【Python实战】Python对中国500强排行榜数据进行可视化分析
目录
前言
环境使用
模块使用
模块介绍
模块安装问题:
数据采集
确定网址
获取数据
解析数据
保存数据
数据可视化
代码
效果
总结
前言

今天来跟大家分析一下2022年中国500强企业排行榜数据,从不同角度去对数据进行统计分析,可视化展示。
本文从开始到最后发文,花费了一天时间(精心制作),保证以高质量文章给大家阅读,麻烦给个赞和在看,谢谢.
环境使用
- python 3.9
- pycharm
模块使用
- requests
模块介绍
- requests
requests是一个很实用的Python HTTP客户端库,爬虫和测试服务器响应数据时经常会用到,requests是Python语言的第三方的库,专门用于发送HTTP请求,使用起来比urllib简洁很多。
- parsel
parsel是一个python的第三方库,相当于css选择器+xpath+re。
parsel由scrapy团队开发,是将scrapy中的parsel独立抽取出来的,可以轻松解析html,xml内容,获取需要的数据。
相比于BeautifulSoup,xpath,parsel效率更高,使用更简单。
- re
re模块是python独有的匹配字符串的模块,该模块中提供的很多功能是基于正则表达式实现的,而正则表达式是对字符串进行模糊匹配,提取自己需要的字符串部分,他对所有的语言都通用。
- os
os 就是 “operating system” 的缩写,顾名思义,os模块提供的就是各种 Python 程序与操作系统进行交互的接口。通过使用 os 模块,一方面可以方便地与操作系统进行交互,另一方面也可以极大增强代码的可移植性。
- csv
它是一种文件格式,一般也被叫做逗号分隔值文件,可以使用 Excel 软件或者文本文档打开 。其中数据字段用半角逗号间隔(也可以使用其它字符),使用 Excel 打开时,逗号会被转换为分隔符。csv 文件是以纯文本形式存储了表格数据,并且在兼容各个操作系统。
模块安装问题:
- 如果安装python第三方模块:
win + R 输入 cmd 点击确定, 输入安装命令 pip install 模块名 (pip install requests) 回车
在pycharm中点击Terminal(终端) 输入安装命令
- 安装失败原因:
- 失败一: pip 不是内部命令
解决方法: 设置环境变量
- 失败二: 出现大量报红 (read time out)
解决方法: 因为是网络链接超时, 需要切换镜像源
清华:https://pypi.tuna.tsinghua.edu.cn/simple 阿里云:https://mirrors.aliyun.com/pypi/simple/ 中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/ 华中理工大学:https://pypi.hustunique.com/ 山东理工大学:https://pypi.sdutlinux.org/ 豆瓣:https://pypi.douban.com/simple/ 例如:pip3 install -i https://pypi.doubanio.com/simple/ 模块名
- 失败三: cmd里面显示已经安装过了, 或者安装成功了, 但是在pycharm里面还是无法导入
解决方法: 可能安装了多个python版本 (anaconda 或者 python 安装一个即可) 卸载一个就好,或者你pycharm里面python解释器没有设置好。
数据采集
确定网址
首先,我们对目标网址进行数据采集。我们可以清楚的看到,在2022年中新财富500富人榜。

确定好我们的目标网址之后,我们要找到我们需要的数据源,通过开发者工具分析,我们不难发现其数据地址。
下面,我们开始写代码。
获取数据
第一步,发送请求,获得数据。
import requests
url = 'https://service.ikuyu.cn/XinCaiFu2/pcremoting/bdListAction.do?method=getPage&callback=jsonpCallback&sortBy=&order=&type=4&keyword=&pageSize=15&year=2022&pageNo=1&from=jsonp&_=1680092323527'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36'}
res = requests.get(url,headers=headers)我们得到数据是这样的,大家可能会以为是一个json数据,其实不是,这个返回值需要我们进一步处理。
jsonpCallback({"data":{"pagesize":15,"current":1,"total":500,"rows":[{"assets":4983.5,"year":2022,"sex":"男","name":"钟睒睒","rank":1,"company":"农夫山泉/万泰生物","industry":"矿泉水饮料、医药生物","id":151478,"addr":"浙江杭州/北京","rankLst":"1","age":"68"},{"assets":3348.2,"year":2022,"sex":"男","name":"曾毓群","rank":2,"company":"宁德时代","industry":"动力电池","id":151479,"addr":"福建宁德","rankLst":"11","age":"54"},{"assets":3010.8,"year":2022,"sex":"男","name":"马化腾","rank":3,"company":"腾讯控股","industry":"互联网综合服务","id":151480,"addr":"广东深圳","rankLst":"3","age":"51"},{"assets":2916.0,"year":2022,"sex":"男","name":"张一鸣","rank":4,"company":"今日头条","industry":"推荐引擎产品、短视频","id":151481,"addr":"北京","rankLst":"16","age":"39"},{"assets":1972.0,"year":2022,"sex":"男","name":"黄峥","rank":5,"company":"拼多多","industry":"电商","id":151482,"addr":"上海","rankLst":"2","age":"42"},{"assets":1937.2,"year":2022,"sex":"男","name":"丁磊","rank":6,"company":"网易","industry":"互联网综合服务","id":151483,"addr":"浙江杭州","rankLst":"12","age":"51"},{"assets":1890.1,"year":2022,"sex":"男","name":"何享健家族","rank":7,"company":"美的集团","industry":"家电","id":151484,"addr":"广东佛山","rankLst":"5","age":"79"},{"assets":1860.3,"year":2022,"sex":"男","name":"王卫","rank":8,"company":"顺丰控股","industry":"物流","id":151485,"addr":"广东深圳","rankLst":"6","age":"51"},{"assets":1535.0,"year":2022,"sex":"男","name":"黄世霖","rank":9,"company":"宁德时代","industry":"动力电池","id":151486,"addr":"福建宁德","rankLst":"41","age":"55"},{"assets":1512.7,"year":2022,"sex":"男/女","name":"秦英林/钱瑛","rank":10,"company":"牧原股份","industry":"畜禽养殖","id":151487,"addr":"河南南阳","rankLst":"19","age":"57,56"},{"assets":1401.1,"year":2022,"sex":"男","name":"王传福","rank":11,"company":"比亚迪","industry":"新能源汽车、电池","id":151488,"addr":"广东深圳","rankLst":"39","age":"56"},{"assets":1388.6,"year":2022,"sex":"男","name":"李西廷","rank":12,"company":"迈瑞医疗","industry":"医疗器械","id":151489,"addr":"广东深圳","rankLst":"18","age":"71"},{"assets":1348.1,"year":2022,"sex":"男/女","name":"王来胜/王来春","rank":13,"company":"香港立讯","industry":"连接器","id":151490,"addr":"广东深圳","rankLst":"17","age":"58,55"},{"assets":1327.2,"year":2022,"sex":"男","name":"马云","rank":14,"company":"阿里巴巴","industry":"互联网综合服务","id":151491,"addr":"浙江杭州","rankLst":"7","age":"58"},{"assets":1322.5,"year":2022,"sex":"女","name":"杨惠妍","rank":15,"company":"碧桂园控股","industry":"房地产","id":151492,"addr":"广东佛山","rankLst":"13","age":"40"}],"end":15,"start":1,"pageCount":34,"conditionsMap":{"year":"2022","pageNo":"1","sortOrder":"year desc,rank","pageSize":"15"},"pageSize":15},"success":true})
解析数据
我们发现,我们得到了这样jsonpCallback()的数据,可能就有人担心了,那这种情况,我们该怎么办呢,不要慌,我们只需要正则表达式就可以。
html_data = re.findall('jsonpCallback\((.*?)\)',res.text)[0]这样,我们就得到了json数据,接下来,我们就开始解析数据。
for index in json.loads(html_data)['data']['rows']:
# print(index)
dit = {
'姓名':index['name'],
'财富值':index['assets'],
'主要公司':index['company'],
'相关行业': index['industry'],
'公司总部':index['addr'],
'排名': index['rank'],
}保存数据
我们先把数据存入到字典里面,然后,方便我们写入csv文件里面,我们看看打印出来的字典数值是怎么样子的。

下面就是数据的写入了。其实,把字典数值写入到csv文件里面,特别简单,只需呀四行代码就可以实现。
f = open('财富榜.csv',mode='a',encoding='utf-8',newline='')
csv_writer = csv.DictWriter(f,fieldnames=['姓名','财富值','主要公司','相关行业','公司总部','排名'])
csv_writer.writeheader()写入字典数值。
csv_writer.writerow(dit)这时候,我们就会在文件夹里面找到财富值的csv文件,我们打开看看效果。

在这里,我只采集了第一页的数据,也就是前15的数据,如果,我们想进行多页数据采集,只需要对网址进行改变,我们会发现网址有相似的规律。直接for循环遍历就可以,这里,就不过多解释。
数据可视化
代码
我们在这里,就要用到pyecharts库,不得不说,这个功能非常强大,我们写这个代码也非常简单,我们只需要去官方文档,复制粘贴就可以,根据自己的数据稍微改动一点代码就可以。
import pandas as pd
import pyecharts.options as opts
from pyecharts.charts import Line
df = pd.read_csv('财富榜.csv')
x = ['农夫山泉/万泰生物' ,'宁德时代' ,'腾讯控股' ,'今日头条', '拼多多']
c = (
Line()
.add_xaxis(x)
.add_yaxis("财富值",df['财富值'].values)
.set_global_opts(title_opts=opts.TitleOpts(title="财富值分布"))
)我们直接让它生成一个网页,方便我们直观的感受。
c.render('地图.html')效果
这里,我做的图不够好看,但是基本功能都实现了。
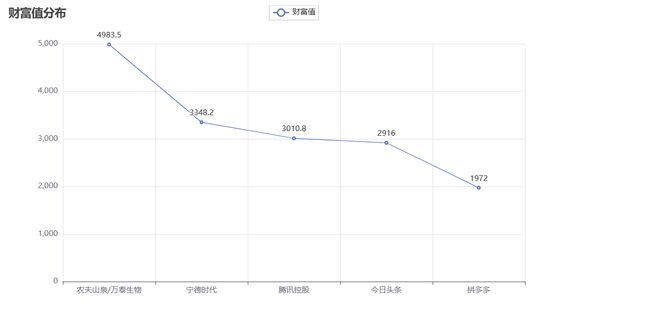
大家如果想做更多的图表,可以去官方网站看看,官方网站有很多示例可以使用。
总结
通过本文的学习,我们学习了数据采集以及可视化分析。我们在研究官方文档的时候,也是在一种学习,本次实战,我们明白如何解决返回值是jsonpCallback()的问题。今天就到这里,有什么问题,可以在评论区留言。
