(预计阅读时间:8分钟)
数据血缘,数据旅行的地图
大数据时代,我们都被数据包围着。企业中的数据作为生产要素,只有进行流转、使用,才能发挥其最大价值。
面对这些来自不同系统、存储为不同形式的数据,我们不禁好奇:这些数据从哪里产生,流经过哪些业务系统?这些系统又对这些数据进行了哪些操作或计算?数据血缘图谱可以回答这些问题。
数据血缘是数据旅行的地图,它显示了数据的起源、沿途的每一站、以及在每一站对数据做了哪些处理和操作。
数据是生产资料,要管理和保护好数据、挖掘数据的价值,最好能怀揣这样一张数据旅行的地图——数据血缘图谱。
数据血缘图谱的典型应用
来源跟踪
这里包括数据来源和报表来源的跟踪。一份数据或是报表的生产,可能涉及到很多的来源和流转路径。掌握这些信息,可以帮助决策者深入理解数据和报表,为科学决策提供依据。
影响分析
数据不断地产生和变化。假如一份数据在源头或上游发生改变,就可以通过数据血缘图谱检查改变后的数据流转过程,并找出下游哪些数据(如消费者)将受到影响。
依赖分析
有些数据源、子系统或中间表、字段是被深入依赖的。数据血缘图谱可以帮助数据管理者调整数据架构,减少数据冗余,优化数据的存储和分析。
数据治理
数据血缘图谱,可以帮助业务领导者在跟踪数据的合规性、管理数据风险的同时,做出更好的决策。
图数据库最适合构建数据血缘图谱
数据血缘映射的是组织中数据实体之间大量的、复杂的依赖关系。假如使用传统关系型数据库中的关系数据模型,由行,列组成的二维表来表示,对于数据血缘问题的处理难免复杂低效。使用图数据库来处理,数据及其关系被抽象为图模型中的“点、边”结构,让关系表达更直观,操作更简单、更快捷。
我们以金融场景为例。如图1所示,这张图被经常引用,它展示的是金融机构在信用卡应用和个人身份分析场景下,数据的来源、流转、最终生成报表和应用的过程。图右侧自上而下的四个节点,分别代表管理者关注的“信用卡历史交易报告”和“数据安全报告”,以及运维系统和工程师日常监测的仪表盘。

(图1,金融机构信用卡应用和个人身份分析架构图)
图片来源: https://www.graphable.ai/blog/graph-data-lineage-graph-database/
面对这两张报表和两个仪表盘,不禁又会引出文章开头的问题: 这些数据从哪里产生,流经过哪些业务系统?这些系统又对这些数据进行了哪些操作或计算?
首先,我们仅看“信用卡交易报表”部分,并把它抽象成更直观的基于图数据模型的点,边示意图(图2),上面的问题就迎刃而解了。
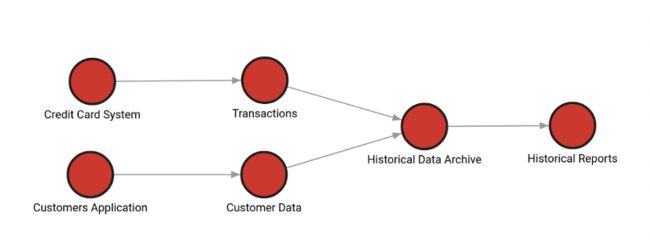
(图2,针对图一进行的图数据建模)
数据血缘图谱就是这样构建的,它包含以下几个关键步骤:
-
顶点识别:基于业务,确定业务功能的实体。
-
边的识别: 关注数据的来源和实体间的依赖与关联。
-
原点追踪: 列出的实体,追踪原点和传导路径。
-
完整数据血缘图谱的打造:将各个系统连接成完整的数据血缘图谱。
下面我们将分享一个使用图数据库构建数据血缘图谱,进行敏感数据保护的应用案例。
蚂蚁集团基于TuGraph实现敏感数据管理和保护
数据在流转和使用中,不可避免地存在安全与合规问题,比如企业非常重视的敏感数据管理和保护。在数据采集,传输,存储,使用,共享和开放的过程中,数据血缘图谱可以起到 敏感数据识别,数据合规判断,行为风险识别, 数据资产管理 的作用。
数据血缘图谱在蚂蚁集团内部应用广泛,蚂蚁基于自研高性能图数据库TuGraph,打造了“敏感数据识别”场景应用。
利用数据血缘图谱,提高敏感数据识别的效率
企业经营过程中总会有一些敏感数据(或隐私数据)被系统收集,存储,比如用户的身份证号、电话号码等。这些信息需要被妥善保管及保护,并时刻防范违规拷贝、访问、调用、转换等行为发生。通常,企业都有专门的敏感数据管理和保护制度,并安排专门的管理员对数据进行分级管理和安全审计。
对于静态存储在数据库或表格里的数据,管理起来不难。但如果这些数据流动起来,需要被不同的系统访问,处理或计算,再流转到下游的系统中,如何能快速并准确地识别哪些数据(表或字段)是敏感数据呢?再者,如果监管力度调整,原来低敏感数据要被定义为高敏感数据,如何能快速定位系统中所有受到影响的数据表和字段呢?
过去的做法是顺序扫描每个数据表和相关的列,依照业务团队制定的敏感数据识别规则来调用“敏感数据识别引擎”,并对敏感数据进行识别和标注。实践中发现,在数据量很大的情况下(表和列的数量很大),容易出现扫描不完整的情况。而且由于敏感数据的稀疏性,单位时间扫描出的敏感数据比较少,效率低下。(如图3所示)

(图3,顺序扫描数据库中的“表”和“列”)
使用图计算技术,以数据库中表和列为顶点,复制和截断等关系为边,打造数据血缘图谱,可以按照敏感数据传播的路径扫描数据,能够明显减少扫描量,提高敏感数据识别的效率。(如图4所示)
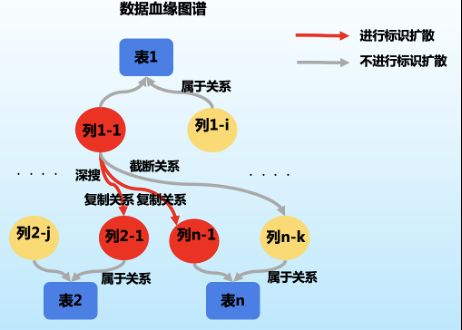
(图4,基于数据血缘图谱,利用图计算的标签扩散算法)
在数据血缘图谱中,我们用度数表示每个数据节点向外扩散的关系个数,它代表节点(表或列)在数据流转过程中的重要程度或参与程度。节点度数越高,其重要性越高。将所有节点的关系度数计算出来并由高到低排序,恰恰是图数据库和图计算技术最擅长的。从度数高的节点开始扫描,能显著提高敏感数据的发现速率。(如图5所示)

(图5,按节点的度数优先扫描)
利用数据血缘图谱,提高敏感数据识别的效果
有了数据血缘图谱,还可以通过逻辑推断提高敏感数据识别的准确度和召回率。
如图6所示,在图的左半部分,A数据的标签为“座机号”、B为“手机号”;A到t1使用“长度为11”作为过滤条件,A到B是“复制关系”,就可以推理出,A数据中同时包含了座机号和手机号,A的敏感标签就应该从“座机号”修改为“联系方式”,敏感标签更加准确。
再看图6的右半部分,C是身份证,D是一个日期类型,如果敏感数据识别规则是,日期不是敏感数据,生日是敏感数据。而C到D是执行了一条图上方的SQL语句。我们就能发现D这个日期值,是从身份证的某个具体位置切分并复制的,就能推断出D 是敏感数据,并表以红色。
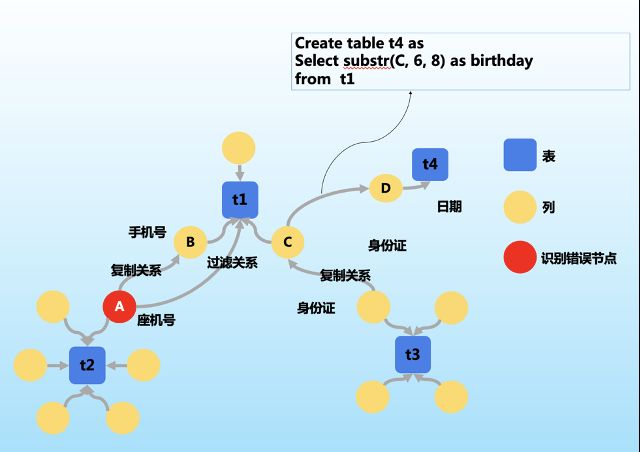
(图6,数据血缘图谱的识别增强能力)
敏感数据的保护也是个“魔高一尺道高一丈”的过程。图7表示的就是这样一种情况。A是身份证号码,属于敏感数据,但有时候,会有人对A的数据进行变种操作,企图隐藏其敏感数据的特征。比如在数字间加上一个特殊符号,绕过敏感数据识别。
但由于数据血缘图谱中记录了这一操作,就可以把代表该操作的这条“边”标注为异常。这样的边一旦被发现,在线情况下可以实时熔点,离线情况下也可以进一步审计,提高敏感数据识别率。
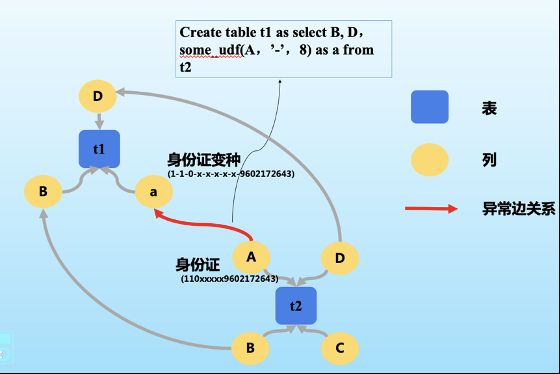
(图7,数据血缘图谱识别异常边关系)
小结
对于企业来说,打造数据血缘图谱,是完善数据治理的有效手段,同时也是一个系统性的工程。需要依据国家政策、监管要求、行业规范,安排专业的人员,制定合理的制度,并配合相应的流程和工具。
针对本文介绍的“敏感数据安全管理”领域,企业如果打算结合自身业务,实施建设,首先要充分重视数据的分类分级,这是打造数据血缘图谱的重要基础。
敏感数据的定义、分类、分级,敏感数据识别规则的设计,识别引擎的开发,都需要有大量的知识积累和应用,例如不同的数据变换操作可能导致不同的数据类别和级别变化,数据传递的风险识别也需要有业务经验的积累。蚂蚁集团基于多年数据安全经验沉,打造了蚂蚁链数字保护伞平台,提供敏感数据识别、分类分级、敏感数据血缘图谱等更全面的数据安全解决方案。TuGraph作为数字保护平台的图数据存储和计算底座,提供了完备的图数据库功能,卓越的性能,丰富的算法库和工具,安全性和易用性等优势。
关于TuGraph
高性能图数据库 TuGraph( https://github.com/TuGraph-db/tugraph-db)由蚂蚁集团和清华大学共同研发,经国际图数据库基准性能权威测试,是 LDBC-SNB 世界纪录保持者,在功能完整性、吞吐率、响应时间等技术指标均达到全球领先水平,为用户管理和分析复杂关联数据提供了高效易用可靠的平台。
历经蚂蚁万亿级业务的实际场景锤炼,TuGraph 已应用于蚂蚁内部150多个场景,助力支付宝2021年资产损失率小于亿分之0.98。关联数据爆炸性增长对图计算高效处理提出迫切需求,TuGraph 已被成熟应用于金融风控、设备管理等内外部应用,适用于金融、工业、互联网、社交、电信、政务等领域的关系数据管理和分析挖掘。
2022年9月,TuGraph 单机版开源,提供了完备的图数据库基础功能和成熟的产品设计,拥有完整的事务支持和丰富的系统特性,单机可部署,使用成本低,支持TB级别的数据规模。
END
往期回顾
→ 蚂蚁图数据库再获LDBC权威测试世界第一
→ 蚂蚁集团开源图数据库TuGraph,成立图计算开源委员会
→ 金融图数据库选型工具“LDBC-FinBench”
▼ 关注蚂蚁图计算,了解最新资讯