MySQL事务实现原理
文章目录
-
- 一、事务的概念
- 二、如何实现原子性——Undo Log
-
-
- 2.1 插入操作对应的undo log
- 2.2 删除操作对应的undo log
- 2.3 更新操作对应的undo log
-
- 三、如何实现隔离性——MVCC和锁
- 四、如何实现持久性——Redo Log和Binlog
-
- 4.1 Redo Log
- 4.2 Binary Log
- 4.3 数据恢复
- 五、总结
一、事务的概念
事务是数据库操作的基本执行单元 ,一个事务可以包含一条或者多条SQL语句,执行一个事务时,所包含的所有SQL操作要么全部执行,要么全部都不执行,这就是事务的目的所在。因此事务是数据库是区别于普通文件系统的重要特性。
标准的事务是需要满足ACID的理论要求的:
- A(Atomicity) 原子性:指事务是不可分割的执行单元,事务中的所有操作要么全都成功,要么全都失败。
- C(Consistency)一致性:指数据必须保证从一种一致性的状态转换为另一种一致性状态。事务前后数据库的完整性约束没有被破坏。
- I(Isolation)隔离性:指事务内部的操作和其他事务之间是隔离的, 不能互相干扰。事务提交之前对其他事务不可见。
- D(Durability)持久性:指事务一旦提交,它对数据库的改变就是永久性的,接下来的其他操作或故障不能对其有任何影响。
其中一致性是事务追求的最终目标,只有在保证原子性、隔离性和持久性的基础上,才能实现数据库的一致性,也就是说前三者是一致性状态的必要条件。
下面我们分别看下MySQL InnoDB是怎么实现原子性、隔离性和持久性的。
二、如何实现原子性——Undo Log
An undo log is a collection of undo log records associated with a single read-write transaction. An undo log record contains information about how to undo the latest change by a transaction to a clustered index record. If another transaction needs to see the original data as part of a consistent read operation, the unmodified data is retrieved from undo log records.
undo log是与单个读写事务相关联的撤消日志记录的集合。undo log记录可以明确如何撤消事务对聚集索引记录的最新更改。如果另一个事务需要通过一致性读取操作查看原始数据,可以从undo log记录中查询未修改前的数据。
设计undo log的目的就是为了能回滚事务,把记录还原成事务未开始之前的状态。数据每进行一次增删改,就会对应一条或多条undo log。
redo log存放在单独的redo日志文件上,而undo log是存放在undo段中(undo segment),位于共享表空间。
需要特别注意的一点是:undo log只是逻辑日志,并不能将数据库物理地恢复到事务之前的状态。原因很简单:因为数据是按页为单位存放的,可能会出现多个事务并发对同一个页上的不同记录进行修改,甚至会出现页分裂,如果直接将页记录物理地恢复,会影响到其他事务。所以undo log只能从逻辑上恢复记录,比如:
- 对于每个insert操作,回滚时会执行delete操作;
- 对于每个delete操作,回滚时会执行insert操作;
- 对于每个update操作,回滚时会执行一个相反的update操作,把数据还原。
2.1 插入操作对应的undo log
TRX_UNDO_INSERT_REC:是插入操作对应的undo log类型,因为插入操作对应的撤销逻辑是删除,所以只需要把这条记录的主键id记录下来。
2.2 删除操作对应的undo log
由于MVCC的存在,被删除的记录并不会被真正的删除, 而是进行delete mark操作——只是将行记录上的删除标记位delete_flag改为1,后面在再通过purge操作把记录加入垃圾链表中,待后续进行空间复用。生成删除语句对应的undo log类型为TRX_UNDO_DELETE_MARK_REC,相比于TRX_UNDO_INSERT_REC,TRX_UNDO_DELETE_MARK_REC不仅保存了主键id,也保存了相关的索引列信息,用来对删除过程中一些中间状态的清理。
2.3 更新操作对应的undo log
更新操作对应的undo log除了会记录主键和索引列信息之外,还会把被更新前各个字段的信息记录下来,还有指向旧记录的DB_ROLL_PTR和DB_TRX_ID。
- 不更新主键,且被更新的列存储空间不发生变化:直接在原有行记录上面更新。
- 不更新主键,且被更新的列存储空间发生了变化:先删除旧记录(不是delete mark,而是直接删除),再插入新记录。
- 更新主键:旧记录进行delete mark,再插入新记录。
- 过程中更新了二级索引:对旧的二级索引进行delete mark,插入新的二级索引记录。
通过以上3种不同操作对应的undo log,可以逻辑地将数据恢复到事务开始前的状态。
三、如何实现隔离性——MVCC和锁
事务隔离性主要描述的是多个事务并发访问数据库记录时不互相影响。
数据库厂商出于对数据一致性和并发性能等其他需求的综合考虑,并没有完全严格遵守【ACID】中 I 隔离性的严格标准。MySQL InnoDB提供了四种隔离级别:
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| READ UNCOMMITTED(读未提交) | 可能 | 可能 | 可能 |
| READ COMMITTED(读已提交) | 不可能 | 可能 | 可能 |
| REPEATABLE READ(可重复读) | 不可能 | 不可能 | 基本不可能 |
| SERIALIZABLE(可串行化) | 不可能 | 不可能 | 不可能 |
我们知道并发访问相同的记录会有以下3种情况:
- 读-读并发:多个事务同时读取相同的数据,由于没有对记录有任何改动,读到的数据都是同一份,所以是允许发生的。
- 写-写并发:多个事务并发修改相同的数据时,防止数据丢失,必须进行加锁排队等待。也就是利用锁来保证隔离性。
- 读-写并发:多个事务并发对相同数据修改和读取的时候,就会出现读写冲突,这个场景是事务隔离性重点关注解决的。
针对于读写并发场景的事务隔离性,MySQL InnoDB给出的解决方案是:
- 针对写事务和快照读事务并发场景,InnoDB使用了MVCC的机制实现了RR和RC隔离级别。(关于MVCC的机制可以参考另外一篇博文《MySQL MVCC原理深入探索》)
- 针对于写事务和锁定读(当前读)事务并发场景,InnoDB通过了行锁,以Next-Key Locks为基本加锁单位,其中包含的Record Locks记录锁和Gap Locks间隙锁实现事务隔离性。(关于锁机制可以参考另外一篇博文《MySQL&InnoDB锁机制全面解析》)
四、如何实现持久性——Redo Log和Binlog
InnoDB存储引擎是按页为单位管理数据存储空间的,正常的数据增删改查操作都是对页进行访问。在访问页面前,需要把磁盘中的页加载到内存中的Buffer Pool里面,修改后再以同步或者异步的方式更新回磁盘文件。
如果只在Buffer Pool中修改了数据,事务提交后发生故障,这个时候数据还没能写回磁盘,那么数据就存在丢失的问题。
针对这种情况,我们可以采取:
方案一:事务提交完成前,把修改的数据都刷新回磁盘。
但是一般情况下都不会使用这种方案,因为会存在比较大的问题:
- 磁盘中数据是按页为单位操作的,每次提交一个事务就需要把整个页进行刷新,资源浪费,效率低。
- 事务可能改动多个页面,不是连续的,随机IO更新,性能差。
所以,InnoDB使用了redo log日志文件来对数据改动进行记录。
4.1 Redo Log
The redo log is a disk-based data structure used during crash recovery to correct data written by incomplete transactions. During normal operations, the redo log encodes requests to change table data that result from SQL statements or low-level API calls. Modifications that did not finish updating the data files before an unexpected shutdown are replayed automatically during initialization, and before connections are accepted.
redo log是一种基于磁盘的数据结构,用于在崩溃恢复期间纠正不完整事务写入的数据。在正常运行时,redo log会对由SQL 语句或底层API调用对表数据产生的更改进行记录。如果数据库意外关闭前有没能完成数据文件的修改。会在重启初始化期间,未接受连接之前自动进行数据修正。
在每次进行事务提交时,只需要把对数据页的修改内容记录到redo log,比如对xx号表空间第xx页中偏移量为xx的值改为xx。事务提交时将数据更新到redo log磁盘日志文件中。那么即使系统崩溃重启了,该事务的修改也依然可以重新执行恢复。
采用redo log的方案相对于方案一有以下优势:
- 日志空间存储占有小,只记录了改动的地方。
- 日志是顺序写入的,使用顺序IO性能高。
通过系统崩溃重启后的redo log日志重放操作,理论上就已经可以保证把事务对数据做的任何修改恢复。那和binlog有什么关系呢?
下面我们介绍一下binlog。
4.2 Binary Log
The binary log contains “events” that describe database changes such as table creation operations or changes to table data. It also contains events for statements that potentially could have made changes (for example, a DELETE which matched no rows), unless row-based logging is used. The binary log also contains information about how long each statement took that updated data. The binary log has two important purposes:
- For replication, the binary log on a replication source server provides a record of the data changes to be sent to replicas. The source sends the events contained in its binary log to its replicas, which execute those events to make the same data changes that were made on the source.
- Certain data recovery operations require use of the binary log. After a backup has been restored, the events in the binary log that were recorded after the backup was made are re-executed. These events bring databases up to date from the point of the backup.
binlog 包含描述数据库更改的“事件”,例如表创建操作或表数据的更改。它还包含可能进行更改的语句的事件(例如, 一条不匹配任何行的 DELETE 语句),除非使用基于行的日志记录。binlog 还包含有关每个语句花费多长时间更新数据的信息。binlog 有两个重要目的:- 为了主从复制,复制服务器上的 binlog 提供了要发送到副本的数据更改记录。源服务器将其 binlog 中包含的事件发送到其副本,副本执行这些事件以进行与源服务器相同的数据更改。
- 某些数据恢复操作需要使用 binlog 。恢复备份后,将重新执行备份后记录的 binlog 中的事件。这些事件使数据库从备份点开始更新。
也就是说,binlog 主要有两个目的:主从复制和数据备份。主从复制是通过将主库的binlog发送到从库执行,从而保证主从数据的一致性。
使用 redo log 进行数据恢复时,可以保证主库上数据的完整持久化,但是对于从库,则仍需要 binlog 配合,才能保证系统崩溃恢复后主从数据的一致性。
redo log 和 binlog 有以下区别:
- redo log 是 InnoDB 引擎所独有的;binlog 则是 MySQL Server 层实现的,所有引擎都可以使用。
- redo log 是物理日志,记录的是“在某个数据页上做了什么修改”;binlog 是逻辑日志,记录的是这个语句的原始逻辑,比如“给 ID=1 这一行的 a 字段加 1 ”。
- redo log 是循环写的,空间固定用完会覆盖从头继续;binlog 是可以追加写入的,写到一定大小后会切换到下一个,不会覆盖原来的日志。
一条简单的更新语句:update t set field_name=“new” where id=1 在MySQL中的执行流程:
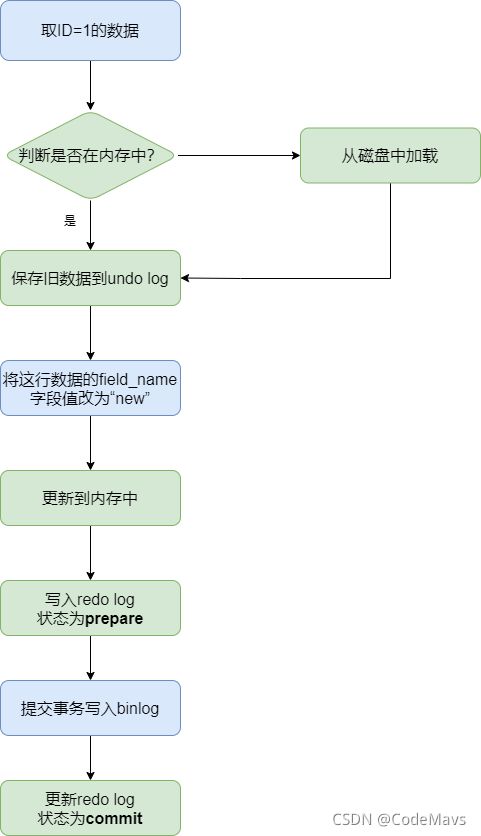
- 从内存中找出id=1这条记录的数据页,如果没有则从磁盘读取到内存,
- 根据原始版本数据生成undo log记录;
- 对内存中该页的数据进行更新;
- 将对数据页的修改记录到内存redo log buffer,状态为prepare;
- 事务提交时将语句的逻辑操作记录到内存binlog cache;
- 将redo log状态该为commit;
- 内存中的数据和日志,通过不同的落盘规则刷新到磁盘;
由于写 redo log 和写 binlog 是两个独立的非原子操作,不管是先写 redo log 还是先写 binlog 都不能保证数据的一致性,所以需要使用两阶段提交,利用各自的状态位来校验整个流程是否已完成。
注意:由于两个阶段的操作是非原子操作,所以要保证多个事务并发时的数据一致性,需要加锁。MySQL5.6之后引入了组提交的方式,将不同阶段的锁粒度拆分的更细,同时使用批量刷盘机制,极大地降低磁盘的IO消耗。感兴趣可以自行了解。
4.3 数据恢复
下面我们看看系统崩溃重启后是如何通过 redo log 和 binlog 来保证数据持久性的。
- 1.当 redo log 处于 prepare 阶段前系统发生崩溃:此时不会有任何影响。
- 2.当 redo log 处于 prepare 阶段,还没有开始写 binlog 时发生崩溃:
- 判断 redo log 是否完整的,如果不是则进行回滚;
- 如果是完整的,则进一步判断对应的事务binlog是不是完整的,如果不完整则进行回滚;
- 3.正在写 binlog 或者已经写完 binlog ,但还没有开始commit redo log时崩溃:
- 判断对应的事务binlog是否完整的,如果不完整则进行事务回滚,完整则重新commit redo log;
- 4.正在 commit redo log 或者提交完成时奔溃:
- 判断redo log和binlog的事务完整性,来决定事务回滚还是重新提交。
五、总结
MySQL通过记录undo log来保存数据的历史版本,来控制事务失败回滚,保证原子性;通过 MVCC 和锁机制来保证事务读写的隔离性、通过 redo log 和 binlog 的崩溃恢复机制来保证数据的持久性。