[TOC]
一. CRNN概论
重点:原论文一定要得看!!!英语好的直接看原论文,不懂的地方查资料。英语不好的(比如笔者),先看中文资料,然后再看原论文。
简介
CRNN全称是:An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition说自己是端到端的的网络,其实严格意义根本不是的,而是一种识别网络而已。
严格意义端到端的网络:Fast Oriented Text Spotting with a Unified Network
请看下图为CRNN网络的输入,得检测到文字之后才能去识别文字。
不严格的端到端是啥意思呢?
下图1-2所示为传统的文字识别,还得把每个文字分割再去识别(这方面的东西不进行说明,很简单的传统方法)
而CRNN直接输入上图得到结果。
网络
CRNN网络结构入下图1-3所示:
- 特征提取
正常的图像提取,提取到的特征以序列方式输出,这里不懂的读者可以去看RNN训练手写数字识别
- BLSTM
特征输入到BLSTM,输出每个序列代表的值(这个值是一个序列,代表可能出现的值),对输出进行softmax操作,等于每个可能出现值的概率。
- CTC
相当于一个LOSS,一个计算概率到实际输出的概率,具体后面章节介绍。
- 创新点
- 使用双向BLSTM来提取图像特征,对序列特征识别效果明显
- 将语音识别领域的CTC—LOSS引入图像,这是质的飞越
- 不足点
- 网络复杂,尤其是BLSTM和CTC很难理解,且很难计算。
- 由于使用序列特征,对于角度很大的值很难识别。
二. CRNN局部之特征提取
假设上图2-1为提取到的特征(特征是一块一块的,这肯定不是特征图,为了看着舒服)
图像经过VGG的特征提取之后就是普通的feature map,然后进行上述的划分,形成特征序列!
如果你的文字很斜或者是纵向的,那就得把特征竖向划分序列了!
三. CRNN局部之BLSTM
基本原理不懂读者可以看看这个教程
懂了原理这部分还是比较简单的(理解简单,实现太难了),笔者这里只介绍几个使用过程难理解的点
- RNN输入序列数量
从上图可以得到的是X1---X6,总共6个序列
- RNN的层数

从上图3-2可以看出,是由五层网络构成
- RNN神经元数量
这里引用知乎大神的一个图,上图中序列为4,层数为3层(当然不加输入和输出也可以说是1层,这里按正常CNN去说就是3层了)
从图中可以看出每个序列包含一个CNN,图中的隐藏层神经元数量为24个,由于RNN使用权值共享,那么不同的神经元个数就为6个。
- 单个序列长度
以上图知乎大神的图为例子,每个输入序列长度8
假设这个网络是一个RNN识别手写数字识别的图,那么图像的宽为4,高为8
注意:输入序列的数量和输入序列的长度和神经元个数无关!!!这里想象RNN即可理解
- BLSTM
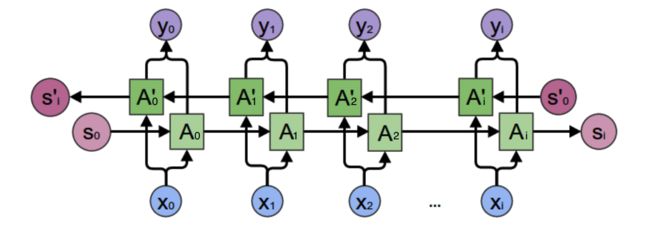
笔者只是推导了单向的LSTM网络,而没有推导BLSTM网络。
其实无论RNN如何变种,像现在最好的GRU等,无非都是在单元(unite)里面的trick而已。
具体公式推导,就是链式求导法则!建议先推RNN、然后LSTM、最后不用推导BLSTM都明白了
四. CRNN局部之CTC
关于CTC的描述网上很多,也讲解的比较清楚了,这里主要是说一下我笔者看原理时候的几个难点(弄了好久才想明白)
关于CTC是什么东西?
- 让我们来看一下正常分类CNN网络:
图4-1
这是鸢尾花分类网络,其中输入一张图像,输出是经过softmax的种类概率。
那么这个网络标签是什么???
标签的制作都是需要经过Incode(分类的种类经过数字化编码),测试过程需要Encode(把输出的数字解码成分类的种类)
这很简单,读者应该都理解,代码为了计算机能看懂,编码就是神经网络能看懂。
- 那么RCNN如何编码呢?
假设有26个英文字母要识别,那么种类数=27(还有一个空白blank字符)
假设CNN输出以50个序列为基准(读者这里看不懂就去看RNN识别手写数字识别),序列太大训练不准,识别结果会漏字母。序列太小训练不准,识别会多字母。
- 打个小比喻
假设CTC是一个黑盒子,它能把输出那么多序列变化为一个序列,这样就能和CNN分类一样计算Loss了。当然不会那么简单,CTC还是比较复杂的,后面具体看这个黑盒子如何工作的。。。。
CTC理论基础
注释:这里笔者就不进行详细的描述了,感觉别人比我写的更好:非常详细的CTC力理论
在这一章,主要针对笔者遇到的重难点进行介绍:
- 训练--前向后相传播
本来还去看了马尔科夫的前后向传播的理论,没怎么看懂(数学基础太差)
针对本文的CTC前后向传播还是比较简单理解的
其实这里可以理解为动态规划的方式进行的,因为其使用递归的方式,以一个点为中心,向前和向后进行递推,以动态规划的方式理解就很简单了。。。。不懂的读者可以刷leetcode,做几题就有感觉了
- 测试--CTC Prefix Search Decoding和CTC Beam Search Decoding
最简单的搜索追溯算法:
每个都列举最后计算,可以看出来是指数级搜索,效率肯定不行的
贪婪算法+动态规划---CTC Prefix Search Decoding:
第一步是进行合并操作:
第二步输出最大概率:
扩充CTC Prefix Search Decoding算法---CTC Beam Search Decoding
- CTC Prefix Search Decoding属于贪心算法,为什么可以得到最优解?
仔细看我上面的标题,CTC Prefix Search Decoding特意加了一个动态规划,动态规划是属于最优解的算法。
因为CTC算法的前提是序列相互独立,所以当前的序列最大,那么整体的序列最大。
注意:得合并之后的序列最大,而不是单个序列的最大!!!,如果是单个序列最大,那这就是单独的贪心算法了。
- 为什么CTC序列之间相互独立还可以计算有序列的文字,文字之间肯定有序列的啊?
这都得重新看网络了,网络用到了BLSTM,序列这个东西已经使用过了,到达CTC已经是使用序列之后的输出了。
不得不佩服设计网络的人RNN+CTC,语音是使用最早的。
其实回头想一下,如果CTC是有序列的,那么前向和后项概率根本不能使用马尔科夫模型(前提相互独立)了,也不能使用CTC Prefix Search Decoding,只能使用最简单的追溯算法,那效率那么低,怎么广泛使用呢?
五. 参考文献
CRNN原论文
CTC论文
深度学习笔记
RNN形象图
RCNN的pytorch实现-冠军的试炼
一文读懂CRNN+CTC文字识别
[透视矫正网络](Attentional Scene Text Recognizer with Flexible Rectification)
简化CTC讲解
知乎beam search讲解
非常详细的CTC讲解
一个CTC的小笔记
外国大神的讲解,大部分人都是直接翻译这个的
大神讲解马尔科夫的前后向计算
CTC详细代码实现+步骤讲解
快速阅读论文之扭曲矫正
2019CVPR论文汇总
ROI Align实现细节