第六课 大数据技术之Hadoop3.x的源码解析
第六课 大数据技术之Hadoop3.x的源码解析
文章目录
- 第六课 大数据技术之Hadoop3.x的源码解析
-
- 第一节 RPC通信原理解析
- 第二节 NameNode启动源码解析
- 第三节 DataNode启动源码解析
- 第四节 HDFS上传源码解析
-
- 4.1 create创建过程
- 4.2 write上传过程
- 第五节 HDFS上传源码解析
- 第六节 MapReduce源码解析
-
- 6.1 Job提交流程源码和切片源码详解
- 6.2 MapTask & ReduceTask源码解析
- 第七节 Hadoop源码编译
-
- 6.1 前期准备工作
- 6.2 工具包安装
- 6.3 编译源码
第一节 RPC通信原理解析
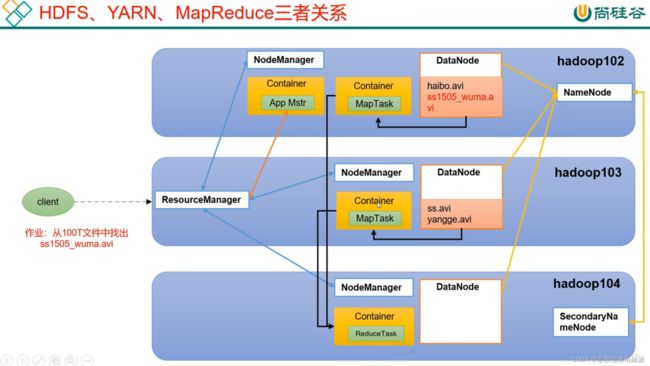
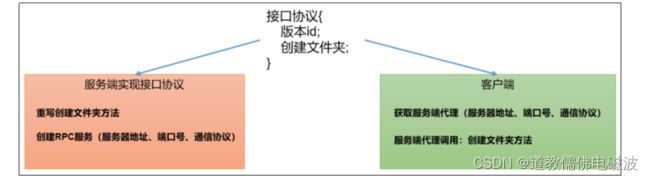
- RPC实例需求。模拟RPC的客户端、服务端、通信协议三者如何工作的
- 代码编写:
- 在HDFSClient项目基础上创建包名com.atguigu.rpc
- 创建RPC协议
package com.atguigu.rpc;
public interface RPCProtocol {
long versionID = 666;
void mkdirs(String path);
}
- 创建RPC服务端
package com.atguigu.rpc;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.ipc.RPC;
import org.apache.hadoop.ipc.Server;
import java.io.IOException;
public class NNServer implements RPCProtocol{
@Override
public void mkdirs(String path) {
System.out.println("服务端,创建路径" + path);
}
public static void main(String[] args) throws IOException {
Server server = new RPC.Builder(new Configuration())
.setBindAddress("localhost")
.setPort(8888)
.setProtocol(RPCProtocol.class)
.setInstance(new NNServer())
.build();
System.out.println("服务器开始工作");
server.start();
}
}
- 创建RPC客户端
package com.atguigu.rpc;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.ipc.RPC;
import java.io.IOException;
import java.net.InetSocketAddress;
public class HDFSClient {
public static void main(String[] args) throws IOException {
RPCProtocol client = RPC.getProxy(
RPCProtocol.class,
RPCProtocol.versionID,
new InetSocketAddress("localhost", 8888),
new Configuration());
System.out.println("我是客户端");
client.mkdirs("/input");
}
}
- 测试, 启动服务端 观察控制台打印:服务器开始工作
- 在控制台Terminal窗口输入,jps,查看到NNServer服务。启动客户端
- 观察客户端控制台打印:我是客户端
- 观察服务端控制台打印:服务端,创建路径/input
- 总结
- RPC的客户端调用通信协议方法,方法的执行在服务端;
- 通信协议就是接口规范。
第二节 NameNode启动源码解析


- 在pom.xml中增加如下依赖
hadoop-hdfs-client
<dependencies>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>3.1.3version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-hdfsartifactId>
<version>3.1.3version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-hdfs-clientartifactId>
<version>3.1.3version>
<scope>providedscope>
dependency>
dependencies>
- ctrl + n 全局查找namenode,进入NameNode.java
- ctrl + f,查找main方法, 点击createNameNode,发现返回了一个NameNode对象点进去,查看initialize点击进去查看,
startHttpServer(conf);点击startHttpServer。启动htt服务 - 点击startHttpServer方法中的
httpServer.start();点击setupServlets。这里设置了启动服务和端口结束。 - 回到initialize这里
loadNamesystem(conf);加载镜像文件和编辑日志,点击进去看具体细节。 - 回到initialize这里
rpcServer = createRpcServer(conf);,初始化NN的RPC服务端 - 回到initialize这里
startCommonServices,startCommonServices,NN启动资源检查。- 追踪startCommonServices继续点击
NameNodeResourceChecker,DFS_NAMENODE_DU_RESERVED_DEFAULT默认100M的元数据储存空间。 - 从上面回到checkAvailableResources 真正检测磁盘空间逻辑
- 追踪startCommonServices继续点击
- 回到initialize这里
startCommonServices,- 追踪startCommonServices继续点击,
blockManager.activate(conf, completeBlocksTotal);,继续追踪datanodeManager.activate(conf);发现heartbeatManager.activate();管理心跳信息。点击进去发现启动一个线程检测心跳,追踪run方法。// 10分钟 + 30秒 - 回到追踪startCommonServices继续点击
blockManager.activate(conf, completeBlocksTotal);,继续追踪`bmSafeMode.activate(blockTotal);计算是否满足块个数的阈值setBlockTotal(total);`。有俩个块损毁不能启动了。areThresholdsMet()判断DataNode节点和块信息是否达到退出安全模式标准
- 追踪startCommonServices继续点击,
第三节 DataNode启动源码解析
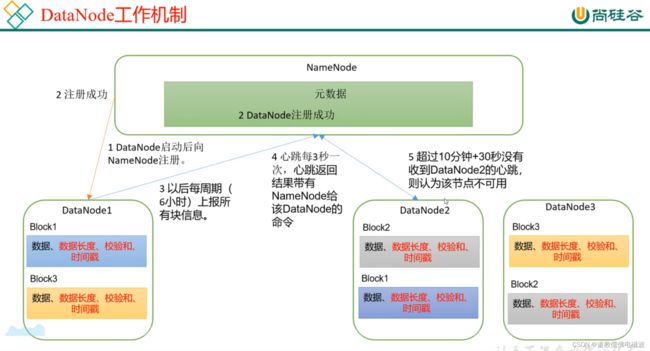

- 在pom.xml中增加如下依赖
<dependencies>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>3.1.3version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-hdfsartifactId>
<version>3.1.3version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-hdfs-clientartifactId>
<version>3.1.3version>
<scope>providedscope>
dependency>
dependencies>
- ctrl + n 全局查找datanode,进入DataNode.java
- ctrl + f,查找main方法, secureMain -> createDataNode -> instantiateDataNode -> makeInstance -> DataNode -> startDataNode -> 这里就是对DN实例化 initDataXceiver -> dataXceiverServer(开启线程)
- ctrl + f,查找main方法, secureMain -> createDataNode -> instantiateDataNode -> makeInstance -> DataNode -> startDataNode -> startInfoServer 初始化http服务 -> DatanodeHttpServer
- ctrl + f,查找main方法, secureMain -> createDataNode -> instantiateDataNode -> makeInstance -> DataNode -> startDataNode -> initIpcServer(); 初始化RPC server
- ctrl + f,查找main方法, secureMain -> createDataNode -> instantiateDataNode -> makeInstance -> DataNode -> startDataNode -> refreshNamenodes DN向NN注册 -> doRefreshNamenodes -> createBPOS -> BPOfferService -> BPServiceActor
- ctrl + f,查找main方法, secureMain -> createDataNode -> instantiateDataNode -> makeInstance -> DataNode -> startDataNode -> refreshNamenodes DN向NN注册 -> doRefreshNamenodes -> startAll -> bpos.start() -> start -> bpThread.start(); 开启线程每个DN向NN注册, 查找它的run方法 -> connectToNNAndHandshake -> register -> rpcProxy.registerDatanode -> 接着就到了服务端NN的接口中了 ctr + N搜索NameNodeRpcServer -> 搜索函数registerDatanode -> 继续追踪
org.apache.hadoop.hdfs.server.blockmanagement.DatanodeManager#registerDatanode
// register new datanode
addDatanode(nodeDescr);
blockManager.getBlockReportLeaseManager().register(nodeDescr);
// also treat the registration message as a heartbeat
// no need to update its timestamp
// because its is done when the descriptor is created
heartbeatManager.addDatanode(nodeDescr);
heartbeatManager.updateDnStat(nodeDescr);
- 对着图追踪。
第四节 HDFS上传源码解析

4.1 create创建过程
- 添加依赖
<dependencies>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>3.1.3version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-hdfsartifactId>
<version>3.1.3version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-hdfs-clientartifactId>
<version>3.1.3version>
<scope>providedscope>
dependency>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>4.12version>
dependency>
<dependency>
<groupId>org.slf4jgroupId>
<artifactId>slf4j-log4j12artifactId>
<version>1.7.30version>
dependency>
dependencies>
- DN向NN发起创建请求,自己写的代码。就追踪这个create即可
@Test
public void testPut2() throws IOException {
FSDataOutputStream fos = fs.create(new Path("/input"));
fos.write("hello world".getBytes());
}
- NN处理DN的创建请求 点击create ClientProtocol.java
HdfsFileStatus create(String src, FsPermission masked,
String clientName, EnumSetWritable<CreateFlag> flag,
boolean createParent, short replication, long blockSize,
CryptoProtocolVersion[] supportedVersions, String ecPolicyName)
throws IOException;
- Ctrl + h查找create实现类,点击NameNodeRpcServer,在NameNodeRpcServer.java中搜索creat
- DataStreamer启动流程 NN处理完DN请求后,再次回到DN端,启动对应的线程
4.2 write上传过程
- 向DataStreamer的队列里面写数据.用户写的代码 点击write
@Test
public void testPut2() throws IOException {
FSDataOutputStream fos = fs.create(new Path("/input"));
fos.write("hello world".getBytes());
}
- 建立管道之机架感知(块存储位置) Ctrl + n全局查找DataStreamer,搜索run方法
- 建立管道之Socket发送 点击nextBlockOutputStream
- 建立管道之Socket发送 点击nextBlockOutputStream
- 客户端接收DN写数据应答Response Ctrl + n全局查找DataStreamer,搜索run方法
第五节 HDFS上传源码解析

- Yarn客户端向RM提交作业 wordcount程序的驱动类中点击 Job.java 最后一行job.waitForCompletion 追踪
- RM启动MRAppMaster 在pom.xml中增加如下依赖 ctrl +n 查找MRAppMaster,搜索main方法
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-mapreduce-client-appartifactId>
<version>3.1.3version>
dependency>
- 调度器任务执行(YarnChild) 启动MapTask ctrl +n 查找YarnChild,搜索main方法
第六节 MapReduce源码解析
- 说明:在讲MapReduce课程时,已经讲过源码,在这就不再赘述。
6.1 Job提交流程源码和切片源码详解
- Job提交流程源码详解
waitForCompletion()
submit();
// 1建立连接
connect();
// 1)创建提交Job的代理
new Cluster(getConfiguration());
// (1)判断是本地运行环境还是yarn集群运行环境
initialize(jobTrackAddr, conf);
// 2 提交job
submitter.submitJobInternal(Job.this, cluster)
// 1)创建给集群提交数据的Stag路径
Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf);
// 2)获取jobid ,并创建Job路径
JobID jobId = submitClient.getNewJobID();
// 3)拷贝jar包到集群
copyAndConfigureFiles(job, submitJobDir);
rUploader.uploadFiles(job, jobSubmitDir);
// 4)计算切片,生成切片规划文件
writeSplits(job, submitJobDir);
maps = writeNewSplits(job, jobSubmitDir);
input.getSplits(job);
// 5)向Stag路径写XML配置文件
writeConf(conf, submitJobFile);
conf.writeXml(out);
// 6)提交Job,返回提交状态
status = submitClient.submitJob(jobId, submitJobDir.toString(), job.getCredentials());

- FileInputFormat切片源码解析(input.getSplits(job))

6.2 MapTask & ReduceTask源码解析
- MapTask源码解析流程
=================== MapTask ===================
context.write(k, NullWritable.get()); //自定义的map方法的写出,进入
output.write(key, value);
//MapTask727行,收集方法,进入两次
collector.collect(key, value,partitioner.getPartition(key, value, partitions));
HashPartitioner(); //默认分区器
collect() //MapTask1082行 map端所有的kv全部写出后会走下面的close方法
close() //MapTask732行
collector.flush() // 溢出刷写方法,MapTask735行,提前打个断点,进入
sortAndSpill() //溢写排序,MapTask1505行,进入
sorter.sort() QuickSort //溢写排序方法,MapTask1625行,进入
mergeParts(); //合并文件,MapTask1527行,进入
collector.close(); //MapTask739行,收集器关闭,即将进入ReduceTask
- ReduceTask源码解析流程
=================== ReduceTask ===================
if (isMapOrReduce()) //reduceTask324行,提前打断点
initialize() // reduceTask333行,进入
init(shuffleContext); // reduceTask375行,走到这需要先给下面的打断点
totalMaps = job.getNumMapTasks(); // ShuffleSchedulerImpl第120行,提前打断点
merger = createMergeManager(context); //合并方法,Shuffle第80行
// MergeManagerImpl第232 235行,提前打断点
this.inMemoryMerger = createInMemoryMerger(); //内存合并
this.onDiskMerger = new OnDiskMerger(this); //磁盘合并
rIter = shuffleConsumerPlugin.run();
eventFetcher.start(); //开始抓取数据,Shuffle第107行,提前打断点
eventFetcher.shutDown(); //抓取结束,Shuffle第141行,提前打断点
copyPhase.complete(); //copy阶段完成,Shuffle第151行
taskStatus.setPhase(TaskStatus.Phase.SORT); //开始排序阶段,Shuffle第152行
sortPhase.complete(); //排序阶段完成,即将进入reduce阶段 reduceTask382行
reduce(); //reduce阶段调用的就是我们自定义的reduce方法,会被调用多次
cleanup(context); //reduce完成之前,会最后调用一次Reducer里面的cleanup方法
第七节 Hadoop源码编译
6.1 前期准备工作
- 官网下载源码
https://hadoop.apache.org/release/3.1.3.html - 修改源码中的HDFS副本数的设置
- CentOS虚拟机准备
- 配置CentOS能连接外网。Linux虚拟机ping www.baidu.com 是畅通的
- 注意:采用root角色编译,减少文件夹权限出现问题
- Jar包准备(Hadoop源码、JDK8、Maven、Ant 、Protobuf)
- hadoop-3.1.3-src.tar.gz
- jdk-8u212-linux-x64.tar.gz
- apache-maven-3.6.3-bin.tar.gz
- protobuf-2.5.0.tar.gz(序列化的框架)
- cmake-3.17.0.tar.gz
6.2 工具包安装
- 注意:所有操作必须在root用户下完成
- 分别创建/opt/software/hadoop_source和/opt/module/hadoop_source路径
- 上传软件包到指定的目录,例如 /opt/software/hadoop_source
pwd
/opt/software/hadoop_source
ll
# 解压软件包指定的目录,例如: /opt/module/hadoop_source
tar -zxvf apache-maven-3.6.3-bin.tar.gz -C /opt/module/hadoop_source/
tar -zxvf cmake-3.17.0.tar.gz -C /opt/module/hadoop_source/
tar -zxvf hadoop-3.1.3-src.tar.gz -C /opt/module/hadoop_source/
tar -zxvf protobuf-2.5.0.tar.gz -C /opt/module/hadoop_source/
pwd
/opt/module/hadoop_source
# 安装JDK
tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/hadoop_source/
vim /etc/profile.d/my_env.sh
#JAVA_HOME
export JAVA_HOME=/opt/module/hadoop_source/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
# 刷新JDK环境变量
source /etc/profile
# 验证JDK是否安装成功
java -version
# 配置maven环境变量,maven镜像,并验证
vim /etc/profile.d/my_env.sh
#MAVEN_HOME
MAVEN_HOME=/opt/module/hadoop_source/apache-maven-3.6.3
PATH=$PATH:$JAVA_HOME/bin:$MAVEN_HOME/bin
source /etc/profile
# 修改maven的镜像
vi conf/settings.xml
# 在 mirrors节点中添加阿里云镜像
<mirrors>
<mirror>
<id>nexus-aliyun</id>
<mirrorOf>central</mirrorOf>
<name>Nexus aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</mirror>
</mirrors>
# 验证maven安装是否成功
mvn -version
# 安装相关的依赖(注意安装顺序不可乱,可能会出现依赖找不到问题)
# 安装gcc make
yum install -y gcc* make
# 安装压缩工具
yum -y install snappy* bzip2* lzo* zlib* lz4* gzip*
# 安装一些基本工具
yum -y install openssl* svn ncurses* autoconf automake libtool
# 安装扩展源,才可安装zstd
yum -y install epel-release
# 安装zstd
yum -y install *zstd*
# 手动安装cmake 在解压好的cmake目录下,执行./bootstrap进行编译,此过程需一小时请耐心等待
pwd
./bootstrap
# 行安装
make && make install
# 证安装是否成功
cmake -version
# 装protobuf,进入到解压后的protobuf目录
pwd
/opt/module/hadoop_source/protobuf-2.5.0
# 次执行下列命令 --prefix 指定安装到当前目录
./configure --prefix=/opt/module/hadoop_source/protobuf-2.5.0
make && make install
# 配置环境变量
vim /etc/profile.d/my_env.sh
# 输入如下内容
PROTOC_HOME=/opt/module/hadoop_source/protobuf-2.5.0
PATH=$PATH:$JAVA_HOME/bin:$MAVEN_HOME/bin:$PROTOC_HOME/bin
# 验证
source /etc/profile
protoc --version
libprotoc 2.5.0
# 到此,软件包安装配置工作完成。
6.3 编译源码
# 进入解压后的Hadoop源码目录下
pwd
/opt/module/hadoop_source/hadoop-3.1.3-src
#开始编译
mvn clean package -DskipTests -Pdist,native -Dtar
# 注意:第一次编译需要下载很多依赖jar包,编译时间会很久,预计1小时左右,最终成功是全部SUCCESS,爽!!!
# 成功的64位hadoop包在/opt/module/hadoop_source/hadoop-3.1.3-src/hadoop-dist/target下
pwd
/opt/module/hadoop_source/hadoop-3.1.3-src/hadoop-dist/target