Flink SQL实现流批一体
1 Flink流批统一思想
1.1 有界流和无界流
在Flink中,批处理时流处理的一个特例。

1.2 Flink老架构与问题
1.从Flink用户角度(企业开发人员)
(1)开发的时候,Flink SQL支持的不好,就需要在两个底层API中进行选择,甚至维护两套代码。
(2)不同的语义、不同的connector支持、不同的错误恢复策略等。
(3)Table API也会受不同的底层API、不同的connector等问题的影响。
2.从Flink开发者角度(Flink社区人员)
(1)不同的翻译流程,不同的算子实现、不同的Task执行。
(2)代码难以复用。
(3)两条独力的技术栈需要更多人力,功能开发变慢、性能提升变难、bug变多。
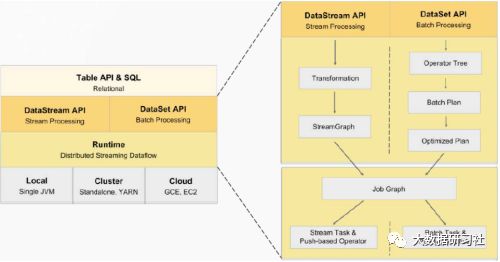
1.3 Flink流批一体新架构

2 Flink 分层API
1.API分层结构
(1)Flink1.12之前的版本,Table API和SQL处于活跃开发阶段,并没有实现流批统⼀的所有特性,所以使用的时候需要慎重。
(2)从Flink1.12开始,Table API和SQL就已经成熟了,可以在生产上放心使用。
2.Flink Table API/SQL的执行过程

3 Flink流批统一
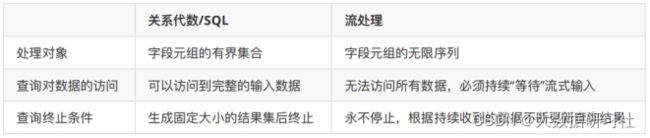
3.1 关系代数与流处理
Flink上层提供的Table API和SQL是流批统一的,即无论是流处理(无界流)还是批处理(有界流),Table API和SQL都具有相同的语意。
我们都知道SQL是为关系模型和批处理而设计,所以SQL查询在流处理上比较难以实现和理解,我们首先从流处理的几个特殊概念入手来帮助大家理解Flink是如何在流处理上执行SQL的。
关系代数(主要就是指关系型数据库中的表)和 SQL,主要就是针对批处理的,这和流处理有天生的隔阂。
3.2 理解动态表与连续查询
为了在流处理上使用关系代数(Table API/SQL),Flink引入了动态表(Dynamic Tables)的概念。
因为流处理面对的数据是无界数据流,这和我们熟悉的关系型数据库中保存的“表” 完全不同,所以一个设想就是把数据流转换成 Table,然后执行SQL操作,但是SQL的执行结果就不是一成不变的,而是随着新数据的到来不断更新的。
可以随着新数据的到来,不断在之前的结果上更新,这样得到的表,在 Flink Table API 概念里,就叫做“动态表”(Dynamic Tables)。
动态表是 Flink 对流数据的 Table API 和 SQL 支持的核心概念。与表示批处理数据的静态表不同,动态表是随时间变化的。动态表可以像静态的批处理表一样进行查询,查询一个动态表会产生持续查询(Continuous Query)。连续查询永远不会终止,并会生成另一个动态表。 查询(Query)会不断更新其动态结果表,以反映其动态输入表上的更改。

在数据流上执行关系查询时,数据流与动态表的转换关系图的主要步骤如下。
(1)将数据流转换为动态表。
(2)在动态表上进行连续查询,并生成新的动态表。
(3)生成的动态表再转换为新的数据流。
3.3 动态表详解
1.定义动态表(点击事件流)
CREATE TABLE clicks (
user VARCHAR, -- 用户名
url VARCHAR, -- 用户访问的URL
cTime TIMESTAMP(3) -- 访问时间
) WITH (...);
2.定义动态表(点击事件流)
为了执行关系查询,首先得把数据流转换为动态表。下图左侧为点击流,右侧为动态表,流上的新增事件都会对应动态表上的insert操作(除了insert还有其他模式,后面再讲)。

3.连续查询
接下来,我们在动态表上执行连续查询生成一个新的动态表(结果表),连续查询不会停止,它会根据输入表新数据的到来不断查询计算并更新结果表(多种模式,后面讲)。我们在click动态表上执行了group by count聚合查询,随着时间推移,右边动态结果表随着左测输⼊表每条数据的变化⽽变化。

我们在click动态表上执行了group by count聚合,另外还加入了一个翻滚窗口,统计1小时翻滚窗口内每个用户的访问次数。随着时间推移,右边动态结果表随着左测输入表数据的变化而变化,但是每个窗口的结果是独立的,且计算是在每个窗口结束时才触发的。

3.4 动态表转为数据流
与常规的数据库表一样,动态表可以通过插入(Insert)、更新(Update)和删除(Delete) 更改,进行持续的修改。将动态表转换为流或将其写入外部系统时,需要对这些更改进行编码。Flink 的 Table API 和 SQL 支持三种方式对动态表的更改进行编码。
1.仅追加流(Append-only stream,即insert-only)
仅通过插入INSERT更改来修改的动态表,可以直接转换为“仅追加”流。这个流中发出的数据就是动态表中新增的每一个事件。
2.撤回流(Retract stream)
插入、更新、删除都支持的动态表会转换为撤回流。
撤回流包含两类消息:添加(Add)消息和撤回(Retract)消息。
动态表通过将 INSERT 编码为 add 消息、DELETE 编码为 retract 消息、UPDATE 编码为被更改行(更改前)的retract 消息和更新后行(新行)的 add 消息,转换为 retract 流。
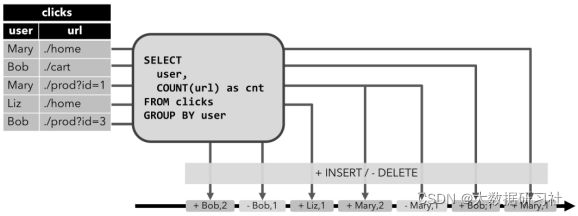
3.更新插入流(Upsert流)
Upsert 流包含两种类型的消息:Upsert 消息和 delete 消息。转换为 upsert 流的动态表, 需要有唯一的键(key)。通过将 INSERT 和 UPDATE 更改编码为 upsert 消息,将 DELETE 更改编码为 DELETE 消息, 就可以将具有唯一键(Unique Key)的动态表转换为流。

4.查询限制
对无界数据流进行连续的查询会有一些限制,主要是如下两个方面:
(1)状态大小限制
无界数据流上的连续查询需要运行数周或者数月甚至更长,因此,连续查询处理的数据量可能会很大。例如,前面计算用户访问量的例子中,需要维护用户访问量的计数状态,如果只考虑已注册用户则状态不会太大,如果为每个非注册用户分配唯一的用户名,则需要维护非常大的状态,随着时间推移就可能导致查询失败。
SELECT user, COUNT(url)
FROM clicks
GROUP BY user;
(2)计算更新成本限制
某些查询即使只添加或更新了一条输入记录,也需要重新计算和更新大部分发出的结果行。 这样的查询不太适合作为连续查询执行。 例如下面那个例子,它根据最后一次点击的时间为每个用户计算一个 RANK。 一旦 clicks 表收到新用,用户的 lastAction 就会更新并计算新的排名。 但是,由于两行不能具有相同的排名,所有排名较低的行也需要更新。
SELECT user, RANK() OVER (ORDER BY lastAction)
FROM (
SELECT user, MAX(cTime) AS lastAction FROM clicks GROUP BY user
);