python读取grib数据
python读取grib数据
windows系统下安装的Ubuntu18.04子系统,anaconda
用到的数据是ec的预报数据,第一步解压
这部分参考博客1
博客2
解压文件夹下所有文件,需要循环遍历一下,参考上面的博客2,数据多的时候很方便
#conda install bzip2 安装库
import bz2
pp = r'/mnt/f/2022/data/0601/W_NAFP_C_ECMF_20180601054641_P_C1D06010000060100001.bz2'
with open('/mnt/f/2022/data/test.grib', 'wb') as new_file, bz2.BZ2File(pp, 'rb') as file:
for data in iter(lambda: file.read(100 * 1024), b''):
new_file.write(data)
解压完毕,开始读取,走了很多弯路
第一种方法:xarray读取
安装库以及依赖库
conda install -c conda-forge xarray
conda install -c conda-forge eccodes
conda install -c conda-forge cfgrib
第一次读取
import xarray as xr
data=xr.open_dataset('/mnt/f/2022/data/test.grib',engine='cfgrib')
报错如下,跟网上的报错不一样,比如multiple values for unique key, try re-open the file with one of…
以及报错
这种报错可参考上面的链接,报错会提示,然后读取的时候加上对应的typeOfLevel,而这里我的报错并没有直接提示与typeOfLevel参数有关的信息
~/anaconda3/envs/jzy_tf2/lib/python3.6/site-packages/cfgrib/dataset.py in enforce_unique_attributes(index, attributes_keys, filter_by_keys)
267 fbk.update(filter_by_keys)
268 fbks.append(fbk)
--> 269 raise DatasetBuildError("multiple values for key %r" % key, key, fbks)
270 if values and values[0] not in ('undef', 'unknown'):
271 attributes['GRIB_' + key] = values[0]
DatasetBuildError: multiple values for key 'edition
然后各种百度,没找到我这样的报错后来又转战其他方法,兜兜转转又回来了,感觉这样的报错可能还是因为数据量太大。试过下面的pygrib之后,对数据信息有了大概了解,知道这个数据分为hybrid、surface、isobaricInhPa这三种类型
像下面这样就不会报错了
data=xr.open_dataset('/mnt/f/2022/data/test.grib',engine='cfgrib',backend_kwargs={'filter_by_keys': {'typeOfLevel': 'isobaricInhPa'}})
print(data)
读取成功,结果如下
Dimensions: (isobaricInhPa: 19, latitude: 281, longitude: 361)
Coordinates:
time datetime64[ns] ...
step timedelta64[ns] ...
* isobaricInhPa (isobaricInhPa) int64 1000 950 925 900 850 ... 70 50 20 10
* latitude (latitude) float64 60.0 59.75 59.5 59.25 ... -9.5 -9.75 -10.0
* longitude (longitude) float64 60.0 60.25 60.5 ... 149.5 149.8 150.0
valid_time datetime64[ns] ...
Data variables:
q (isobaricInhPa, latitude, longitude) float32 ...
r (isobaricInhPa, latitude, longitude) float32 ...
gh (isobaricInhPa, latitude, longitude) float32 ...
v (isobaricInhPa, latitude, longitude) float32 ...
u (isobaricInhPa, latitude, longitude) float32 ...
pv (isobaricInhPa, latitude, longitude) float32 ...
t (isobaricInhPa, latitude, longitude) float32 ...
d (isobaricInhPa, latitude, longitude) float32 ...
w (isobaricInhPa, latitude, longitude) float32 ...
Attributes:
GRIB_edition: 1
GRIB_centre: ecmf
GRIB_centreDescription: European Centre for Medium-Range Weather Forecasts
GRIB_subCentre: 0
Conventions: CF-1.7
institution: European Centre for Medium-Range Weather Forecasts
history: 2022-03-16T11:38:09 GRIB to CDM+CF via cfgrib-0....
Dimensions(维度)气压层、经度、纬度。
Coordinates(坐标)前面有星号表示可变,没有星号表示固定
Data variables(变量)包含常见的相对湿度r,风速uv等9个要素。
然后进一步提取数据经纬度层次信息,可以看到气压层有19层
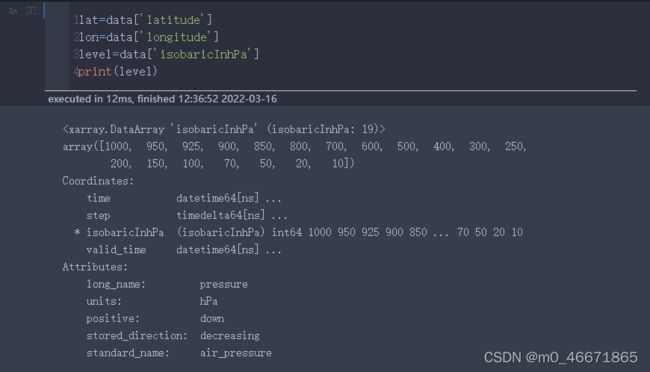
读取变量,可以看到变量完整名称long name

可以查看详细信息,可以看到相对湿度r的typeOfLevel
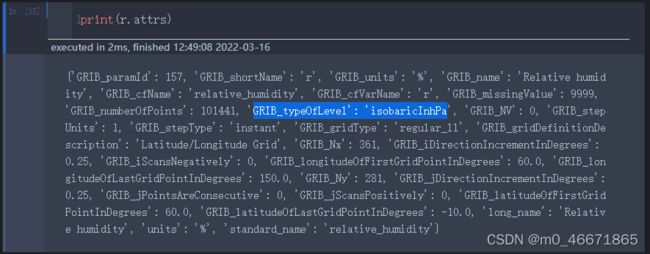
知道自己需要的变量名字及其对应的typeOfLevel,就可以直接读取
data_r = xr.open_dataset("/mnt/f/2022/data/test.grib", engine='cfgrib',\
backend_kwargs={'filter_by_keys': {'typeOfLevel': 'isobaricInhPa', "cfVarName": "r"}})
读取数据后可以位置索引
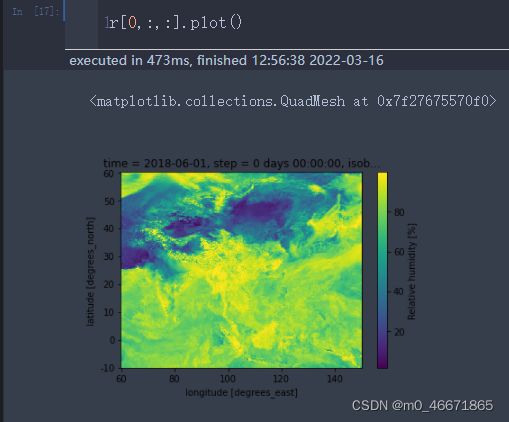
也可以.loc来索引
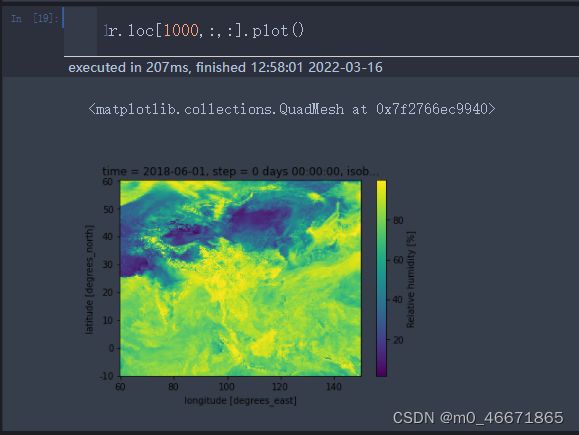
第二种方法:pygrib
conda install pygrib
import pygrib as pg
grbs = pg.open("/mnt/f/2022/data/test2.grib")#成功读取文件
#第一次读取数据时因为路径包含中文字符,所以报错了,大家注意,
#报错如下
#UnicodeEncodeError: 'ascii' codec can't encode characters in position 7-11: ordinal not in range(128)
输出变量信息
grbs.seek(0)
for grb in grbs:
print(grb)
结果如下,这个文件有601个变量。
1:Specific cloud ice water content:kg kg**-1 (instant):regular_ll:hybrid:level 133:fcst time 0 hrs:from 201806010000
......
601:Temperature:K (instant):regular_ll:isobaricInhPa:level 70:fcst time 0 hrs:from 201806010000
输出信息
数据列表行号,即第几个变量
数据名称(全称)
数据单位
regular表示常规数据
hybrid、isobaricInhPa、surface 表示数据属性,isobaricInhPa表示以hPa为单位的等压面,isobaric-等压的
level表示层次
fcst time表示预报时效
fromxxx表示从xxx起报
以上参考博客数据信息描述
也可以这样查看文件有多少数据
grbs.messages
结果如下
601
看了上面输出信息之后,对文件有了大概了解,
后来又发现如果前面安装了eccodes,就可以在终端直接查看文件信息
可参考ECMWF官方GRIB TOOLS
grib_ls -w typeOfLevel=surface test.grib
根据之前的信息大概知道文件包括hybrid,surface,isobaricInhPa三种类型,可以查看每个type下数据有多少,这个时候我就察觉到这个hybrid,surface,isobaricInhPa其实就是xarray读取数据时typeOfLevel参数,只是我用xarray读取时报错没提示这些信息。

常用isobaricInhPa数据,共计171个变量(9个要素(可看上面xarray输出信息,这里输出太长不好截屏),19层次)
grib_ls -w typeOfLevel=isobaricInhPa test.grib
......
171 of 601 messages in test.grib
综上,可以先终端或者pygrib查看一下数据大概信息,再用xarray读取,个人比较偏向xarray。所以就不继续写pygrib等。
希望对大家有所帮助。
其他方法可参考
meteva库
pygrib库
pygrib库
pyNio库,python2.7/2.8版本