ELK+Filebeat+Kafka分布式日志管理平台搭建
文章目录
- ELK+Filebeat+Kafka分布式日志管理平台搭建
-
- 为什么选择ELK+Filebeat+Kafka?
- Filebeat搭建
- Kafka搭建
- Elasticsearch搭建
- Logstash搭建
- Kibana搭建
ELK+Filebeat+Kafka分布式日志管理平台搭建
为什么选择ELK+Filebeat+Kafka?
在线上问题排查时,通过日志来定位是经常使用的手段之一。线上服务为了实现高可用往往采用多节点部署,又或者随着项目愈发复杂会考虑微服务架构,导致日志分散在不同的服务器上,排查问题就需要去多台服务器上查询日志,麻烦且低效。目前采用最多的日志服务的解决方案,是 使用 ELK 搭建的日志服务。
Logstash 是基于 JVM 的重量级的采集器,对系统的 CPU、内存、IO 等等资源占用非常高,这样可能影响服务器上的其它服务的运行。所以,Elastic NV 推出 Beats ,一个基于 Go 的轻量级采集器,对系统的 CPU、内存、IO 等等资源的占用基本可以忽略不计。因此,使用 Beats 采集数据,并通过网路传输给 Logstash,即 ELFK 架构。ELK+Filebeat 架构如下图所示:

随着 Beats 收集的每秒数据量越来越大,Logstash 可能无法承载这么大量日志的处理。虽然说,可以增加 Logstash 节点,提高每秒数据的处理速度,但是仍需考虑可能 Elasticsearch 无法承载这么大量的日志的写入。此时,可以考虑引入消息队列。Beats 收集数据,写入数据到消息队列中,Logstash 从消息队列中,读取数据,写入 Elasticsearch 中。ELK+Filebeat+Kafka 架构如下图所示:

Filebeat搭建
打开 Filebeat下载页面,选择想要的 Filebeat 版本。本文选择的是 Filebeat 8.6.2 版本。
第一步:解压 filebeat-8.6.2-linux-x86_64.tar.gz
tar -zxvf filebeat-8.6.2-linux-x86_64.tar.gz
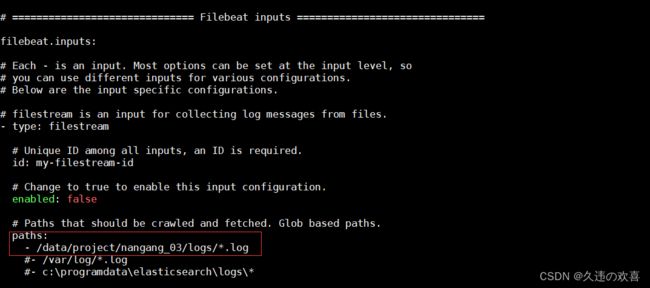
第二步:修改配置文件 filebeat.yml,如下图所示:

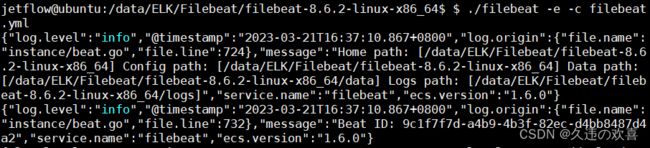
第三步:执行以下命令启动 Filebeat:
nohup ./filebeat -e -c filebeat.yml &
Kafka搭建
打开 Zookeeper 下载页面,选择想要的 Zookeeper 版本。本文选择的是 Zookeeper 3.8.0 版本。
打开 Kafka 下载页面,选择想要的 Kafka 版本。本文选择的是 Kafka 3.4.0 版本。
第一步:解压 apache-zookeeper-3.8.0-bin.tar.gz
tar -zxvf apache-zookeeper-3.8.0-bin.tar.gz
第二步:创建 zkData 文件夹:
mkdir /data/ELK/zookeeper/apache-zookeeper-3.8.0-bin/zkData/
第三步:新建 zoo.cfg 文件:
cp zoo_sample.cfg zoo.cfg
第四步:修改 zoo.cfg 文件,如下图所示:
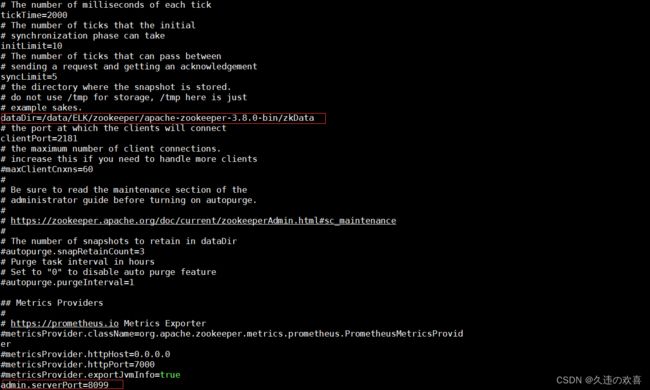
因为 zookeeper 默认需要使用 8080 端口,而 8080 端口往往会被占用,所以在配置文件中指定其他端口。
第五步:执行以下命令启动 zookeeper:
./zkServer.sh start
第六步:解压 kafka_2.12-3.4.0.tgz
tar -zxvf kafka_2.12-3.4.0.tgz
第七步:创建日志存储目录:
mkdir /data/ELK/Kafka/kafka-logs/
第八步:修改 server.properties 文件,如下图所示:
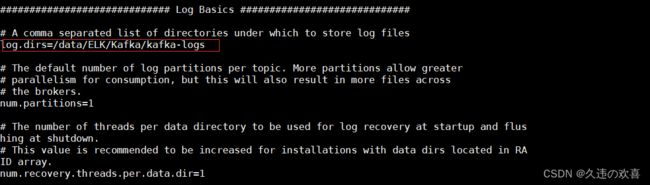
因为 Kafka 默认的 9092 端口被占用,所以将端口改为 9093。
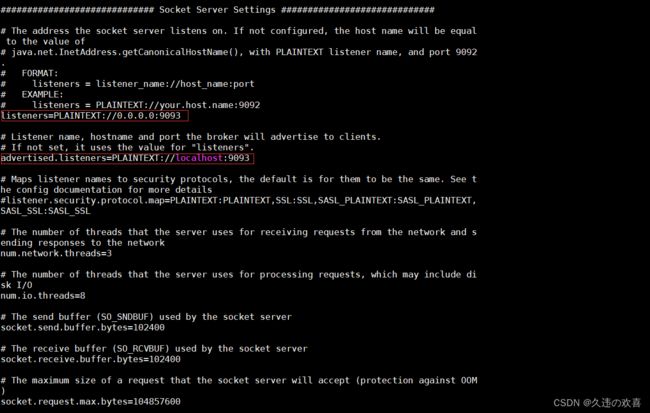
第九步:执行以下命令启动 Kafka:
nohup bin/kafka-server-start.sh config/server.properties &
第十步:执行以下命令创建 topic:
bin/kafka-topics.sh --bootstrap-server localhost:9092
--create --topic logstash --partitions 1 --replication-factor 1
--config retention.ms=15552000000 --config max.message.bytes=5242880
Elasticsearch搭建
打开 Elasticsearch 下载页面,选择想要的 Elasticsearch 版本。本文选择的是 Elasticsearch 8.6.2 版本。
第一步:解压 elasticsearch-8.6.2-linux-x86_64.tar.gz
tar -zxvf elasticsearch-8.6.2-linux-x86_64.tar.gz
第二步:在 root 权限下,修改 /etc/security/limits.conf ,配置以下内容:
* soft nofile 65535
* hard nofile 65535
修改完成后同时使用命令修改配置:
$ ulimit -n 65535
如果没有进行以上操作,启动时将会出现以下错误:
![]()
第三步:在 root 权限下,修改 /etc/sysctl.conf ,增加如下内容:
vm.max_map_count=655360
修改完成后,执行 sysctl -p 命令,使配置生效。
如果没有进行以上操作,启动时将会出现以下错误:
![]()
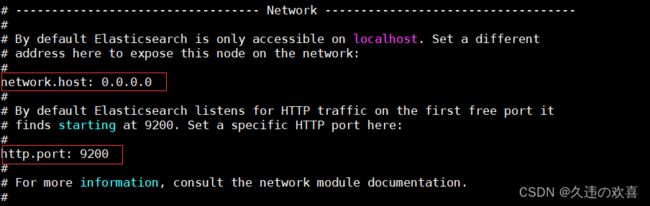
第四步:修改 elasticsearch.yml 配置文件,如下图所示:
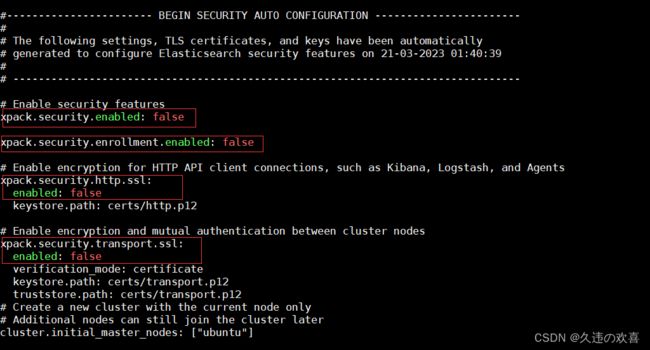
因为搭建的 Elasticsearch 是 8.X 版本,需要关闭 security 安全相关的功能。如下图所示:
第五步:执行 ./elasticsearch -d 命令后台启动 Elasticsearch。
启动后,通过 curl 命令验证是否启动成功,如下图所示:

Logstash搭建
打开 Logstash 下载页面,选择想要的 Logstash 版本。本文选择的是 Logstash 8.6.2 版本。
第一步:解压 logstash-8.6.2-linux-x86_64.tar.gz
tar -zxvf logstash-8.6.2-linux-x86_64.tar.gz
第二步:新建 logstash.conf 文件:
cp logstash-sample.conf logstash.conf
logstash.conf 文件内容如下图所示:

在 Logstash 中,定义了一个 Logstash 管道(Logstash Pipeline),来读取、过滤、输出数据。一个 Logstash Pipeline 包含三部分,如下图所示:
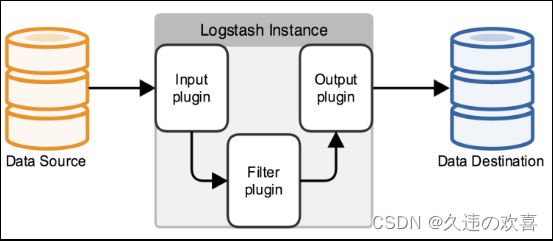
【必选】 输入(Input):数据(包含但不限于日志)往往都是以不同的形式、格式存储在不同的系统中,而 Logstash 支持从多种数据源中收集数据(File、Syslog、MySQL、消息中间件等等)。
【可选】 过滤器(Filter):实时解析和转换数据,识别已命名的字段以构建结构,并将它们转换成通用格式。
【必选】 输出(Output) :Elasticsearch 并非存储的唯一选择,Logstash 提供很多输出选择。
本文 Logstash 的 Input 的数据源为 Kafka,Output 为 Elasticsearch。
第三步:修改 logstash.conf 文件,如下所示:
input {
kafka {
codec => "json"
bootstrap_servers => "10.0.0.250:9093"
group_id => "logstash_group"
auto_offset_reset => "latest"
topics => ["test","logstash"]
}
}
output {
elasticsearch {
hosts => ["http://10.0.0.250:9200"]
index => "logstash-%{+YYYY.MM.dd}"
#user => "elastic"
#password => "changeme"
}
}
第四步:执行以下命令后台启动 Logstash:
nohup bin/logstash -f config/logstash.conf &
启动 Logstash 前,需要先启动 logstash.conf 文件中配置的 Kafka。
Kibana搭建
打开 Kibana下载页面,选择想要的 Kibana版本。本文选择的是 Kibana 8.6.2 版本。
第一步:解压 kibana-8.6.2-linux-x86_64.tar.gz
tar -zxvf kibana-8.6.2-linux-x86_64.tar.gz
第二步:修改 kibana.yml 文件,如下所示:
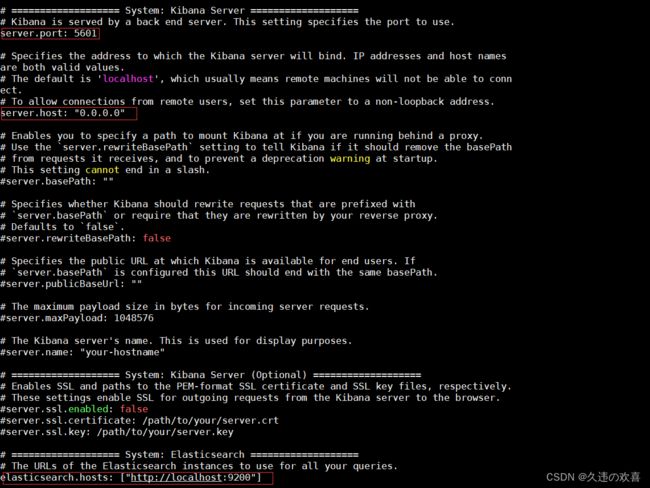
第三步:执行以下命令,后台启动 Kibana:
nohup bin/kibana &
第四步:浏览器访问 http://10.0.0.250:5601/,查看 Kibana 是否启动成功。

Kibana 界面与老版本的有所不同,点击上图中的 Dev Tools 可跳转到开发界面。