小白学Pytorch系列-- Torch API (5)
小白学Pytorch系列-- Torch API (5)
Math operations
Pointwise Ops
TORCH.ABS
计算输入中每个元素的绝对值。

>>> torch.abs(torch.tensor([-1, -2, 3]))
tensor([ 1, 2, 3])
TORCH.ABSOLUTE
torch.abs() 的别名
TORCH.ACOS
计算输入中每个元素的逆余弦。

a = torch.randn(4)
a
torch.acos(a)
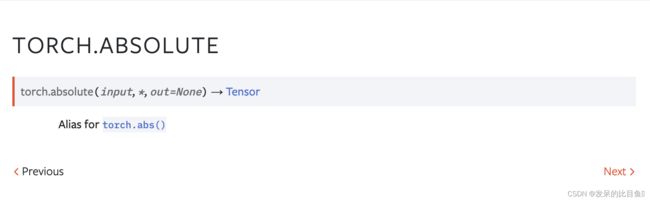
TORCH.ARCCOS
torch.acos()的别名。
TORCH.ACOSH
返回具有输入元素的反双曲余弦值的新张量。

TORCH.ARCCOSH
Torch.acosh() 的别名。

TORCH.ADD
将按 alpha 缩放的other添加到input。
![]](https://img-blog.csdnimg.cn/992cd8fd81ba4b209a07df9c0a3360a0.png)
>>> a = torch.randn(4)
>>> a
tensor([ 0.0202, 1.0985, 1.3506, -0.6056])
>>> torch.add(a, 20)
tensor([ 20.0202, 21.0985, 21.3506, 19.3944])
>>> b = torch.randn(4)
>>> b
tensor([-0.9732, -0.3497, 0.6245, 0.4022])
>>> c = torch.randn(4, 1)
>>> c
tensor([[ 0.3743],
[-1.7724],
[-0.5811],
[-0.8017]])
>>> torch.add(b, c, alpha=10)
tensor([[ 2.7695, 3.3930, 4.3672, 4.1450],
[-18.6971, -18.0736, -17.0994, -17.3216],
[ -6.7845, -6.1610, -5.1868, -5.4090],
[ -8.9902, -8.3667, -7.3925, -7.6147]])
TORCH.ADDCDIV
执行 tensor1 除以 tensor2 的逐元素除法,将结果乘以标量值并将其添加到input。

t = torch.randn(1, 3)
t1 = torch.randn(3, 1)
t2 = torch.randn(1, 3)
torch.addcdiv(t, t1, t2, value=0.1)
TORCH.ADDCMUL
执行 tensor1 与 tensor2 的逐元素乘法,将结果乘以标量值并将其添加到input。

t = torch.randn(1, 3)
t1 = torch.randn(3, 1)
t2 = torch.randn(1, 3)
torch.addcmul(t, t1, t2, value=0.1)
TORCH.ANGLE
计算给定输入张量的元素角度(以弧度为单位)。

torch.angle(torch.tensor([-1 + 1j, -2 + 2j, 3 - 3j]))*180/3.14159
TORCH.ASIN
返回一个新的张量与输入元素的反正弦值。

a = torch.randn(4)
a
torch.asin(a)
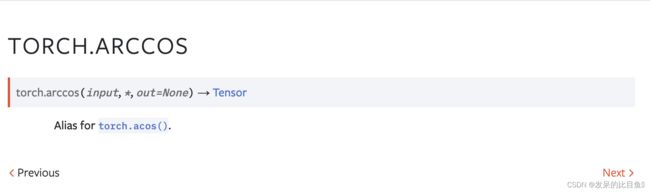
TORCH.ARCSIN
torch.asin() 的别名。

TORCH.ASINH
返回具有输入元素的反双曲正弦值的新张量。

a = torch.randn(4)
a
torch.asinh(a)
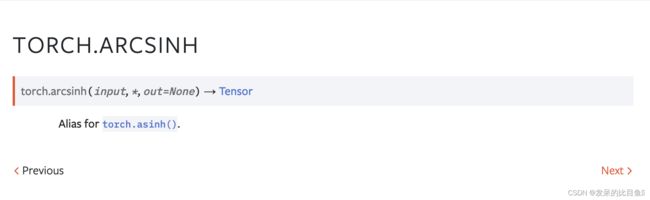
TORCH.ARCSINH
torch.asinh()的别名
TORCH.ATAN
返回一个新的张量与输入元素的反正切值。

a = torch.randn(4)
a
torch.atan(a)
TORCH.ARCTAN
torch.atan().别名

TORCH.ATANH
返回一个新的张量,该张量具有输入元素的反双曲正切。
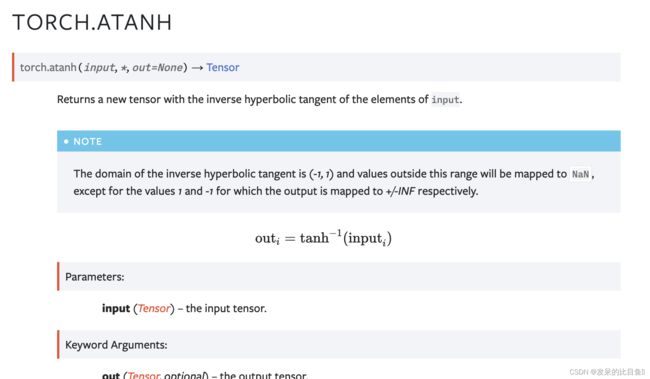
>>> a = torch.randn(4).uniform_(-1, 1)
>>> a
tensor([ -0.9385, 0.2968, -0.8591, -0.1871 ])
>>> torch.atanh(a)
tensor([ -1.7253, 0.3060, -1.2899, -0.1893 ])
TORCH.ARCTANH
torch.atanh().别名

TORCH.ATAN2
考虑象限的input/other元素的反正切。 返回一个新的张量,在向量(other,input)和向量(1,0)之间以弧度表示有符号的角度(注意第二个参数 other 是 x 坐标,而第一个参数 input 是 y-坐标。)
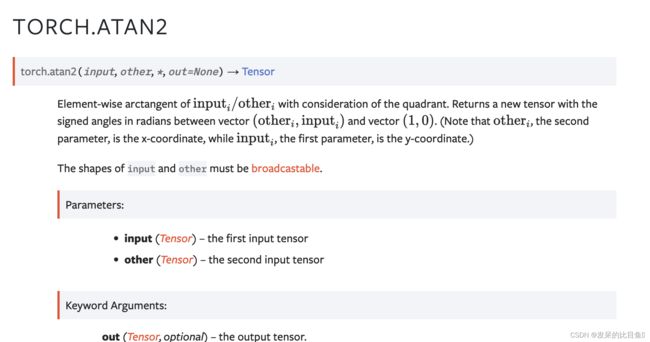
>>> a = torch.randn(4)
>>> a
tensor([ 0.9041, 0.0196, -0.3108, -2.4423])
>>> torch.atan2(a, torch.randn(4))
tensor([ 0.9833, 0.0811, -1.9743, -1.4151])
TORCH.ARCTAN2
torch.atan2() 别名。

TORCH.BITWISE_NOT
计算给定输入张量的按位非。 输入张量必须是整数或布尔类型。 对于 bool 张量,它计算逻辑 NOT。

>>> torch.bitwise_not(torch.tensor([-1, -2, 3], dtype=torch.int8))
tensor([ 0, 1, -4], dtype=torch.int8)
TORCH.BITWISE_AND
计算输入和其他的按位与。 输入张量必须是整数或布尔类型。 对于布尔张量,它计算逻辑与。

>>> torch.bitwise_and(torch.tensor([-1, -2, 3], dtype=torch.int8), torch.tensor([1, 0, 3], dtype=torch.int8))
tensor([1, 0, 3], dtype=torch.int8)
>>> torch.bitwise_and(torch.tensor([True, True, False]), torch.tensor([False, True, False]))
tensor([ False, True, False])
TORCH.BITWISE_OR
计算输入和其他的按位或。 输入张量必须是整数或布尔类型。 对于布尔张量,它计算逻辑或。

>>> torch.bitwise_or(torch.tensor([-1, -2, 3], dtype=torch.int8), torch.tensor([1, 0, 3], dtype=torch.int8))
tensor([-1, -2, 3], dtype=torch.int8)
>>> torch.bitwise_or(torch.tensor([True, True, False]), torch.tensor([False, True, False]))
tensor([ True, True, False])
TORCH.BITWISE_XOR
计算输入和其他的按位异或。 输入张量必须是整数或布尔类型。 对于 bool 张量,它计算逻辑 XOR。

>>> torch.bitwise_xor(torch.tensor([-1, -2, 3], dtype=torch.int8), torch.tensor([1, 0, 3], dtype=torch.int8))
tensor([-2, -2, 0], dtype=torch.int8)
>>> torch.bitwise_xor(torch.tensor([True, True, False]), torch.tensor([False, True, False]))
tensor([ True, False, False])
TORCH.BITWISE_LEFT_SHIFT
计算输入的其他位的左算术移位。 输入张量必须是整数类型。 此运营商支持广播到一个共同的形状和类型推广。

>>> torch.bitwise_left_shift(torch.tensor([-1, -2, 3], dtype=torch.int8), torch.tensor([1, 0, 3], dtype=torch.int8))
tensor([-2, -2, 24], dtype=torch.int8)
TORCH.BITWISE_RIGHT_SHIFT
计算其他位输入的算术右移。输入张量必须是积分类型。该运营商支持以普通形状和类型进行广播推广。

>>> torch.bitwise_right_shift(torch.tensor([-2, -7, 31], dtype=torch.int8), torch.tensor([1, 0, 3], dtype=torch.int8))
tensor([-1, -7, 3], dtype=torch.int8)
TORCH.CEIL
返回一个新的张量,其中包含输入元素的 ceil,即大于或等于每个元素的最小整数。
对于整数输入,遵循返回输入张量副本的 array-api 约定。

>>> a = torch.randn(4)
>>> a
tensor([-0.6341, -1.4208, -1.0900, 0.5826])
>>> torch.ceil(a)
tensor([-0., -1., -1., 1.])
TORCH.CLAMP
将 input 中的所有元素限制在 [ min, max ] 范围内。 令 min_value 和 max_value 分别为最小值和最大值,返回:
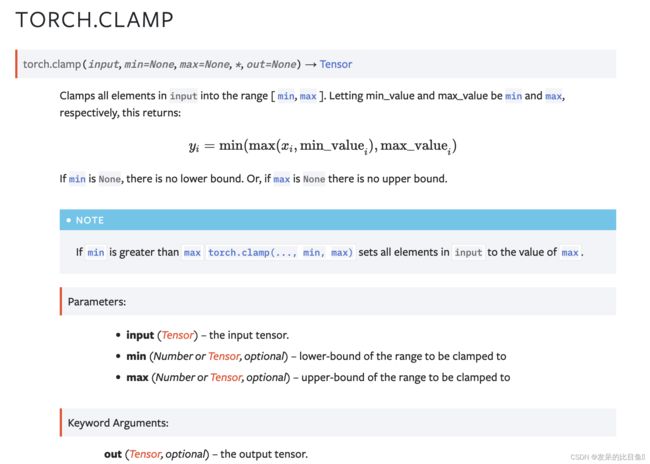
>>> a = torch.randn(4)
>>> a
tensor([-1.7120, 0.1734, -0.0478, -0.0922])
>>> torch.clamp(a, min=-0.5, max=0.5)
tensor([-0.5000, 0.1734, -0.0478, -0.0922])
>>> min = torch.linspace(-1, 1, steps=4)
>>> torch.clamp(a, min=min)
tensor([-1.0000, 0.1734, 0.3333, 1.0000])
TORCH.CLIP
torch.clamp() 的别名。

TORCH.CONJ_PHYSICAL
计算给定输入张量的逐元素共轭。 如果输入有一个非复杂数据类型,这个函数只返回输入。

>>> torch.conj_physical(torch.tensor([-1 + 1j, -2 + 2j, 3 - 3j]))
tensor([-1 - 1j, -2 - 2j, 3 + 3j])
TORCH.COPYSIGN
创建一个新的浮点张量,具有输入的大小和其他元素的符号。
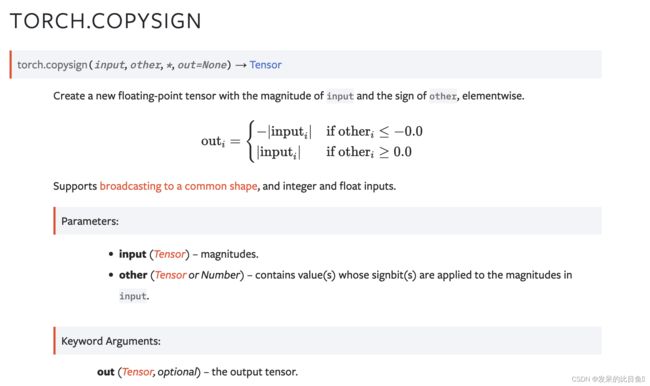
>>> a = torch.randn(5)
>>> a
tensor([-1.2557, -0.0026, -0.5387, 0.4740, -0.9244])
>>> torch.copysign(a, 1)
tensor([1.2557, 0.0026, 0.5387, 0.4740, 0.9244])
>>> a = torch.randn(4, 4)
>>> a
tensor([[ 0.7079, 0.2778, -1.0249, 0.5719],
[-0.0059, -0.2600, -0.4475, -1.3948],
[ 0.3667, -0.9567, -2.5757, -0.1751],
[ 0.2046, -0.0742, 0.2998, -0.1054]])
>>> b = torch.randn(4)
tensor([ 0.2373, 0.3120, 0.3190, -1.1128])
>>> torch.copysign(a, b)
tensor([[ 0.7079, 0.2778, 1.0249, -0.5719],
[ 0.0059, 0.2600, 0.4475, -1.3948],
[ 0.3667, 0.9567, 2.5757, -0.1751],
[ 0.2046, 0.0742, 0.2998, -0.1054]])
>>> a = torch.tensor([1.])
>>> b = torch.tensor([-0.])
>>> torch.copysign(a, b)
tensor([-1.])
TORCH.COS
返回一个新的张量与输入元素的余弦值。

>>> a = torch.randn(4)
>>> a
tensor([ 1.4309, 1.2706, -0.8562, 0.9796])
>>> torch.cos(a)
tensor([ 0.1395, 0.2957, 0.6553, 0.5574])
TORCH.COSH
返回具有输入元素的双曲余弦值的新张量。

>>> a = torch.randn(4)
>>> a
tensor([ 0.1632, 1.1835, -0.6979, -0.7325])
>>> torch.cosh(a)
tensor([ 1.0133, 1.7860, 1.2536, 1.2805])
TORCH.DEG2RAD
返回一个新的张量,其中输入的每个元素都从以度为单位的角度转换为弧度。
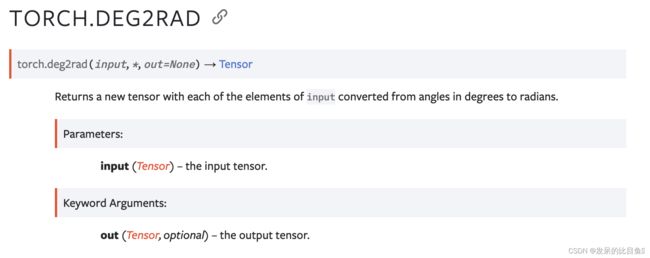
>>> a = torch.tensor([[180.0, -180.0], [360.0, -360.0], [90.0, -90.0]])
>>> torch.deg2rad(a)
tensor([[ 3.1416, -3.1416],
[ 6.2832, -6.2832],
[ 1.5708, -1.5708]])
TORCH.DIV
将输入 input 的每个元素除以 other 的对应元素。

>>> x = torch.tensor([ 0.3810, 1.2774, -0.2972, -0.3719, 0.4637])
>>> torch.div(x, 0.5)
tensor([ 0.7620, 2.5548, -0.5944, -0.7438, 0.9274])
>>> a = torch.tensor([[-0.3711, -1.9353, -0.4605, -0.2917],
... [ 0.1815, -1.0111, 0.9805, -1.5923],
... [ 0.1062, 1.4581, 0.7759, -1.2344],
... [-0.1830, -0.0313, 1.1908, -1.4757]])
>>> b = torch.tensor([ 0.8032, 0.2930, -0.8113, -0.2308])
>>> torch.div(a, b)
tensor([[-0.4620, -6.6051, 0.5676, 1.2639],
[ 0.2260, -3.4509, -1.2086, 6.8990],
[ 0.1322, 4.9764, -0.9564, 5.3484],
[-0.2278, -0.1068, -1.4678, 6.3938]])
>>> torch.div(a, b, rounding_mode='trunc')
tensor([[-0., -6., 0., 1.],
[ 0., -3., -1., 6.],
[ 0., 4., -0., 5.],
[-0., -0., -1., 6.]])
>>> torch.div(a, b, rounding_mode='floor')
tensor([[-1., -7., 0., 1.],
[ 0., -4., -2., 6.],
[ 0., 4., -1., 5.],
[-1., -1., -2., 6.]])
TORCH.DIVIDE
torch.div() 的别名

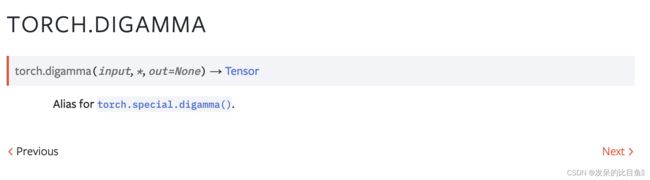
TORCH.DIGAMMA
Torch.special.digamma()的别名。
TORCH.ERF
torch.special.erf()的别名。

TORCH.ERFC
Torch.special.erfc() 的别名。

TORCH.ERFINV
torch.special.erfinv()的别名。

TORCH.EXP
返回一个新的张量,其中包含输入张量 input 的元素的指数。

>>> torch.exp(torch.tensor([0, math.log(2.)]))
tensor([ 1., 2.])
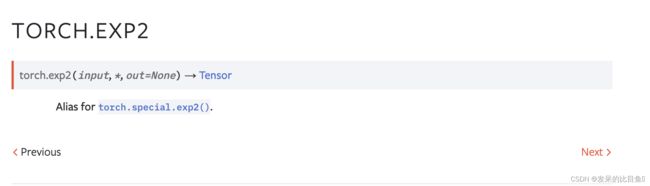
TORCH.EXP2
torch.special.exp2().别名
TORCH.EXPM1
torch.special.expm1().别名

>>> torch.special.expm1(torch.tensor([0, math.log(2.)]))
tensor([ 0., 1.])
TORCH.FAKE_QUANTIZE_PER_CHANNEL_AFFINE
返回一个新的张量,其中输入伪造中的数据在 axis 指定的通道中使用 scale、zero_point、quant_min 和 quant_max 按通道量化。

>>> x = torch.randn(2, 2, 2)
>>> x
tensor([[[-0.2525, -0.0466],
[ 0.3491, -0.2168]],
[[-0.5906, 1.6258],
[ 0.6444, -0.0542]]])
>>> scales = (torch.randn(2) + 1) * 0.05
>>> scales
tensor([0.0475, 0.0486])
>>> zero_points = torch.zeros(2).to(torch.int32)
>>> zero_points
tensor([0, 0])
>>> torch.fake_quantize_per_channel_affine(x, scales, zero_points, 1, 0, 255)
tensor([[[0.0000, 0.0000],
[0.3405, 0.0000]],
[[0.0000, 1.6134],
[0.6323, 0.0000]]])
TORCH.FAKE_QUANTIZE_PER_TENSOR_AFFINE
返回一个新的张量,其中使用 scale、zero_point、quant_min 和 quant_max 量化了输入伪造中的数据。

>>> x = torch.randn(4)
>>> x
tensor([ 0.0552, 0.9730, 0.3973, -1.0780])
>>> torch.fake_quantize_per_tensor_affine(x, 0.1, 0, 0, 255)
tensor([0.1000, 1.0000, 0.4000, 0.0000])
>>> torch.fake_quantize_per_tensor_affine(x, torch.tensor(0.1), torch.tensor(0), 0, 255)
tensor([0.6000, 0.4000, 0.0000, 0.0000])
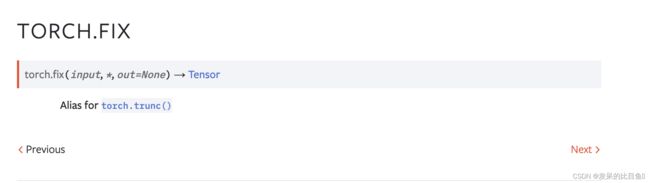
TORCH.FIX
返回一个新的张量,其中包含输入元素的截断整数值。
对于整数输入,遵循返回输入张量副本的 array-api 约定。
>>> a = torch.randn(4)
>>> a
tensor([ 3.4742, 0.5466, -0.8008, -0.9079])
>>> torch.trunc(a)
tensor([ 3., 0., -0., -0.])
TORCH.FLOAT_POWER
以双精度按元素将输入提高到指数的幂。 如果两个输入都不是复数,则返回 torch.float64 张量,如果一个或多个输入是复数,则返回 torch.complex128 张量。

>>> a = torch.randint(10, (4,))
>>> a
tensor([6, 4, 7, 1])
>>> torch.float_power(a, 2)
tensor([36., 16., 49., 1.], dtype=torch.float64)
>>> a = torch.arange(1, 5)
>>> a
tensor([ 1, 2, 3, 4])
>>> exp = torch.tensor([2, -3, 4, -5])
>>> exp
tensor([ 2, -3, 4, -5])
>>> torch.float_power(a, exp)
tensor([1.0000e+00, 1.2500e-01, 8.1000e+01, 9.7656e-04], dtype=torch.float64)
TORCH.FLOOR
返回一个新的张量,其中包含输入元素的底数,小于或等于每个元素的最大整数。
对于整数输入,遵循返回输入张量副本的 array-api 约定。

>>> a = torch.randn(4)
>>> a
tensor([-0.8166, 1.5308, -0.2530, -0.2091])
>>> torch.floor(a)
tensor([-1., 1., -1., -1.])
TORCH.FLOOR_DIVIDE
计算输入除以其他元素,然后计算结果。

>>> a = torch.tensor([4.0, 3.0])
>>> b = torch.tensor([2.0, 2.0])
>>> torch.floor_divide(a, b)
tensor([2.0, 1.0])
>>> torch.floor_divide(a, 1.4)
tensor([2.0, 2.0])
TORCH.FMOD
在入口处应用 C++ 的 std::fmod。 结果与被除数输入同号且绝对值小于other。

>>> torch.fmod(torch.tensor([-3., -2, -1, 1, 2, 3]), 2)
tensor([-1., -0., -1., 1., 0., 1.])
>>> torch.fmod(torch.tensor([1, 2, 3, 4, 5]), -1.5)
tensor([1.0000, 0.5000, 0.0000, 1.0000, 0.5000])
TORCH.FRAC
计算输入中每个元素的小数部分。

>>> torch.frac(torch.tensor([1, 2.5, -3.2]))
tensor([ 0.0000, 0.5000, -0.2000])
TORCH.FREXP
将输入分解为尾数和指数张量,使得 输入 = 尾数 × 2 指数 输入=尾数×2^{指数} 输入=尾数×2指数

>>> x = torch.arange(9.)
>>> mantissa, exponent = torch.frexp(x)
>>> mantissa
tensor([0.0000, 0.5000, 0.5000, 0.7500, 0.5000, 0.6250, 0.7500, 0.8750, 0.5000])
>>> exponent
tensor([0, 1, 2, 2, 3, 3, 3, 3, 4], dtype=torch.int32)
>>> torch.ldexp(mantissa, exponent)
tensor([0., 1., 2., 3., 4., 5., 6., 7., 8.])
TORCH.GRADIENT

>>> # Estimates the gradient of f(x)=x^2 at points [-2, -1, 2, 4]
>>> coordinates = (torch.tensor([-2., -1., 1., 4.]),)
>>> values = torch.tensor([4., 1., 1., 16.], )
>>> torch.gradient(values, spacing = coordinates)
(tensor([-3., -2., 2., 5.]),)
>>> # Estimates the gradient of the R^2 -> R function whose samples are
>>> # described by the tensor t. Implicit coordinates are [0, 1] for the outermost
>>> # dimension and [0, 1, 2, 3] for the innermost dimension, and function estimates
>>> # partial derivative for both dimensions.
>>> t = torch.tensor([[1, 2, 4, 8], [10, 20, 40, 80]])
>>> torch.gradient(t)
(tensor([[ 9., 18., 36., 72.],
[ 9., 18., 36., 72.]]),
tensor([[ 1.0000, 1.5000, 3.0000, 4.0000],
[10.0000, 15.0000, 30.0000, 40.0000]]))
>>> # A scalar value for spacing modifies the relationship between tensor indices
>>> # and input coordinates by multiplying the indices to find the
>>> # coordinates. For example, below the indices of the innermost
>>> # 0, 1, 2, 3 translate to coordinates of [0, 2, 4, 6], and the indices of
>>> # the outermost dimension 0, 1 translate to coordinates of [0, 2].
>>> torch.gradient(t, spacing = 2.0) # dim = None (implicitly [0, 1])
(tensor([[ 4.5000, 9.0000, 18.0000, 36.0000],
[ 4.5000, 9.0000, 18.0000, 36.0000]]),
tensor([[ 0.5000, 0.7500, 1.5000, 2.0000],
[ 5.0000, 7.5000, 15.0000, 20.0000]]))
>>> # doubling the spacing between samples halves the estimated partial gradients.
>>>
>>> # Estimates only the partial derivative for dimension 1
>>> torch.gradient(t, dim = 1) # spacing = None (implicitly 1.)
(tensor([[ 1.0000, 1.5000, 3.0000, 4.0000],
[10.0000, 15.0000, 30.0000, 40.0000]]),)
>>> # When spacing is a list of scalars, the relationship between the tensor
>>> # indices and input coordinates changes based on dimension.
>>> # For example, below, the indices of the innermost dimension 0, 1, 2, 3 translate
>>> # to coordinates of [0, 3, 6, 9], and the indices of the outermost dimension
>>> # 0, 1 translate to coordinates of [0, 2].
>>> torch.gradient(t, spacing = [3., 2.])
(tensor([[ 4.5000, 9.0000, 18.0000, 36.0000],
[ 4.5000, 9.0000, 18.0000, 36.0000]]),
tensor([[ 0.3333, 0.5000, 1.0000, 1.3333],
[ 3.3333, 5.0000, 10.0000, 13.3333]]))
>>> # The following example is a replication of the previous one with explicit
>>> # coordinates.
>>> coords = (torch.tensor([0, 2]), torch.tensor([0, 3, 6, 9]))
>>> torch.gradient(t, spacing = coords)
(tensor([[ 4.5000, 9.0000, 18.0000, 36.0000],
[ 4.5000, 9.0000, 18.0000, 36.0000]]),
tensor([[ 0.3333, 0.5000, 1.0000, 1.3333],
[ 3.3333, 5.0000, 10.0000, 13.3333]]))
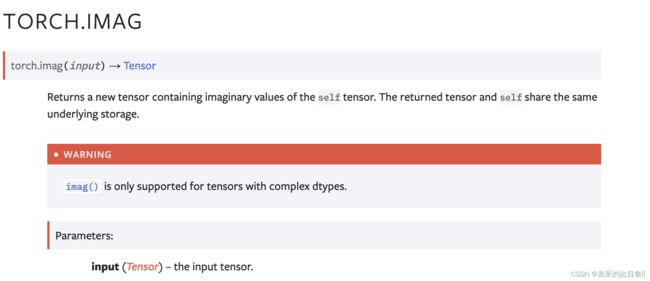
TORCH.IMAG
返回一个包含自张量的虚数值的新张量。 返回的张量和 self 共享相同的底层存储。
>>> x=torch.randn(4, dtype=torch.cfloat)
>>> x
tensor([(0.3100+0.3553j), (-0.5445-0.7896j), (-1.6492-0.0633j), (-0.0638-0.8119j)])
>>> x.imag
tensor([ 0.3553, -0.7896, -0.0633, -0.8119])
TORCH.LDEXP
将输入乘以 2 ** other。
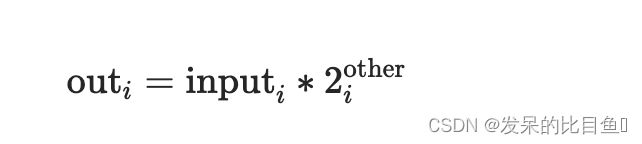
通常,此函数用于通过将输入中的尾数与从其他中的指数创建的两个整数幂相乘来构造浮点数。

>>> torch.ldexp(torch.tensor([1.]), torch.tensor([1]))
tensor([2.])
>>> torch.ldexp(torch.tensor([1.0]), torch.tensor([1, 2, 3, 4]))
tensor([ 2., 4., 8., 16.])
TORCH.LERP
两个张量的线性插值是否开始(由输入给出)并基于标量或张量权重结束并返回结果张量。

>>> start = torch.arange(1., 5.)
>>> end = torch.empty(4).fill_(10)
>>> start
tensor([ 1., 2., 3., 4.])
>>> end
tensor([ 10., 10., 10., 10.])
>>> torch.lerp(start, end, 0.5)
tensor([ 5.5000, 6.0000, 6.5000, 7.0000])
>>> torch.lerp(start, end, torch.full_like(start, 0.5))
tensor([ 5.5000, 6.0000, 6.5000, 7.0000])
TORCH.LGAMMA
计算输入的 gamma 函数的绝对值的自然对数。
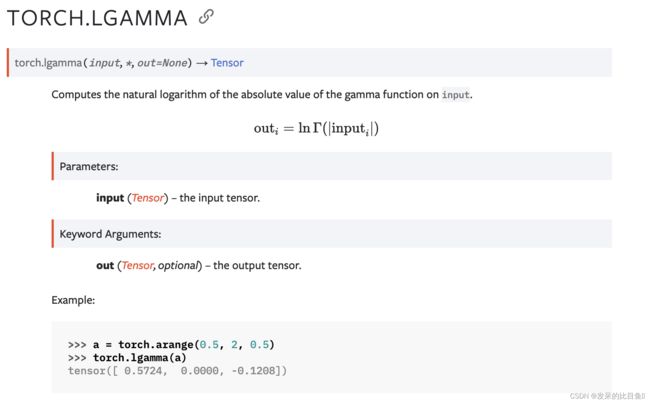
>>> a = torch.arange(0.5, 2, 0.5)
>>> torch.lgamma(a)
tensor([ 0.5724, 0.0000, -0.1208])
TORCH.LOG
返回具有输入元素自然对数的新张量。

>>> a = torch.rand(5) * 5
>>> a
tensor([4.7767, 4.3234, 1.2156, 0.2411, 4.5739])
>>> torch.log(a)
tensor([ 1.5637, 1.4640, 0.1952, -1.4226, 1.5204])
TORCH.LOG1P
返回具有 (1 + input) 自然对数的新张量。
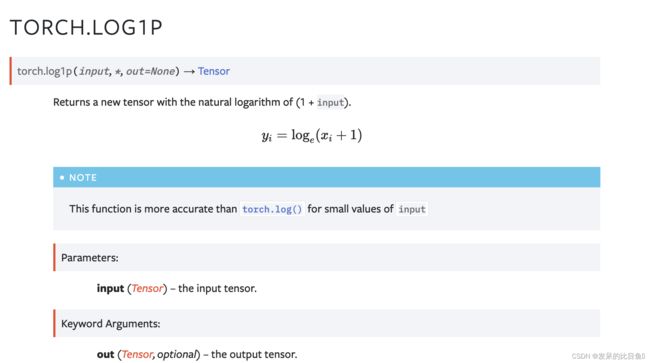
>>> a = torch.randn(5)
>>> a
tensor([-1.0090, -0.9923, 1.0249, -0.5372, 0.2492])
>>> torch.log1p(a)
tensor([ nan, -4.8653, 0.7055, -0.7705, 0.2225])
TORCH.LOG2
返回一个新的张量,其对数为输入元素的底 2。

>>> a = torch.rand(5)
>>> a
tensor([ 0.8419, 0.8003, 0.9971, 0.5287, 0.0490])
>>> torch.log2(a)
tensor([-0.2483, -0.3213, -0.0042, -0.9196, -4.3504])
TORCH.LOGADDEXP
输入的指数总和的对数。
计算逐点对数 ( e x + e y ) (e^x +e^y) (ex+ey)。 此函数在统计中很有用,其中计算的事件概率可能小到超出正常浮点数的范围。 在这种情况下,存储计算概率的对数。 此函数允许添加以这种方式存储的概率。
此操作应与 torch.logsumexp() 消除歧义,后者对单个张量执行缩减。

>>> torch.logaddexp(torch.tensor([-1.0]), torch.tensor([-1.0, -2, -3]))
tensor([-0.3069, -0.6867, -0.8731])
>>> torch.logaddexp(torch.tensor([-100.0, -200, -300]), torch.tensor([-1.0, -2, -3]))
tensor([-1., -2., -3.])
>>> torch.logaddexp(torch.tensor([1.0, 2000, 30000]), torch.tensor([-1.0, -2, -3]))
tensor([1.1269e+00, 2.0000e+03, 3.0000e+04])
TORCH.LOGADDEXP2
以 2 为基数的输入的指数总和的对数。
计算逐点 l o g 2 ( 2 x + 2 y ) log2 (2^x+2^y) log2(2x+2y)。 有关详细信息,请参阅 torch.logaddexp()。

TORCH.LOGICAL_AND
计算给定输入张量的逐元素逻辑与。 零被视为假,非零被视为真。
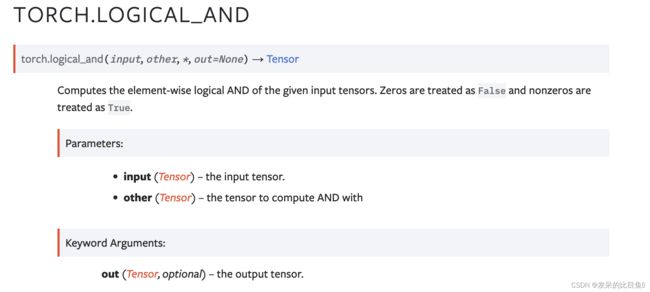
>>> torch.logical_and(torch.tensor([True, False, True]), torch.tensor([True, False, False]))
tensor([ True, False, False])
>>> a = torch.tensor([0, 1, 10, 0], dtype=torch.int8)
>>> b = torch.tensor([4, 0, 1, 0], dtype=torch.int8)
>>> torch.logical_and(a, b)
tensor([False, False, True, False])
>>> torch.logical_and(a.double(), b.double())
tensor([False, False, True, False])
>>> torch.logical_and(a.double(), b)
tensor([False, False, True, False])
>>> torch.logical_and(a, b, out=torch.empty(4, dtype=torch.bool))
tensor([False, False, True, False])
TORCH.LOGICAL_NOT
计算给定输入张量的逐元素逻辑非。 如果未指定,输出张量将具有 bool dtype。 如果输入张量不是 bool 张量,则将零视为 False,将非零视为 True。

>>> torch.logical_not(torch.tensor([True, False]))
tensor([False, True])
>>> torch.logical_not(torch.tensor([0, 1, -10], dtype=torch.int8))
tensor([ True, False, False])
>>> torch.logical_not(torch.tensor([0., 1.5, -10.], dtype=torch.double))
tensor([ True, False, False])
>>> torch.logical_not(torch.tensor([0., 1., -10.], dtype=torch.double), out=torch.empty(3, dtype=torch.int16))
tensor([1, 0, 0], dtype=torch.int16)
TORCH.LOGICAL_OR
计算给定输入张量的逐元素逻辑或。 零被视为假,非零被视为真。
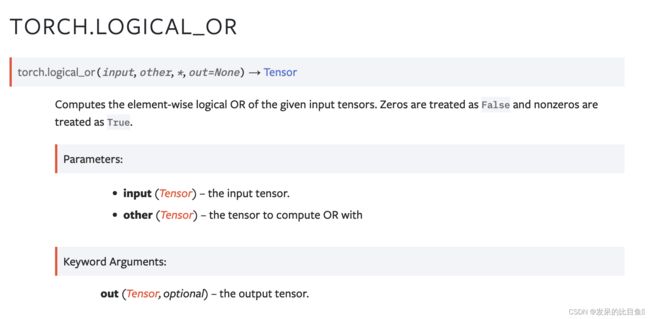
>>> torch.logical_or(torch.tensor([True, False, True]), torch.tensor([True, False, False]))
tensor([ True, False, True])
>>> a = torch.tensor([0, 1, 10, 0], dtype=torch.int8)
>>> b = torch.tensor([4, 0, 1, 0], dtype=torch.int8)
>>> torch.logical_or(a, b)
tensor([ True, True, True, False])
>>> torch.logical_or(a.double(), b.double())
tensor([ True, True, True, False])
>>> torch.logical_or(a.double(), b)
tensor([ True, True, True, False])
>>> torch.logical_or(a, b, out=torch.empty(4, dtype=torch.bool))
tensor([ True, True, True, False])
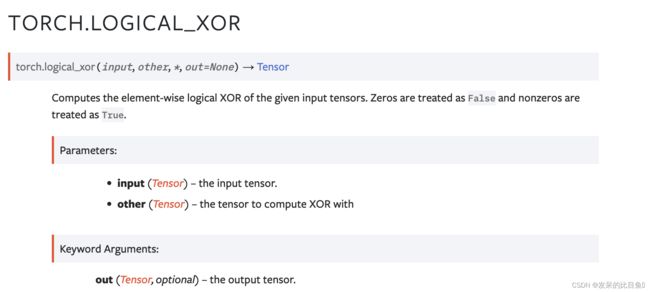
TORCH.LOGICAL_XOR
计算给定输入张量的逐元素逻辑异或。 零被视为假,非零被视为真。
>>> torch.logical_xor(torch.tensor([True, False, True]), torch.tensor([True, False, False]))
tensor([False, False, True])
>>> a = torch.tensor([0, 1, 10, 0], dtype=torch.int8)
>>> b = torch.tensor([4, 0, 1, 0], dtype=torch.int8)
>>> torch.logical_xor(a, b)
tensor([ True, True, False, False])
>>> torch.logical_xor(a.double(), b.double())
tensor([ True, True, False, False])
>>> torch.logical_xor(a.double(), b)
tensor([ True, True, False, False])
>>> torch.logical_xor(a, b, out=torch.empty(4, dtype=torch.bool))
tensor([ True, True, False, False])
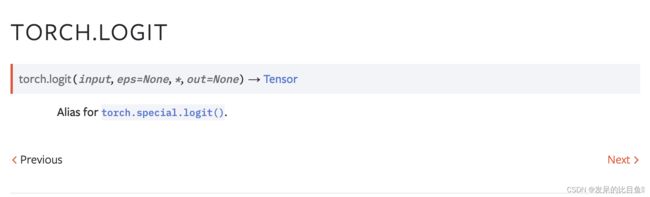
TORCH.LOGIT

>>> a = torch.rand(5)
>>> a
tensor([0.2796, 0.9331, 0.6486, 0.1523, 0.6516])
>>> torch.special.logit(a, eps=1e-6)
tensor([-0.9466, 2.6352, 0.6131, -1.7169, 0.6261])
TORCH.HYPOT
给定一个直角三角形的边,返回它的斜边。

>>> a = torch.hypot(torch.tensor([4.0]), torch.tensor([3.0, 4.0, 5.0]))
tensor([5.0000, 5.6569, 6.4031])
TORCH.I0
torch.special.i0().别名

>>> torch.i0(torch.arange(5, dtype=torch.float32))
tensor([ 1.0000, 1.2661, 2.2796, 4.8808, 11.3019])
TORCH.IGAMMA
torch.special.gammainc().别名

>>> a1 = torch.tensor([4.0])
>>> a2 = torch.tensor([3.0, 4.0, 5.0])
>>> a = torch.special.gammaincc(a1, a2)
tensor([0.3528, 0.5665, 0.7350])
tensor([0.3528, 0.5665, 0.7350])
>>> b = torch.special.gammainc(a1, a2) + torch.special.gammaincc(a1, a2)
tensor([1., 1., 1.])
TORCH.IGAMMAC
torch.special.gammaincc().别名

>>> a1 = torch.tensor([4.0])
>>> a2 = torch.tensor([3.0, 4.0, 5.0])
>>> a = torch.special.gammaincc(a1, a2)
tensor([0.6472, 0.4335, 0.2650])
>>> b = torch.special.gammainc(a1, a2) + torch.special.gammaincc(a1, a2)
tensor([1., 1., 1.])
TORCH.MUL

>>> a = torch.randn(3)
>>> a
tensor([ 0.2015, -0.4255, 2.6087])
>>> torch.mul(a, 100)
tensor([ 20.1494, -42.5491, 260.8663])
>>> b = torch.randn(4, 1)
>>> b
tensor([[ 1.1207],
[-0.3137],
[ 0.0700],
[ 0.8378]])
>>> c = torch.randn(1, 4)
>>> c
tensor([[ 0.5146, 0.1216, -0.5244, 2.2382]])
>>> torch.mul(b, c)
tensor([[ 0.5767, 0.1363, -0.5877, 2.5083],
[-0.1614, -0.0382, 0.1645, -0.7021],
[ 0.0360, 0.0085, -0.0367, 0.1567],
[ 0.4312, 0.1019, -0.4394, 1.8753]])
TORCH.MULTIPLY
torch.mul().别名

TORCH.MVLGAMMA
torch.special.multigammaln()别名

TORCH.NAN_TO_NUM
分别用 nan、posinf 和 neginf 指定的值替换输入中的 NaN、正无穷大和负无穷大值。 默认情况下,NaN 替换为零,正无穷大替换为输入数据类型可表示的最大有限值,负无穷大替换为输入数据类型可表示的最小有限值。

>>> x = torch.tensor([float('nan'), float('inf'), -float('inf'), 3.14])
>>> torch.nan_to_num(x)
tensor([ 0.0000e+00, 3.4028e+38, -3.4028e+38, 3.1400e+00])
>>> torch.nan_to_num(x, nan=2.0)
tensor([ 2.0000e+00, 3.4028e+38, -3.4028e+38, 3.1400e+00])
>>> torch.nan_to_num(x, nan=2.0, posinf=1.0)
tensor([ 2.0000e+00, 1.0000e+00, -3.4028e+38, 3.1400e+00])
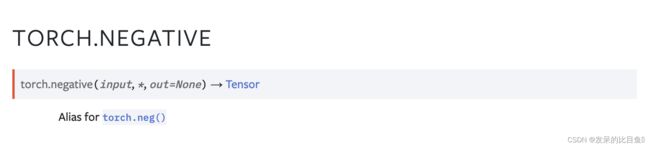
TORCH.NEG
返回具有输入元素负值的新张量。

>>> a = torch.randn(5)
>>> a
tensor([ 0.0090, -0.2262, -0.0682, -0.2866, 0.3940])
>>> torch.neg(a)
tensor([-0.0090, 0.2262, 0.0682, 0.2866, -0.3940])
TORCH.NEGATIVE
torch.neg()别名
TORCH.NEXTAFTER
在向其他元素输入后返回下一个浮点值。
input 和 other 的形状必须是可广播的。

>>> eps = torch.finfo(torch.float32).eps
>>> torch.nextafter(torch.tensor([1.0, 2.0]), torch.tensor([2.0, 1.0])) == torch.tensor([eps + 1, 2 - eps])
tensor([True, True])
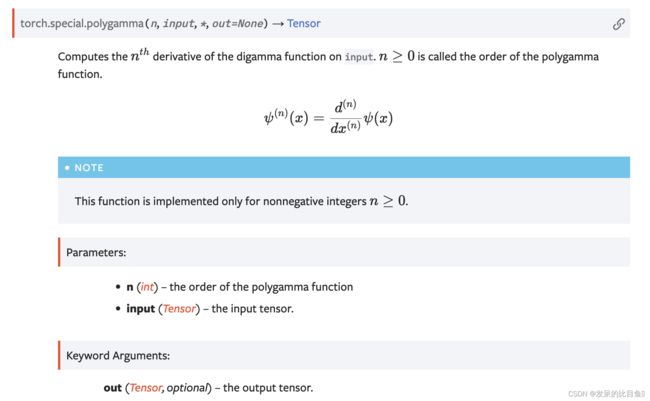
TORCH.POLYGAMMA
计算输入的 digamma 函数的 th 导数。n≥0称为多伽马函数的阶数。
>>> a = torch.tensor([1, 0.5])
>>> torch.special.polygamma(1, a)
tensor([1.64493, 4.9348])
>>> torch.special.polygamma(2, a)
tensor([ -2.4041, -16.8288])
>>> torch.special.polygamma(3, a)
tensor([ 6.4939, 97.4091])
>>> torch.special.polygamma(4, a)
tensor([ -24.8863, -771.4742])
TORCH.POSITIVE
返回输入。 如果输入是 bool 张量,则抛出运行时错误。

>>> t = torch.randn(5)
>>> t
tensor([ 0.0090, -0.2262, -0.0682, -0.2866, 0.3940])
>>> torch.positive(t)
tensor([ 0.0090, -0.2262, -0.0682, -0.2866, 0.3940])
TORCH.POW
取输入中每个元素的幂和指数,并返回张量和结果。
指数可以是单个浮点数或具有与输入相同数量的元素的张量。

>>> a = torch.randn(4)
>>> a
tensor([ 0.4331, 1.2475, 0.6834, -0.2791])
>>> torch.pow(a, 2)
tensor([ 0.1875, 1.5561, 0.4670, 0.0779])
>>> exp = torch.arange(1., 5.)
>>> a = torch.arange(1., 5.)
>>> a
tensor([ 1., 2., 3., 4.])
>>> exp
tensor([ 1., 2., 3., 4.])
>>> torch.pow(a, exp)
tensor([ 1., 4., 27., 256.])

>>> exp = torch.arange(1., 5.)
>>> base = 2
>>> torch.pow(base, exp)
tensor([ 2., 4., 8., 16.])
TORCH.QUANTIZED_BATCH_NORM
对 4D (NCHW) 量化张量应用批量归一化。
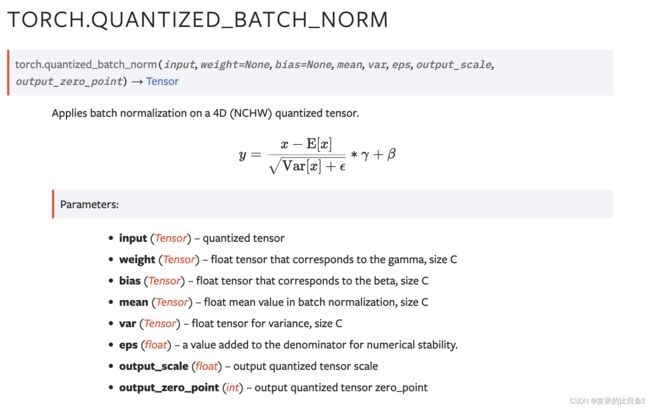
>>> qx = torch.quantize_per_tensor(torch.rand(2, 2, 2, 2), 1.5, 3, torch.quint8)
>>> torch.quantized_batch_norm(qx, torch.ones(2), torch.zeros(2), torch.rand(2), torch.rand(2), 0.00001, 0.2, 2)
tensor([[[[-0.2000, -0.2000],
[ 1.6000, -0.2000]],
[[-0.4000, -0.4000],
[-0.4000, 0.6000]]],
[[[-0.2000, -0.2000],
[-0.2000, -0.2000]],
[[ 0.6000, -0.4000],
[ 0.6000, -0.4000]]]], size=(2, 2, 2, 2), dtype=torch.quint8,
quantization_scheme=torch.per_tensor_affine, scale=0.2, zero_point=2)
TORCH.QUANTIZED_MAX_POOL1D
在由多个输入平面组成的输入量化张量上应用一维最大池化。
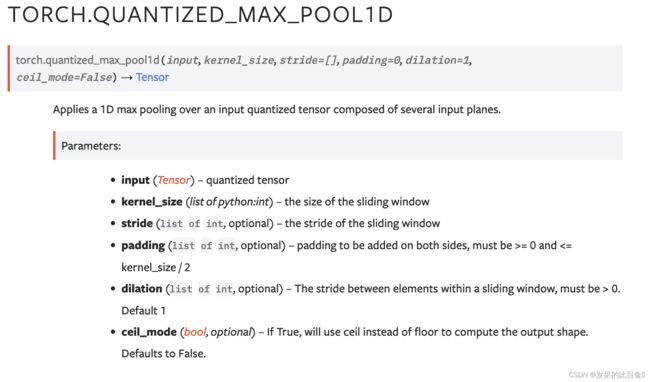
>>> qx = torch.quantize_per_tensor(torch.rand(2, 2), 1.5, 3, torch.quint8)
>>> torch.quantized_max_pool1d(qx, [2])
tensor([[0.0000],
[1.5000]], size=(2, 1), dtype=torch.quint8,
quantization_scheme=torch.per_tensor_affine, scale=1.5, zero_point=3)
TORCH.QUANTIZED_MAX_POOL2D
在由多个输入平面组成的输入量化张量上应用 2D 最大池化。
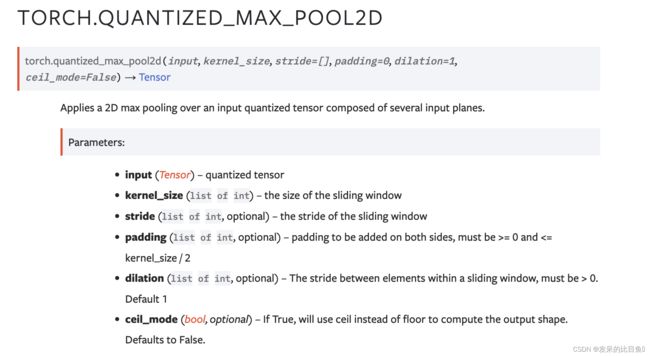
>>> qx = torch.quantize_per_tensor(torch.rand(2, 2, 2, 2), 1.5, 3, torch.quint8)
>>> torch.quantized_max_pool2d(qx, [2,2])
tensor([[[[1.5000]],
[[1.5000]]],
[[[0.0000]],
[[0.0000]]]], size=(2, 2, 1, 1), dtype=torch.quint8,
quantization_scheme=torch.per_tensor_affine, scale=1.5, zero_point=3)
TORCH.RAD2DEG
返回一个新的张量,其中输入的每个元素都从以弧度为单位的角度转换为度数。
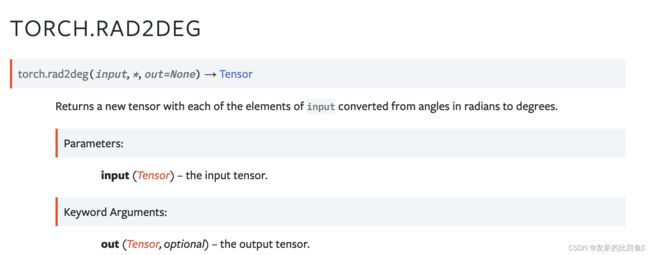
>>> a = torch.tensor([[3.142, -3.142], [6.283, -6.283], [1.570, -1.570]])
>>> torch.rad2deg(a)
tensor([[ 180.0233, -180.0233],
[ 359.9894, -359.9894],
[ 89.9544, -89.9544]])
TORCH.REAL
返回一个包含自张量实数值的新张量。 返回的张量和 self 共享相同的底层存储。

>>> x=torch.randn(4, dtype=torch.cfloat)
>>> x
tensor([(0.3100+0.3553j), (-0.5445-0.7896j), (-1.6492-0.0633j), (-0.0638-0.8119j)])
>>> x.real
tensor([ 0.3100, -0.5445, -1.6492, -0.0638])
TORCH.RECIPROCAL
返回一个新的张量与输入元素的倒数

>>> a = torch.randn(4)
>>> a
tensor([-0.4595, -2.1219, -1.4314, 0.7298])
>>> torch.reciprocal(a)
tensor([-2.1763, -0.4713, -0.6986, 1.3702])
TORCH.REMAINDER
结果与除数other同号且绝对值小于other。

>>> torch.remainder(torch.tensor([-3., -2, -1, 1, 2, 3]), 2)
tensor([ 1., 0., 1., 1., 0., 1.])
>>> torch.remainder(torch.tensor([1, 2, 3, 4, 5]), -1.5)
tensor([ -0.5000, -1.0000, 0.0000, -0.5000, -1.0000 ])
TORCH.ROUND
将输入的元素四舍五入为最接近的整数。
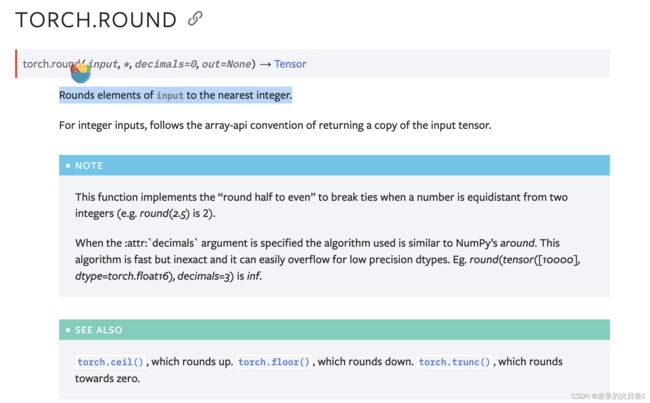

>>> torch.round(torch.tensor((4.7, -2.3, 9.1, -7.7)))
tensor([ 5., -2., 9., -8.])
>>> # Values equidistant from two integers are rounded towards the
>>> # the nearest even value (zero is treated as even)
>>> torch.round(torch.tensor([-0.5, 0.5, 1.5, 2.5]))
tensor([-0., 0., 2., 2.])
>>> # A positive decimals argument rounds to the to that decimal place
>>> torch.round(torch.tensor([0.1234567]), decimals=3)
tensor([0.1230])
>>> # A negative decimals argument rounds to the left of the decimal
>>> torch.round(torch.tensor([1200.1234567]), decimals=-3)
tensor([1000.])
TORCH.RSQRT
返回一个新的张量,它是输入的每个元素的平方根的倒数。

>>> a = torch.randn(4)
>>> a
tensor([-0.0370, 0.2970, 1.5420, -0.9105])
>>> torch.rsqrt(a)
tensor([ nan, 1.8351, 0.8053, nan])
TORCH.SIGMOID
torch.special.expit().别名

>>> t = torch.randn(4)
>>> t
tensor([ 0.9213, 1.0887, -0.8858, -1.7683])
>>> torch.special.expit(t)
tensor([ 0.7153, 0.7481, 0.2920, 0.1458])
TORCH.SIGN
返回一个带有输入元素符号的新张量。

>>> a = torch.tensor([0.7, -1.2, 0., 2.3])
>>> a
tensor([ 0.7000, -1.2000, 0.0000, 2.3000])
>>> torch.sign(a)
tensor([ 1., -1., 0., 1.])
TORCH.SGN
此函数是 torch.sign() 对复杂张量的扩展。 它计算一个新的张量,其元素与输入的对应元素具有相同的角度,对于复数张量,绝对值(即幅度)为 1,对于非复数张量,它等效于 torch.sign()。
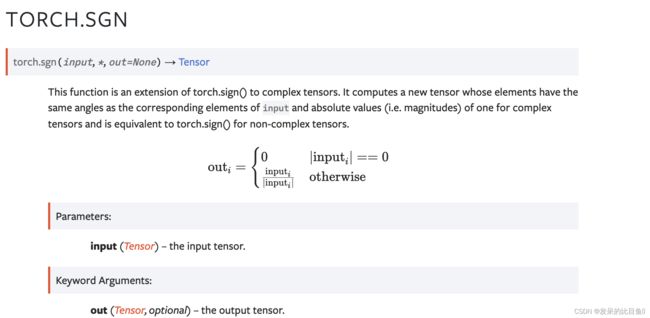
>>> t = torch.tensor([3+4j, 7-24j, 0, 1+2j])
>>> t.sgn()
tensor([0.6000+0.8000j, 0.2800-0.9600j, 0.0000+0.0000j, 0.4472+0.8944j])
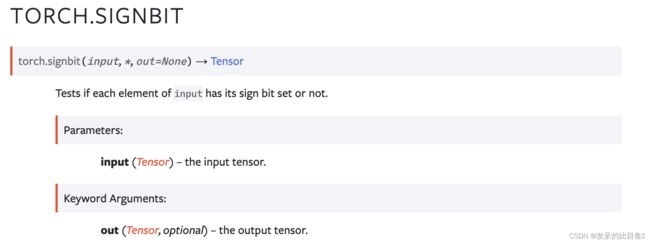
TORCH.SIGNBIT
测试输入的每个元素是否设置了符号位。
>>> a = torch.tensor([0.7, -1.2, 0., 2.3])
>>> torch.signbit(a)
tensor([ False, True, False, False])
>>> a = torch.tensor([-0.0, 0.0])
>>> torch.signbit(a)
tensor([ True, False])
TORCH.SIN

>>> a = torch.randn(4)
>>> a
tensor([-0.5461, 0.1347, -2.7266, -0.2746])
>>> torch.sin(a)
tensor([-0.5194, 0.1343, -0.4032, -0.2711])
TORCH.SINC
torch.special.sinc().别名

>>> t = torch.randn(4)
>>> t
tensor([ 0.2252, -0.2948, 1.0267, -1.1566])
>>> torch.special.sinc(t)
tensor([ 0.9186, 0.8631, -0.0259, -0.1300])
TORCH.SINH

>>> a = torch.randn(4)
>>> a
tensor([ 0.5380, -0.8632, -0.1265, 0.9399])
>>> torch.sinh(a)
tensor([ 0.5644, -0.9744, -0.1268, 1.0845])
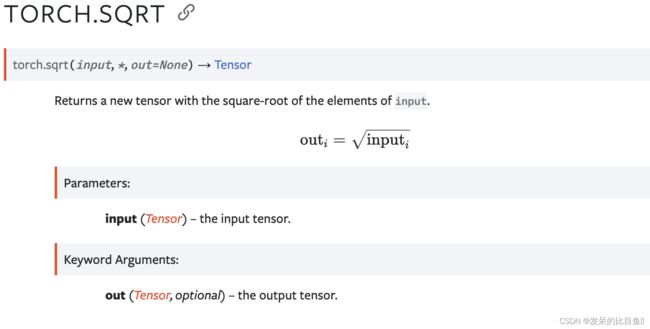
TORCH.SQRT
>>> a = torch.randn(4)
>>> a
tensor([-2.0755, 1.0226, 0.0831, 0.4806])
>>> torch.sqrt(a)
tensor([ nan, 1.0112, 0.2883, 0.6933])
TORCH.SQUARE
返回一个新的张量,其中包含输入元素的平方。

>>> a = torch.randn(4)
>>> a
tensor([-2.0755, 1.0226, 0.0831, 0.4806])
>>> torch.square(a)
tensor([ 4.3077, 1.0457, 0.0069, 0.2310])
TORCH.SUB

>>> a = torch.tensor((1, 2))
>>> b = torch.tensor((0, 1))
>>> torch.sub(a, b, alpha=2)
tensor([1, 0])
TORCH.SUBTRACT

TORCH.TAN

>>> a = torch.randn(4)
>>> a
tensor([-1.2027, -1.7687, 0.4412, -1.3856])
>>> torch.tan(a)
tensor([-2.5930, 4.9859, 0.4722, -5.3366])
TORCH.TANH

>>> a = torch.randn(4)
>>> a
tensor([ 0.8986, -0.7279, 1.1745, 0.2611])
>>> torch.tanh(a)
tensor([ 0.7156, -0.6218, 0.8257, 0.2553])
TORCH.TRUE_DIVIDE
torch.div()关于 rounding_mode=None的别名

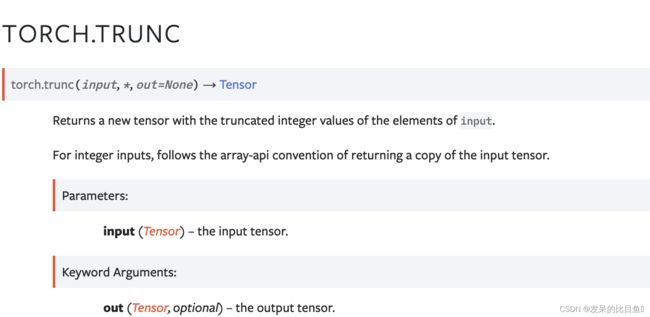
TORCH.TRUNC
返回一个新的张量,其中包含输入元素的截断整数值。
对于整数输入,遵循返回输入张量副本的 array-api 约定。
>>> a = torch.randn(4)
>>> a
tensor([ 3.4742, 0.5466, -0.8008, -0.9079])
>>> torch.trunc(a)
tensor([ 3., 0., -0., -0.])
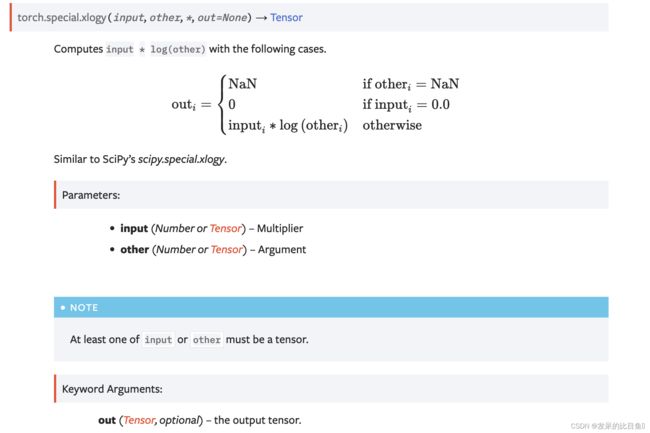
TORCH.XLOGY
torch.special.xlogy(). 别名
>>> x = torch.zeros(5,)
>>> y = torch.tensor([-1, 0, 1, float('inf'), float('nan')])
>>> torch.special.xlogy(x, y)
tensor([0., 0., 0., 0., nan])
>>> x = torch.tensor([1, 2, 3])
>>> y = torch.tensor([3, 2, 1])
>>> torch.special.xlogy(x, y)
tensor([1.0986, 1.3863, 0.0000])
>>> torch.special.xlogy(x, 4)
tensor([1.3863, 2.7726, 4.1589])
>>> torch.special.xlogy(2, y)
tensor([2.1972, 1.3863, 0.0000])