「万物生长」一个APK从诞生到活跃在Android手机上,android驱动开发权威指南pdf
可能到这里你还没有感觉,但如果看了这张图呢?
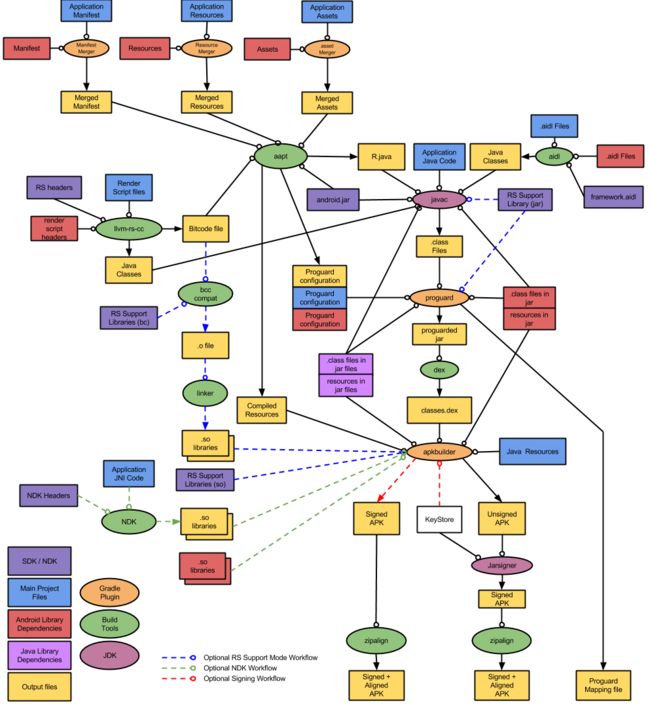
是否能切实的感受到Gradle所提供的强大能力了,因为对我们我们开发者而言其实只干了一件运行按钮的触发操作,但是背后Gradle给我们所带来的收益是无穷无尽的。
在这里我们知道他很有用了,但是为什么还要提一下他的兄弟Maven呢?主要是为了让你转化手头的构建工具,根据官网的构建速度对比。
具体请参考文档Gradle vs Maven:性能比较

因为公司里一般的项目都是组件化的,而且接入方会很多很多很多,所以我们拿一个大型构建的时间对比可能更服人心。对于干净的构建,Gradle的速度提高了2-3倍,对于增量更改,Gradle的速度提高了约7倍,而对Gradle任务输出进行缓存时,Gradle的速度提高了3倍。 如此之高的构建效率提升对我们开发者而言肯定也是有利有“弊”的,比如说我作为一个抖音开发者,原本抖音的构建工具使用的是Maven他的增量编译构建速度原本20分钟完成一次,那说明我现在有20分钟的摸鱼时间了,但是如果我一天要编译10次20次呢?总体这样折算下来一天的工作效率可以说骨折式缩短,可能因为编译效率过低,导致你无法按时完成需求年终奖一无所有。但是用了Gradle以后,效率翻倍,每次增量编译只用10分钟就完成了,虽然摸鱼时间短了,但是效率上来了,老板说你表现优异又给你加了3个月的奖金。
回归这个主题的内容,Gradle是怎么为我们提供能力的?
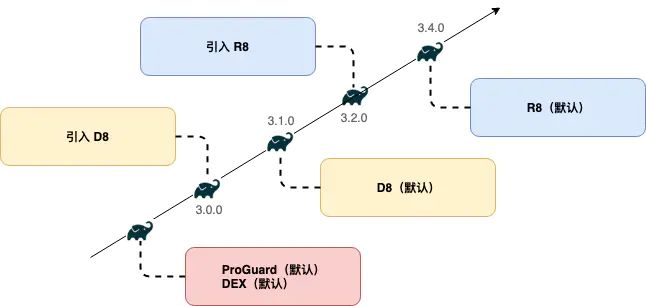
Proguard + Dex
Dex工具就是将Class文件转换成二进制这里就不做介绍
在关于proguard的内容上,对于8成的开发者阮大概最熟悉的内容就是混淆了。
Q1:混淆带给我们的好处有什么?
A1: 为什么我们要混淆?很简单,不想让第三者轻易获得我们开发的app源码,那他的第一个优势就出来了,让代码失去直观的语义,让一部分想窃取公司机密的外部业余黑客望而却步。其实这个工具还给我们带来了第二个优势,就是代码内容缩短,在整体的包体积缩小起到了至关重要的作用。
那Proguard只有这么点作用吗??显然并不是这样的。
从图中可以得知,Proguard针对的部分是抛去系统库的,所以在混淆的图中能够发现android.support的库还是清晰的显示着,个人考虑是因为如果加上系统库进行混淆的话,可能引来奇怪的Bug。
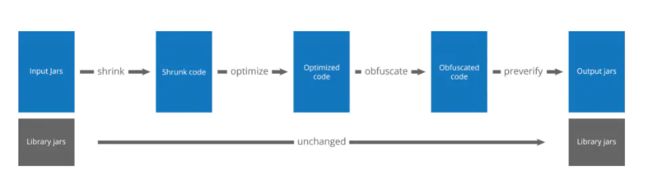
我们将整体分为4个部分:
shrink—— 代码删减optimize—— 指令优化obfuscate—— 代码混淆preverify—— 代码校验
Shrink
作为代码删减肯定是有删减的入口的。ProGuard会根据Configuration Roots开始标记, 同时根据Roots为入口开始发散。标记完成以后, 删除未被标记的类或成员。最终得到的是精简的ClassPool。
Q1:那这些Roots的来源是什么呢?
A1:Roots包括类,方法字段,方法指令, 来源主要有2种。
- 通过
keep同时allowshrinking不为true。计算class_specification中类限定和限定成员 - 通过
keepclasseswithmembers关键字allowshrinking不为true。如果类限定和成员限定都存在。计算class_specification中类限定和成员限定。
Q2:删除的是那些代码?
A2: 其实删除的内容就是在全局范围内并没有调用点并且没有用keep去保留的方法或者类。
Optimize
Optimize会在该阶段通过对 代码指令、 堆栈, 局部变量以及数据流分析。来模拟程序运行中尽可能出现的情况来优化和简化代码. 为了数据流分析的需要Optimize会多次遍历所有字节码ProGuard会开启多线程来加快速度。
具体的优化策略详见于ProGuard 初探的 Optimize 部分
Obfuscate
代码混淆想来是我们最为常见的部分了。

混淆部分一共会带来两部分的收益:
- 代码失去直观的语义(因为我们的方法或者函数命名时都会有一定的规则)
- 代码内容缩短,缩小整体的包体积
Preverify
对代码进行预校验。 主要校验StackMap / StackMapTable属性。android虚拟机字节码校验不基于StackMap /StackMapTable。
具体内容详见于 ProGuard 初探
D8
是
Dex的替代产品

这一解析器的引入非常重要的目的是为了适应Java 8上新概念Lambda。Java底层是通过invokedynamic指令来实现,由于Dalvik/ART并没有支持invokedynamic指令或者对应的替代功能。简单的来说,就是Android的dex编译器不支持invokedynamic指令,导致Android不能直接支持Java 8。
所以Android做的事情就是间接支持,将Lambda变化为可以解析的语法然后执行。

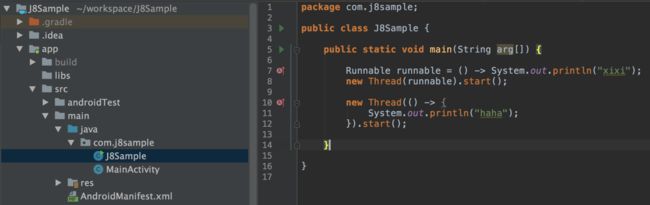
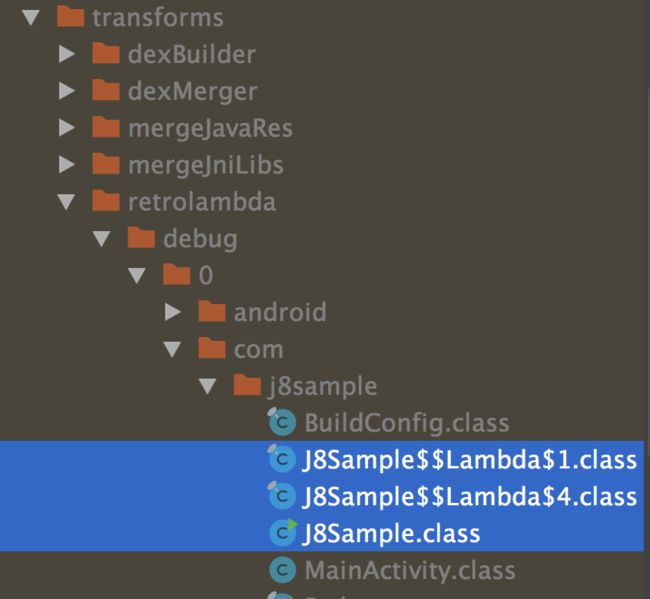
将代码编译以后,我们能够发现生成的代码中会同时生成以Lambda来标识的类,这就是说明了他的解析方案,而代码的实现方式就是我们在Java 7中常见的方案了。
不过你觉得新产品的提升会止步于此吗?
-
编译速度的提升

-
编译产生的
dex文件体积缩小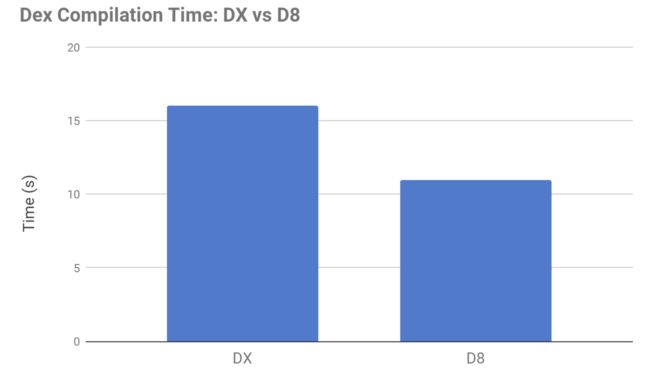
R8
是
Proguard+Dex的替代产品
R8中包含了D8+R8
R8作为Proguard的替代产品,继承了原有的功能并且做出了拓展。
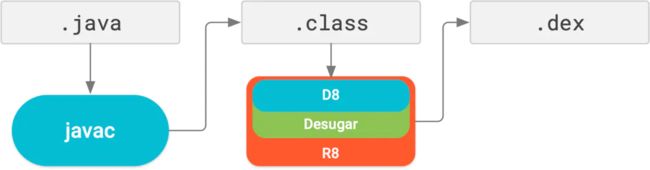
那在R8这个工具上,开发者又做出了什么样的突破呢?
从图中能够比较直观地看到,R8作为集成物,将ProGuard+Dex的能力集成,不仅在编译效率上提升,并且包大小的体积也有一定的收益
apkbuilder的话就是一个集成工具了不做讲解了
签名
为什么Android的程序需要签名呢?是否经常遇到这样的情况,同一个项目两个台机器上运行到同一部手机中,我们经常会碰到关于签名不同的报错。然后我们的做法可能就是删除,然后重新安装,这样就能解决问题了,但其实导致这个问题的原因是签名,如果两台机器使用了同样的签名,这个问题就自动解除了。
签名为我们带来了什么样的好处呢?
- 使用特殊的key签名可以获取到一些不同的权限
- 验证数据保证不被篡改,防止应用被恶意的第三方覆盖
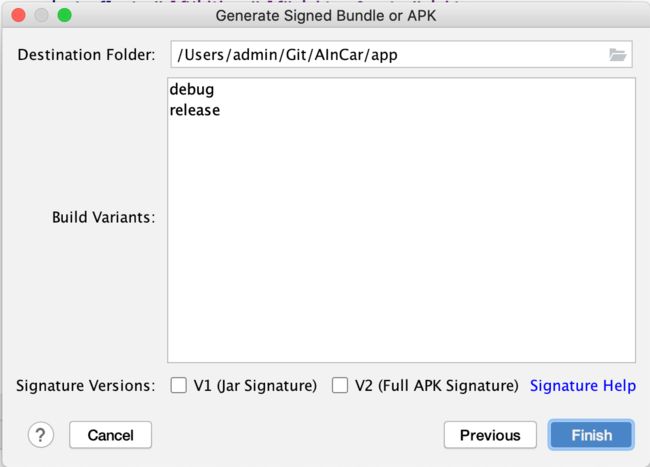
通过Android Studio的Generate Signed Bundle or APK方法可以看到上述的两种签名的方法:Jar Signature和Full APK Signature,那这两种签名方式又有什么区别呢?
Jar Signature / v1
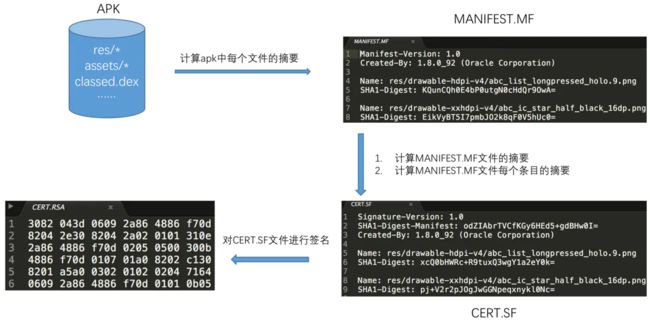
签名通过Jar Signature在APK的表现形式又是怎么样的呢](https://upload-images.jianshu.io/upload_images/24244313-66bc0461ee974372.png?imageMogr2/auto-orient/strip%7CimageView2/2/w/1240)
v1签名过程很简单,一共分为了三个部分:
- 对非目录文件以及过滤文件进行摘要,存储在
MANIFEST.MF文件中。 - 对
MANIFEST.MF文件的进行摘要以及对MANIFEST.MF文件的每个条目内容进行摘要,存储在CERT.SF文件中。 - 使用指定的私钥对
CERT.SF文件计算签名,然后将签名以及包含公钥信息的数字证书写入CERT.RSA。
从这个实现流程上其实能够明显感觉出来这个签名模式肯定是存在问题的,因为最后的签名数据相当于说向外暴露了。只要稍微注意一下数据就能够把一个APK反编译改完以后再编译回来。
Full APK Signature / v2
我们知道了Jar Signature的签名方式,那现在这个新的签名方式又是如何实现的呢?
APK签名方案v2是一种全文件签名方案,该方案能够发现对APK的受保护部分进行的所有更改,从而有助于加快验证速度并增强完整性保证。
使用APK签名方案v2进行签名时,会在APK文件中插入一个APK签名分块,该分块位于“ZIP中央目录”部分之前并紧邻该部分。在“APK签名分块”内,v2签名和签名者身份信息会存储在APK签名方案v2分块中。

APK 签名方案 v2 验证

- 找到“APK 签名分块”并验证以下内容:
- “APK 签名分块”的两个大小字段包含相同的值。
- “ZIP 中央目录结尾”紧跟在“ZIP 中央目录”记录后面。
- “ZIP 中央目录结尾”之后没有任何数据。
- 找到“APK 签名分块”中的第一个“APK 签名方案 v2 分块”。如果 v2 分块存在,则继续执行第 3 步。否则,回退至使用 v1 方案验证 APK。
- 对“APK 签名方案 v2 分块”中的每个 signer 执行以下操作:
- 从 signatures 中选择安全系数最高的受支持 signature algorithm ID。安全系数排序取决于各个实现/平台版本。
- 使用 public key 并对照 signed data 验证 signatures 中对应的 signature。(现在可以安全地解析 signed data 了。)
- 验证 digests 和 signatures 中的签名算法 ID 列表(有序列表)是否相同。(这是为了防止删除/添加签名。)
- 使用签名算法所用的同一种摘要算法计算 APK 内容的摘要。
- 验证计算出的摘要是否与 digests 中对应的 digest 一致。
- 验证 certificates 中第一个 certificate 的 SubjectPublicKeyInfo 是否与 public key 相同。
- 如果找到了至少一个 signer,并且对于每个找到的 signer,第 3 步都取得了成功,APK 验证将会成功。
那问题来了,这个这个v2的整块数据是如何计算出来的呢?
v2的详细计算过程请见于 APK 签名方案 v2 分块
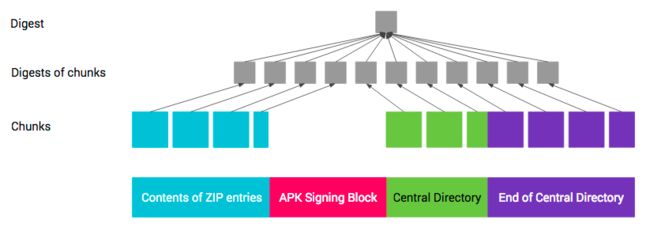
[图片上传中…(image-4a28ef-1600953978232-9)]
- 每个部分都会被拆分成多个大小为 1MB 的连续块。每个部分的最后一个块可能会短一些。
- 每个块的摘要均通过字节 0xa5 + 块的长度 + 块的内容进行计算。
- 顶级摘要通过字节 0x5a + 块数 + 块的摘要的连接进行计算。
摘要以分块方式计算,以便通过并行处理来加快计算速度。
v3(Android 9 及更高版本)
v3新版本签名中加入了证书的旋转校验,即可以在一次的升级安装中使用新的证书,新的私钥来签名APK。当然这个新的证书是需要老证书来保证的,类似一个证书链。
详细内容见于:Android P v3签名新特性
v4(Android 11)
此方案会在单独的文件 (apk-name.apk.idsig) 中生成一种新的签名,但在其他方面与 v2 和 v3 类似。没有对 APK 进行任何更改。此方案支持 ADB 增量 APK 安装。设备上安装大型(2GB 以上)APK 可能需要很长的时间,ADB(Android 调试桥)增量 APK 安装可以安装足够的 APK 以启动应用,同时在后台流式传输剩余数据,从而加快 APK 安装速度。
zipalign
zipalign是一种归档对齐工具,可对 Android 应用 (APK) 文件提供重要的优化。 其目的是要确保所有未压缩数据的开头均相对于文件开头部分执行特定的对齐。具体来说,它会使 APK 中的所有未压缩数据(例如图片或原始文件)在 4 字节边界上对齐。
使用时间点
必须在应用构建过程中的两个特定时间点之一使用 zipalign,具体在哪个时间点使用,取决于所使用的应用签名工具:
- 如果使用的是 jarsigner,则只能在为 APK 文件签名之后执行 zipalign。
- 如果使用的是 apksigner,则只能在为 APK 文件签名之前执行 zipalign。如果您在使用 apksigner 为 APK 签名之后对 APK 做出了进一步更改,签名便会失效。
自此,一个可以运行的APK就诞生了。
APK运行在Android手机上
既然我们要开始在手机上运行了,那基本还要用上adb的工具了,这里温习一个安装的命令adb install
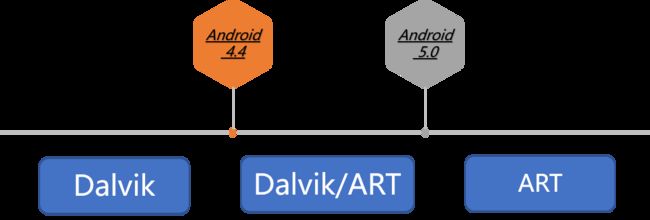
在Android里我们需要了解的的就是Dalvik和ART两个虚拟机了。
但是我们得先了解一下为什么当年在有JVM的情况下,还要自己造出一个DVM来满足需求呢?
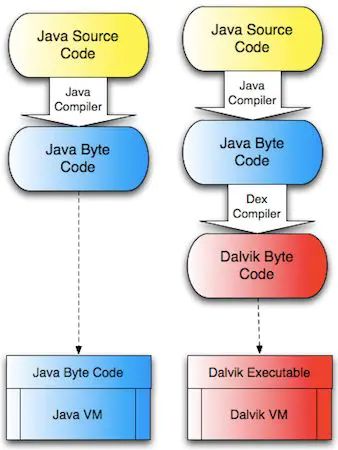
先思考一个问题,为什么Android程序明明是用Java写的,能够直接在JVM上运行,还要自己再写一个DVM呢??
可能很多文章都这样说,因为通过JVM来运行,虽然能够一份代码到处跑,但是显然从性能上跟不上直接通过寄存器来完成所有的数据操作的。但是我之前听说过一个故事,是谷歌被Oracle限制了JVM的使用 , 所以才造了一个DVM。然后效果又比用JVM好,就开始流行起来了。
那为什么JVM会比DVM运行起来慢呢?
| JVM | DVM |
|---|---|
| 基于栈开发 | 基于寄存器开发 |
| java文件 | dex文件 |
| 按需加载 | 一次性加载 |
在没有引入multiDex之前的DVM是一次性加载,可能加载速度上会比JVM慢,但是加载完毕以后,整体效率高,这基于的是几个方面:
- 按需加载,导致加载不够实时。
- 基于栈开发,对应的二进制指令更加复杂。
既然Davlik听起来已经这么好了,为什么还要再开发一套ART的虚拟机呢?
其实他的优化角度有这几个层面:
- 采用AOT(Ahead-Of-Time,预编译)编译技术,它能将Java字节码直接转换成目标机器的机器码。
- 更为高效和细粒度的垃圾回收机制(GC)。
AOT(Ahead-Of-Time,预编译)编译技术
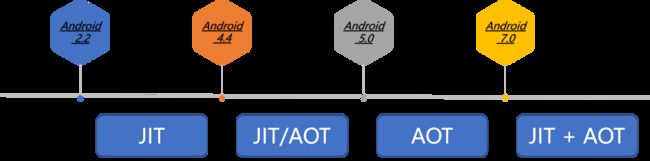
JIT(Just in Time)
运行时进行字节码到本地机器码的编译

缺点:
- 每次启动应用都需要重新编译
- 运行时比较耗电(因为经常有编译的过程)
AOT(Ahead of Time)
在应用安装时就将字节码编译成本地机器码

缺点:
- 应用安装和系统升级之后的应用优化比较耗时(重新编译,把程序代码转换成机器语言)
- 优化后的文件会占用额外的存储空间(缓存转换结果)
JIT + AOT
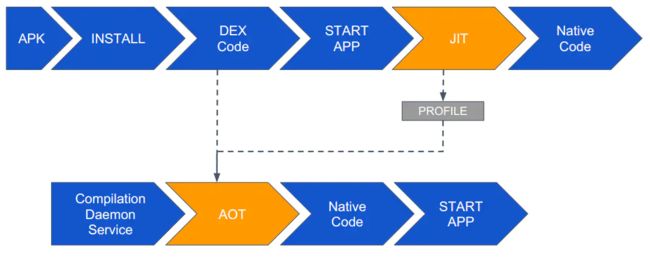
为什么要出现这样的方案呢?其实我们看不管是单纯的JIT或是AOT方案都有自己的优缺点,为什么这么说呢。
这是一个流量的时代,而一个安装包的体积大小、安装时间经常就会成为用户安装时的软肋,原因见于 App竞品技术分析 (3)减小安装包的体积。这就体现了JIT方案的优势,因为安装时没有了编译的过程,安装速度相比较而言就更快。但是运行后呢?JIT的优势就断崖式下降了,这个时候有AOT的话,能够再下一次启动时来加速我们的程序执行效率,但是AOT的触发条件是什么?
当手机长期处于空闲或者充电状态的时候,系统才会进行执行 AOT 过程进行编译,生成的机器码缓存为文件,所以说这个AOT在无人干预的情况下是一个非常不可控的过程。
更为高效和细粒度的垃圾回收机制(GC)
关于GC又可以分为这样的几个层面:
- 内存分配器
- 垃圾回收算法
- 超大对象存储空间的支持
- Moving GC策略
- GC调度策略的多样性
这里我们只对GC垃圾回收算法做一个讲解。首先我们先做一个回顾,在关于JVM,你必须知道的那些玩意儿 中我曾经提到过关于JVM内的三种垃圾回收算法,复制收集、标记清理、标记整理三种算法,但对于JVM而言是有将堆区通过自己的规则整体成一个生命周期。然后他与会有很多很多的垃圾回收器,比如说Serial收集器、ParNew收集器、G1回收器。。。。
一个非常不可控的过程。
更为高效和细粒度的垃圾回收机制(GC)
关于GC又可以分为这样的几个层面:
- 内存分配器
- 垃圾回收算法
- 超大对象存储空间的支持
- Moving GC策略
- GC调度策略的多样性
这里我们只对GC垃圾回收算法做一个讲解。首先我们先做一个回顾,在关于JVM,你必须知道的那些玩意儿 中我曾经提到过关于JVM内的三种垃圾回收算法,复制收集、标记清理、标记整理三种算法,但对于JVM而言是有将堆区通过自己的规则整体成一个生命周期。然后他与会有很多很多的垃圾回收器,比如说Serial收集器、ParNew收集器、G1回收器。。。。