mitmproxy
我们经常了解到的抓包工具有wireshark、fiddler、charles等,mitmproxy也是一个代理工具,突出的优点是可以命令行方式或脚本的方式进行代理,可以对请求数据进行二次开发(二次定制)
官网:https://mitmproxy.org/
官方文档:https://docs.mitmproxy.org/stable/
本章的学习是参考了这篇优秀教程:使用 mitmproxy + python 做拦截代理
本文侧重点是二次定制内容
安装
mitmproxy是基于python环境进行二次定制的,我们需要先配置python环境,python环境的配置可以网上找教程,这里不细述了。
注意:最好是配置python3.8及以上的python环境,如果是以下的版本,则最好安装5.2.0版本的mitmproxy,因为其他的版本有编码问题
配置好python环境,通过pip安装mitmproxy
pip install mitmproxy
通过mitmdump --version可以查看mitmproxy是否安装成功,安装成功的话,命令打印内容如下:
Mitmproxy: 9.0.1
Python: 3.10.7
OpenSSL: OpenSSL 3.0.7 1 Nov 2022
Platform: Windows-10-10.0.19044-SP0
安装证书
现在很多请求都是https的,https的抓包需要安装证书。第一次启动mitmproxy时,就会在当前用户目录下生成.mitmproxy目录,目录存放了证书相关信息,官网对于证书的描述如下:
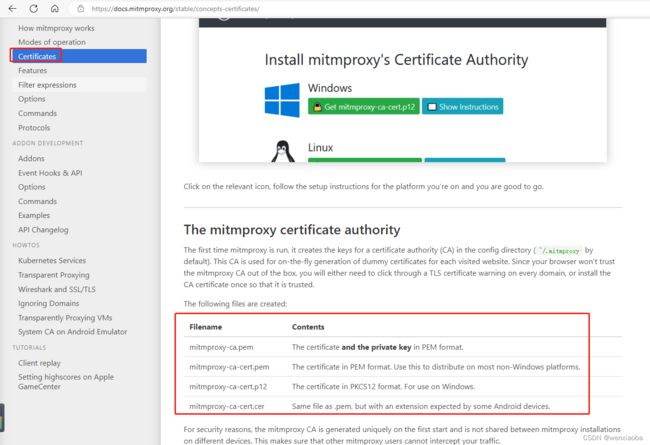
windows端
启动时是用的Administrator用户,所以我是在Administrator目录下找到.mitmproxy目录:

根据官网的描述,windows用的是mitmproxy-ca-cert.p12这个,双击完成证书安装

在这里博主遇到了一个坑,就是证书已经安装了,但是访问https还是报了有风险,可以通过netstat -ano | findstr "端口号"查看端口被占用情况,如果有多个应用占用,我们就重启mitmproxy,使用Ctrl+c停止当前的mitmproxy,然后使用mitmdump -p 新端口命令占用其他端口,再去抓包https就不会有报错了。
Android端
Android端的大部分请求都是https,如果想抓包Android的请求,需要:
- 步骤1:Android设备与mitmproxy代理在同一个局域网内,比如连接同一个wifi
- 步骤2:Android设备连接的网络设置代理,让请求通过mitmproxy代理
- 步骤3:Android设备下载证书并安装(证书安装了才支持正常进行https抓包)
Android设备设置代理
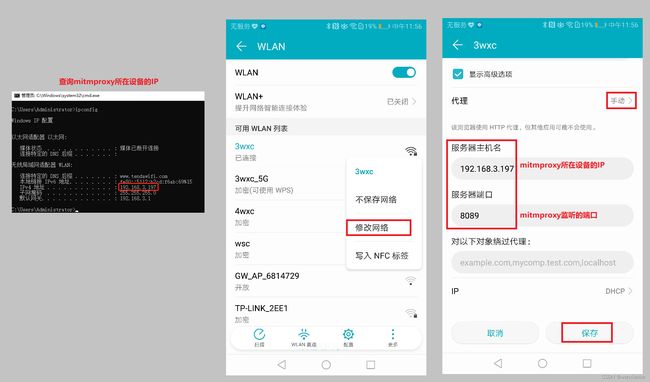
Android设备访问mitm.it网站下载证书,然后进行安装

注意:有些手机对证书做了限制,无法正常下载和安装证书,我们可以在mitmproxy所在设备中,设置浏览器通过代理,然后用浏览器访问mitm.it网站,下载对应证书,传输给手机,手机在【设置】中搜索“证书”,选择【安装证书】进行安装。
启动mitmproxy
我们可以通过mitmproxy、mitmdump、mitmweb中任意一个命令即可启动mitmproxy,这3个命令的功能是一致的,只是交互界面不太一样
如下是mitmproxy的交互界面:类似于命令行界面,实时展示抓包到的请求,能通过命令行窗口底下的提示进行请求过滤、数据查看等

mitmdump类似于linux的tail,只能默默看着数据一溜烟的更新,还不能过滤

mitmweb命令启动后,除了命令行会像mitmdump一样打印抓包到的请求外,还会自动打开一个web页面,显示抓包到的请求,在web页面,可以对请求进行过滤、查看等

mitmweb命令启动后,前2行会打印监听端口web服务端口,如上,mitmweb执行后,第一行说明mitmproxy监听了8080端口,第二行说明了可以通过 http://127.0.0.1:8081/ 打开web页面(会自动打开)

在web界面,Search是对请求数据进行过滤;Intercept对匹配的请求进行暂停操作(可),类似于fiddler或charles的断点。

我们将age编辑为233,然后点击Done按钮退出编辑状态,点击左上角的Resume进行执行生效,如下图:
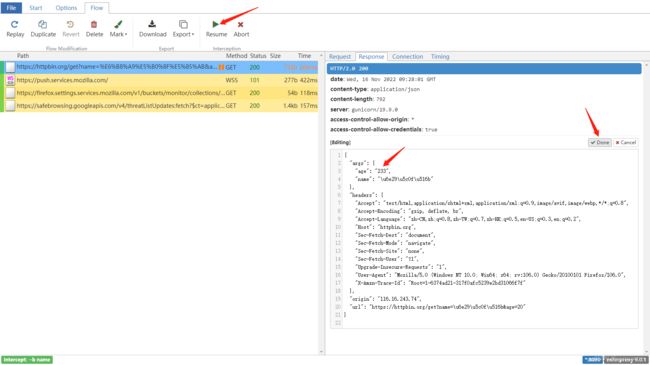
浏览器显示响应体的内容如下:
上传的是age为20,正常情况下响应体中的age应该也是20,但是因为经过了mitmproxy代理的修改,所以响应体报文中实际展示的是代理修改后的数据233。
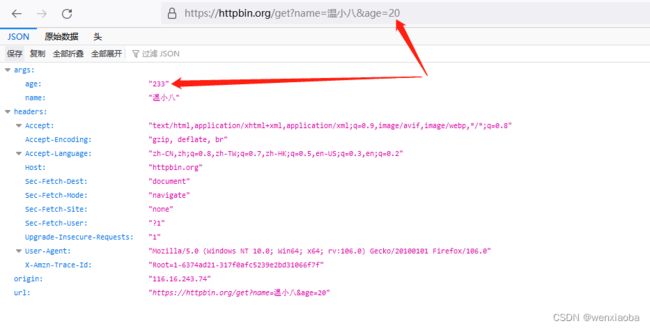
mitmproxy代理启动时,若没有指定端口的话,默认占用的是8080端口,如果想指定其他端口,则可以添加
-p 端口号指定端口,比如mitmweb -p 8089表示mitmweb方式启动mitmproxy,mitmproxy监听的端口是8089
启动参数
启动mitmproxy常用的参数有:
| 参数格式 | 说明 |
|---|---|
-p 端口号 |
指定监听端口 |
-s xxx.py |
执行指定脚本 |
-w 文件完整路径 |
指定输出文件 |
-q quiet |
仅匹配脚本过滤后的数据包(即不输出不符合脚本的请求信息) |
"~m post |
m表示method,当前表示仅匹配post请求 |
脚本定制
在教程:使用 mitmproxy + python 做拦截代理 中,有对请求的生命周期进行说明,但是我们经常用到的是如下2个:
def request(self, flow: mitmproxy.http.HTTPFlow):
def response(self, flow: mitmproxy.http.HTTPFlow):
本文主要对这2个事件进行展开。
入门
我们先简单的入门下,了解事件是怎么使用的。以下是统计http或https的请求数:
count.py内容如下:
import mitmproxy.http
class CountDemo:
# 从请求的角度来统计http请求数量,如果想从响应的角度来统计的话,可以使用response()
def request(self, flow: mitmproxy.http.HTTPFlow):
# 如果对象中已经有num属性,则num属性加1
if hasattr(self, "num"):
self.num += 1
else:
# 如果对象中没有num属性,则直接赋属性值为1
setattr(self, "num", 1)
# 显示当前请求数量
print(f"当前http/https的请求总数量为:{self.num}")
# 变量名必须为addons,列表元素必须是相关实例(即对象)
addons = [
CountDemo()
]
在count.py当前目录下,执行mitmweb -s count.py命令,刷新浏览器页面,显示如下:

request()
def request(self, flow: mitmproxy.http.HTTPFlow)
从请求数据开始处理,即请求发送到服务端前进行处理,以下是一些可能常用的属性说明:
| 属性 | 描述 |
|---|---|
request = flow.request |
获取到request对象,对象包含了诸多属性,保存了请求的信息 |
request.url |
请求的url(字符串形式),修改url并不一定会生效,因为url是整体的,包含了host、path、query,最好从分体中修改 |
request.host |
请求的域名,字符串形式 |
request.headers |
请求头,Headers形式(类似于字典) |
request.content |
请求内容(byte类型) |
request.text |
请求内容(str类型) |
request.json() |
请求内容(dict类型) |
request.data |
请求信息(包含协议、请求头、请求体、请求时间、响应时间等内容) |
request.method |
请求方式,字符串形式,如POST、GET等 |
request.scheme |
协议,字符串形式,如http、https |
request.path |
请求路径,字符串形式,即url中除了域名之外的内容 |
request.query |
url中的键值参数,MultiDictView类型的数据(类似于字典) |
request.query.keys() |
获取所有请求参数键值的键名 |
request.query.get(keyname) |
获取请求参数中参数名为keyname的参数值 |
示例:
demo.py的内容如下:
import mitmproxy.http
class Demo:
def request(self, flow: mitmproxy.http.HTTPFlow):
rq = flow.request
print("---------------开始---------------")
print(f"url:{rq.url}\n")
print(f"host:{rq.host}\n")
print(f"headers:{rq.headers}\n")
print(f"method:{rq.method}\n")
print(f"scheme:{rq.scheme}\n")
print(f"path:{rq.path}\n")
print(f"query:{rq.query}\n")
print(f"content: {rq.content}\n")
print(f"text: {rq.text}\n")
print(f"json: {rq.json()}\n")
print(f"data: {rq.data}\n")
print("---------------结束---------------")
addons = [
Demo()
]
发送一个post请求:https://postman-echo.com/post?from=en&to=zh
命令行窗口打印如下:
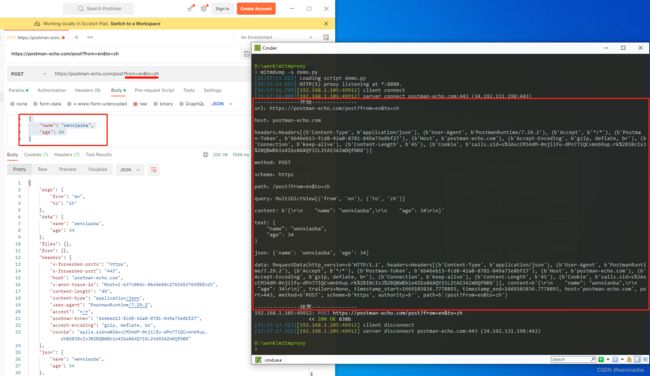
接口说明:
postman-echo.com/post接口支持任意的url参数和请求体设置,响应报文会根据上传的请求头、请求的url参数、请求体进行返回。
以下从几个示例中进行理解:
修改请求头
接口信息:
请求协议:https
域名:httpbin.org
路径:/get
参数:可以任意设置
响应数据:包含请求的请求头信息、请求参数信息和请求的其他信息
需求:修改接口的请求头内容,修改字段为:user-agent、content-type、cookie
脚本modify_headers的内容如下:
import mitmproxy.http
class ModifyDemo:
def request(self, flow: mitmproxy.http.HTTPFlow):
rq = flow.request
if "httpbin.org" in rq.url:
rq.headers["user-agent"] = "listen in mitmproxy"
rq.headers.update({
"content-type": "personal make",
"cookie": "key1=value1; key2=value2"
})
addons = [
ModifyDemo()
]
mitmweb -s modify_headers.py命令启动mitmproxy代理,并执行modify_headers.py脚本,对比未走代理和走了代理的结果如下:

重定向
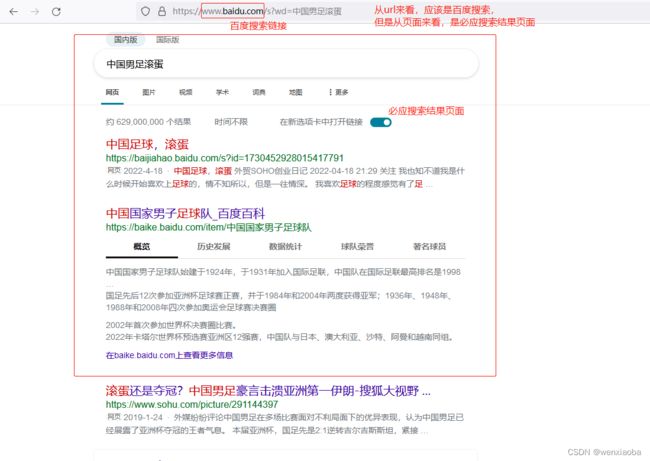
需求:在百度搜索的内容,重定向到必应搜索
脚本redirect.py的内容如下:
import mitmproxy.http
class RedirectDemo:
def request(self, flow: mitmproxy.http.HTTPFlow):
rq = flow.request
if "www.baidu.com" in rq.host and "wd=" in rq.url:
sw = rq.query.get('wd')
# 由于sw获取到的数据是ascii编码格式的内容,脚本默认的是utf-8格式的,所以url处理时需要将sw进行编码处理
rq.url = f"https://cn.bing.com/search?q={sw.encode('utf-8')}"
rq.host = "cn.bing.com"
rq.query.clear()
rq.query.update({"q": sw})
addons = [
RedirectDemo()
]
未启动代理时,百度搜索结果和必应搜索结果如下:
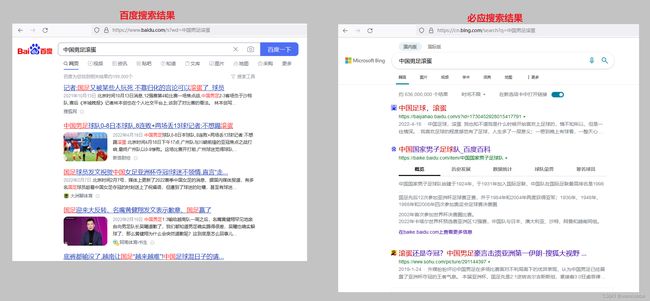
启动mitmproxy代理后,百度搜索被重定向到了必应搜索,显示了必应搜索结果页面
修改请求体内容
需求:修改postman-echo.com请求体中的年龄,给httpbin.org请求体增加gender字段
分析:我们可以从text、content、json()中获取请求体的内容,但是json()是个方法,所以无法从json()方法中进行请求体的修改,但我们可以从text和content这2个属性中进行修改
modify_req_body.py的内容如下:
# -*- coding:utf-8 -*-
# -*- coding:utf-8 -*-
import mitmproxy.http
import json
class ModifyReqBodyDemo:
def request(self, flow: mitmproxy.http.HTTPFlow):
req = flow.request
if "postman-echo.com" == req.host:
jdata = req.json()
jdata.update({"age": 26})
req.text = json.dumps(jdata)
if "httpbin.org" == req.host:
con = req.content
req.content = con.title() + ",学习进度70%".encode("utf-8")
addons = [
ModifyReqBodyDemo()
]
执行结果如下:
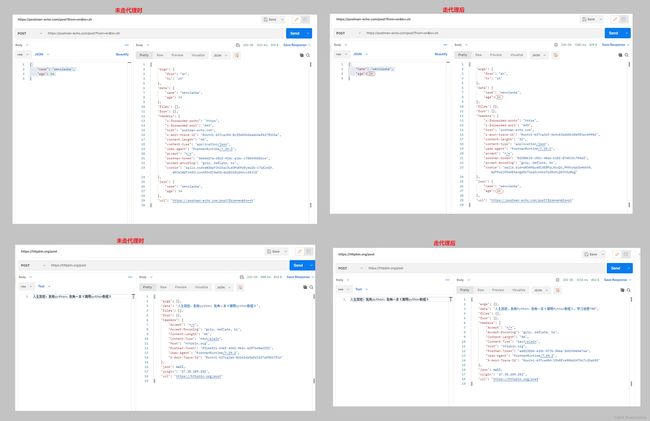
接口说明:
postman-echo.com/post和httpbin.org/post接口的逻辑是一样的,均支持任意的url参数和请求体设置,响应报文会根据上传的请求头、请求的url参数、请求体进行返回。
response()
def response(self, flow: mitmproxy.http.HTTPFlow)
从获取到请求的响应数据开始处理,即代理收到服务端返回的响应数据,但是还没将数据发送给客户端的情况下进行处理,以下是一些可能常用的属性说明:
| 属性 | 描述 |
|---|---|
response = flow.response |
获取到response对象,对象包含了诸多属性,保存了请求的响应信息 |
response.status_code |
响应码 |
response.text |
响应数据(str类型) |
response.content |
响应数据(Bytes类型) |
response.headers |
响应头,Headers形式(类似于字典) |
response.cookies |
响应的cookie |
response.set_text() |
修改 响应数据 |
response.get_text() |
响应数据(str类型) |
flow.response = flow.response.make(status_code, content, headers) |
设置响应信息 |
示例:
脚本resp_demo.py的内容如下:
import mitmproxy.http
class Demo:
def response(self, flow: mitmproxy.http.HTTPFlow):
resp = flow.response
print(f"类型:{type(resp.status_code)},内容:{resp.status_code}\n")
print(f"类型:{type(resp.text)},内容:{resp.text}\n")
print(f"类型:{type(resp.content)},内容:{resp.content}\n")
print(f"类型:{type(resp.headers)},内容:{resp.headers}\n")
print(f"类型:{type(resp.cookies)},内容:{resp.cookies}\n")
addons = [
Demo()
]
访问 https://httpbin.org/get?name=%E6%B8%A9%E5%B0%8F%E5%85%AB&age=18的情况如下:
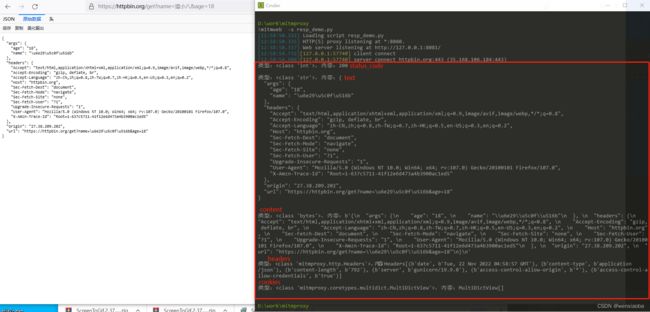
修改响应报文体
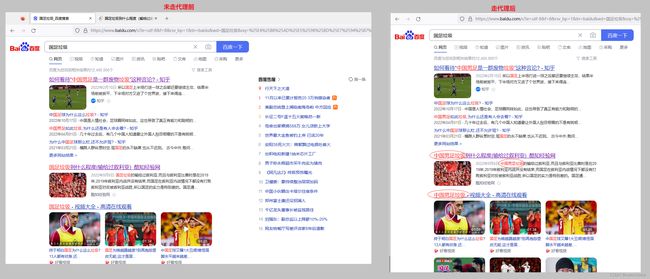
需求:将百度搜索结果中的”国足垃圾“修改成”中国男足垃圾“(女足好样的!!!)
modify_resp_body.py脚本内容如下:
import mitmproxy.http
class ModifyRespBodyDemo:
def response(self, flow: mitmproxy.http.HTTPFlow):
req = flow.request
resp = flow.response
if "baidu.com" in req.url:
t = resp.text
new = t.replace("国足垃圾", "中国男足垃圾")
resp.text = new
addons = [
ModifyRespBodyDemo()
]
代理执行前后变化如下:
修改响应状态
我们知道响应状态码是status_code字段,但是客户端并不一定是根据status_code字段值去处理响应错误的情况,flow.response提供了flow.response.make(status_code, content, headers)方法来修改响应信息
使用格式:
flow.response = flow.response.make(status_code=200, content=b"", headers=())
- status_code:响应状态码,int类型,默认为200
- content:响应报文体内容,可以传入字符串数据
- headers:响应头,可以传入字典数据

需求:如果百度搜索中包含敏感词,则返回违规说明;如果识别到是必应搜索,则直接返回404(
modify_resp_status.py脚本如下:
import mitmproxy.http
class ModifyRespStatusDemo:
def response(self, flow: mitmproxy.http.HTTPFlow):
req = flow.request
if "baidu.com" in req.host and "wd" in req.query:
if req.query.get("wd") in ["十八禁", "AV", "迷药", "杀人"]:
flow.response = flow.response.make(
status_code=400,
content="""访问违规
涉及访问不健康内容,数据已上报
哔哩哔哩
""",
headers={"content-type": "text/html"}
)
elif "cn.bing.com/" in req.host:
flow.response = flow.response.make(404)
# 以下的写法无效
# resp = flow.response
# resp = resp.make(404)
addons = [
ModifyRespStatusDemo()
]
执行结果如下: