Reading Note(3)——基于FPGA的动态可重构特性探索新型加速器架构
这是关于一篇使用FPGA动态可重构特性进行新型FPGA加速器体系结构设计的一篇论文, 在此将这篇文章的主要内容和细节梳理一下。
0.Abstract
现有的面向神经网络的基于FPGA的加速器,很多只使用FPGA的静态重配置特性。所谓静态可重构性指的就是我们日常意义上的对FPGA重复烧写的过程(板子必须停止工作,然后用新的比特流重新配置)。这篇文章(mproving HW/SW Adaptability for Accelerating CNNs on FPGAs Through A Dynamic/Static Co-Reconfiguration Approach, no.10.1109/TPDS.2020.3046762)。从现代FPGA的动态部分可重构技术(Dynamic Partial Reconfiguration, DPR)入手,提出了一种将FPGA静态可重构和静态可重构的方式相结合得出的新的加速器架构。然后分别使用静态设计空间探索(static design space exploration)和基于强化学习(reinforcement learning)的方法来分别确定最优的静态硬件配置和运行时重构策略。
有关动态部分可重构的工程细节参考,点击这里。
1.Introduction
CNNs作为深度学习领域最有代表性的算法之一,已经有很多基于ASIC方案的面向CNN的加速器诞生。但是因为深度学习算法还在不断发展和迭代,所以FPGA在当下因为可重构性和灵活性而具有独特的优势。原先的设计中FPGA被当作传统的固定电路,然后在此基础上通过静态设计空间探索(DSE)来确定最佳并行比,但是这样相对死板的一次性决策会使得CNN中的不同层次上性能存在显著差异。因为决策是不变的,它肯定不能很好的契合每一个层次的最优计算并行度、数据局部性和数据流调度,所以所谓基于静态设计空间探索得到的结果只是一个"折中方案"。
所以在这种大前提下,FPGA的DPR特性就可以给设计空间的探索带来更多可能性和灵活性。
这篇文章的主要贡献有:
-
提出了一款新的加速器架构,它可以协同使用FPGA的静态和动态可重构性来提升CNN中的软硬件适应性。(软硬件适应性是本文作者提出的一个概念,它表示底层加速器架构和目标CNN模型的高级计算功能完全适应,从而实现片内资源和片外数据通信的最高效率。)
-
基于提出的加速器体系结构,提出了一种基于分层聚类的网络映射方法,可以有效地降低运行时硬件重构的性能开销。
-
针对给定的计算场景,提出了一种系统化的设计与优化方法,该方法采用静态设计空间探索过程和基于强化学习的决策方法来寻找最优的静态硬件配置和动态重构策略。
2.BACKGROUND AND MOTIVATION
首先,这部分介绍了卷积神经网络的基本运算模式:
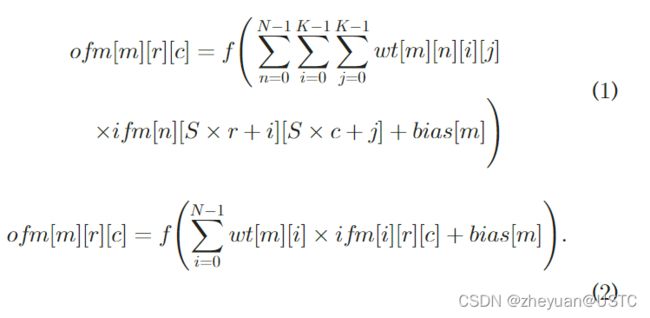
以及将循环展开和循环分块技术施加到卷积层上的伪代码:

最后对传统的基于静态重构配置的FPGA加速器进行了有关软硬件适应性的分析,得出的结论是传统的静态重构FPGA加速器对于神经网络的加速而言是不够高效的。
3.ACCELERATION PARADIGM
3.1 Overall Architecture
这部分首先介绍了加速器的整体架构,整体架构图如下:

整个加速器可以分为两个部分,计算端和基于软件的控制端,这两部分分别实现在平台的可重配置逻辑部分和嵌入式处理器部分。计算端根据是否可以重配置被分为两部分,即固定部分(static core)和动态重配置部分(RP),这两部分在神经网络层级(layer-level)进行相互配合。
每个RP在加速器运行时可以选择Core Lib中提前准备好的配置文件来动态的配置RP中计算单元的架构。从通用性的角度出发。在本次工作中准备好的比特流文件都是具备独立内积计算单元和缓冲区,但是具有不同设计参数(计算并行度、缓冲区大小、数据流类型)的计算单元,它们共同组成了可重配置的功能模块,它们的基本架构如下:

整个架构中,静态核的并行性始终保持不变,可变的只有可重配置模块RP。但值得注意的是,可重配置的动态模块换入换出的开销很大,所以不能指望主要的运算任务全部依靠切换动态核心来完成。所以为了保证计算能力的连续性,可以将大部分的硬件资源用于构建静态核心来保证性能,而用相对较少的资源来构建动态核心来保持灵活性。
加速器的软件部分分为控制模块(Control Module)和强化学习模块(RL)组成,前者用于协调整个加速过程,包括数据在各个模块之间的划分、启动DMA进行传输、执行动态模块的换入换出、以及持续对每个核心给定大小的输入数据保持分析。控制模块将分析结果反馈给RL模块,RL模块根据策略指导控制模块换入换出可重配置块。最后,RL模块的训练是在线下进行的,训练完成之后在运行时依照结果做出决策。
3.2 Collaborative Computing Schemes
工作还为提出的加速器定义了两种协同计算方案(),分别是LoopC-Major计算方案和LoopM-Major计算方案。这两种方案其实就是复用数据的模式不一样,示意图如下。
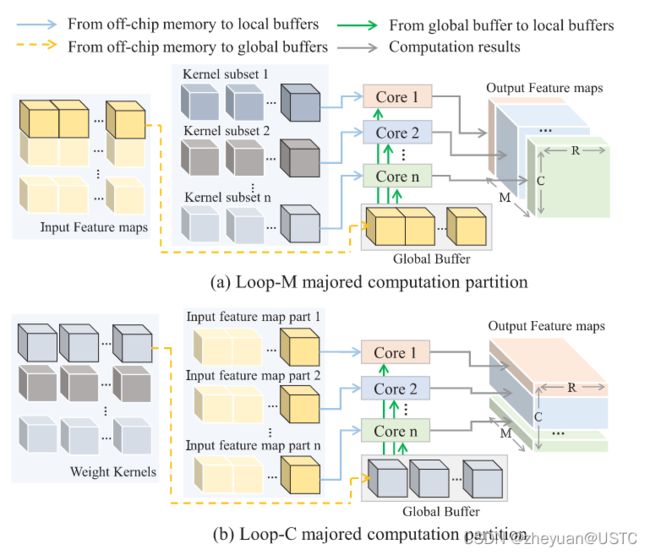
LoopC-Major方案就是沿着列方向将输出特征图切分开来并行计算,LoopM-Major方案就是沿着通道(纵深)方向将输出特征图切分开来并行计算。在这两种情况中Global Buffer存储的数据不一样,LoopM-Major存储的是输入特征图,LoopC-Major存储的是卷积核,分发在各个运算核心的并行计算的对象也不一样。
3.3 Network Mapping Method
这部分主要解释了如何将一个完整的CNN映射到我们设计的FPGA加速系统上。因为每次重新配置可重配置模块开销很大,一般开销通常在几十毫秒内,所以不可以在架构中频繁的进行逻辑块的换入换出。那么如何将重配置的开销降低到最小,一种方法就是使用批处理的手段来延长每一个计算层次中的计算时间来使其与重配置时的时间重叠(overlap),但是这样的开销也很大,因为重配置的时间太长了,批的大小得非常大才可以满足条件。
针对这样的问题,本文提出的方案是通过聚类算法将特征相似的层加以聚类,这样就可以大大减少动态重配置时的换入换出次数。那么如何定义层次的特征,本文给出的参考指标如下:
-
如果不同层的M和N值很接近,那么在这些层的相同内积单元下,它往往能够实现较高的计算资源利用率。
-
如果不同层的K和N值接近,则在这些层的缓冲相同的情况下,它往往能够实现高缓冲利用率。
-
如果不同层输入特征图和的权重核之间的数据量比率接近,则在这些层的相同数据流调度下(相同循环顺序下),它往往能够实现较高的整体数据局部性。这个指标由以下的公式来衡量:
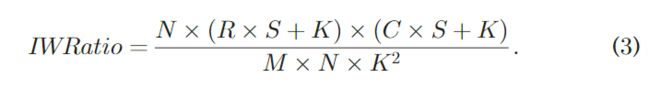
这三个指标的公式化描述如下,将这三个指标综合起来得到 D i , j D_{i,j} Di,j作为不同层次之间差异性的度量。采用k_means聚类算法将神经网络的不同层次加以聚类,以此获取最小的换入换出次数来减少动态重配置的开销。

这种基于层次聚类的方式只适用于二维卷积,三维卷积中的计算量本身就已经很大了,足以覆盖换入换出的延迟开销,所以没有必要采用层次聚类方式。聚类的簇数默认情况下是不同层次的种类数,但实际最优的聚类簇数需要通过设计空间探索(DSE)来进一步确定。
4.A CCELERATOR IMPLEMENTATION STRATEGY
据前所述,将一个给定的CNN模型部署到一款给定的FPGA平台上的流程如下所示,以下讨论的假定场景是二维的卷积运算。
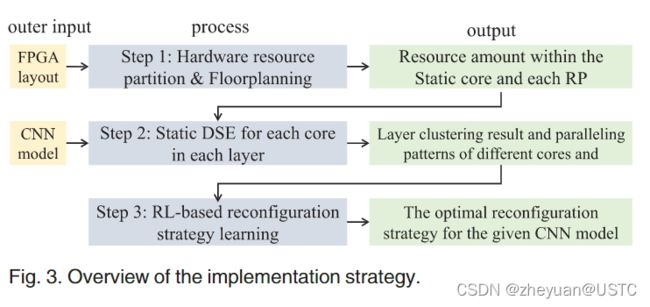
4.1 Resource Partition and Floorplanning
这一步就是根据FPGA资源分布来对可重构模块在片上的布局进行手动的划分,这篇工作在这里提出了在划分时应该注意的几点约束:
1.每个RP的形状应该是规则的
2.分块之后的RP的数量不能超过FPGA片上时钟的数量
3.与I/O或者通信有关的硬核的所属的时钟信号不能分配给RP
4.FPGA上的资源分布不均匀,不同的RP应该包含一定数量的硬件资源来部署计算核心
5.每一个RP所包含的资源用量应该尽可能一致,这是为了兼容性而做的努力
本文提出在现代FPGA的硬件资源下,结合上述的约束,RP的数量大约在4-6个。
在完成手动的划分之后,还需要对资源使用情况做一个大致的统计。这些数据包含DSP和BRAM块的数量,每一个RP核心和静态核心的BRAM容量,以及静态核心相对于所有RP所使用的DSP比例。这些在静态设计空间探索时都会用到。
4.2 Static Design Space Exploration
这部分就是静态设计空间探索(static DSE)所做的主要工作,就是获得上面所述的层聚类结果的最佳静态配置。算法主要流程如下所示:

可以看到DSE过程最终想要得到最佳的聚类中心点个数以及聚类结果,以及对应于每一个聚类核心的并行模式。算法中最核心的步骤就是Search,而Search也分为两个子步骤。
- 假设静态核独立工作,承担的计算量比例等同于它所占用的DSP资源比例,在此条件下完成静态核的并行模式的确定。层内的并行模式到底是采用LoopC-Major还是LoopM-Major也在这个子步骤中对每个聚簇进行确定。
- 在1的工作基础之上,完成对不同动态可配置核心的并行模式确定,所有被聚类在同一类的可重配置核心都具有相同的并行模式。
在1、2的步骤中,本文的工作提出了一种基于roofline model(屋顶线模型)的优化模型,来完成对最优并行模式的探索。这个模型由以下几个部分组成:
-
变量:包含了不同核心并行模式的硬件参数,形式化的表示如下:

-
目标函数:目标函数的的定义与屋顶线模型保持一致,都是为了找到一个变量组合来最大化加速器的性能值和片内计算/片外访存比率。

在公式(10)和(11)中,参数相应的估算方法如下:
计算量的估算大致这样进行:在第一个步骤中,计算量通过静态核心DSP所占比重来大致估算;在第二个步骤中,计算量通过将各个聚簇的层次加和来得到。计算时间的估算大致这样进行:总计算量除以总的计算并行度,计算并行度的估算方法是所有核心的 ∑ T m × T n \sum{T_m \times T_n} ∑Tm×Tn。
访存量等于所有核心上输入输出特征图和卷积核的总和,访存量也和数据量化有关。
访存量可以使用下表来估计
- 约束条件:约束条件是用来限制每一个核心的取值和组合范围来使其符合硬件约束的。一共有以下几条约束:


D S P n u m , B R A M n u m , B R A M c a p DSP_{num},BRAM_{num},BRAM_{cap} DSPnum,BRAMnum,BRAMcap分别表示每个核心可以使用的DSP数量,BRAM数量和BRAM总容量,这三个量资源划分阶段确定下来的。
计算并行度(computing parallelism)的计算方法是 T m × T n T_m \times T_n Tm×Tn再乘以每个MAC操作需要使用的DSP平均数量。
总缓冲端口宽度(total buffer port width)是核内输入缓冲区、输出缓冲区和权重缓冲区的占用的BRAM个数之和。
总缓冲尺寸(total buffer size)就是以上三部分缓冲区尺寸的加和,它和位宽的乘积应该小于BRAM的总容量。
4.计算方法:这两个子步骤中使用的优化模型可以通过穷举不同变量的值和组合来求解。
4.3 RL-Based Dynamic Reconfiguration Decision
这部分工作就是在之前静态工作状态已经确定的情况下,如何在加速过程中获得动态的状态转移序列。这篇文章采用了基于强化学习(Deep Q-Network)的方法来进行动态重配置序列的决策。整个模型的训练在线下进行,然后在线阶段根据确定的序列做出动态重构决策。
训练过程大致如下所示:

在这个过程中,加速器的配置被抽象成向量形式,输出相应的Q值作为每一个RP的行动决策。神经网络的全职W将根据训练结果进行更新,直至收敛到最优解。
每一个层中一批数据中的每一个样本开始处理的时间点都是制定决策(decision making point)的时间点。CNN的前馈过程一直持续到预定义的条件被满足时停止,这样的一轮训练叫做一个学习阶段(learning episode)。整个Deep-Q Network模型中的一些关键元素定义如下:
-
状态集合:本文中建立了描述加速器状态的状态向量s,向量中总共定义了25个维度,所有的状态向量的加在一起构成了状态集合。
-
行动集合:每一个RP都面临两种选择,一是不重配置,二是选择对应于下一个聚簇的核心进行重配置。所以向量的维度等于RP的数目,每个RP的取值只有两个,0(不配置)或者1(重新配置)。
-
终止条件:终止条件用来判断当前的学习阶段是否已经完成,判据如下所示:
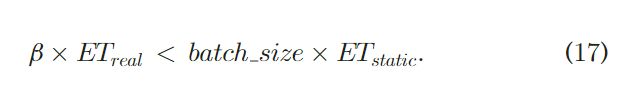
这个式子中 E T r e a l ET_{real} ETreal和 E T s t a t i c ET_{static} ETstatic分别表达的是在静态DSE阶段得到的执行时间的真实值和执行时间的理想值。 β \beta β是一个逐渐递增但是小于1的值,初始值为0.7。上面这个式子就是CNN前馈过程完成的判据。 -
奖励函数:奖励函数的定义如下,它其实表达的是每一个动态重配置前后可以得到的时间收益。 P a r a c u r r e n t Para_{current} Paracurrent和 P a r a n e x t Para_{next} Paranext表达的分别是当前核心和下一个核心所能获得的并行度,OP则表达的是计算量。

-
DQN的训练采用了经验重放法来减小模型收敛到局部最优点的可能(experience replay method),并采用了 ϵ \epsilon ϵ-贪心策略来加强通用性。也就是说对于决策,有 1 − ϵ 1-\epsilon 1−ϵ的概率按照神经网络的输出进行动作,还有 ϵ \epsilon ϵ的概率进行随机动作。 值得注意的是, ϵ \epsilon ϵ也是随着过程而不断变化的,训练过程采用基于SGD的反向传播算法来完成。
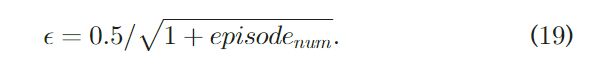
整个对于DQN的训练算法如下所示:

5.EXPERIMENTAL EVALUATION
这部分的结论主要是,本次提出的含动态可重配置的加速器架构相比于之前的加速器工作,能实现更高的计算密度。这表明了本次提出的加速器架构能够更好的贴合CNN模型的计算特征,实现了更好的加速器软硬件适应性。
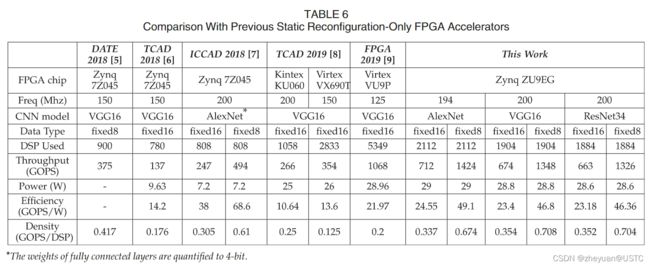
实现在16位固定数据类型下平均可以实现683个GOP,在8位固定数据类型下平均可以实现1.37个TOP,与以前在同类FPGA平台上的实现相比,计算密度从1.1提高到1.91。