算法刷题笔记(CodeTop)
个人通过CodeTop的刷过一些经典算法
目录
leetcode 146 LRU缓存
leetcode 912 手撕快速排序
leetcode 15 三数之和
leetcode 53 最大子序和
leetcode 33 搜索旋转排序数组
leetcode 25 K个一组反转链表
leetcode 21 合并有序链表
leetcode 102 二叉树的层序遍历
leetcode 121 买卖股票的最佳时机
leetcode 141 环形链表
leetcode 103 二叉树的锯齿形层序遍历
leetcode 20 有效的括号
leetcode 88 合并两个有序数组
leetcode 5 最长回文子串
leetcode 236 二叉树的最近公共祖先
leetcode 206 反转链表
leetcode 3 无重复字符的最长子串
leetcode 121 买卖股票的最佳时机
leetcode 1 两数之和
leetcode 200 岛屿数量
leetcode 46 全排列
leetcode 160 相交链表
leetcode 54 螺旋矩阵
leetcode 23 合并K个升序链表
leetcode 146 LRU缓存

思路:使用LinkedHashMap,LinkedHashMap是一个会按照put顺序,为key排序的的一个hash链表。作为缓存,在get时,如果命中缓存,将key删除重新put到链表尾部;在put时,如果命中缓存,将key删除再重新put到链表尾部,如果未命中且链表长度已满,删除链表头节点。即新的数据插入链表尾部,旧的数据从链表头部删除。
class LRUCache {
private int capacity;
private Map map;
public LRUCache(int capacity) {
this.capacity = capacity;
map = new LinkedHashMap<>();
}
public int get(int key) {
if(map.containsKey(key)){
moveToFirst(key);
return map.get(key);
}else{
return -1;
}
}
public void put(int key, int value) {
if(map.containsKey(key)){
moveToFirst(key);
map.put(key,value);
}else{
if(map.size() >= capacity){
map.remove(map.keySet().iterator().next());
}
map.put(key,value);
}
}
public void moveToFirst(int key){
int val = map.remove(key);
map.put(key,val);
}
} leetcode 912 手撕快速排序

思路:本题主要考察的是快排的写法,有两种,一种是基于交换的快排,一种是堆排序。
class Solution {
public int[] sortArray(int[] nums) {
quickSort(nums,0,nums.length-1);
return nums;
}
public void quickSort(int[] nums,int L, int R){
if(L >= R) return;
int mid = (L + R) >> 1;
swap(nums,L,mid);
int pivot = nums[L];
int index = L;
for(int i = L+1; i <= R; i++){
if(nums[i] < pivot){
index++;
swap(nums,index,i);
}
}
swap(nums,L,index);
quickSort(nums,L,index - 1);
quickSort(nums,index + 1,R);
}
public void swap(int[] nums,int i, int j){
int temp = nums[i];
nums[i] = nums[j];
nums[j] = temp;
}
}leetcode 15 三数之和

思路:本题的难点在于如何去除重复的解,本题解使用排序+双指针。
1.先对数组进行排序。
2.从数组开头遍历获取一个值,如果值大于0,直接结束;如果小于0,判断是否与前一个值相同,相同则循环找下一个值,直到不同。
3.确定一个数之后,再通过双指针获取剩下两个数,左指针指向当前的下一个数,右指针指向数组的最后一个数
4.将三个数相加,和大于0,右指针左移;和小于0,左指针右移;等于0,将三个数加入结果集,同时左指针右移、右指针左移,继续获取解。
class Solution {
public List> threeSum(int[] nums) {
List> lists = new ArrayList<>();
if(nums == null || nums.length < 3){
return lists;
}
Arrays.sort(nums);
for(int i = 0; i < nums.length; i++){
if(nums[i] > 0) break;
if(i > 0 && nums[i] == nums[i-1]) continue;
int L = i + 1;
int R = nums.length - 1;
while( L < R ){
if(L - 1 > i && nums[L-1] == nums[L]){
L++;
continue;
}
if(R + 1 < nums.length && nums[R+1] == nums[R]){
R--;
continue;
}
if(nums[i] + nums[L] + nums[R] == 0){
List list = new ArrayList<>();
list.add(nums[i]);
list.add(nums[L]);
list.add(nums[R]);
lists.add(list);
L++;
R--;
}else if(nums[i] + nums[L] + nums[R] > 0){
R--;
}else{
L++;
}
}
}
return lists;
}
} leetcode 53 最大子序和

思路:最大子序和考虑到需要是连续的,当前元素加上之前的和如果大于当前元素本身,就加入的子序和中,如果当前元素加上之前的和小于当前元素本身,不如直接从当前元素开始重新计算子序和。
class Solution {
public int maxSubArray(int[] nums) {
int result = nums[0];
int current = nums[0];
for(int i = 1; i < nums.length; i++){
if(current + nums[i] > nums[i]){
current += nums[i];
}else{
current = nums[i];
}
result = Math.max(current,result);
}
return result;
}
}leetcode 33 搜索旋转排序数组

思路:使用二分查找,由于是将原本排序过的数组进行旋转,根据中点分成两段,两段之中一定有其中一段是有序的,所以这种情况也适用于二分查找。
二分不是单纯指从有序数组中快速找某个数,这只是二分查找的一个应用。
二分的本质是两段性,并非单调性。只要一段满足某个性质,另一段不满足某个性质,就可以使用二分。
class Solution {
public int search(int[] nums, int target) {
int left = 0;
int right = nums.length - 1;
while(left <= right){
int mid = (left + right) >> 1;
if(nums[mid] == target) return mid;
if(nums[0] <= nums[mid]){
if(target < nums[mid] && target >= nums[left]){
right = mid - 1;
}else{
left = mid + 1;
}
}else{
if(target > nums[mid] && target <= nums[right]){
left = mid + 1;
}else{
right = mid - 1;
}
}
}
return -1;
}
}leetcode 25 K个一组反转链表

思路:本题考查的是翻转链表,不过是将整个链表拆分为n个分别进行翻转,同时还需要几个变量来记录翻转前后的节点。
class Solution {
public ListNode reverseKGroup(ListNode head, int k) {
if (k == 1){
return head;
}
ListNode dummy = new ListNode();
dummy.next = head;
ListNode pre = dummy;
ListNode end = dummy;
while (end.next != null) {
for (int i = 0; i < k && end != null; i++) end = end.next;
if (end == null) break;
ListNode start = pre.next;
ListNode next = end.next;
end.next = null;
pre.next = reverse(start);
start.next = next;
pre = start;
end = pre;
}
return dummy.next;
}
public ListNode reverse(ListNode head){
ListNode pre = null;
ListNode current = head;
while(current != null){
ListNode next = current.next;
current.next = pre;
pre = current;
current = next;
}
return pre;
}
}
leetcode 21 合并有序链表
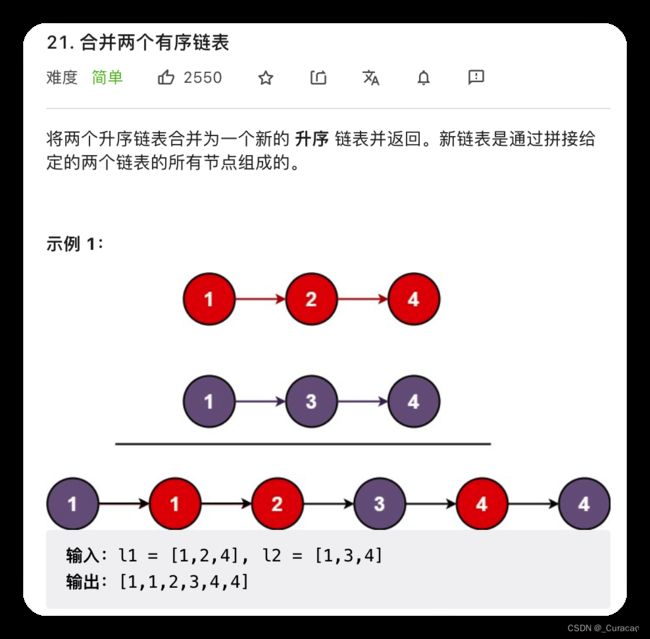
思路:使用递归,每次递归比较两个链表当前节点的大小。
终止条件:当两个链表都为空时,表明已经合并完成。
如何递归:判断每次的list1和list2的头结点大小,将较小结点的next指针指向其余的待递归的结点合并结果。
力扣对于递归计算进行详细说明,递归时间复杂度通常是调用数量 R 和计算的时间复杂度O(s)的乘积:O(T) = R * O(s)
所以本题的时间复杂度:O(m+n),m和n分别时两个链表的长度,因为递归每次只取掉一个结点,因此调用次数为m+n,计算只是对结点进行赋值,因此时间复杂度为O(1),最终时间复杂度为O(m+n)
空间复杂度:O(m+n),对于递归调用,当遇到终止条件时,已经调用了m+n次,使用了m+n个栈帧,故最后的空间复杂度为O(m+n)
class Solution {
public ListNode mergeTwoLists(ListNode list1, ListNode list2) {
if(list1 == null){
return list2;
}
if(list2 == null){
return list1;
}
if(list1.val < list2.val){
list1.next = mergeTwoLists(list1.next,list2);
return list1;
}else{
list2.next = mergeTwoLists(list1,list2.next);
return list2;
}
}
}leetcode 102 二叉树的层序遍历

思路:使用BFS(广度优先遍历),使用队列,同时需要将遍历的数字分为各自的层次,所以需要用到size来记录每个层的个数然后一口气处理完。
class Solution {
public List> levelOrder(TreeNode root) {
List> ans = new ArrayList<>();
LinkedList queue = new LinkedList<>();
if(root == null) return ans;
queue.add(root);
while(!queue.isEmpty()){
int size = queue.size();
List list = new ArrayList<>();
for(int i = 0; i < size; i++){
TreeNode temp = queue.pop();
if(temp.left != null) queue.add(temp.left);
if(temp.right != null ) queue.add(temp.right);
list.add(temp.val);
}
ans.add(list);
}
return ans;
}
} leetcode 121 买卖股票的最佳时机

思路: 动态规划思想,遍历数组,如果当天的股票价格低于历史最低价格则替换,并且作为买入股票的价格,如果高于买入价格,则算出差值作为最大利润。
class Solution {
public int maxProfit(int[] prices) {
int minPrice = Integer.MAX_VALUE;
int maxProfit = 0;
for(int i = 0; i < prices.length; i++){
if(prices[i] < minPrice){
minPrice = prices[i];
}else if(prices[i] - minPrice > maxProfit){
maxProfit = prices[i] - minPrice;
}
}
return maxProfit;
}
}leetcode 141 环形链表

思路:链表相对于数组有两个缺点:无法高效获取长度,无法根据偏移量快速访问元素。所以在碰见需要关于链表的长度和结点位置有关的问题,都可以使用双指针灵活解决。本题使用快慢指针,如果链表存在环的话,快慢指针通过不断移动之后将会相遇。
public class Solution {
public boolean hasCycle(ListNode head) {
ListNode fast = head;
ListNode slow = head;
while(fast != null && fast.next != null){
fast = fast.next.next;
slow = slow.next;
if(fast == slow){
return true;
}
}
return false;
}
}leetcode 103 二叉树的锯齿形层序遍历

思路:类似二叉树的层序遍历,在此基础上通过一个变量来决定用队列的头插法或尾插法。
class Solution {
public List> zigzagLevelOrder(TreeNode root) {
List> ans = new ArrayList<>();
LinkedList queue = new LinkedList<>();
if(root != null){
queue.add(root);
}
boolean order = true; //通过这个变量控制头插法和尾插法
while(!queue.isEmpty()){
LinkedList list = new LinkedList<>();
int size = queue.size();
for(int i = 0; i < size; i++){
TreeNode temp = queue.poll();
if(order){
list.offerLast(temp.val);
}else{
list.offerFirst(temp.val);
}
if(temp.left != null) queue.add(temp.left);
if(temp.right != null) queue.add(temp.right);
}
ans.add(list);
order = !order;
}
return ans;
}
} leetcode 20 有效的括号
 思路:使用map来作为判断条件,可以减少使用 if 来进行判断,同时使用栈来存储括号。
思路:使用map来作为判断条件,可以减少使用 if 来进行判断,同时使用栈来存储括号。
class Solution {
public boolean isValid(String s) {
if(s.length() % 2 != 0){
return false;
}
LinkedList stack = new LinkedList<>();
Map map = new HashMap<>();
map.put(')','(');
map.put(']','[');
map.put('}','{');
for(int i = 0; i < s.length(); i++){
char c = s.charAt(i);
if(map.containsKey(c)){
if(stack.isEmpty() || stack.peek() != map.get(c)){
return false;
}
stack.poll();
}else{
stack.offerFirst(c);
}
}
return stack.isEmpty();
}
} leetcode 88 合并两个有序数组

思路:根据题意得知,并不是合并为一个新数组,而是合并到nums1数组中,所以可以使用双指针和倒序合并来解决,当nums2指针小于0,直接返回,当nums1指针小于0,循环将nums2剩下的元素放进nums1数组。
class Solution {
public void merge(int[] nums1, int m, int[] nums2, int n) {
int i = m - 1;
int j = n - 1;
int idx = m + n - 1;
while(i >= 0 && j >= 0){
if(nums1[i] <= nums2[j]){
nums1[idx] = nums2[j];
j--;
}else{
nums1[idx] = nums1[i];
i--;
}
idx--;
}
while(j >= 0){
nums1[idx] = nums2[j];
idx--;
j--;
}
}
}leetcode 5 最长回文子串
 思路:
思路:
动态规划,回文天然具有状态转移的性质,一个长度大于2的回文子串去掉收尾之后,剩下的部分依然是回文。反之,如果一个字符串头尾两个字符不相等,那它一定不是回文,动态规划的方法由此性质得到。
第一步:定义状态
dp[ i ][ j ] 表示子串 s [ i ... j ] 是否为回文子串,这里的区别定义为闭区间,可以取到 s[ i ] 和 s[ j ]。
第二部:思考状态转移方程
根据头尾字符是否相等,需要分类讨论:
dp[ i ][ j ] = s[ i ] == s[ j ] && dp[ i +1 ][ j - 1]
说明:
动态规划的自顶向下求解问题的思路,很多时候是在填写一张二维表格。由于 s [ i ... j ] 表示 s 的一个子串,所以 i 和 j 的关系是 i <= j ,只需要填这张表格对角线以上的部分。
看到dp [ i + 1 ][ j - 1 ]就需要考虑特殊情况:如果去掉 s[ i .. j ]头尾两个字符,子串 [ i + 1 ... j - 1]的长度小于2,即 j - 1 - ( i + 1) < 2,也就是 j - i < 3,此时 s [ i ... j ] 是否为回文子串取决于 s [ i ] 和 s [ j ] 是否相等。
第三步:考虑初始化
单个字符一定是回文子串,因此把对角线初始化为true,即dp [ i ][ i ] = true,根据第二步的结论,当s[ i ... j ]的长度为2时,只需要判断s[ i ] 是否等于 s[ j ],所以二维表格对角线上的数值不会被参考,所以不设置dp [ i ][ i ] = true,也可以得出正确结论。
第四步:考虑输出
一旦得到dp[ i ][ j ]为true,就记录下 i 和 j 的数值,没有必要进行截取,因为字符串截取也会消耗性能。
class Solution {
public String longestPalindrome(String s) {
int x = 0;
int y = 0;
int n = s.length();
boolean[][] dp = new boolean[n][n];
for(int j = 0; j < n; j++){
for(int i = 0; i <= j; i++){
if(s.charAt(i) == s.charAt(j) && (j - i < 2 || dp[i+1][j-1])){
dp[i][j] = true;
if(j - i > y - x){
y = j;
x = i;
}
}
}
}
return s.substring(x,y+1);
}
}leetcode 236 二叉树的最近公共祖先

思路:祖先的定义,若p在节点root的左(右)子树中,或 p = root,则称root是p的祖先。
根据以上定义,若root是p和q的最近公共祖先,则只可能是以下情况之一:
1.p和q在root的子树中,且分列在root的异侧(即分别在左、右子树)
2.p = root,且q在root的左或右子树中
3.q = root,且p在root的左或右子树中
考虑通过递归对二叉树进行先序遍历,当遇到节点p或q时返回,从底至顶回溯,当节点p,q在root的异侧时,节点root即为最近公共祖先,则向上返回root。
递归解析:
1.终止条件:
当越过叶子节点,返回null;
当root等于p,q,返回root。
2.递推工作:
开启递归左子节点,返回值记为left;
开启递归右子节点,返回值记为right。
3.返回值:根据left和right,可展开四种情况。
(1)left 和 right 同时为空,说明root的左右子树都不包含p,q,返回null;
(2)left和right同时不为空,说明p和q分别在root的异侧(即分别在左子树和右子树),返回root
(3)left为空,right不为空,说明p和q都不在root的左子树中,直接返回right。这种情况可分为两种,
1)p,q其中一个在root的右子树中,同时right指向p(假设为p,也可以假设为q)
2)p,q都在root的右子树中,同时right指向最近公共祖先节点(可以为p,也可以为q)
(4)当left不为空,right为空,与情况3同理。
class Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
if(root == null || root == p || root == q) return root;
TreeNode left = lowestCommonAncestor(root.left,p,q);
TreeNode right = lowestCommonAncestor(root.right,p,q);
if(left == null && right == null) return null;
if(left == null) return right;
if(right == null) return left;
return root;
}
}leetcode 206 反转链表

思路:本题的解法有很多,这里采用双指针+递归的方式。
双指针:递归的传参为前一个节点pre 和 当前节点cur。
递归解析:
终止条件:当前节点的下一个节点为空时,终止递归。此时当前节点即时链表的最后一个节点,由于该题时要反转链表,所以此时的最后一个节点翻转后就是链表的头节点,所以将该节点返回。
递归工作:每一层递归要做的事就是将当前节点的 next 修改为指向前一个节点 pre ,达成链表的翻转,并将返回的最后一个节点继续返回。
时间复杂度:力扣的递归时间复杂度是采用递归的调用次数和每层递归的时间复杂度的乘积,因此这里的时间复杂度为 O( n ) * O ( 1 ),n为链表长度,即递归调用次数,1为每层递归的赋值操作。
class Solution {
public ListNode reverseList(ListNode head) {
if(head == null){
return head;
}
return recursion(null,head);
}
public ListNode recursion(ListNode pre,ListNode cur){
if(cur.next == null){
cur.next = pre;
return cur;
}
ListNode newHead = recursion(cur,cur.next);
cur.next = pre;
return head;
}
}leetcode 3 无重复字符的最长子串

思路:看到子串问题一般都可以采用滑动窗口来解决,本题采用双指针滑动窗口+Map解决。
双指针:left 作为左指针,right 作为右指针,采用for循环,右指针 right 每次向右移动一位。
Map的作用:右指针 right 每次向右移动一位,便将该位置的字符 和 该字符在字符串中的位置记录到map中,有两种情况。
1.当前字符第一次出现,还未记录到map中,直接put进去。
2.当前字符已经出现过,同时会出现两种情况。
(1)已经出现过的字符在滑动窗口中,即在左指针 left 和右指针 right 中间。此时将左指针 left 赋值为 已经出现过的字符的位置 +1(即下一个),并更新map中该字符新出现的位置。
(2)已经出现过的字符在滑动窗口外,即在左指针 left 的左边。此时直接更新map中该字符的新位置。
最后,每一次循环都计算滑动窗口的长度,得出最大的长度。
时间复杂度:O(n),对字符串进行一个遍历,n为字符串的长度。
class Solution {
public int lengthOfLongestSubstring(String s) {
int left = 0;
int maxLength = 0;
Map map = new HashMap<>();
for(int i = 0; i < s.length(); i++){
char c = s.charAt(i);
if(map.containsKey(c) && map.get(c) >= left){
left = map.get(c) + 1;
map.put(c,i);
}else{
map.put(c,i);
}
maxLength = Math.max(i - left + 1, maxLength);
}
return maxLength;
}
} leetcode 121 买卖股票的最佳时机

思路: 一次遍历,有点类似动态规划。
既然想要得出买卖股票能得出的最大利润,首先肯定需要一个变量 maxProfit 来记录最大利润,初始值为 0 ,同时还需要一个变量minPrice来记录我们应该买入股票的最低价格,初始值为无穷大,最后for循环从左到右遍历每天的股票价格 price[ i ] 对 maxProfit 和 minPrice 的影响。如下:
1.当price[i] < minPrice 时,此时的股票价格是我们目前遇到到最低价,应该考虑买入,所以minPrice = price[i]
2.当price[i] > minPrice 时,此时的股票价格是大于我们的最低价,可以考虑卖出,如果卖出的利润大于 maxProfit ,即更新maxProfit。
3.当price[i] == minPrice 时,跳过。
class Solution {
public int maxProfit(int[] prices) {
int minPrice = Integer.MAX_VALUE;
int maxProfit = 0;
for(int i = 0; i < prices.length; i++){
if(prices[i] < minPrice){
minPrice = prices[i];
}else if(prices[i] - minPrice > maxProfit){
maxProfit = prices[i] - minPrice;
}
}
return maxProfit;
}
}leetcode 1 两数之和

思路:使用Map缓存。
遍历数组,将遍历到的每个元素和在数组对应的索引位置 put 到 Map 中记录下来,此时有两种情况:
1. 如果 target 减去当前遍历到的元素的差可以在Map中找到,直接返回结果;
2.如果 target 减去当前遍历到的元素的差在Map未找到,将当前元素put到Map中,key为元素,value为元素在数组中的索引位置。
class Solution {
public int[] twoSum(int[] nums, int target) {
Map map = new HashMap<>();
int[] ans = new int[2];
for(int i = 0; i < nums.length; i++){
if(map.containsKey(target - nums[i])){
ans[0] = map.get(target - nums[i]);
ans[1] = i;
return ans;
}else{
map.put(nums[i],i);
}
}
return ans;
}
} leetcode 200 岛屿数量
思路:深度优先遍历(DFS),将访问过的 "1" 都改为 "0"。
首先循环遍历整个二维数组,当遍历到的元素为 "1" 时,进行递归(深度优先遍历也是递归的一种)。
递归解析:
终止条件:当前的数组索引超出二维数组的范围或者当前元素为 "0"。
递归工作:将当前元素 "1" 改为 "0",再以上左右下的顺序递归(任意顺序都可以)。
递归结束之后,将记录岛屿的数量+1再继续遍历二维数组。
class Solution {
public int numIslands(char[][] grid) {
int count = 0;
for(int i = 0; i < grid.length; i++){
for(int j = 0; j < grid[0].length; j++){
if(grid[i][j] == '1'){
dfs(grid,i,j);
count++;
}
}
}
return count;
}
public void dfs(char[][] grid,int i,int j){
if(i >= 0 && i < grid.length && j >= 0 && j < grid[0].length && grid[i][j] == '1'){
grid[i][j] = '0';
dfs(grid,i - 1,j);
dfs(grid,i,j - 1);
dfs(grid,i,j + 1);
dfs(grid,i + 1,j);
}
}
}leetcode 46 全排列

思路:全排列问题一般的方法就是使用 递归回溯 + 使用一个 boolean 数组来记录访问过的元素
递归解析:
终止条件:当前排列的元素数量到达nums数组的长度,将该排列加入到全排列的数组中并回溯,即返回到上一次递归。
递归工作:对nums数组从头到尾遍历,判断元素是否访问过,此时有两种情况:
1.访问过,continue 跳过该元素;
2.未访问,将该元素加入到当前排列,同时将该元素记录为已访问。当前递归已经加入了一个元素,进入下一层递归。当递归回溯到这一层时,将刚才加入到排列中的元素删除,同时该元素记录为未访问,然后遍历下一个元素,继续判断是否访问过。
class Solution {
public List> permute(int[] nums) {
List> ans = new ArrayList<>();
List list = new ArrayList<>();
int n = nums.length;
boolean[] used = new boolean[n];
dfs(ans,list,n,nums,used);
return ans;
}
public void dfs(List> ans,List list,int n,int[] nums,boolean[] used){
if(list.size() == n){
List temp = new ArrayList<>(list);
ans.add(temp);
return;
}
for(int i = 0; i < n; i++){
if(used[i]) continue;
list.add(nums[i]);
used[i] = true;
dfs(ans,list,n,nums,used);
used[i] = false;
list.remove(list.size()-1);
}
}
} leetcode 160 相交链表

思路:双指针
设 第一个相交节点 为node,链表A的节点数量为 a ,链表B的节点数量为 b,两条链表的公共尾部的节点数量为 c。
从 headA 到 node 前的长度为 a - c。
从 headB 到 node 前的长度为 b - c。
此时构建两个节点 A 和 B:
A 遍历 链表A,遍历完链表A之后再遍历链表B,当走到node时的长度为:a + (b - c)
B 遍历 链表B,遍历完链表B之后再遍历链表A,当走到node时的长度为:b + (a - c)
由于 a + (b - c)= b + (a - c),所以 A 和 B 走了相同的长度,访问到同一个节点。
此时有两种情况:
1.链表A 和 链表B 相交,该节点为相交节点;
2.链表A 和 链表B 没有相交,该节点为null;
public class Solution {
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
ListNode curA = headA;
ListNode curB = headB;
while(curA != curB){
if(curA == null){
curA = headB;
}else{
curA = curA.next;
}
if(curB == null){
curB = headA;
}else{
curB = curB.next;
}
}
return curA;
}
}leetcode 54 螺旋矩阵

思路:
先定义遍历数组的边界,按照从左到右、从上到下、从右到左、从下到上的顺序遍历数组,每次走完一行或者一列后,将该行或该列删除,缩小边界。当边界交错时,遍历结束。
class Solution {
public List spiralOrder(int[][] matrix) {
int left = 0;
int right = matrix[0].length - 1;
int top = 0;
int bottom = matrix.length - 1;
List ans = new ArrayList<>();
while(true){
for(int i = left; i <= right; i++){
ans.add(matrix[top][i]);
}
if(++ top > bottom) break;
for(int i = top; i <= bottom; i++){
ans.add(matrix[i][right]);
}
if(-- right < left) break;
for(int i = right; i >= left; i--){
ans.add(matrix[bottom][i]);
}
if(-- bottom < top) break;
for(int i = bottom; i >= top; i--){
ans.add(matrix[i][left]);
}
if(++ left > right) break;
}
return ans;
}
} leetcode 23 合并K个升序链表
思路:分治合并,使用递归和二分法将数组进行一层一层的一分为二,分到不可再分时递归返回,对返回的两个链表进行排序,再将排序好的链表向上返回。
递归解析:
终止条件:当左指针left > 右指针right 返回null,或者 左指针left == 右指针right,返回当前链表。
递归工作:取左指针left 和 右指针right 的中点mid,将left和mid继续递归,mid + 1和right继续递归,直到达成终止条件返回,将返回的两个链表进行排序。
class Solution {
public ListNode mergeKLists(ListNode[] lists) {
return merge(lists,0,lists.length - 1);
}
public ListNode merge(ListNode[] lists,int left,int right){
if(right == left) return lists[left];
if(left > right) return null;
int mid = (left + right) >> 1;
return sort(merge(lists,left,mid),merge(lists,mid + 1,right));
}
public ListNode sort(ListNode node1,ListNode node2){
ListNode dummy = new ListNode();
ListNode cur = dummy;
while(node1 != null && node2 != null){
if(node1.val < node2.val){
cur.next = node1;
node1 = node1.next;
}else{
cur.next = node2;
node2 = node2.next;
}
cur = cur.next;
}
cur.next = node1 == null ? node2 : node1;
return dummy.next;
}
}持续更新ing