Flink的Java Api 实现WordCount的批处理和流处理
1 基础说明
Flink 是一款优秀的批处理和流处理的大数据计算引擎,本文将通过Flink的Java Api实现WordCount多版本案例。更多请查阅 Flink官网
说明:
- Flink版本:1.13.5
- Flink Web UI地址:http://192.168.18.88:7999
- 服务器具备nc(netcat)环境,如果不具备,可在服务器执行安装命令
yum -y install netcat
2 WordCount案例
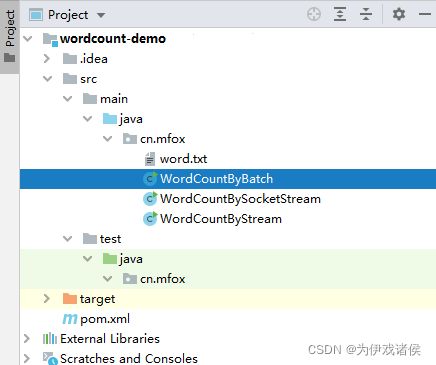
2.1 项目目录结构
创建maven项目,目录结构如下:
2.2 maven依赖
依赖内容如下:
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.14.4</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.14.4</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>1.14.4</version>
</dependency>
</dependencies>
完整的pom.xml文件如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.mfox</groupId>
<artifactId>wordcount-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<name>wordcount-demo</name>
<!-- FIXME change it to the project's website -->
<url>http://www.example.com</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.14.4</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.14.4</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>1.14.4</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
</project>
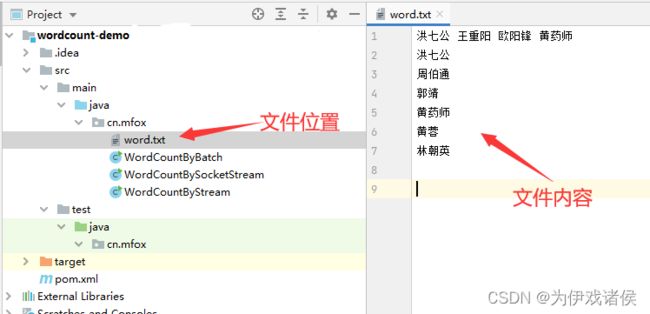
2.3 创建word.txt文件
创建src/main/java/cn/mfox/word.txt文件,word.txt文件的具体内容如下:
洪七公 王重阳 欧阳锋 黄药师
洪七公
周伯通
郭靖
黄药师
黄蓉
林朝英
word.txt文件位置及内容截图如下:
2.4 批处理WordCount
WordCountByBatch.java代码如下:
package cn.mfox;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.apache.flink.api.java.operators.FlatMapOperator;
import org.apache.flink.api.java.operators.UnsortedGrouping;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
/**
* 基于批计算的wordcount案例
*
* @author hy
* @version 1.0
* @date 2022/3/24 16:52
*/
public class WordCountByBatch {
public static void main(String[] args) throws Exception {
// 1. 创建执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 2. 从文件中读取文件,按行读取(存取的元素就是每行的文本)
String inputPath = "src/main/java/cn/mfox/word.txt";
DataSet<String> inputDataSet = env.readTextFile(inputPath);
// 3. 转换数据格式
// returns说明:当Lambda表达式使用Java泛型的时候,由于泛型擦除,需要显示的声明类型信息
FlatMapOperator<String, Tuple2<String, Long>> wordAndOne = inputDataSet
.flatMap((String line, Collector<Tuple2<String, Long>> out) -> {
Arrays.stream(line.split(" "))
.map(word -> word.trim())
.filter(word -> !word.isEmpty())
.map(word -> Tuple2.of(word, 1L))
.forEach(out::collect);
}).returns(Types.TUPLE(Types.STRING, Types.LONG));
// 4. 安装word进行分组
UnsortedGrouping<Tuple2<String, Long>> wordAndOneUG = wordAndOne.groupBy(0);
// 5. 分组内聚合
AggregateOperator<Tuple2<String, Long>> sumResult = wordAndOneUG.sum(1);
// 6. 打印结果
sumResult.print();
}
}
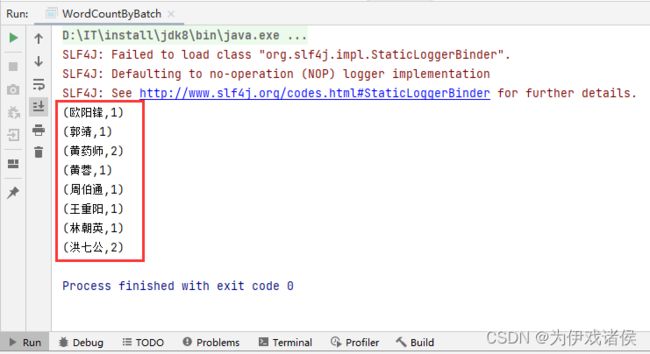
程序运行结果如下:
2.5 流处理WordCount
WordCountByStream.java代码如下:
package cn.mfox;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* 基于socket流计算的wordcount案例
*
* @author hy
* @version 1.0
* @date 2022/3/25 14:52
*/
public class WordCountByStream {
public static void main(String[] args) throws Exception {
// 1. 创建流式执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 从文件中读取文件
String inputPath = "src/main/java/cn/mfox/word.txt";
DataStream<String> inputDataStream = env.readTextFile(inputPath);
// 3. 转换计算
SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOne = inputDataStream
.flatMap((String line, Collector<String> words) -> {
// 分割及排空
Arrays.stream(line.split(" "))
.map(word -> word.trim())
.filter(word -> !word.isEmpty())
.forEach(words::collect);
}).returns(Types.STRING)
.map(word -> Tuple2.of(word, 1L))
.returns(Types.TUPLE(Types.STRING, Types.LONG));
// 4. 分组
KeyedStream<Tuple2<String, Long>, String> wordAndOneKS = wordAndOne.keyBy(t -> t.f0);
// 5. 求和
SingleOutputStreamOperator<Tuple2<String, Long>> sumResult = wordAndOneKS.sum(1);
// 6. 打印
sumResult.print();
// 7. 启动任务
env.execute();
}
}
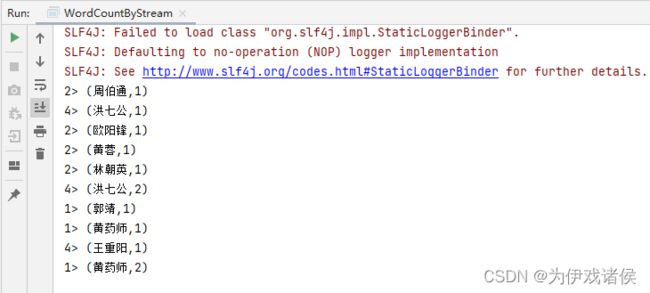
程序运行结果如下:
2.6 Socket流处理WordCount
- shell窗口中创建socket端口,命令如下
nc -lk 18888
- socket端口中输入测试数据,截图如下:
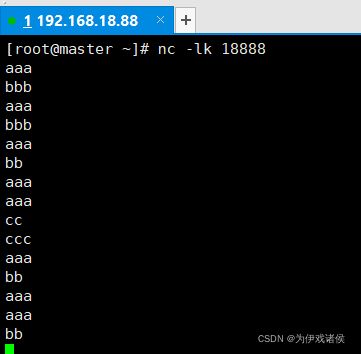
- 编写 WordCountBySocketStream.java 文件,代码如下:
package cn.mfox;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
/**
* 基于socket流计算的wordcount案例
*
* @author hy
* @version 1.0
* @date 2022/3/25 14:52
*/
public class WordCountBySocketStream {
public static void main(String[] args) throws Exception {
// 1. 创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 获取ParameterTool
ParameterTool parameterTool = ParameterTool.fromArgs(args);
String host = parameterTool.get("host");
int port = parameterTool.getInt("port");
// 3. 从socket文本流读取数据
DataStream<String> inputDataStream = env.socketTextStream(host, port);
// 4. 转换计算
SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOne = inputDataStream
.flatMap((String line, Collector<String> words) -> {
// 分割及排空
Arrays.stream(line.split(" "))
.map(word -> word.trim())
.filter(word -> !word.isEmpty())
.forEach(words::collect);
}).returns(Types.STRING)
.map(word -> Tuple2.of(word, 1L))
.returns(Types.TUPLE(Types.STRING, Types.LONG));
// 5. 分组
KeyedStream<Tuple2<String, Long>, String> wordAndOneKS = wordAndOne.keyBy(t -> t.f0);
// 6. 求和
SingleOutputStreamOperator<Tuple2<String, Long>> sumResult = wordAndOneKS.sum(1);
// 7. 打印
sumResult.print();
// 8. 启动任务
env.execute();
}
}
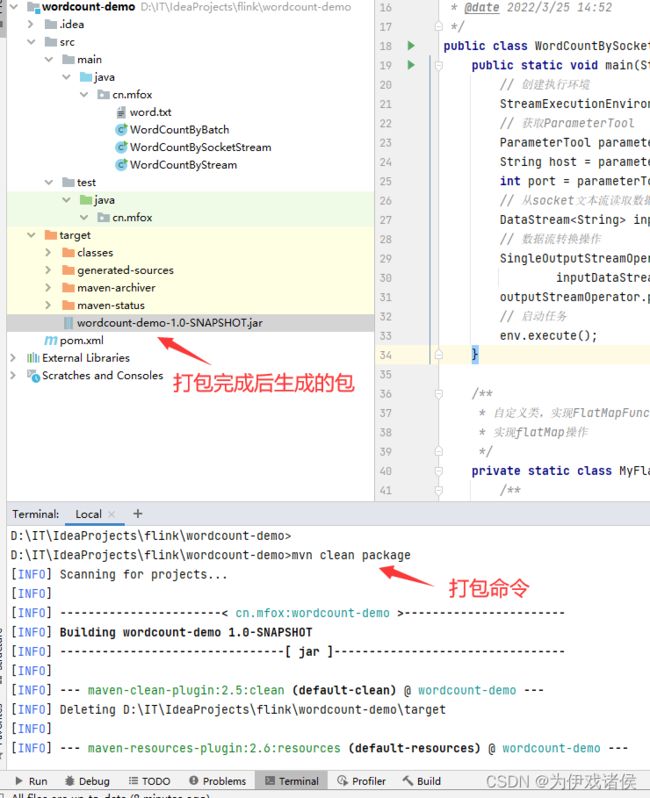
- 在当前工程目录下执行maven打包命令
mvn clean package
流程截图如下:
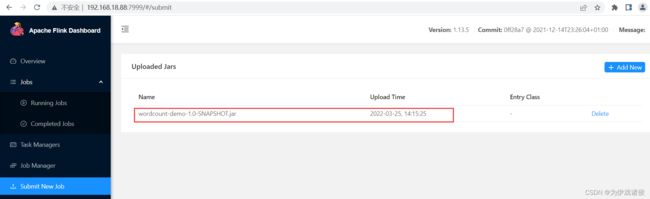
- 在Flink的Web界面(Submit New Job)菜单中上传Jar包,上传成功后的截图如下:
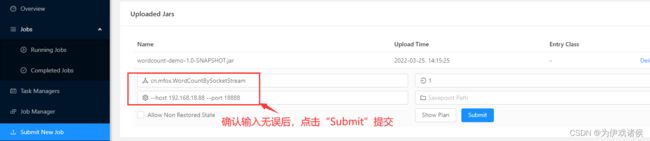
- 界面点击刚上传的jar包,输入要运行的类、socket的地址、端口,输入的内容如下:
cn.mfox.WordCountBySocketStream
--host 192.168.18.88 --port 18888
截图如下:
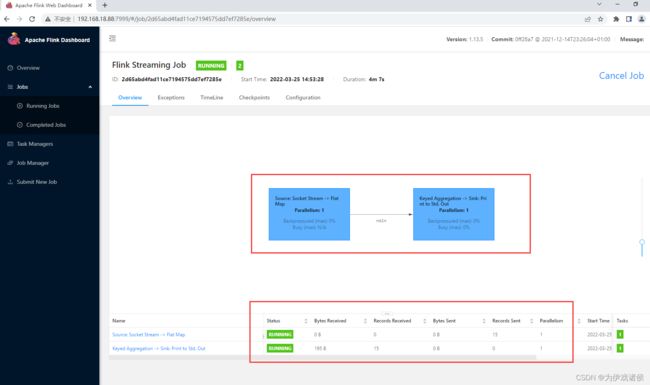
- 在Running Jobs菜单中可查看刚提交的Flink程序的执行情况,如各个算子的并行度,接受数据的条数大小等,截图如下:
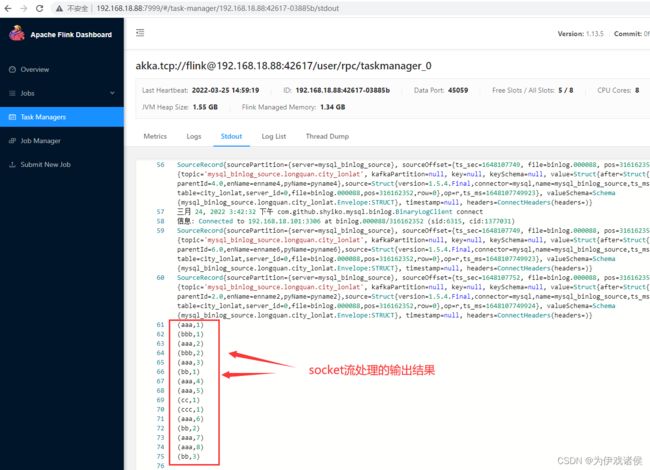
- 在Task Manages菜单下可以查看Flink程序的日志输出,截图如下:
3 结束语
至此,文档篇幅结束…
因初次接触Flink及个人水平有限,如有错误,欢迎各位大佬点评 !