爬虫09——xpath解析
1. 了解xpath
xpath是在XML文档中搜索内容的一门语言
html是xml的一个子集
1
野花满地香
1.23
周大强
周诺宁
在xml中,这些标签都被称为节点,在以上案例中,
总而言之,谁包着谁,谁在外层,谁就是父节点。
#当要查找price的值,应该先从文档的根目录开始寻找
/book/price2. xpath入门
2.1 安装lxml模块
利用lxml模块中的一些功能就能使用xpath解析了
pip install lxml2.2 一些简单案例(语法规则)
# xpath 是在XML文档中搜索内容的一门语言
# html 是xml的一个子集
from lxml import etree
xml = """ #首先导入一个xml数据
1
野花满地香
1.23
周大强
周诺宁
周杰伦
蔡依林
热热热热热热
热热热热热热1
热热热热热热3
胖胖陈
胖胖不陈
"""
tree = etree.XML(xml)
#1. 想要拿到name的值
result1 = tree.xpath("/book/name/text()") # text()是用来获取文本值
print(result1) # >>> ['野花满地香']
#2. 获取author里nick的值
result2 = tree.xpath("/book/author/nick/text()")
print(result2) # >>> ['周大强', '周诺宁', '周杰伦', '蔡依林']
#因为div下的nick与上面的nick不是在同一阶级上,所以找不到
#3. 获取author中div里的nick值
result3 = tree.xpath("/book/author/div/nick/text()")
print(result3) # >>> ['热热热热热热']
#4. 获取author中所有的nick值
result4 = tree.xpath("/book/author//nick/text()") # // 获取父节点下所有的后代
print(result4) # >>> ['周大强', '周诺宁', '周杰伦', '蔡依林', '热热热热热热', '热热热热热热1', '热热热热热热3']
#5. 获取热,热1
result5 = tree.xpath("/book/author/*/nick/text()") # * 表示获取该阶级下所有的nick值 相当于斗地主中的赖子
print(result5) # >>> ['热热热热热热', '热热热热热热1']
#6. 获取book下所有的nick值
result6 = tree.xpath("/book//nick/text()")
print(result6) # >>> ['周大强', '周诺宁', '周杰伦', '蔡依林', '热热热热热热', '热热热热热热1', '热热热热热热3', '胖胖陈', '胖胖不陈']
2.3 一些深入案例(语法规则)
2.3.1 首先创建一个html文件,用于案例的练习
Title
李嘉诚
胡辣汤
2.3.2 案例练习 代码+解析
from lxml import etree
#新版本的lxml中没有集成etree,所以需要在b.html后增加一个解析
tree = etree.parse("b.html",etree.HTMLParser()) #parse用于导入文件
#1. 获取百度,谷歌,搜狗
result1 = tree.xpath('/html/body/ul/li/a/text()')
print(result1) # >>> ['百度', '谷歌', '搜狗']
#2. 根据索引来寻找想要的值->获取百度,谷歌,搜狗中其中的某一个
# xpath中索引是从1开始的
result2 = tree.xpath('/html/body/ul/li[1]/a/text()') # [数字] 表示索引
result3 = tree.xpath('/html/body/ul/li[2]/a/text()')
result4 = tree.xpath('/html/body/ul/li[3]/a/text()')
print(result2) # >>> ['百度']
print(result3) # >>> ['谷歌']
print(result4) # >>> ['搜狗']
#3. 根据属性对应的属性值来寻找元素->寻找href的值是大炮的元素
result5 = tree.xpath('/html/body/ol/li/a[@href="dapao"]/text()') # [@xxx=xxx] 表示属性的筛选
result6 = tree.xpath('/html/body/ol/li/a[@href="huojian"]/text()')
print(result5) # >>> ['大炮']
print(result6) # >>> ['火箭']
#4. 遍历元素
request7 = tree.xpath('/html/body/ol/li')
for li in request7:
# print(li) # 此时的request7里应该是存放着三个li节点
#1. 接着从每一个li中提取到文字信息
# 但是现在的li已经不是整体的根节点了,所以需要增加 ' ./ ' 表示定位到当前节点
result8 = li.xpath('./a/text()') # 在li中继续去寻找,此时为相对查找
print(result8)
#2. 获取到值对应的属性,-> 拿到href值 @属性
result9 = li.xpath('./a/@href') #拿到属性对应的值是加[],去掉[]就是获取属性了
print(result9)
'''
['飞机']
['feiji']
['大炮']
['dapao']
['火箭']
['huojian']
'''
#5. 获取ul下所有的href属性
result10 = tree.xpath('/html/body/ul/li/a/@href')
print(result10)
# >>> ['http://www.baidu.com', 'http://www.google.com', 'http://www.sogou.com']
2.3.3 一些小技巧
首先在浏览器中打开我们创建的html,右键点击检查,当页面的内容很多,看起来很乱的时候,可以点击想要的内容,会发现在检查栏中就会给你定位到相应的位置上。

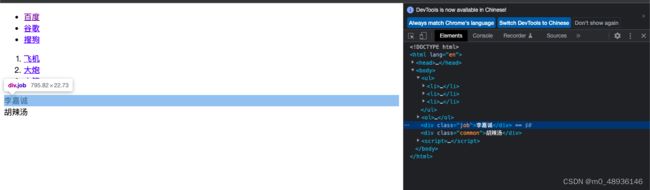
然后再右键,在copy栏中就会有xpath复制的选项,此时我们复制它的xpath。
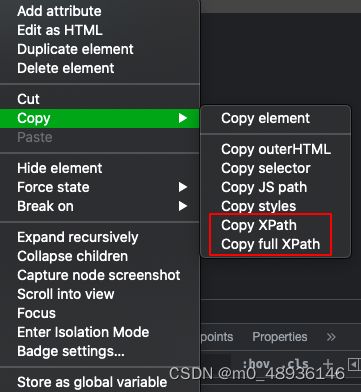
/html/body/div[1]接着我们将复制的xpath导入代码中就可以得到我们想要的数据了
#6. 通过网页复制的xpath进行获取数据
result10 = tree.xpath('/html/body/div[1]/text()')
print(result10) # >>> ['李嘉诚']3. xpath实战,抓取猪八戒网信息
网站地址【宁波美工价格_宁波美工报价】_宁波美工服务外包信息-宁波猪八戒网
爬取每个店铺的名字、价格、简介以及地址
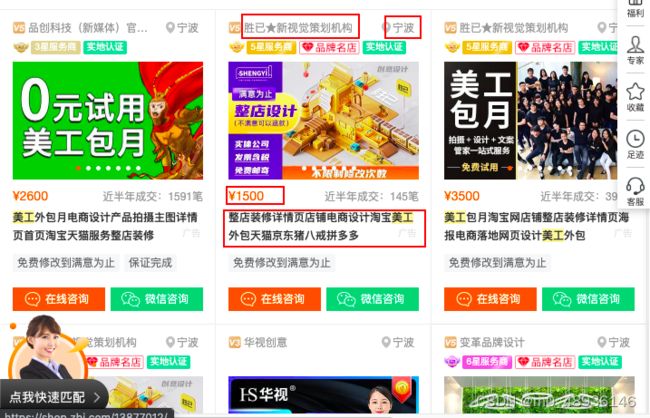
3.1 首先查看这些信息是否在源代码上,通过搜索相关字可以发现,是存在源代码上的
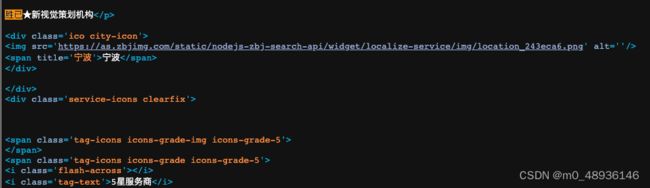
3.2 接着通过上面学习的案例,一层一层的抓取内容就可以了
通过对源代码的解析,可以发现框框圈起来的是所有的服务商,下面对应的每个div就是我们要找的每家服务商的信息。,可以使用上面的小技巧来获取xpath,或者从根节点一层一层的寻找。
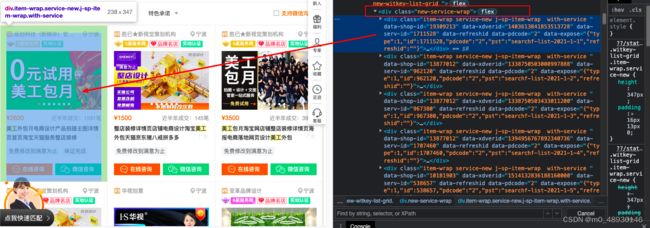 通过获取xpath,我们还需要进行稍稍的修改,需要将最后那个div[1]改为div,因为[1]表示全文中的第一个服务商,而我们需要获取的是所有服务商的信息,所以需要直接定位到div,表示整体。
通过获取xpath,我们还需要进行稍稍的修改,需要将最后那个div[1]改为div,因为[1]表示全文中的第一个服务商,而我们需要获取的是所有服务商的信息,所以需要直接定位到div,表示整体。

通过仔细的观察,我们就能获取到每一家服务商的所有信息。这边只输出一家服务商,所有服务商信息就只需要将breal注释掉就好了。
import requests
from lxml import etree
url = 'https://ningbo.zbj.com/search/f/?kw=%E7%BE%8E%E5%B7%A5'
response = requests.get(url=url)
#print(response.text)
#解析
html = etree.HTML(response.text)
# 定位
# 获取到的xpath -> /html/body/div[6]/div/div/div[2]/div[5]/div[1]
divs = html.xpath('/html/body/div[6]/div/div/div[2]/div[5]/div[1]/div') # 获取到所有服务商
#遍历,div就表示页面上一个个的服务商
for div in divs:
name = div.xpath('./div/div/a[1]/div[1]/p/text()') #服务商店名
addr = div.xpath('./div/div/a[1]/div[1]/div/span/text()') #服务商地址
money = div.xpath('./div/div/a[2]/div[2]/div[1]/span[1]/text()') #服务费
tittle = div.xpath('./div/div/a[2]/div[2]/div[2]/p/text()') #标签
print(name)
print(addr)
print(money)
print(tittle)
break #用于方便观察,所以只输出一次运行结果

但是,观察运行结果可以发现,还不够完善,需要再修一修
3.3 完善
#遍历,div就表示页面上一个个的服务商
for div in divs:
name = div.xpath('./div/div/a[1]/div[1]/p/text()')[1].strip('\n') # 服务商店名
addr = ''.join(div.xpath('./div/div/a[1]/div[1]/div/span/text()')) # 服务商地址
money = ''.join(div.xpath('./div/div/a[2]/div[2]/div[1]/span[1]/text()')).strip('¥') # 服务费
tittle = ''.join(div.xpath('./div/div/a[2]/div[2]/div[2]/p/text()')) # 标签
print(name)
print(addr)
print(money)
print(tittle)
break # 用于方便观察,所以只输出一次