计算机架构总结笔记(2)
目录
计算机架构----机器码和汇编语言
引入--汇编语言的产生
指令集系统
MIPS
引入--计算机系统结构
MIPS指令介绍
寄存器和内存的比较
排序--大端和小端
计算机架构----机器码和汇编语言
引入--汇编语言的产生
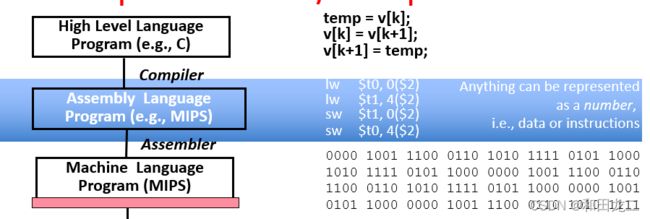
如图所示,语言从高到低按级别排列。最上层是编程语言,可以用代码表示要处理的指令。最下层是机器语言,所有指令都以数字的形式呈现,也是计算机可以识别的语言。为了方便记忆机器语言,在高级语言和机器码之间加入了一层缓冲区,也就是汇编语言。汇编语言的本质就是一种助记符,用来帮助汇编人员记忆计算机指令。
指令集系统
如前文所述,所谓语言就是让计算机听懂的指令,而包含所有这种指令的集合就称为指令集(instruction set architecture (ISA))。
指令集可以是单独的,也可以是多个指令集混用。
早期指令集的设计理念是尽可能多的加入指令使其能够进行精细化操作,也就是复杂指令集(CISC)
之后,指令集进行了精简化,指令更加简短,复杂指令也可以使用简单操作实现,也就是精简指令集(RISC)
RISC的创作原则:简单既是快速。因此尽量精简CPU使其浓缩在内核中,因此,RISC就是对指令的数量和复杂程度实现简化
RISC的规则:
1. 固定的指令长度:方便从内存获取信息
2. 简单的寻址方式:方便从内存中提取指令
3. 更少更简单的指令集:方便运行指令
4. 仅有读取和存取指令需要接入内存:无需在寄存器载入内存
5. 将复杂程序移交程序员,计算机无需涵盖复杂指令
MIPS
MIPS是一种ISA,也是一种RISC,之后的介绍会主要围绕MIPS进行
引入--计算机系统结构
Any computer, no matter how primitive or advance, can be divided into five parts:
1) The input devices bring the data from the outside world into the computer.
2) These data are kept in the computer’s memory until...
3) The datapath request and process them.
4) The operation of the datapath is controlled by the computer’s controller.
All the work done by the computer will NOT do us any good unless we can get the data back to the outside world, so…
5) Getting the data back to the outside world is the job of the output devices.
计算机体统结构可分为五个部分:处理器 数据流 储存器 输入和输出 本课程主要围绕前三项进行介绍
指令集拥有固定的少量操作数,称为:寄存器(rigester)
寄存器速度快 但也因为数量少因此限制很多
MIPS拥有32个寄存器,每个寄存器有32位同时可容纳一个字符
MIPS指令介绍
在MIPS中,用“$”符号表示寄存器
![]()
s0寄存器到s7寄存器对应第16到第23号寄存器,用来存储变量
![]()
t0 - t9寄存器用来存储临时数据
• Instruction Syntax is rigid:op dst, src1, src2
– 1 operator, 3 operands• op = operation name (“operator”)• dst = register getting result (“destination”)• src1 = first register for operation (“source 1”)• src2 = second register for operation (“source 2”)
MIPS的指令被严格限制为指令 目的地 变量1 变量2 的形式
1. 加法指令
• Integer Addition ( add )– C: a = b + c– MIPS: add $s1, $s2, $s3
2. 减法指令
• Integer Subtraction ( sub )– C: a = b - c– MIPS: sub $s1, $s2, $s3
例题1
•Suppose a→$s0, b→$s1, c→$s2, d→$s3, and e→$s4. Convert the following C statement to MIPS:a = (b + c) – (d + e)
解:
add $t1, $s3, $s4
add $t2, $s1, $s2
sub $s0, $t2, $t1
对于复杂运算就会用到临时寄存器,将每个小项的结果存储起来再一起运算
3. 注释
对于MIPS,只需在注释前加上“#”即可
add $t1, $s3, $s4 # $t1=d+e
4. “零”寄存器
寄存器零的值永远为0 我们可以应用这个特性对其他寄存器实现赋值操作
add $s3, $0, $0 # c=0
add $s1, $s2, $0 # a=b
5. 常数指令
MIPS能够识别常数,但是书写规则是要在指令后补上“i”
opi dst, src, imm
– Operation names end with ‘ i ’, replace 2 nd source register with an immediate (check Green Sheet for un/signed)
举例
addi $s1, $s2, 5 # a=b+5
addi $s3, $s3, 1 # c++
6. 数据转移指令--变址寻址
引入--高级语言的数据移入
在高级语言中,我们可以对字符串进行直接操作。
比如在Python里面可以直接选取特定的字符串中的某个位进行操作
# 通过如下操作我们可以很简单的把a的0到5位赋值给b
a = 'Hello World'
b = a[0:5]
print(b) 在MIPS中,是无法直接达到这样的效果的。需要通过寄存器变址寻址才可以达到类似的效果
op reg, off(bAddr)
– op = operation name (“operator”)– reg = register for operation source or destination– bAddr = register with pointer to memory (“base address”)– off = address offset (immediate) in bytes (“offset”)
在MIPS中,可以通过寄存器的数值和偏移量(常数)找到内存中的地址。其格式为:
操作 要赋值/传输数据的寄存器,偏移量(寄存器(携带内存指针))
由于MIPS的最小操作量级是word,因此在取值时只能将偏移量地址的后四位全部取出。另外,如果偏移量不是4的整数倍的话将会发生错位现象,去除的四位数不属于同一个word
数据转移指令共有两个:存取操作和读取操作
lw为存取操作,将地址中的数据移入寄存器。sw为读取操作,将寄存器中的数值移入地址
# addr of int A[] -> $s3, a -> $s0
lw $t0,12($s3) # $t0=A[3]
add $t0,$s0,$t0 # $t0=A[3]+a
sw $t0,40($s3) # A[10]=A[3]+a
上面的例子展示了lw和sw的使用。s3寄存器存储了本次的内存指针。首先将指针所指字符串的第四个word的值移入t0(注意内存地址在指令中需要*4),之后把t0中的值增加后放入A存储器的第11个word中。
7. 转移和标签操作
在MIPS中,无法使用指令分块,只能用标签进行替代。(和单片机类似)
MIPS中共有三个比较跳转操作:
beq reg1,reg2,label # branch if equal
bne reg1,reg2,label # branch if not equal
j label jump without condition下面用C和MIPS实现同一个条件跳转指令加深理解
C:
if(i==j) {
a = b /* then */
} else {
a = -b /* else */
}
MIPS:
beq $s0,$s1,then
else:
sub $s2, $0, $s3
j end
then:
add $s2, $s3, $0
end:
注意MIPS除了判断语句还要加一个无条件跳转指令,防止程序继续运行另一种情况的操作。
寄存器和内存的比较
显然,寄存器的存储量比内存小得多。但是我们仍然需要寄存器,因为它的速度比内存快得多(100-500倍)

排序--大端和小端
在MIPS中数据的排布顺序可能不同,可能从最后开始存储,也可以从较小的地址开始存储。从小到大为大端;从大到小为小端。
例题:
将0x1234567小端存到3001到3004,3003存放的数值
答:23,因为是八位数要在最前补0