teamtalk原理
再贴一遍架构图
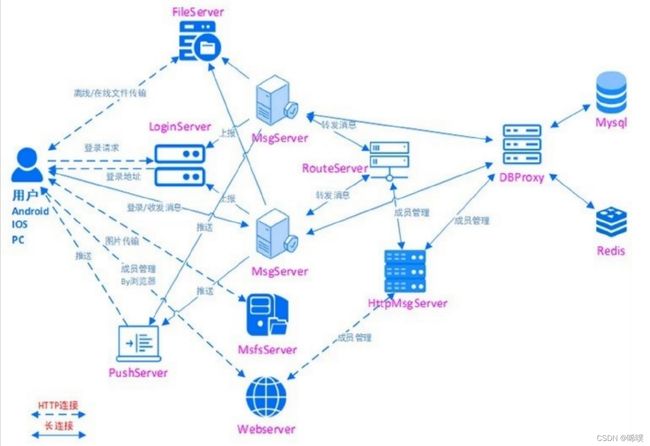
从图中可以看出,对外使用的是http连接,内部使用的是tcp长连接。
类的命名规则:xxxServConn是模块连别的模块,xxxConn是别的模块连它。
协议设计
teamtalk采用protobuf进行序列化
typedef struct {
uint32_t length; // the whole pdu length
uint16_t version; // pdu version number
uint16_t flag; // not used
uint16_t service_id; //
uint16_t command_id; //
uint16_t seq_num; // 包序号
uint16_t reversed; // 保留
} PduHeader_t;
应该不需要再解释了。
网络模型
teamtalk是reactor网络模型,具体靠CBaseSocket类和CEventDispatch类来实现。CBaseSocket用来管理socket io,作为client或者server都需要实例化一个CBaseSocket,而CEventDispatch类是reactor的触发器,epoll相关的函数都在此调用。
此外还有数据库的设计,要么看一下那个sql文件,要么直接进mysql看一看就会清楚,不解释。
下面介绍各个模块的工作流程,完整的代码就不贴了,只会贴一些辅助介绍的代码。
login_server
有这么一张图,比较清晰地介绍了login_server的流程。
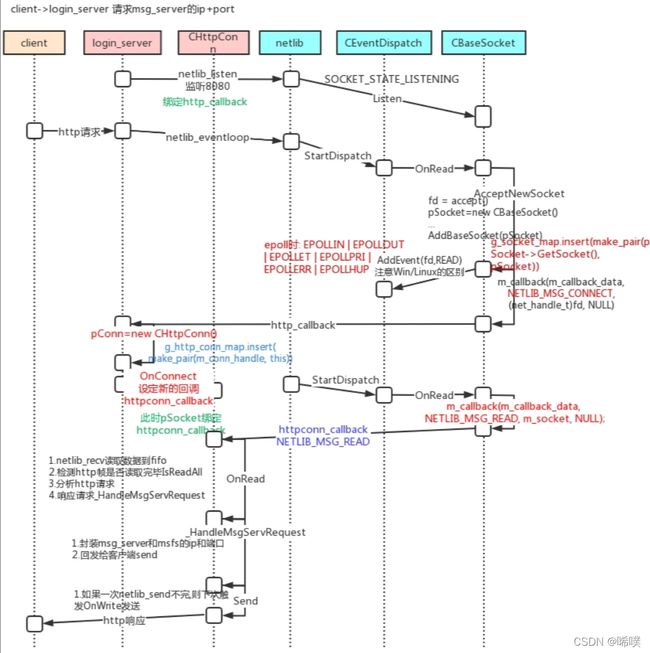
比较具有迷惑性的一点是,login_server是用来做负载均衡的,给不同客户端返回负荷最小的msg_server,也就是说,登录业务也是在msg_server中完成的。
msg_server
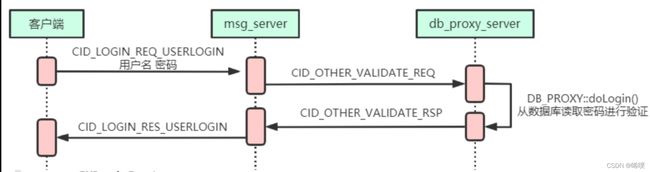
用户名密码校验
这里介绍一下密码的检验。肯定不能明文传输密码,这里的做法是,注册时客户端先对密码做一次md5运算,然后服务端再加上一个随机值,叫做混淆值,然后对这个加上了随机值的密码再做一次md5,注意这个混淆值和客户端传过来的第一次md5密码都会存到数据库。为什么要做两次md5?主要是为了避免撞库。
用户状态同步
为了防止用户多端登录,这里要进行检验。这里的做法,移动端和电脑端可以分别登一个,什么意思?就是说pc登录了,另外的pc或mac登录,就要把原来的pc登录端给踢掉;安卓和苹果端也是如此。但是如果登了一个pc,再登一个安卓,是可以的。
当然,具体怎么设置,可以自己修改成为自己想要的样子,比如允许多端登录,或者移动和电脑端也不能同时在线,或者登上了不能再登,等等。
值得注意的是,这里的获取状态,是去route_server查询。
同步信息
登录后,客户端会向msg_server发送消息,拉取部门信息、更新用户列表、请求群组id列表、获取最近会话等。
请求群组id列表中的做法,是一次去数据库拉取全部的群,没有分批,可以改成根据更新时间来增量查询。
获取最近会话时,是增量更新,注意这个会话表会在数据库中存两份,收发是有方向的,两个方向各一份。这样一来,就算一端请求删掉会话,另一端也不受影响。
客户端在点开一个消息时,才会拉取具体消息。一个是客户端也有数据库,会做一些数据的缓存,比如部门信息等,另一个,对于群组消息而言,拉取群成员列表是在点开群会话时做的。
实时更新用户状态
客户端登录,通过msg_server给route_server上报状态。
如果route_server重启,msg_server也会上报状态,把连上自己的所有客户端的状态上报给route_server。
离线状态更新,一是下线会上报,二是防止突然断线,msg_server会与客户端之间进行心跳保持,如果msg_server一段时间内没有收到某个客户端的回应,则认为该客户端下线,上报给route_server。第二种情况,这个状态的更新就有延迟了,其实没有关系,又不是发射火箭,客户一般能接受。
这里可以看出,route_server可能成为性能瓶颈,优化的方法,一是做成集群,二是做一个信息中心。还有一点,msg_server并没有与route_server建立心跳机制,也就是说,如果msg_server崩了,用户的状态信息不会更新,只有等到下次用户登录其他msg_server才会更新。因为如果内部保持心跳,那么内部的数据将会非常多。其实这一点延迟也能接受,掉线了重新登嘛,大家应该都有过这个体验。
获取未读消息数量
这个未读消息数量,是存到redis中的,为什么?因为服务器中,发消息的数量很大的,如果存到mysql,来一条消息就+1,数据库会受不了的。计算用户未读消息总数,是在服务器中做的。我一直认为这个设计不好,想把这个功能做到客户端里面,减轻一点服务社的压力。注意,消息本身是存到mysql的。
未读消息数量什么时候清零呢?客户点击会话阅读消息,客户端会发ack,当然不是tcp的那个ack,服务器收到后清零。
发送消息
为了确保消息可靠性,客户端发送消息后,需要等到服务器发送ack才认为发送成功。注意这个ack也不是tcp的ack。贴一下相关代码
enum MessageCmdID{
...
CID_MSG_DATA_ACK = 0x0302; //
CID_MSG_READ_ACK = 0x0303; //
...
};
发送方有一个发送队列,发送出去的消息会先存到这个队列中,如果收到了对应(pdu中seq_num字段)的ack,就从队列中删除。如果没有收到ack,会有一个超时检测机制,超时还未收到ack,消息会重发。
这个ack会区分离线和在线消息。如果对方在线,需要等到对方回应服务器,服务器才会回应发送端;如果是离线消息,服务器确认存到数据库了就回ack。
消息的顺序问题。通信双方会共同维护一个msg_id。刚才提到,消息发送给服务器,服务器会回ack,字段里就有msg_id,客户端根据这个msg_id来排序。服务端怎么给msg_id呢?一般是根据收到消息的先后顺序依次+1,这样一来,这个msg_id就需要放到redis了。有时我们遇到过这种情况,两端同时发消息,我感觉是我先发的,一刷新,发现消息在对方发过来的消息的下面,就是自己的消息没跑赢对方的消息。这个情况应该也能接受,毕竟同时发消息的情况也不太多。而且,即时通讯项目,一般会对客户端发送消息的频率做一个限制,比如1秒最多发一次。
发消息的时间。消息里面有个字段create_time,来存储消息的发送时间。这个时间怎么同步呢?一种做法是用服务器的时间,对于多台服务器而言,利用NTP服务器专门来给各个服务器同步时间。
可以看出,msg_server的负荷还是比较大的,我们可以把单聊、群聊消息的功能分开,做成不同的msg_server,单聊群聊走不同的server,降低服务器的负荷
route_server
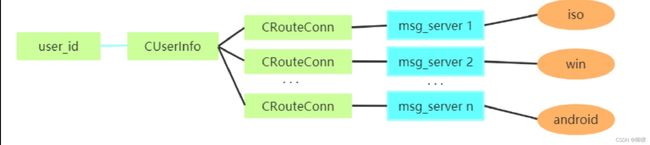
⼀台消息转发服务器,客户端消息发送到msg_server。msg_server判断接收者是否在本地,是的话,直接转发给⽬标客户端。否的话,转发给route_server。route_server接收到msg_server的消息后,获取to_id所在的msg_server,将消息转发给msg_server。msg_server再将消息转发给⽬标接收者。route_server只和msg_server进⾏通信,且是msg_server去连route_server,它们之间保持心跳。
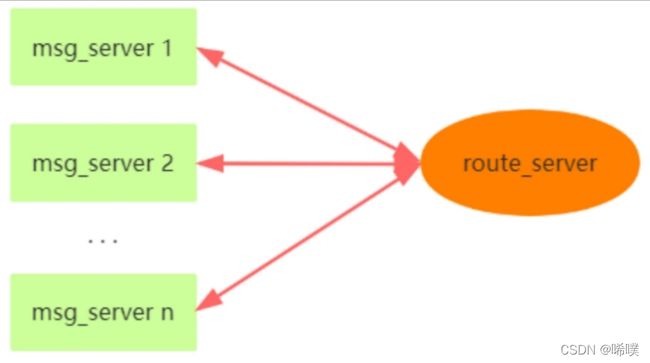
当存在多端登录时,不同的客户端可能登录在不同的msg_server(对于route_server来说,体现为CRouteConn连接),所以需要记录对应所有的msg_server连接。
上下线通知
主要是处理CID_OTHER_USER_STATUS_UPDATE命令。对于teamtalk⽽⾔,主要是给内部开发的,所以通讯录⾥的所有⼈都认为是好友,上线下线都通知到每⼀个⼈,所以,如果要商用,这块逻辑要改一改。具体逻辑,登录后查看route_server有没有保存同种端的连接,如果有则踢掉,如果不是同种端,广播信息告诉它,我登录了。
CID_BUDDY_LIST_USERS_STATUS_REQUEST命令用得比较多,是查询用户状态。
db_proxy_server
db_proxy_server是TeamTalk服务器端最后端的程序,它连接着关系型数据库mysql和nosql内存数据库redis。
teamtalk一共建了7个数据库,mysql两个,redis五个,具体每个库里面是什么样,自己去库里看
- TeamTalk_Matser MySQL主数据库,用来写入数据
- TeamTalk_Slave MySQL从数据库(单机配置时涉及都是同⼀个数据库),用来读取数据
- unread 未读信息实例 Redis 数据库
- group_set 群组设置实例 redis数据库
- token 实例 redis数据库
- sync实例 redis数据库 同步功能
- group_member redis数据库
注意如果数据库的压力过大,需要分库分表,这里teamtalk只做了一个简单的分表,单聊和群聊消息分别8张表,存到哪张表用relatedId%8来决定。
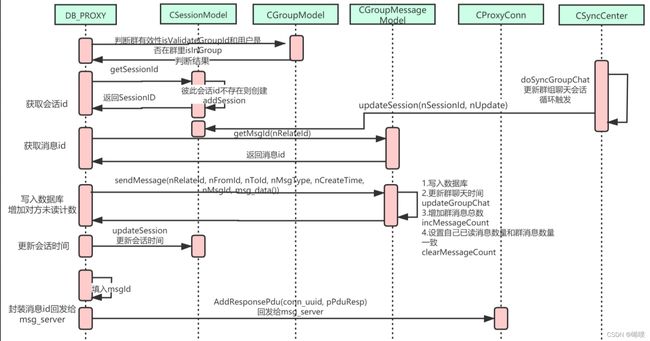
响应流程
主要是利用线程池与数据库交互,各个Model类来操作mysql和redis。注意数据回发给客户端是在io中做的,不是在线程池中做的,接收数据也是在io中做,然后转给线程池的。因为如果给线程池增加收发的功能,会增加对线程池操作的难度。这一点是不是有那么一丢丢似曾相识?对,redis就是这样的,io线程负责io,工作线程负责处理数据。

这里连接池的连接数据与线程池的线程数量保持一致就行,因为这个连接池的连接是同步的,线程数一般还是设2n。
发送消息
分为单聊

和群聊。
注意体会两者区别。
最后提示一下,离线文件会把离线文件的信息(注意不是文件本身)存到数据库,用户上线后,去数据库拉信息,再去对应的file_server获取文件。
之前提到,未读消息计数是在redis中,其实群成员列表也存在redis中,用了hash结构。加入成员会在mysql和redis中分别插入数据,删除成员同样会在两个数据库中删除数据。群成员放在缓存中,因为每个群成员的未读消息计数、每个群成员的会话信息、查看群推送消息,这些都需要遍历,交给mysql受不了。
CSyncCenter类
单独介绍一下这个类。它是一个独立的线程,定时更新所有的群成员的会话信息,目前是5秒更新一次,不能是群里有一个人发消息就更新,否则服务器压力大。
具体更新步骤:
- 获取群最后聊天时间,这就知道了哪些群需要更新会话(上次更新时间之后的所有群)
- 设置新的最后同步时间
- 根据群id获取群成员(redis做),然后更新每个群成员的这个群的会话信息。这一步有点耗时,可以考虑放到redis中。因为会话信息没有消息内容本身重要。
- 遍历群成员,查看是否有登陆,有就到msg_server发消息。
file_server
⽂件传输分2类:在线⽂件传输和离线⽂件传输。
在线传输
在线文件传输过程有两种,p2p和服务器转发。这里用的是服务器转发。
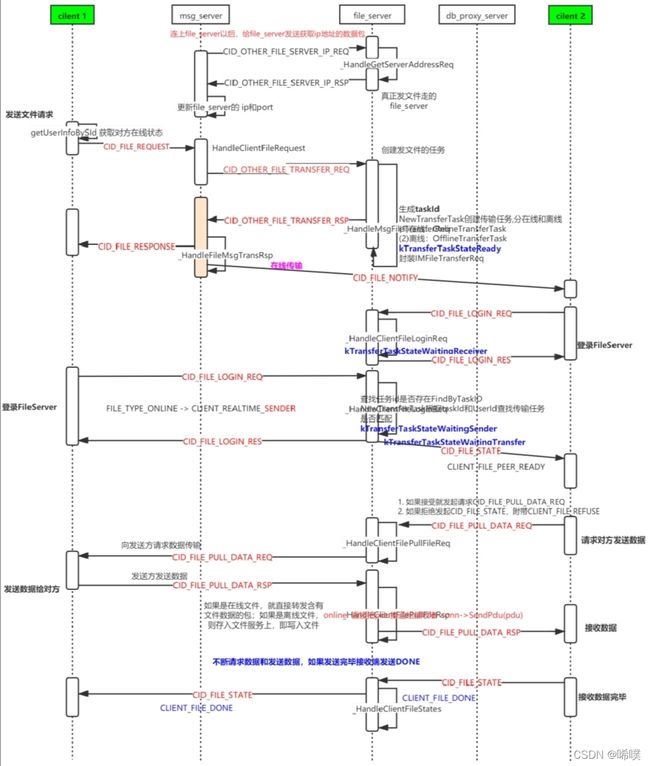
具体过程:客户端通过msg_server获取file_server的地址,并通知接收⽅有⼈要传输⽂件给他,然后发送⽅和接收⽅都登录到file_server,后续的状态和⽂件传输都转由file_server来处理,不再需要msg_server。在线⽂件传输没有做数据库的写⼊操作,没有中间缓存,服务器都是收到发送⽅的数据后原封不动转发给接收⽅。
离线传输

file_server先以⽂件的⽅式缓存离线⽂件(也可以做成http实现),离线推送请求需要以CID_FILE_ADD_OFFLINE_REQ的命令,在db_proxy_server调⽤DB_PROXY::addOfflineFile写⼊到⽂件。接收⽅上线后去服务器查询是否有离线⽂件CID_FILE_HAS_OFFLINE_REQ,db_proxy_server调⽤DB_PROXY::hasOfflineFile获取离线⽂件信息,最终也是要⽤CID_FILE_LOGIN_REQ登录file_server,进⾏⽂件⽂件的拉取。
注意这里数据是分批发送的,每次32KB。
teamtalk大概流程就是这样,具体细节需要自己看源码,这里不介绍源码是因为讲的话显得太啰嗦。在理解了源码之后,可以尝试实现一下注册的功能,这样添加用户的时候不需要跑去后台添加了。