python画图分析问卷(含多选题)
jupyter notebook环境下~
这是一个很奇妙的开始,老师让我做一个问卷,调查学校的文创产品销售情况,排出最受欢迎的文创产品。由于是大数据专业的,就不防用python分析一下咯~
问卷
问卷,我使用的问卷星做的,之后查看结果可以下载详细的数据报告,是以excel储存的。在Jupyter notebook分析中我们一般用csv格式,所以打开excel另存为.csv。
预处理数据
数据分析第一步,预处理数据,首先将数据分析最常用的包导入numpy、pandas、csv画图所要用的包matplotlib,seanborn等(根据需要,之后再导入也不迟)
data.head()查看一下数据的前五行:

由于在此不需要分析提交时间 ,IP之类的特征值,可以直接删去,然后把索引标题进行转化一下,便于之后引用。
data.drop()函数用于扔掉不要的行或列,axis=1表示列,axis=0表示行
data = data.drop(['序号','提交答卷时间','所用时间','来源','来源详情','来自IP'], axis=1)
data.columns=[]是一种强制改变 列的名字的方式(直接覆盖原来的列名)
data.columns=['class','gender','major','buy','buy_what','buy_for','distribute_what','guess_what','ideas']
紧接着用循环的方式将年级,性别,专业,是否购买过这几项数据转化为更加方便的数据类型(代替原有的string),如:char、int,更加方便。
- 用int类型代替年级和性别:
i=0
for item in data['class']:
if item=='大三':
data['class'][i]=3
i=i+1
elif item =='大二':
data['class'][i]=2
i=i+1
elif item =='大一':
data['class'][i]=1
i=i+1
elif item =='大四':
data['class'][i]=4
i=i+1
else:
data['class'][i]=5
i=i+1
i=0
for item in data['gender']:
if item=='男':
data['gender'][i]=0 #boy
i=i+1
else:
data['gender'][i]=1 #girl
i=i+1
- 用char类型代替专业(专业前有对应的选项字符,保留其字符即可):
i=0
for item in data['major']:
# print(item[0])
data['major'][i]=item[0]
i=i+1
是否购买同理~
再此查看数据data.head():

数据变得更加简介,明了~
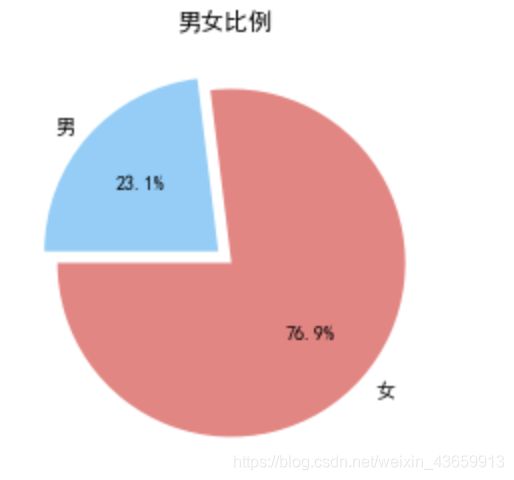
男女比列饼图
下面这行代码,非常快速的统计了gender中男女人数分别是多少,而不必采用循环的方式进行数值统计:
data['gender'].value_counts()
![]()
同时补充:
zero_col_count = dict(df[0].value_counts())#统计第0列元素的值的个数
three_row_count = dict(df.loc[3].value_counts())#统计第3行元素的值的个数
画饼图
我看了很多博客,找了画饼图最简单的代码:
labels标记出要画为几个板块,share表明分别对应的百分比是多少,explode表明每块饼之间的裂缝大小。
- explode:一个列表,用于指定每块饼片边缘偏离半径的百分比
- labels:每份饼片的标签 autopct:数值百分比的样式
- startangle:起始角度,跟四象限的角度一致
- shadow:是否绘制阴影
- colors:饼片的颜色
开始绘制饼图:
labels = ['女','男']
count=156
share =[120/count,36/count]
# 设置分裂属性
explode = [0.05, 0.05]
# 分裂饼图
plt.pie(share, explode = explode,
labels = labels, autopct = '%3.1f%%',
startangle = 180, shadow = False,
colors = ['lightcoral', 'lightskyblue'])
# 标题
plt.title('男女比例')
plt.savefig("./boy_girl.png",dpi=500,bbox_inches = 'tight')
plt.show()
savefig的时候添加了dpi即分辨率这个参数,因为发现直接存图的图片是非常糊的,所以加上这参数后,瞬间清晰!!(我这里的图都是直接从JN上截图的嘻嘻,所以糊)
图的颜色和字体
图的颜色选择可以参考https://matplotlib.org/gallery/color/named_colors.html#sphx-glr-gallery-color-named-colors-py官方文档,非常完整的配色,但记住要先import以下几个包:
#作图分析
import matplotlib as mpl
import matplotlib.pyplot as plt
# import seaborn as sns
import matplotlib
matplotlib.colors
matplotlib.colors.rgb_to_hsv
matplotlib.colors.to_rgba
matplotlib.figure.Figure.get_size_inches
matplotlib.figure.Figure.subplots_adjust
matplotlib.axes.Axes.text
matplotlib.axes.Axes.hlines
mpl.rcParams['font.sans-serif'] = ['SimHei']
最后一行设置中文显示十分重要!!![‘SimHei’]为字体,你也可以自己选一种字体,这样保证画出来的图中文字可以显示,就不是框框了!
男女差异
重点观察了男女生自己买文创产品的用途,已经买的类型的区别:
首先,将男女生数据分别提出来,下列代码示例将男生数据提出:
(因为我们之前把男生定为0,女生定为1),则排序后位于前列的是男生数据:
- 以男生数据为例:
#男生数据
data_sortsex=data.sort_values(by=['gender']) #将整体数据排序
data_boy=data_sortsex.iloc[0:36]
data_boy.head()
这行data_boy=data_sortsex.iloc[0:36]的作用是提取出data中[0:36]的行数据。如下:

对男生数据进行统计,绘制男生在不同专业的比例:

-
作出男生专业分布饼图
同样为饼图:
labels = ['理工类','文史类','艺体类']
count=boys_count
share =[27/count,9/count,0/count]
# 设置分裂属性
explode = [0.05, 0.05, 0.05]
# 分裂饼图
plt.pie(share, explode = explode,
labels = labels, autopct = '%3.1f%%',
startangle = 180, shadow = False,
colors = ['lightgreen', 'lightskyblue', 'gold'])
# 标题
plt.title('男生的专业分布')
plt.savefig("./boy_major.png",dpi=500,bbox_inches = 'tight')
plt.show()

可以看到在我的调查问卷中,男生大多来源于理工类,这也和我的专业有关(大多都是我的同学在填啦,怎么会不是理工的呢··)
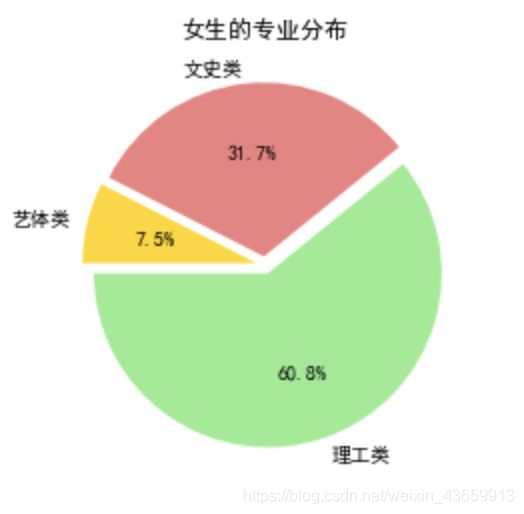
同理,女生的专业分布
-
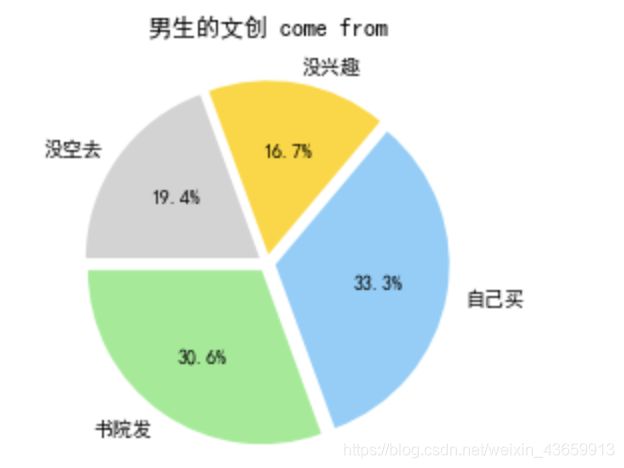
标题男生手中的文创产品来自于?自己买?书院发?
与之前几乎一样的代码绘制:
在这里可以比较一下女生:
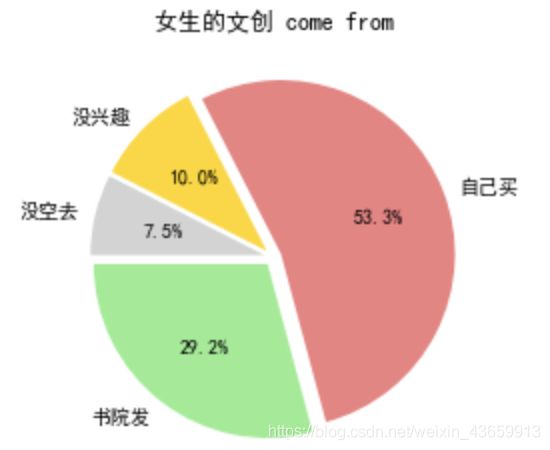
很明显,女生的购买力是非常强滴~
-
(多选题分析)为什么买?买什么?
首先,将男生自己买文创产品的数据提出来:
data_boy_buy = data_boy[data_boy.buy==1]
data_boy_buy.head() #自己买文创产品的男生数据
查看一下:

我们可以看到buy_for那一项有很多选项,当时设置的为多选题,每个选项由“┋”进行分割,所以,先将其split之后,再循环统计的方式,输出每一个选项的个数:
y = [x for x in data_boy_buy['buy_for'].str.split('┋')]
self = 0
schoomate = 0
graduate = 0
family = 0
younger = 0
for item in y:
# print(item)
for select in item:
# print(select[0])
if select[0]=='自':
self = self+1
elif select[0]=='毕':
graduate = graduate + 1
elif select[-1]=='妹':
younger = younger + 1
elif select[1] == '亲':
family = family +1
else:
schoomate = schoomate + 1
print(self)
print(schoomate)
print(graduate)
print(family)
print(younger)
-###柱状图(条形图)
x=np.arange(5)
labels = ('送同学','自己买着用', '毕业留念', '送家人','送学弟学妹')
share = [9/12, 8/12, 4/12,3/12,2/12]
plt.bar(x,share,color='lightskyblue', tick_label=labels) # 做柱状图
for a,b in zip(x,share):
plt.text(a,b,"%.1f%%"%(b*100),ha='center', va= 'bottom',fontsize=9)
plt.ylabel('percentage')
plt.xlabel('buy_for')
plt.title('男生买文创 for',fontsize=15)
plt.savefig("./boy_buy_for.png",dpi=500,bbox_inches = 'tight')
plt.show()
代码for a,b in zip(x,share): plt.text(a,b,"%.1f%%"%(b*100),ha='center', va= 'bottom',fontsize=9)用于标注出条形图的数值: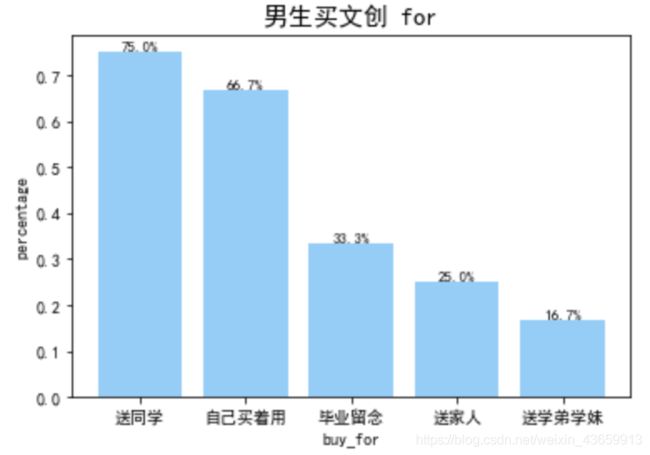
同理,女生:
可以发现,女生不仅在文创产品上投入money,男生更多为了送同学or npy买,但女生更多为了买着自己用,且女生比男生更想念着家人哦~(不愧是小棉袄嘻嘻)
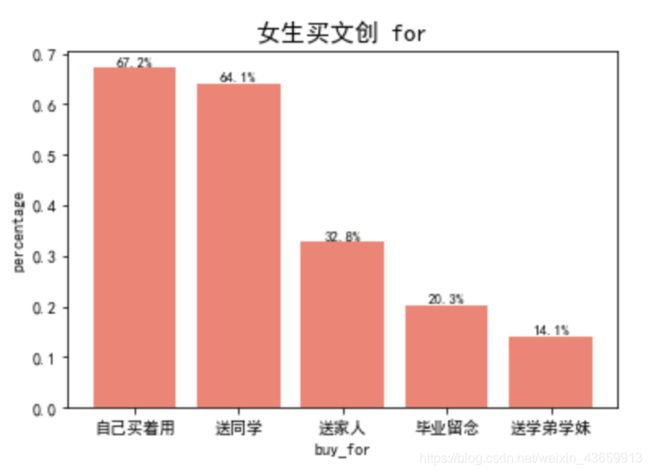
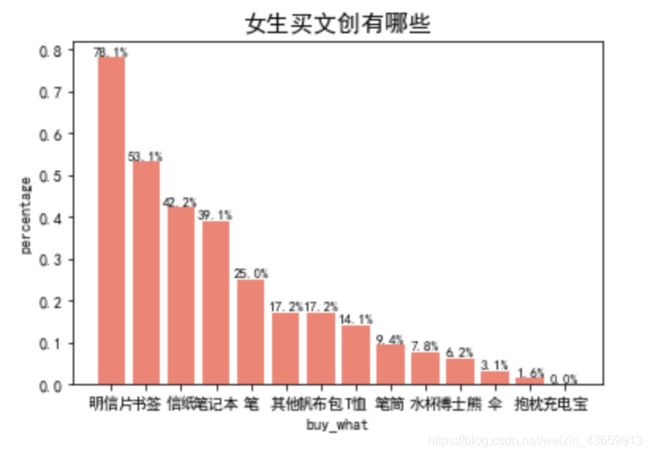
统计top文创产品,和上述几乎一致,唯一不同之处,我用一个字典dict来存储每一类的个数,方便以后排序等操作:
y = [x for x in data_boy_buy['buy_what'].str.split('┋')]
bwhat={'ming':0,'book':0,'T':0,'letter':0,'cup':0,'note':0,'pen':0,'bag':0,'tong':0,'bear':0,'um':0,'hug':0,'charge':0,'others':0}
other_boy=[]
for item in y:
for select in item:
if select[0]=='明':
bwhat['ming']=bwhat['ming']+1
elif select[0]=='书':
bwhat['book'] = bwhat['book'] + 1
elif select[0]=='T':
bwhat['T'] = bwhat['T'] + 1
elif select[0] == '便':
bwhat['letter']= bwhat['letter'] +1
elif select[0] == '水':
bwhat['cup']= bwhat['cup'] +1
elif select[1] == '记':
bwhat['note']= bwhat['note'] +1
elif select[-1] == '筒':
bwhat['tong'] =bwhat['tong'] + 1
elif select[0] == '笔':
bwhat['pen']= bwhat['pen'] +1
elif select[0] == '帆':
bwhat['bag'] = bwhat['bag'] +1
else:
bwhat['others'] = bwhat['others'] + 1
other_boy.append(select)
查看字典储存内容,以及同学们自己填写的购买的其他文创产品:

按照之前同样的做柱状图的方式进行绘制:

同样,女生:
书院购买也做相同的分析:
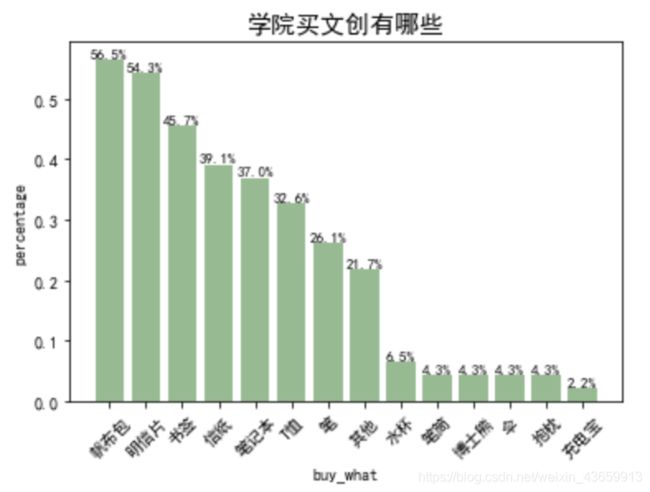
补充:如何把x轴上的标签选择角度:
旋转45度(如上图)
import pylab as pl
pl.xticks(rotation=45)
-
other ideas
不难发现,top6的文创产品是:明信片,书签,信纸,笔记本,笔,T恤~
同时,我们也调查了同学们想要的新颖的文创有哪些?
比如:(同学们真是脑洞大开~maybe哪一天**屋就能看见这些奇妙的文创产品了呢~)

以上就是我的问卷分析啦~还是挺有意思的?叭?