了解大数据技术原理与应用(复习知识点)
目录
①大数据(Big Data)与云计算、物联网的相互关系
②介绍Hadoop、MapReduce、HDFS和HBase以及其他功能组 件,复习重点以及其他可用点!
一 大数据介绍
1信息科技为大数据时代提供技术支撑
2数据产生方式的变革促成大数据时代的来临
3大数据特点
4大数据影响
5大数据关键技术
6 大数据产业
7大数据与云计算、物联网的关系
二 Hadoop
1.Hadoop基础了解与使用
2.hdfs相关命令
3.分布式文件系统HDFS
①大数据(Big Data)与云计算、物联网的相互关系
②介绍Hadoop、MapReduce、HDFS和HBase以及其他功能组 件,复习重点以及其他可用点!
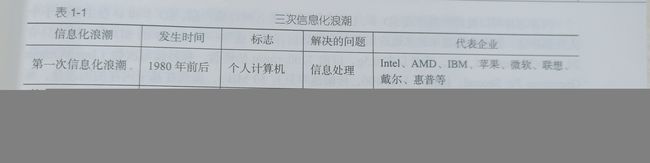
三次信息化浪潮
一 大数据介绍
1信息科技为大数据时代提供技术支撑
☺存储设备容量不断增加
☺CPU处理能力大幅提升
☺网络带宽不断增加
2数据产生方式的变革促成大数据时代的来临
·运营式系统阶段
·拥护原创内容阶段
·感知式系统阶段
3大数据特点
①数据量大
②数据类型繁多
③处理速度快
④价值密度低
4大数据影响
四种范式:
实验科学 理论科学 计算科学 数据密集型科学
5大数据关键技术
层面分为:
数据采集与预处理
数据存储和管理
数据处理与分析
数据安全与隐私保护
数据计算模式分为:
批处理计算 MapReduce Spark
图计算 百度的DStream 淘宝的银河流数据处理平台
图计算 Pregel
查询分析计算 Impala
6 大数据产业
IT基础建设层
数据源层
数据管理层
数据分析层
数据平台层
数据应用层
7大数据与云计算、物联网的关系
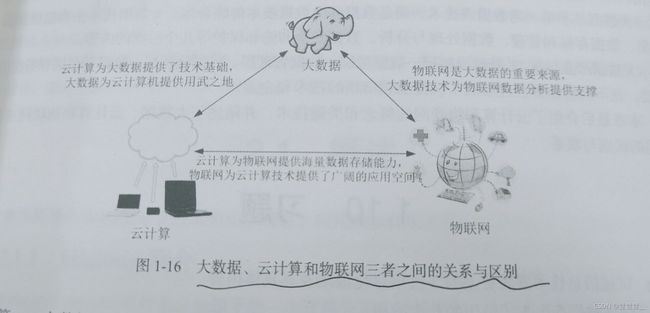
云计算:虚拟化 分布式存储 分布式计算 多租户
物联网:识别和感知技术 网络与通信技术 数据挖掘和融合技术
二 Hadoop
1.Hadoop的基础了解及使用
Hadoop是一个开源的,可运行于大规模集群上的分布式计算平台,具有MapReduce计算模型和分布式文件系统HDFS等功能。它具有可靠性,高效,可维持的特性。
在后续开发Hadoop2.0,实现联邦集群管理和YARN资源管理
它包含Map和Reduce操作,尤其是suffer操作很重要
它与后来的spark平台有相对的比较
在Hadoop生态系统中包含了很多其他的组件。如Zookepper,hive仓库
Hadoop自带有hdfs分布式系统,可以进行相关的shell命令
在Hadoop的安装中注意相关文件的配置,熟悉相关的命令
在后续Hbase数据库等都在Hadoop上进行运行
2关于hdfs分布式系统中的一些常用命令
1》创建文件:
mkdir创建文件夹:hdfs fs -mkdir [-p] < paths > hdfs dfs -mkdir /jdh
touchz新建文件:hdfs fs -touchz URI [URI …] hdfs dfs -touchz /jdh
2》显示文件:
显示目录与文件名:hdfs dfs -ls [-d][-h][-R] < paths >
d 列出/test目录信息 -h列出目录和文件的大小 -R循环列出目录、子目录及文件信息
3》删除文件目录或者全部文件:
删除目录和文件:hdfs dfs -rm [-f] [-r|-R] < paths >
-r 级联删除目录下的所有文件和子目录文件
4》上传,复制和覆盖:
hdfs dfs -put [-f] [-p] < localsrc > … < dst >
hdfs dfs -get [-p] [-ignoreCrc] [-crc] < src > … < localdst >
put将本地文件系统的复制到HDFS文件系统的目录下
get 将HDFS中的文件复制到本地文件系统中,与-put命令相反
-f 如果文件在分布式文件系统上已经存在,则覆盖存储,若不加则会报错
-p 保持源文件的属性(组、拥有者、创建时间、权限等)把本地新建的文件放到分布式文件系统主目录下,保持源文件属性
5》查看文件内容:
hdfs dfs -cat/text [-ignoreCrc] < src >
Hdfs dfs -tail [-f] < file >
其中,-ignoreCrc 忽循环检验失败的文件;-f 动态更新显示数据,如查看某个不断增长的文件的日志文件。
3个命令都是在命令行窗口查看指定文件内容。区别是 text 不仅可以查看文本文件,还可以查看压缩文件和Avro序列化的文件,其他两个不可以;tail 查看的是最后1KB的文件(Linux上的tail默认查看最后10行记录)
6》appendToFile追写文件
使用方法: hdfs dfs -du [-s] [-h] < path > …
7》cp复制文件
hdfs dfs -cp /test/file /test/file 注意空格
3分布式文件系统HDFS
是Hadoop中的分布式文件系统,对大量的集群的文件进行管理。
-
文件系统定义:文件系统是一种存储和组织计算机数据的方法,它使得对其访问和查找变得容易。
-
文件名:在文件系统中,文件名是用于定位存储位置。
-
元数据(Metadata):保存文件属性的数据,如文件名,文件长度,文件所属用户组,文件存储位置等。
-
数据块(Block):存储文件的最小单元。对存储介质划分了固定的区域,使用时按这些区域分配使用。
①特点:具有容错性,高吞吐量,存储容量大
它延迟比较低,有很多的小文件,
流式数据访问
②HDFS架构包含三个部分:NameNode,DataNode,Client。
NameNode叫名称节点,DataNode叫数据节点
名称节点负责元数据之间的映射关系
数据节点负责对元数据的读写信息
……