时序图文献精度——7.2019-IJCAI-Spatio-Temporal Attentive RNN for Node Classification in Temporal Attributed G
Spatio-Temporal Attentive RNN for Node Classification in Temporal Attributed Graphs
1.Abstract
时间属性图中的节点分类在两个主要方面具有挑战性:
首先,有效地建模时空上下文信息是困难的。其次,由于时间维度和空间维度纠缠在一起,为了学习一个目标节点的特征表示,区分不同因素的相对重要性,如不同的邻居和时间周期的相对重要性是非常理想且具有挑战性的。
作者提出的STAR通过采样和聚合局部邻域节点来提取邻域的向量表示。它进一步将邻域表示和节点属性输入到一个门控递归单元网络中,以共同学习时空上下文信息。在此基础上,我们利用双重注意机制对模型的可解释性进行了全面的分析。在真实数据集上的大量实验证明了STAR模型的有效性。
2.Introduction
节点分类方法的目的是根据图的拓扑结构和节点属性将节点分为不同的类别。
作者介绍了部分节点分类的相关工作,从静态图到动态图的各个工作。
但是作者发现,现有的动态图上的节点分类的相关工作目前只考虑了图的拓扑结构的动态变化,然而,绝大多数的真实网络都带有一组丰富的顶点属性,这些属性也会随着时间的推移而发展。由于时间维度和空间维度的纠缠,需要设计一种有效的方法,对图拓扑和节点属性的时空上下文信息进行联合建模,同时为分类结果提供模型可解释性。
对于动态图的节点分类来说,由于图拓扑和节点属性都会随时间变化,所以会面临一下两个挑战:
首先,有效地建模时空上下文信息是困难的。对于时间属性图,演化在于图的拓扑结构和节点属性。随着时间的变化,时间维度和空间维度被纠缠在一起。如何同时联合学习时空两方面的节点表示是一项挑战。其次,区分影响节点表示的不同因素的相对重要性以进行有效分类也具有挑战性。不同时间段的不同邻居会对节点的表示产生不同的影响。因此作者认为,我们需要识别出哪些邻居在哪个时间段对目标节点的表示学习有更大的影响。
为了解决上述两个挑战,作者提出了STAR模型(如下图1所示),STAR的目的是通过联合考虑节点的时间和空间模式来学习节点的分类表示。具体来说,STAR将局部邻居节点的采样和聚合嵌入到一个门控循环单元(GRU)网络中,以联合学习时空上下文信息。通过将不同时间段的顺序节点属性输入GRU网络,可以有效地提取属性演化的时间特征。除此之外,作者建立了一种时间和空间方面的双重注意机制,选择性地聚集不同的时间段和不同的邻居,有助于对模型的可解释性进行全面的分析。

2.Problem
时间属性图是一个属性图在不同时间步长下的快照的集合,用G =(G1、G2、···、GT)表示。Gt =(V,At,Xt)是时间步长t时的图。节点V的集合对于所有的时间步长都是固定的。每个节点在T个时间步长上都有其一致的标签。At∈RN×N为邻接矩阵,Xt∈RN×d是节点属性矩阵。At和xt在不同的时间步长上都是不同的。给定G和节点VL的一个子集的标签,时间属性图中的节点分类的目标是对标签未知的子集VU中的节点进行分类,其中V = VL∪VU。
3.Spatio-Temporal Attentive RNN
3.1 Gated Recurrent Unit
GRU网络是捕获序列数据时间模式的有效方法。关于GRU的详细信息,见博客GRU单元
3.2 Vector Representation of The Neighborhood
我们在每个时间步长为每个节点提取一个邻域向量来表示其邻域信息。关键思想是聚合邻居的表示。我们将考虑k跳的邻居。
首先,我们准备好k跳的邻居。给定一组要分类的节点B,我们对B中节点的近邻进行采样。这些采样的邻居和B中的节点一起形成一个新的集合B1。我们对B1做同样的事情,然后得到另一个新的集合B2。因此,我们可以得到一个用B0、B1… Bk表示的集合序列。其中B0=B,通过采样函数N(·)进行采样。该过程在算法1中进行描述。

然后,基于节点集的序列,生成B中所有节点的邻域向量,在算法2中描述,其中gkt (v)是节点v在时间步t聚合其k跳邻居后的表示。其关键思想是应用聚合器AGGk(·)来聚合邻居的表示法(第5行),并将聚合器与之连接起来。

3.3 Spatio-Temporal GRU
ST-GRU有两个优点:状态向量显式地包含了节点属性的时间信息和在邻域中编码的空间信息。并在时间和空间两方面进一步实施双重注意机制。
ST-GRU在方程式(5)-(9).中被描述。给定一个节点属性序列x1,…,xT∈Rd和一个邻域向量序列e1,…,eT∈R dg,通过应用以下方程迭代计算每个时间步长的状态向量h’t∈R dh,其中h‘0 = 0。
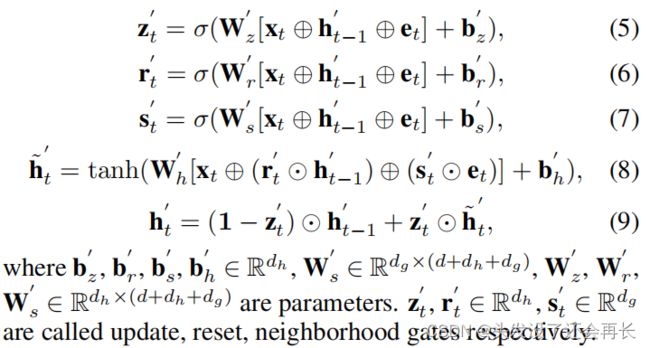
3.4 Dual Attention Mechanism
Spatial Attention
不同的邻居对节点表示的影响也有所不同,注意技术能够自适应地捕获相关信息。
在聚合过程中,将空间注意应用于聚合器(算法2中的第5行)。基于注意值,聚合器对邻居的表示进行总结如下。
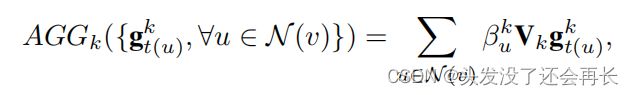
βku是位于第k跳的邻居u的注意值。它表明了u对节点v的重要性与位于第k跳的其他邻居的重要性。βku是由我们的空间注意模块产生的,该模块将节点及其邻居的表示作为输入,描述如下:
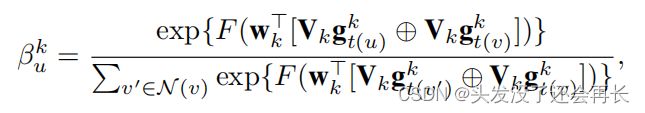
其中,F(·)是一个激活函数。wk∈R dg和Vk∈R dg×dg是参数。
Temporal Attention
对于时间属性图G =(G1、G2、...,GT),不同时间步长提供的有价值的信息量是不同的。只有一些信息包含了用于确定节点标签的最具区别性的信息。
时间注意模块以状态向量h’t作为输入,并输出一个注意值如下:

αt表示时间步长t对于确定目标节点与其他节点相比的标签的重要性。所有状态向量的连接被表示为:
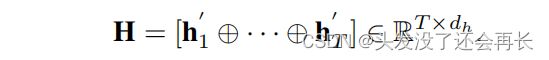
因此,所有状态向量的注意值均为
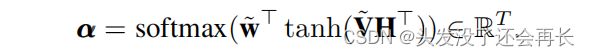
然后我们总结所有用α缩放的状态向量,生成节点的向量表示,如下所示:

一个这样的注意单元的输出通常集中在节点的时间模式的一部分上。然而,有可能是多个部分一起描述了整体模式。因此,我们需要多个注意力单元来关注不同的部分。假设有m个部分需要从输入中提取。我们使用m˜w的,并将它们连接为˜w=[˜w1⊕···⊕˜wm]。所得到的注意值矩阵为:
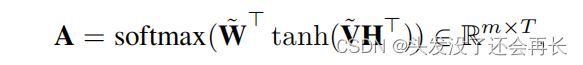
其中,softmax(·)在其输入的第二个维度上执行。最后的表示法然后表示为
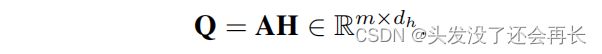
3.5 Objective Function
给定用Q1、···、QN表示的节点表示,以及节点标签y1、···、yN,其中N为节点数,STAR的目标函数为:
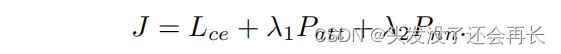
4 Experiments
4.1 Datasets and Baselines
作者使用了四个真实的数据集,如表1所示。
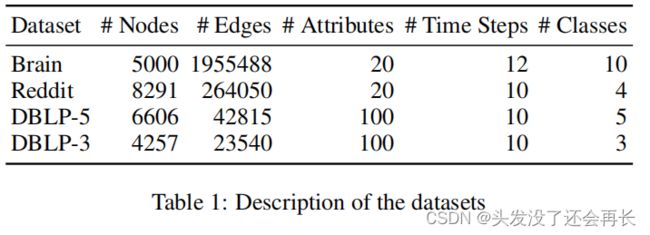
我们将STAR与最先进的基线方法进行了比较。两者之间的比较如表2所示。

4.2 Experimental Results
Node classification
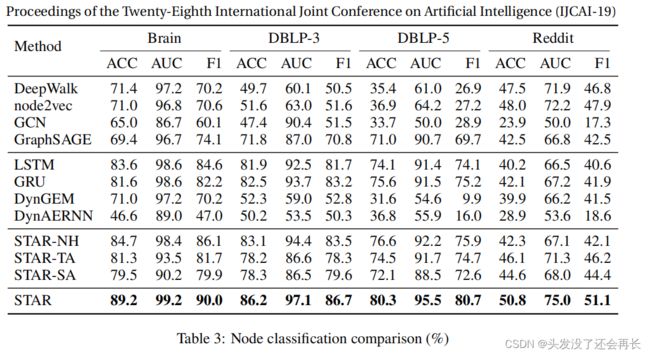
我们通过准确性、AUC和F1来评估分类结果,如表3所示。可以观察到,STAR的性能最好。
5 Related
见文献
6 Conclusion
在本文中,作者提出了一种新的方法,STAR,在时间属性图中的节点分类。STAR由一个时空GRU和一个双注意模块组成。通过将顺序节点属性和邻域表示输入GRU,可以分别有效地建模属性演化的时间特征和节点局部邻域的空间信息。本文开发了一种双重注意机制来对STAR的可解释性进行全面的分析。它还可以帮助STAR检测出对分类更重要的时间步长和节点邻居。大量的实验结果证明了STAR的有效性。