务配置规范
6.1、事务建议rollback for=exception
6.2、业务数据库读写master。避免不同步带来的问题。如果读写分离了则不能更新完立即查询。