爬虫必备网页解析库——Xpath使用详解汇总(含Python代码举例讲解+爬虫实战)...
大家好,我是辰哥~
本文带大家学习网页解析库Xpath——lxml,并通过python代码举例讲解常用的lxml用法
最后实战爬取小说网页:重点在于爬取的网页通过lxml进行解析。
lxml的安装

在使用lxml解析库之前,先简单介绍一下lxml的概念,并讲解如何安装lxml库。
lxml的基本概念
lxml是Python的一个解析库,支持html和xml的解析,其解析的效率极快。xpath全称为Xml Path Language,顾名思义,即一种在xml中查找信息的语言。lxml主要是用xpath模块去解析html或者xml等文档内容。
安装lxml
lxml的安装其实很简单,下面介绍两种不同的安装方式(适用不同的操作系统)。
#方式一:pip安装
pip install lxml
#方式二:wheel安装
#下载对应系统版本的wheel文件:http://www.lfd.uci.edu/~gohlke/pythonlibs/#lxml
pip install lxml-4.6.3-cp39-cp39-win_amd64.whl方式一,通过pip install lxml 命令就可以直接安装;
方式二,需要通过下载whl文件,再去安装。whl文件的下载链接为:http://www.lfd.uci.edu/~gohlke/pythonlibs/#lxml,进入这个链接后选择下载自己python版本和系统版本(32位/64位)对应的whl文件即可;
Xpath的常用规则

规则具体见表所示。
| 表达式 |
描述 |
| nodename |
选取此节点的所有子节点 |
| / |
从当前节点选取直接子节点 |
| // |
从当前节点选择子孙节点 |
| . |
选取当前节点 |
| .. |
选择当前节点的父节点 |
| @ |
选取属性 |
| * |
通配符,选择所有元素节点与元素名 |
| @* |
选取所有属性 |
| node |
匹配任何类型的节点 |
举例:
from lxml import etree
from io import StringIO
test_html = '''
学号
- 2112001
- 2112002
2112003
- 2112004
姓名
张三
李四
王五
老六
'''
#将html网页源码加入带etree中
html = etree.parse(StringIO(test_html))
print(html)
结果:
上述代码中,先是随机构造了部分html源码,并将其放入lxml的etree对象中。然后待解析的html就可以通过lxml去进行操作。最后对这段html进行不同的提取操作。
获取所有li标签下的数据,并提取其内容:
list = html.xpath('//li')
for i in list:
print("数据:" + i.text)
结果:
数据:2112001
数据:2112002
数据:2112003
数据:2112004
数据:张三
数据:李四
数据:王五
数据:老六
通过属性class获取值
#获取class为blank的所有li标签,并提取其内容
blank_li_list = html.xpath('//li[@class="blank"]')
for l in blank_li_list:
print("数据:" + l.text)
结果:
数据:2112003
删除子元素
比如要删除第一个ul下的第一个li元素
获取html中的所有ul标签
first_ul = html.find("//ul")
#获取first_ul下的所有li标签
ul_li = first_ul.xpath("li")
#打印长度
print(len(ul_li))
# 删除操作
ul_li.remove(ul_li[0])
#打印长度
print(len(ul_li))
结果:
4
3可以看到获取第一个ul标签,接着取出第一个ul下的所有li标签。输出其长度为4,删除第一个li之后,还是剩下3个li,因此输出3。
获取最后一个ul标签下的所有li数据
last_ul_li = html.xpath('//ul[last()]/li')
for l in last_ul_li:
print("数据:" + l.text)
结果:
数据:张三
数据:李四
数据:王五
数据:老六
实战:提取小说所有章节

现在我们来获取《大主宰》整本小说的所有章节,包括章节名称和章节链接。
目标:《大主宰》整本小说的所有章节
链接:http://book.chenlove.cn/novel/36.html#catalog
思路:先获取网页源码,接着通过lxml的xpath模块去解析网页源码,并提取出所有章节的标题和章节链接,最后打印输出。
在开始之前,先预览一下网页页面:

通过按F12,点击elements/元素查看网页源代码:
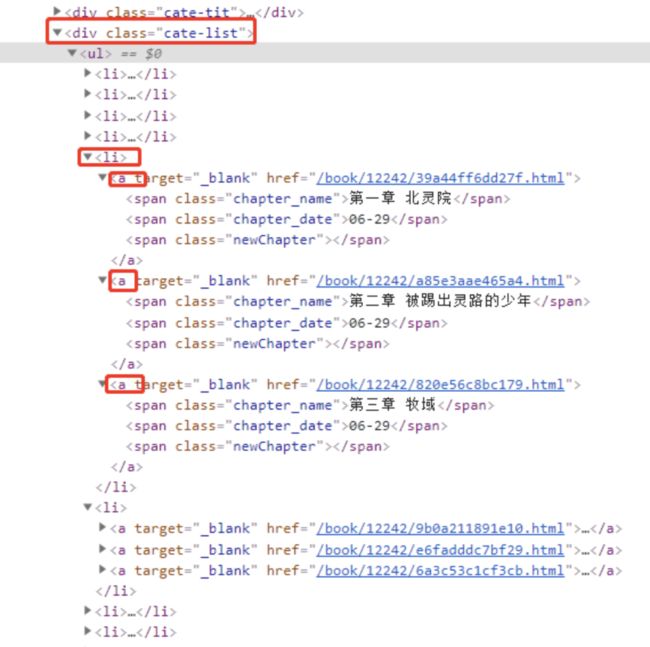
通过查看源代码,我们可以知道所有章节标签内容都在class为cate-list的div标签中,ul下的所有li对应网页中每三章为一行。因此获取到li之后,再解析li标签下的三个a标签。完整代码如下:
import requests
from lxml import etree
# 设置代理服务器
headers = {
'User_Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36'
}
#请求链接
url = "http://book.chenlove.cn/novel/36.html#catalog"
response = requests.get(url, headers=headers)
if response.status_code == 200:
# 转化为utf-8格式,不加这条语句,输出爬取的信息为乱码
response.encoding = 'utf8'
#获取到源码
html = etree.HTML(response.text)
ul_li_list = html.xpath('//*[@class="cate-list"]/ul/li')
通过发送requests请求获取网页源码,并提取出所有小说章节,即class为cate-list的div标签下的所有li标签。接着从li标签中提取出章节标题和章节链接。
for l in ul_li_list[4:]:
for i in l:
href = i.xpath('.//@href')[0]
title = i.xpath('.//span[@class="chapter_name"]/text()')[0]
print(title,href)集合ul_li_list中存储着所有的li标签,从第五个li开始才是第一章(前面4行是最新章节),因此我们需要从第5行开始,然后通过xpath提取出li中的含有的章节标题和章节链接。
输出:
第一章 北灵院 /book/12242/39a44ff6dd27f.html
第二章 被踢出灵路的少年 /book/12242/a85e3aae465a4.html
第三章 牧域 /book/12242/820e56c8bc179.html
第四章 大浮屠诀 /book/12242/9b0a211891e10.html
第五章 大千世界 /book/12242/e6fadddc7bf29.html
第六章 灵力增幅 /book/12242/6a3c53c1cf3cb.html
第七章 慕元 /book/12242/7717207387f31.html
........