微处理器系统结构·第二章·结构组成与工作原理
微处理器系统结构·第二章·结构组成与工作原理系列文章目录
目录
- 微处理器系统结构·第二章·结构组成与工作原理系列文章目录
- 一、工作原理
-
- 1. 冯·诺依曼架构
- 2. 模型机系统结构
-
- 1)总线
- 2)存储器子系统
- 3)输入/输出子系统
- 4)CPU子系统
- 3. 模型机指令集
- 4. 模型机工作流程
- 二、微处理器体系结构的改进
-
- 1. 冯诺依曼架构的改进
-
- 1)指令集:CISC与RISC
- 2) 存储分层
- 3)总线与输入输出子系统
- 2. 并行技术
-
- 1)流水线结构
- 2)超标量与超长指令字结构
-
- 超标量处理机
- 超长指令字处理机(VLIW)
- 3)多机多核结构
-
- 多级系统
- 多核系统和多线程技术
- 三、体系结构分类
- 四、性能描述
一、工作原理
1. 冯·诺依曼架构
核心五部分:计算器,控制器,存储器,输入设备,输出设备

2. 模型机系统结构
由诸多子系统通过总线互连构成
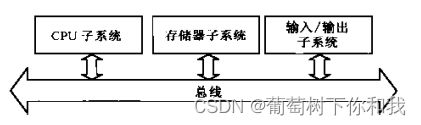
1)总线
各部件的公共通道,实现数据,信息的传输与交换
2)存储器子系统
存放当前的运行程序与数据。每个存储单元有唯一编号,称为地址

3)输入/输出子系统
用于完成计算机与外部交换信息,外设种类繁多,总线协议各不相同。因而引入接口,作为信息交换的中间层,简化设计
4)CPU子系统
系统的核心处理单元,主要由运算器,控制器,寄存器阵列,地址和数据缓冲器构成
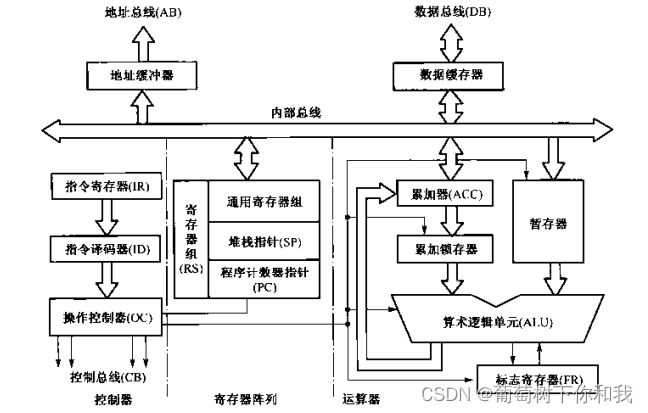
- 运算器:
由ALU(算术逻辑单元),ACC(累加器),FR(标志寄存器)和暂存器构成,其中ALU负责运算,ACC作为寄存器组的通用寄存器,负责给ALU传递以及暂存数据,暂存器与之类似,但暂存器对程序员透明,不可访问。FR用于标志当前运算结果的状态 - 控制器:
由IR(指令寄存器),ID(指令译码器),OC(操作控制器)构成。执行流程为,首先根据PC的值获取下一条指令的地址,然后进行取指,并通过DB(数据总线)送入IR中,而后由ID对IR的指令进行译码,并通过OC确定的时序,向对应部件发送控制信号 - 寄存器阵列:
CPU临时存储单元,分为专用寄存器和通用寄存器 - 数据和地址缓冲器:
数据和地址的缓冲器,作为总线缓冲,隔离内外总线,提供驱动能力
3. 模型机指令集
指令由两部分组成:操作码,操作数
操作码指明操作的性质,操作数指明参与操作的数据或数据存放的地址
亦有教材称,指令由操作码和地址码构成
个人理解地址码指明数据的地址,即地址码是操作数的子集
如有错误欢迎指正
4. 模型机工作流程

执行如下指令
模型机采用DOS汇编,无指令流水,数据总线宽度为8,一条指令由16字节组成,不同机器细节不同,但流程一致,此处只需关注流程,而不用在意具体细节,如果你不知道这段话在说啥,那就忽略这段话
MOV AX,0X5C -> B0 5C
假定PC此时为0x1000,上述指令翻译的机器码为B053,流程如下
- PC内的数据传输至MAR中,进行取指
- PC+1,此时PC为0x1001
- MAR经过地址译码,找到0x1000单元
- CPU发出读命令
- 0x1000内容被读出,送至MDR
- 由于B0为操作码,由OC发出相应控制信号
- PC内传输至MAR
- PC+1,此时为0x1002
- MAR经过译码,找到0x1002单元
- CPU发读命令
- 0x1001单元内容送至MDR
- 将0x5C送入AX寄存器
二、微处理器体系结构的改进
由于冯诺依曼架构指令串行的特点,以及数据和程序混合,带来相应的瓶颈。因而对其有三方面的改进:指令集,存储分层,高速总线
1. 冯诺依曼架构的改进
1)指令集:CISC与RISC
CISC(复杂指令集):由于历史原因,上世纪的存储器造价高,容量小,速度慢,因而为了减少对内存的存取操作,复杂指令通过微程序实现,微程序固化在一块ROM中,而后由硬件实现
其缺点为:
- 操作复杂,效率低
- 硬件设计困难
- 不利于采用流水线技术
基于以上原因,产生了RISC(精简指令集),其主要思想为将复杂功能拆解为简单指令,而执行简单指令。因而其特别依赖编译器的有效性
其设计原则为:
- 指令少,格式简单
- 寄存器充足,但只有加载和存储指令能访存
- 指令直接由硬件执行,单周期内完成
- 充分利用指令流水
- 强调编译器作用
2) 存储分层

将存储器进行四级分层,这样在总体上提高访存效率
cache-主存:解决高速度和低成本的矛盾
主存-辅存:解决大容量和低成本的矛盾
此外,哈佛结构将指令和数据分开存储,提高了存储器带宽

3)总线与输入输出子系统
连接各子系统的结构称为互连结构,而总线结构是最常用的互连结构,有如下形式

前者一般用于外设少,逻辑简单的系统,后者一般用于体系庞大,逻辑复杂的系统
2. 并行技术
为了提高系统的并行性,发展出了四种级别的并行技术:SLP(系统级并行,多处理器,多磁盘结构),ISP(指令级并行,流水线技术),TLP(线程级并行,多线程处理器技术),CLP(电路级并行,超前进位加法器)
1)流水线结构
将一条指令拆分为不同的子过程,每个子过程称为流水线的级,级数也被称为流水线深度。
不同指令的不同子过程在时间上可以重叠,这样就提高了指令的并行性,一个典型的四级流水被划分为:取指,译码,执行,回写。如下所示
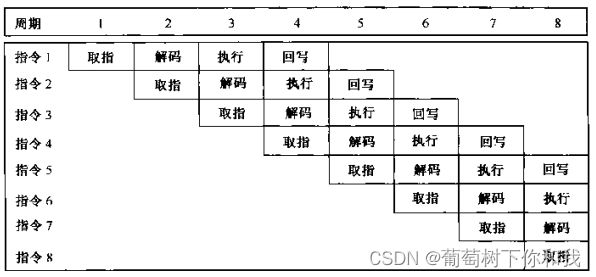
宏观上看,每个周期都能完成一个指令,提高了处理效率
2)超标量与超长指令字结构
过深的流水不仅不会增加效率,反而会以为延时问题降低效率,同时时钟频率越高,也会带来功耗大,指令冒险等问题,因而有了多发射技术,多发射技术又衍生出了超标量和超长指令字两种架构,其CPI可能比1小
超标量处理机
超标量处理机通过重复设置多个流水段硬件并行工作来提高性能,但考虑到硬件设计部分的难度,目前一般采用多执行单元的超标量形式

现代的超标量计算机一般采用两条输入流水和三条执行流水

如上所示,执行流水是非对称结构,其依托于此,每个流水适合处理的指令类别就各不相同。为了充分发挥其并行性,其指令分发单元一般会设置一个对指令进行动态调度的机构
超长指令字处理机(VLIW)
与上述不同,VLIW依靠编译器在编译阶段找出潜在的并行指令,并通过指令调度将数据冲突降低至最小,而后将多个并行指令组装为一个指令,形成一条超长的指令,而后由多个部件执行这个超长指令,相当于同时执行多条指令。其效率取决于指令的压缩程度,因而不适用于一般领域。

3)多机多核结构
多级系统
通过分布式系统实现,由物理上的多个主机构成集群,协同处理问题
多核系统和多线程技术
利用多线程技术,使得一个处理器能交叠的处理多个线程,使处理器能并发的执行他们。其主要有两种实现方式:
- 细粒度多线程:在每个指令中都进行线程切换,优点是降低线程由于时间长短引起的cpu空闲,提高效率,缺点是已处理的线程会被其他线程的指令拖延,使得单个线程处理速度降低
- 粗粒度多线程:仅在遇到大开销的阻塞时才切换线程。这样对单个线程的处理速度影响小。同时每次停顿时,都要清空或冻结流水线,新的线程要填满流水线,就会有启动开销。粗粒度多线程便可以减少这样的启动开销。
三、体系结构分类
根据费林分类法,有四种类别SISD(单指令流单数据流),MISD(多指令流单数据流),SIMD(单指令流多数据流),MIMD(多指令多数据流)
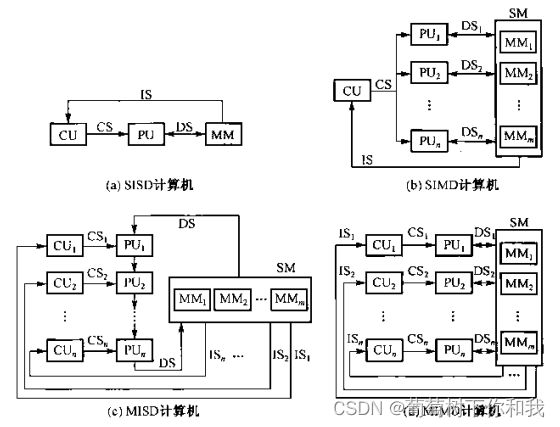
- SISD:传统的顺序处理机,流水线处理机,超标量处理机等
- MISD:无现实的实现
- SIMD:阵列处理机与向量处理机
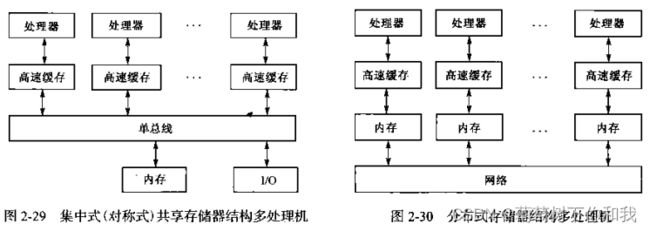
- MIMD:多核多线程处理机,分为集中式共享存储器和分布式存储器两类
四、性能描述
- 字长:CPU一次运算的最大数据宽度
- 存储容量:CPU能直接访问的主存容量,一般由地址总线宽度决定
- 运算速度:
- CPI:指令的平均周期数
- MIPS:每秒百万条指令的个数
- T:执行时间
有如下关系
M I P S = f ( M H z ) C P I MIPS=\frac {f(MHz )}{CPI} MIPS=CPIf(MHz)
以及
T ( s ) = I C × C P I f ( H z ) T(s)=\frac{IC\times CPI}{f(Hz)} T(s)=f(Hz)IC×CPI
其中 I C IC IC 为指令数目, f f f 为时钟频率