“人生苦短,我用Python“——python基础<3>
python变成入门总结3
- 字符串
-
- 什么是字符串的驻留机制?
- 字符串的查询操作
- 字符串的大小写转换操作
- 字符串内容对齐操作
- 字符串分隔操作方法
- 判断字符串的方法
- 字符串操作的其他方法
- 字符串的比较操作
- 字符串的切片操作
- 格式化字符串
- 字符串的编码转换
- 函数
-
- 函数的创建与调用
- 函数调用的参数传递
- 函数调用的参数传递内存分析图
- 函数的返回值
- 函数定义默认值参数
- 个数可变的位置参数/关键字形参
- 函数的参数总结
- 变量的作用域
- 递归函数
-
- 递归计算阶乘
- 斐波那契数列
- Bug
-
- Bug常见类型
- 异常处理机制
-
- python中常见的异常类型
- traceback模块
字符串
在Python中字符串是基本数据类型,是一个不可变的字符序列。
什么是字符串的驻留机制?
仅保存一份相同且不可变字符串的方法,不同的值被存放在字符串的驻留池中,Python的驻留机制对相同的字符串只保留一份拷贝,后续创建相同字符串时,不会开辟新空间,而是把该字符串的地址赋给新创建的变量。

a='Python'
b="Python"
c='''Python'''
print(a,id(a))#Python 2794637196512
print(b,id(b))#Python 2794637196512
print(c,id(c))#Python 2794637196512 地址相同,abc变量中存储的是同一个引用。
驻留机制的集中情况(交互模式)
- 字符串的长度为0或1时。
- 符合标识符的字符串。
- 字符串只在编译时进行驻留,而非运行时。
- [-5,256]之间的整数数字。
sys中的intern方法强制2个字符串指向同一对象。



PyCharm对字符串进行了优化处理
s1='abc%'
s2='abc%'
print(s1 is s2)#True
字符串驻留机制的优缺点
- 当需要值相同的字符串时,可以直接从字符串池里拿来使用,避免频繁的创建和销毁,提升效率和节约内存,因此拼接字符串和修改字符串是会比较影响性能的。
- 在需要进行字符串拼接时建议使用str类型的join方法,而非+,因为join()方法是先计算出所有字符中的长度,然后再拷贝,只new一个对象,效率要比"+“高(”+"拼接需要new多个对象:例如’a’+‘b’,new两个对象)。
字符串的查询操作
| 方法名称 | 作用 |
|---|---|
| index() | 查找子串substr第一次出现的位置,如果查找的子串不存在时,则抛出ValueError |
| rindex() | 查找子串substr最后一次出现的位置,如果查找的子串不存在时,则抛出ValueError |
| find() | 查找子串substr第一次出现的位置,如果查找的子串不存在时,则返回-1 |
| rfind() | 查找子串substr最后一次出现的位置,如果查找的子串不存在时,则返回-1 |
s='hello,hello'
print(s.index('lo'))#3
print(s.find('lo'))#3
print(s.rindex('lo'))#9
print(s.rfind('lo'))#9
print(s.index('k'))#ValueError: substring not found 查询不存在的元素,报错
print(s.find('k'))#-1 查询不存在元素,返回-1
字符串的大小写转换操作
| 方法名称 | 作用 |
|---|---|
| upper() | 把字符串中所有字符都转成大写字母 |
| lower() | 把字符串中所有字符都转成小写字母 |
| swapcase() | 把字符串中所有大写字母转成小写字母,把所有小写字母都转成大写字母 |
| capitalize() | 把第一个字符转换为大写,把其余字符转换成小写 |
| title() | 把每个单词的第一个字符转换为大写,把每个单词的剩余字符转换为小写 |
s='hello,python'
a=s.upper()
print(a)#HELLO,PYTHON
print(id(a))#2149937377456
print(id(s))#2149937342960 会产生新的对象
b=s.lower()
print(b,id(b))#hello,python 2067692450160
print(s,id(s))#hello,python 2067692415472 虽然都是小写,转化后也会产生一个新的对象。这里驻留机制可解释,转换操作在运行后。
s2='hello,Python'
print(s2.swapcase())#HELLO,pYTHON
print(s2.title())#Hello,Python
字符串内容对齐操作
| 方法名称 | 作用 |
|---|---|
| center() | 居中对齐,第1个参数指定宽度,第2个参数指定填充符,第2个参数是可选的,默认是空格,如果设置宽度小于实际宽度则返回原字符串 |
| ljust() | 左对齐,第1个参数指定宽度,第2个参数指定填充符,第2个参数是可选的,默认是空格,如果设置宽度小于实际宽度则返回原字符串 |
| rjust() | 右对齐,第1个参数指定宽度,第2个参数指定填充符,第2个参数是可选的,默认是空格,如果设置宽度小于实际宽度则返回原字符串 |
| zfill() | 右对齐,左边用0填充,该方法只接收一个参数,用于指定字符串的宽度,如果指定的宽度小于等于字符串的长度,返回字符串本身 |
s='hello,Python'
print(s.center(20,'*'))#****hello,Python****
print(s.ljust(20,'*'))#hello,Python********
print(s.ljust(10))#print(s.ljust(10))
print(s.rjust(20,'*'))#********hello,Python
print(s.rjust(10))#hello,Python
print(s.zfill(20))#00000000hello,Python
print(s.zfill(10))#hello,Python
print('-8910'.zfill(8))#-0008910
字符串分隔操作方法
| 方法名称 | 作用 |
|---|---|
| split() | ①从字符串的左边开始分隔,默认的分隔符是空格,返回的值是一个列表②通过参数sep指定分隔字符串的分隔符③通过参数maxsplit指定分隔字符串时最大分隔次数,在经过最大次分隔后,剩余子串单独作为一部分 |
| rsplit() | 从字符串的右边开始分隔,默认分隔符是空格,返回值是一个列表②通过参数sep指定分隔字符串的分隔符③通过参数maxsplit指定分隔字符串时最大分隔次数,在经过最大次分隔后,剩余子串单独作为一部分 |
s='hello world Python'
lst=s.split()
print(lst)#['hello', 'world', 'Python']
s1='hello,world,Python'
lst1=s1.split(sep=',',maxsplit=1)
print(lst1)#['hello', 'world,Python']
判断字符串的方法
| 方法名称 | 作用 |
|---|---|
| isidentifier() | 判断指定的字符串是不是合法的标识符 |
| isspace() | 判断指定的字符串是否全部由空白字符组成(回车、换行、水平制表符) |
| isalpha() | 判断指定的字符串是否全部由字母组成 |
| isdecimal() | 判断指定的字符串是否全部由十进制的数字组成 |
| isnumeric() | 判断指定的字符串是否全部由数字组成 |
| isalnum() | 判断指定字符串是否全部由字母和数字组成 |
s='hello,python'
print(s.isidentifier())#False 合法字符数字字母下划线,不包括逗号
print('hello'.isidentifier())#True
print('张三'.isidentifier())#True
print('张三_123'.isidentifier())#True
print('\t'.isspace())#True
print('abc'.isalpha())#True
print('张三'.isalpha())#True
print('张三1'.isalpha())#False
print('123'.isdecimal())#True
print('123四'.isdecimal())#False
print('Ⅳ'.isdecimal())#False
print('123'.isnumeric())#True
print('123四'.isnumeric())#True
print('Ⅳ'.isnumeric())#True
print('abc1'.isalnum())#True
print('张三123'.isalnum())#True
print('abc!'.isalnum())#False
字符串操作的其他方法
| 方法名称 | 作用 |
|---|---|
| replace() | 第1个参数指定被替换的子串,第2个参数指定替换子串的字符串,该方法返回替换后得到的字符串,替换前的字符串不发生变化,调用该方法时可以通过第3个参数指定最大替换次数 |
| join() | 将列表或元组的字符串合并成一个字符串 |
s='hello,python'
print(s.replace('hello','python'))#python,python
s1='hellp,python,python,python'
print(s1.replace('python','java',2))#hellp,java,java,python
lst=['hello','java','Python']
print('|'.join(lst))#hello|java|Python
print(''.join(lst))#hellojavaPython
t=('hello','java','python')
print(''.join(t))#hellojavapython
print('*'.join('Python'))#P*y*t*h*o*n
字符串的比较操作
运算符:>,>=,<,<=,==,!=
***比较规则:***首先比较两个字符串中的第一个字符,如果相等则继续比较下一个字符,依次比较下去,直到两个字符串中的字符不相等时,其比较结果就是两个字符串的比较结果,两个字符串中的所有后续字符将不再被比较。
***比较原理:***两个字符进行比较时,比较的是其ordinal value(原始值),调用内置函数ord可以得到指定字符的ordinal value。其内置函数ord对应的内置函数chr,调用内置函数chr时指定ordinal value可以得到其对应的字符。
print('apple'>'app')#True
print('apple'>'banana')#False
print(ord('a'),ord('b'))#97 98
print(chr(97),chr(98))#a b
print(ord('张'))#24352
print(chr(24352))#张
==与is的区别
==比较的是value,is比较的是地址(id)是否相同。
a=b='Python'
c='Python'
print(a==b)#True
print(a is b)#True
print(c is b)#True
字符串的切片操作
字符串是不可变类型
- 不具备增、删、改等操作。
- 切片操作将产生新的对象。

s='hello,Python'
s1=s[:5]#字符串切片产生新的对象,从0开始到5(不包含5)
s2=s[6:]
s3='!'
newstr=s1+s3+s2
print(s1)#hello
print(s2)#Python
print(newstr)#hello!Python
"""切片[start:end:step]"""
print(s[1:5:1]) #ello 从1开始截到5(不包含5),补偿为1
print(s[::2])#hloPto 默认从0开始,最后一个结束。元素之间索引间隔为2
print(s[::-1])#nohtyP,olleh 默认从字符串最后一个元素开始,到第一个字符结束,步长为1,就是倒叙
print(s[-6::1])#Python 从-6开始到字符串最后,步长为1
格式化字符串
为什么要格式化字符串?

格式化字符串:按一定格式输出的字符串。
格式化字符串的两种方式

#(1) % 占位符
name='张三'
age=20
print('我叫%s,今年%d岁' % (name,age))#我叫张三,今年20岁
#(2) {}
print('我叫{0},今年{1}岁'.format(name,age))#我叫张三,今年20岁
#(3) f-string ——python3+支持
print(f'我叫{name},今年{age}岁')#我叫张三,今年20岁
print('%10d' % 99)# 99 10表示的是宽度
print('%.3f' % 3.1415926)#3.142 保留三位小数
print('%10.3f' % 3.1415926)# 3.142 同时表示精度和宽度
print('{0:.3}'.format(3.1415926))#3.14 .3表示一共三位数 0代表占位符,也可以省略
print('{:.3f}'.format(3.1415926))#3.142 .3f表示保留三位小数
print('{:10.3f}'.format(3.1415926))# 3.142 宽度是10,保留三位小数
字符串的编码转换
为什么需要字符串的编码转换?
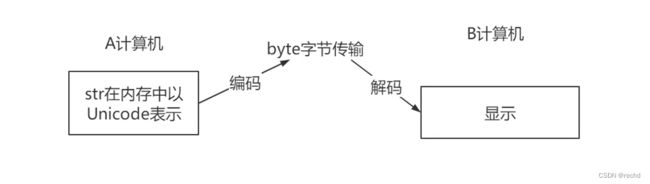
编码与解码的方式:
- 编码:将字符串转换为二进制数据(bytes)。
- 解码:将bytes类型的数据转换成字符串类型。
s='天涯共此时'
#编码
print(s.encode(encoding='GBK')) #b'\xcc\xec\xd1\xc4\xb9\xb2\xb4\xcb\xca\xb1' 在GBK编码中,汉字占两个字节
print(s.encode(encoding='UTF-8'))#b'\xe5\xa4\xa9\xe6\xb6\xaf\xe5\x85\xb1\xe6\xad\xa4\xe6\x97\xb6' 在UTF-8编码中,汉字占三个字节
#解码
byte=b'\xcc\xec\xd1\xc4\xb9\xb2\xb4\xcb\xca\xb1'
print(byte.decode(encoding='GBK'))#天涯共此时
函数
什么是函数?
函数就是执行特定任何以完成特定功能的一段代码。
为什么需要函数?
- 复用代码
- 隐藏实现细节
- 提供可维护性
- 提供可读性便于调试
函数的创建与调用
def 函数名(输入参数):
函数体
[return xxx]
#函数的创建
def calc(a,b):
c=a+b
return c
#函数的调用
result=calc(1,2)
print(result)#3
函数调用的参数传递
-
位置实参:根据形参对应的位置进行参数的传递。

-
关键字实参:根据形参名称进行实参传递。
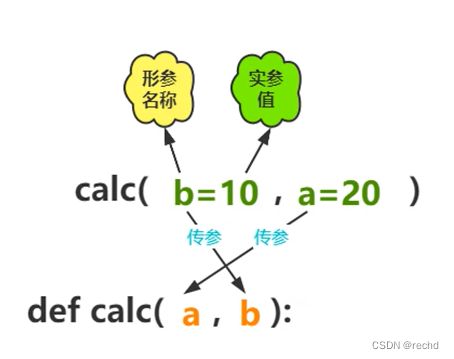
def calc(a,b):
c=a+b
return c
result=calc(1,2)#实参位置
print(result)#3
result1=calc(b=2,a=1)#关键字参数
print(result1)#3
函数调用的参数传递内存分析图
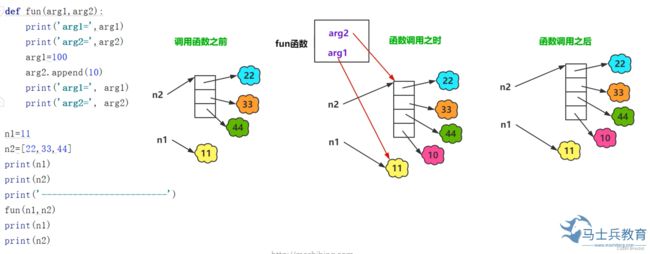
def fun(arg1,arg2):
print('arg1',arg1)
print('arg2',arg2)
arg1=100
arg2.append(10)
print('arg1',arg1)
print('arg2',arg2)
#return
n1=11
n2=[22,33,44]
fun(n1,n2)
print(n1)
print(n2)
"""
arg1 11
arg2 [22, 33, 44]
arg1 100
arg2 [22, 33, 44, 10]
11
[22, 33, 44, 10]
"""
#总结:在函数调用过程中,进行参数的传递,如果是不可变对象,在函数体的修改不会影响实参的值。如果是可变对象,在函数体内的修改会影响到实参的值。
总结:在函数调用过程中,进行参数的传递,如果是不可变对象,在函数体的修改不会影响实参的值。如果是可变对象,在函数体内的修改会影响到实参的值。
函数的返回值
- 如果函数没有返回值,return可以省略
- 函数返回值,如果是一个,直接返回类型
- 函数返回值,如果是多个,返回结果为元组
def fun(num):
odd=[] #存奇数
even=[] #存偶数
for i in num:
if i%2:
odd.append(i)
else:
even.append(i)
return odd,even
lst=[11,22,3,44,55,421]
print(fun(lst))#([11, 3, 55, 421], [22, 44])
函数定义默认值参数
函数定义时,给形参设置默认值,只有与默认值不符的时候才需要传递实参。
def fun(a,b=100):
print(a,b)
fun(200)#200 100
fun(200,300)#200 300
个数可变的位置参数/关键字形参
个数可变的位置参数
- 定义参数时,可能无法实现确定传递的位置实参的个数时,使用可变的位置参数
- 使用 * 定义个数可变的位置形参
- 结果为一个元组
def fun(*args):
print(args)
fun(1)#(1,)
fun(1,2,3)#(1, 2, 3)
个数可变的关键字形参
- 定义参数时,可能无法实现确定传递的位置实参的个数时,使用可变的关键字形参
- 使用 ** 定义个数可变的关键字形参
- 结果为一个字典
def fun(**args):
print(args)
fun(a=1)#{'a': 1}
fun(a=1,b=2,c=3)#{'a': 1, 'b': 2, 'c': 3}
==注意:个数可变位置参数/关键字参数,只能是一个 ==
在一个函数的定义的过程中,既有个数可变的关键字形参,也有个数可变的位置参数,要求位置形参放置在关键字形参之前,否则报错
def fun(*args,**args2):
pass
函数的参数总结
| 参数的类型 | 函数的定义 | 函数的调用 | 备注 |
|---|---|---|---|
| 位置实参 | √ | ||
| 将序列中的每个元素都转换为位置实参 | √ | 使用 * | |
| 关键字实参 | √ | ||
| 将字典中每个键值对都转换为关键字实参 | √ | 使用 ** | |
| 默认值形参 | √ | ||
| 关键字形参 | √ | 使用 * | |
| 个数可变的位置形参 | √ | 使用 * | |
| 个数可变的关键字形参 | √ | 使用 ** |
def fun(a,b,c): #a,b,c在函数的定义处,所以是形式参数
print('a=',a)
print('b=',b)
print('c=',c)
fun(10,20,30)# 函数调用时的参数传递,称为位置传参
lst=[11,22,33]
fun(*lst) # 在函数调用时,将列表中的每个元素都转换为位置实参传入
fun(a=100,c=200,b=300)#函数调用,关键字实参
dic={'a':111,'b':222,'c':333}
fun(**dic) #在函数调用时,将字典中的键值对都转换为关键字参数传入
def fun(a,b,*,c,d):# 从*之后的参数,在函数调用时,只能采用关键字参数传递
print('a=',a)
print('b=',b)
print('c=',c)
print('d=',d)
fun(10,20,c=30,d=40)
其他几种参数定义形式
def fun1(a,b,*,c,d,**args):
pass
def fun2(*args,**args2):
pass
def fun3(a,b=10,*args,**args2):
pass
变量的作用域
程序代码能访问该变量的区域称为作用域。
根据变量的有效范围可分为:
- 局部变量:在函数内定义并使用的变量,只能函数内部有效,局部变量使用global声明,这个变量就会变成全局变量。
- 全局变量:函数体外定义的变量,可作用于函数内外。
def fun(a,b):
c=a+b # c就是局部变量
print(c)
name='张三'#name是全局变量
def fun2():
print(name)#可在函数内部使用
fun2()#张三
def fun3():
global age #局部变量使用global定义变为全局变量
age=20
print(age)
fun3()#20
print(age)#20
递归函数
什么是递归函数?
如果在一个函数的函数体内调用了该函数本身,这个函数就称为递归函数。
递归的组成部分
递归调用与递归终止条件
递归的调用过程
- 每递归调用一次函数,都会在栈内存分配一个栈帧
- 每执行完一次函数,都会释放相应的空间
递归的优缺点
- 缺点:占用内存多,效率低下
- 优点:思路和代码简单
递归计算阶乘

def fac(n):
if n==1:
return 1
else:
return n*fac(n-1)
print(fac(6))#720
斐波那契数列
斐波那契数列:第3项=第1项+第2项
def fib(n):
if n==1:
return 1
elif n==2:
return 1
else:
return fib(n-1)+fib(n-2)
print(fib(6))#8
Bug
Bug常见类型
粗心导致的语法错误,SyntaxError
- 漏了末尾的冒号,如if语句,循环语句,else子句等
- 缩进错误
- 把英文符号写成中文符号
- 字符串拼接时,把字符串和数字拼在一起
- 没有定义变量,比如while的循环条件变量
- “==”比较运算符和"="赋值运算符混用
知识点不熟练导致的错误:index下标越界等
思路不清导致的错误
解决方案:(1)使用print()函数,一步一输出。(2)使用#注释,暂时注释掉部分代码。
异常处理机制
***被动掉坑:***程序代码逻辑没有错误,只是因为用户错误操作或一些“意外情况”而导致的程序崩溃。
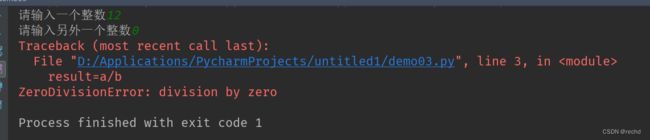
例如:输入两个整数进行除法运算。
a=int(input('请输入一个整数'))
b=int(input('请输入另外一个整数'))
result=a/b
print(result)
输入非整数,直接报错。

除数输入0也会报错
被动掉坑问题的解决方案——异常处理机制
python提供了异常处理机制,可以在异常出现时即时捕获,然后内部“消化”,让程序继续运行。

try:
a=int(input('请输入一个整数'))
b=int(input('请输入另外一个整数'))
result=a/b
print(result)
except ZeroDivisionError:
print('除数不能为0')
多个except结构
捕获异常的顺序按照先子类后父类的顺序,为了避免遗漏可能出现的异常,可以在最后增加BaseException。
try:
a=int(input('请输入一个整数'))
b=int(input('请输入另外一个整数'))
result=a/b
print(result)
except ZeroDivisionError:
print('除数不能为0')
except ValueError:
print('不能将字符串转换为数字')
except BaseException as e:
print(e)
try…except…else结构
如果try块中没有抛出异常,则执行else块,如果try中抛出异常,则执行except块。
try:
a=int(input('请输入一个整数'))
b=int(input('请输入另外一个整数'))
result=a/b
except BaseException as e:
print(e)
else:
print(result)
try…except…else…finally结构
finally块无论是否发生异常都会被执行,能常用来释放try块中申请的资源。
try:
a=int(input('请输入一个整数'))
b=int(input('请输入另外一个整数'))
result=a/b
except BaseException as e:
print(e)
else:
print(result)
finally:
print('无论是否产生异常,都会执行')#一般用来释放资源
print('程序结束')
python中常见的异常类型
| 异常类型 | 描述 |
|---|---|
| ZeroDivisionError | 除(或取模)零(所有数据类型) |
| IndexError | 序列中没有此索引(index) |
| KeyError | 映射中没有这个键 |
| NameError | 未声明/初始化对象(没有属性) |
| ValueError | 传入无效参数 |
traceback模块
使用traceback模块打印异常信息。
import traceback
try:
print('--------------')
print(1/0)
except:
traceback.print_exc()
"""
--------------
Traceback (most recent call last):
File "D:/Applications/PycharmProjects/untitled1/demo03.py", line 5, in
print(1/0)
ZeroDivisionError: division by zero
"""