ray简单介绍
ray使用也有一段时间了, 这篇文章总结下ray的使用场景和用法
ray可以做什么?
总结就两点:
- 可以将其视为一个进程池(当然不仅限于此), 可以用于开发并发应用
- 还可以将应用改造为分布式
基于以上两点, 有人称之为:Modern Parallel and Distributed Python
构成
- Ray AI Runtime
用于开发分布式机器学习应用的工具包, 包括数据处理/模型训练和tuning/强化学习/部署服务… - Ray Core
用于开发/改造并发/分布式应用程序, 大部分通过装饰器形式实现. 因此如果你想改造现有应用, 基本不用怎么修改代码. - Ray Clusters
用于在云上或k8s集群上开发自动伸缩服务的分布式程序.
使用
由于笔者只使用过Ray Core功能, 因此只介绍这个模块, 其他可以参考官网ray doc
- 安装
pip install ray
- 术语
- Task: 任务实例, 通过给函数添加装饰器实现
看下例子:
import time
import ray
@ray.remote
def square(x):
time.sleep(5)
return x * x
start = time.time()
tasks = [square.remote(i) for i in range(3)]
print(ray.get(tasks))
end = time.time()
print(f'time cost:{end-start}')
输出:
[0, 1, 4]
time cost:9.302684783935547
如果顺序执行square()3次, 预计需要15s, 但是使用了@ray.remote后, 总执行时间缩减到了9s(sleep时间太短会出现改造后的执行时间反而更大的现象, 这是因为ray在启动时会先进行初始化(类似于生成进程池), 这个本身也是耗时的, 本机测试大概需要4s)
上面例子可以看出, 要将一个普通函数改造为并发非常简单, 只需要加装饰器后执行func.remote(*args, **kwargs)即可, 获取函数结果使用rag.get(), 但需要注意的是, square.remote(i)是非阻塞的, 立即返回, 而remote.ray.get()是阻塞的(有点类似multipleprocessing pool中的apply_async()), 因此在启动多个task期间, 不要去get, 否则就会退化为顺序执行.
- actor: 任务实例, 通过给类添加装饰器实现
看下例子:
@ray.remote(num_cpus=0.1)
class Counter:
def __init__(self):
self.i = 0
def get(self):
return self.i
def incr(self, value):
self.i += value
c = Counter.remote()
for _ in range(10):
c.incr.remote(1)
print(ray.get(c.get.remote()))
输出: 10
用法和上面的task差不多, 有一点小小的区别就是装饰器上加上了资源的限制@ray.remote(num_cpus=0.1), 可以为该actor分配对应限额资源, 资源数量可以为浮点数.
- objects
在ray中, 数据或者可以产生数据的对象(如上面的task和actor)称为object, 该对象一旦生成不可改变. 这么说可能有点抽象, 举个例子, 一般大型任务由多个小任务组成, 这些小任务组成了一个pipeline, 该pipeline上的所有节点都是object, 每个obect都有自己的object ref, 相当于它的id, 在集群所有node上是唯一的. 看下计算 ( ( a + b ) × 2 ) 2 ((a+b)\times2)^2 ((a+b)×2)2例子:
import ray
@ray.remote
def simple_sum(a, b):
return a + b
@ray.remote
class Mul:
def __init__(self, factor):
self.factor = factor
def process(self, x):
return x * self.factor
@ray.remote
def square(a):
return a * a
if __name__ == '__main__':
a, b = 3, 5
simple_sum_ref = simple_sum.remote(a, b)
mul = Mul.remote(2)
mul_ref = mul.process.remote(simple_sum_ref)
square_ref = square.remote(mul_ref)
print('simple_sum_ref==>', simple_sum_ref)
print('mul_ref==>', mul_ref)
print('square_ref==>', square_ref)
print('result: ', ray.get(square_ref))
输出:
simple_sum_ref==> ObjectRef(c8ef45ccd0112571ffffffffffffffffffffffff0100000001000000)
mul_ref==> ObjectRef(c2668a65bda616c17530094e1437f255eb2e95990100000001000000)
square_ref==> ObjectRef(32d950ec0ccf9d2affffffffffffffffffffffff0100000001000000)
result: 256
ray.put()
生成object有两种方式, 一种如上面例子, 调用task或者actor, 便会return回来一个object, 另外一种方式就是使用ray.put(), 看下例子:
import ray
import numpy as np
@ray.remote
def matrix_sum(x):
return np.sum(x)
if __name__ == '__main__':
a_ref = ray.put(np.array([1,2,3]))
print(f'a_ref==>{a_ref}')
print(ray.get(matrix_sum.remote(a_ref)))
输出:
a_ref==>ObjectRef(00ffffffffffffffffffffffffffffffffffffff0100000001000000)
6
有小伙伴会问, 直接把上面的numpy array传给task就行了, 为什么要多此一举, 使用put先生成object, 再传递过去呢?
这就涉及到ray的内存管理了, 如下图:
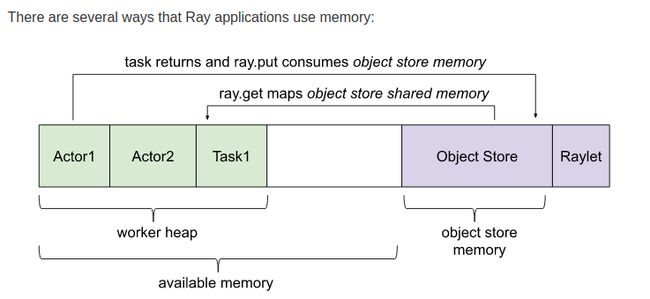 在ray中, 执行任务的实体就是actor和task, 相当于multiprocessing中的worker, 和worker类似, 每个actor或task都是一个单独进程, 他们之间是不共享内存的, 但是实际任务中少不了要交换数据怎么办?通过一块叫Object Store的区域. 这块内存区域是共享的, 是用来存储object的地方, 各个actor或task产生的obect都会放在这个区域, 如果想获取obect的value, 也是从这个区域取的结果.
在ray中, 执行任务的实体就是actor和task, 相当于multiprocessing中的worker, 和worker类似, 每个actor或task都是一个单独进程, 他们之间是不共享内存的, 但是实际任务中少不了要交换数据怎么办?通过一块叫Object Store的区域. 这块内存区域是共享的, 是用来存储object的地方, 各个actor或task产生的obect都会放在这个区域, 如果想获取obect的value, 也是从这个区域取的结果.
基于以上原因, 在某些场景, 如果为了方便共享数据, 尤其是在分布式的环境下, 如果想共享某变量, 只需要使用ray.put()将该变量转化为object, 该集群下的所有节点都可以get到该数据了.
比如我有100w张imgs, 需要在分布式的环境下分析所有imgs的数据质量(大小, 曝光等等). 可以通过将100w个imgs路径打包成一个object, ray的各个节点就可以获取到这个object, 然后每个节点各分析一部分即可.
- ray serve
如果想将自己的应用作为网络服务暴露出去的话, 就需要用到ray.serve, 下面提供一个官方提供的英文翻译为法语的例子, 在运行之前需要安装以下依赖库:
pip install "ray[serve]" transformers requests torch
服务端ray_serve_exp.py:
from transformers import pipeline
from starlette.requests import Request
from ray import serve
@serve.deployment(num_replicas=2, ray_actor_options={'num_cpus': 0.2})
class Translator:
def __init__(self):
self.model = pipeline('translation_en_to_fr', model='t5-small')
def translate(self, text:str):
model_output = self.model(text)
translation = model_output[0]["translation_text"]
return translation
async def __call__(self, http_request: Request):
englist_text = await http_request.json()
return self.translate(englist_text)
translator = Translator.bind()
运行服务端: serve run ray_serve_exp:translator
客户端model_client.py:
import requests
english_text = "Hello world!"
response = requests.post("http://127.0.0.1:8000/", json=english_text)
french_text = response.text
print(french_text)
运行客户端: python model_client.py
输出:
Bonjour monde!