numpy pandas读文件 numpy数值计算模块
Pandas模块
pandas模块提供了特有的文件读取函数,最常用的是处理csv文件的read_csv函数,其他还有read_table函数等。
read_csv函数
能从文件、url、文件对象中加载带有分隔符的数据,默认分隔符是逗号。常用的txt文件和csv文件都可以读取。
import pandas as pd
data1 = pd.read_csv('文件名.csv')
print(data1)
data2 = pd.read_csv('文件名.csv',sep='',encoding='utf-8')
print(data2)
写入csv文件
data1.to_csv('h1.csv')
data2.to_csv('h2.csv')
numpy存取文件
使用numpy也能非常方便的存取文件主要包括下面三组函数:
1、tofile和fromile()
存取二进制问你件
2、load() 和save()
存取numpy专用的二进制格式文件
3、savetxt() 和 loadtxt()
最为常用,可以存取文本文件,也可以访问csv文件。
格式:np.loadtxt(fname,dtype = ,comments = “#” , delimiter = None,comverters = None, skiprows = 0,usecols = None,unpack = False,ndmin = 0,encoding=‘bytes’)
常用参数解析–
fname:文件、字符串或产生器,可以是.gz 或.bz2的压缩我呢见。dtype:数据类型,可选。
delimter:分割字符串,默认是任何空格
usecols:选取数据的列。
需要注意:np.savetxt() ,np.loadtxt() 只能存取一维和二维数组。
import numpy as np
tmp = np.loadtxt('文件名.txt',dtype='np.str')
print(tmp)
print("-------")
tmp1 = np.loadtxt('文件名.txt',dtype='np.str',usrcols=(0,1))
print(tmp1)
这样处理后就会只保留前面两列数据
x = [1,2,3]
y = [4,5,6]
z = [7,8,9]
np.savetxt("保存的文件名.txt",(x,y,z))
写入了文件 (内部数据类型为浮点型)
numpy常用计算模块
numpy是numerical Python的简称 ,是高性能计算和数据分析的基础包
numpy是python的一个扩充程序库。支持高级大量的维度数组和矩阵运算,此外也针对数组运算提供大量的数学函数库。numpy运算效率极好,是大量机器学习框架的基础库。
- 一个强大的N维数组对象ndarrary;
- 比较成熟的函数库;
- 用于整合C/C++ 和 Fortran代码的工具包;
- 实用的线性代数、傅里叶变换和随机数生成函数。
使用numpy,可以有利于以下操作:
- 数组的算数和逻辑运算。
- 傅立叶变换和用于图形操作的例程。
- 与线性代数有关的操作Numpy+Matplotlib绘图库 + Scipy科学计算包 一起使用,这种组合渐渐称为Matlab的替代方案。
numpy ndarray对象
Numpy 的底层是一个Ndarray结构,该结构可以生成N为数组对象。
ndarray 对象是用于存放同类型元素的多维数组
ndarray 内部由以下内容组成:
- 指针:一个指向数据的指针
- dtype:数据类型
- Shape:表示各维度大小的元组。
- Stride:一个跨度元组,指为了前进到当前维度下一个元素需要跨过的字节数。
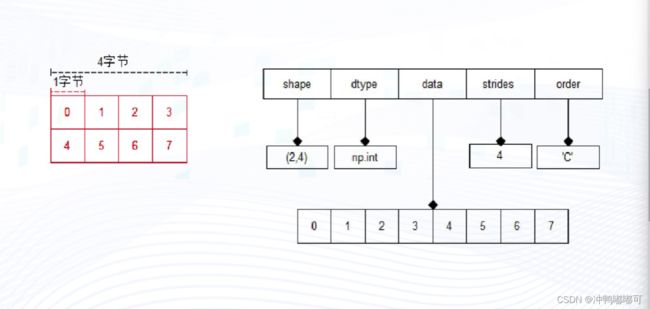
ndarray的术语
- 轴(axis):每一维数组称为一个轴
- 秩(rank):秩是描述轴的数量,即数组的维数。一维数组的秩为1,二维数组的秩为2,以此类推。
numpy.array(object,dtype=None,copy=True,order=None,subok=False,ndmin=0)
练习:
import numpy as np
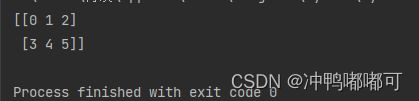
arr = np.array([[0,1,2],[3,4,5]])
print(arr)
reArr = arr.reshape(3,2)
print(reArr)
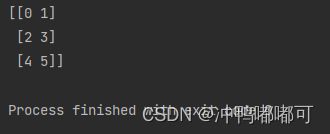
reshape函数可以改变原数组的形状
arr.shape(3,2)
print(arr)

创建特殊的数组
(1) numpy.empty:
创建一个指定形状的(shape) 、 数据类型(dtype) 且未初始化的数组。
(2) numpy.zeros:
创建指定大小的数组,以0填充。
(3) numpy.ones:
创建指定形状的数组,数组元素以1来填充
(4) 能创建序列的函数
arange函数、linspace函数以及python的range函数
numpy.arrange()函数
函数形式:arrange(),其功能是根据[start,stop) 范围以及step设定的步长,生成一个ndarry。
linspace()函数
numpy.linspace(start,stop,num=50,endpoint = True,retstep=False,dtype = None)
start是序列的起始点,stop是序列的结束点,num是在[start,stop]范围内生成的样本数
numpy实例
import numpy as np
arr = np.arange(1,5,0.2)
for j in arr:
print("还剩{}升油!".format(5-j))
arr1 = np.linspace(1,5,50)
for i in arr1:
print("还剩{}升油!".format(5-i))