详谈JavaScript 二进制家族:Blob、File、FileReader、ArrayBuffer、Base64
JavaScript 提供了一些 API 来处理文件或原始文件数据,例如:
1. Blob、ArrayBuffer、File可以分为一类,它们都是数据;
2. fileReader是一种工具,用来读取数据。
一、Blob
Blob 全称为 binary large object ,即二进制大对象,它是 JavaScript 中的一个对象,表示原始的类似文件的数据。实际上,Blob 对象是包含有只读原始数据的类文件对象。简单来说,Blob 对象就是一个不可修改的二进制文件。
new Blob(array, options);
array: 由 ArrayBuffer、ArrayBufferView、Blob、DOMString 等对象构成的,将会被放进 Blob options: 可选的 BlobPropertyBag 字典,它可能会指定如下两个属性。 type:默认值为 “”,表示将会被放入到 blob 中的数组内容的 MIME 类型。
这里可以成为动态文件创建,其正在创建一个类似文件的对象。这个 blob 对象上有两个属性:
size: Blob对象中所包含数据的大小(字节)
type: 字符串,认为该Blob对象所包含的 MIME 类型
下面来看打印结果:
const blob = new Blob(["Hello World"], {type: "text/plain"});
console.log(blob.size); // 11
console.log(blob.type); // "text/plain"
注意
字符串"Hello World"是 UTF-8 编码的,因此它的每个字符占用 1 个字节。
到现在,Blob 对象看起来似乎我们还是没有啥用。那该如何使用 Blob 对象呢?可以使用 URL.createObjectURL() 方法将其转化为一个 URL,并在 Iframe 中加载:
<iframe></iframe>
const iframe = document.getElementsByTagName("iframe")[0];
const blob = new Blob(["Hello World"], {type: "text/plain"});
iframe.src = URL.createObjectURL(blob);
**
- Blob 分片
**
其有三个参数:
start:设置切片的起点,即切片开始位置。默认值为 0,这意味着切片应该从第一个字节开始
end:设置切片的结束点,会对该位置之前的数据进行切片。默认值为blob.size
contentType:设置新 blob 的 MIME 类型。如果省略 type,则默认为 blob 的原始值
const iframe = document.getElementsByTagName("iframe")[0];
const blob = new Blob(["Hello World"], {type: "text/plain"});
const subBlob = blob.slice(0, 5);
iframe.src = URL.createObjectURL(subBlob);
此时页面会显示"Hello"。
二、File
文件(File)接口提供有关文件的信息,并允许网页中的 JavaScript 访问其内容。实际上,File 对象是特殊类型的 Blob,且可以用在任意的 Blob 类型的 context 中。Blob 的属性和方法都可以用于 File 对象。
在 JavaScript 中,主要有两种方法来获取 File 对象:
元素上选择文件后返回的 FileList 对象;文件拖放操作生成的 DataTransfer 对象
<input type="file" id="fileInput" multiple="multiple">
这里给 input 标签添加了三个属性:
type=“file”: 指定 input 的输入类型为文件
id=“fileInput”: 指定 input 的唯一 id
multiple=“multiple”: 指定 input 可以同时上传多个文件
下面来给 input 标签添加 onchange 事件,当选择文件并上传之后触发:
const fileInput = document.getElementById("fileInput");
fileInput.onchange = (e) => {
console.log(e.target.files);
}
当点击上传文件时,控制台就会输出一个 FileList 数组,这个数组的每个元素都是一个 File 对象,一个上传的文件就对应一个 File 对象
每个 File 对象都包含文件的一些属性,这些属性都继承自 Blob 对象:
- lastModified:引用文件最后修改日期,为自1970年1月1日0:00以来的毫秒数
- lastModifiedDate:引用文件的最后修改日期
- name:引用文件的文件名
- size:引用文件的文件大小
- type:文件的媒体类型(MIME)
- webkitRelativePath:文件的路径或 URL
通常,我们在上传文件时,可以通过对比 size 属性来限制文件大小,通过对比 type 来限制上传文件的格式等。
另一种获取 File 对象的方式就是拖放 API,这个 API 很简单,就是将浏览器之外的文件拖到浏览器窗口中,并将它放在一个成为拖放区域的特殊区域中。拖放区域用于响应放置操作并从放置的项目中提取信息。这些是通过 ondrop 和 ondragover 两个 API 实现的。
下面来看一个简单的例子,首先定义一个拖放区域:
<div id="drop-zone"></div>
然后给这个元素添加 ondragover 和 ondrop 事件处理程序:
const dropZone = document.getElementById("drop-zone");
dropZone.ondragover = (e) => {
e.preventDefault();
}
dropZone.ondrop = (e) => {
e.preventDefault();
const files = e.dataTransfer.files;
console.log(files)
}
注意: 这里给两个 API 都添加了 e.preventDefault(),用来阻止默认事件。它是非常重要的,可以用来阻止浏览器的一些默认行为,比如放置文件将显示在浏览器窗口中。
当拖放文件到拖放区域时,控制台就会输出一个 FileList 数组,该数组的每一个元素都是一个 File 对象。这个 FileList 数组是从事件参数的 dataTransfer 属性的 files 获取的。
三、FileReader
FileReader 是一个异步 API,用于读取文件并提取其内容以供进一步使用。FileReader 可以将 Blob 读取为不同的格式。
const reader = new FileReader();
FileReader 对象提供了以下方法来加载文件:
- readAsArrayBuffer():读取指定 Blob 中的内容,完成之后,result 属性中保存的将是被读取文件的 ArrayBuffer 数据对象
- readAsBinaryString():读取指定 Blob 中的内容,完成之后,result 属性中将包含所读取文件的原始二进制数据
- readAsDataURL():读取指定 Blob 中的内容,完成之后,result 属性中将包含一个data: URL 格式的 Base64 字符串以表示所读取文件的内容
- readAsText():读取指定 Blob 中的内容,完成之后,result 属性中将包含一个字符串以表示所读取的文件内容
FileReader 对象常用的事件如下:
- abort:该事件在读取操作被中断时触发
- error:该事件在读取操作发生错误时触发
- load:该事件在读取操作完成时触发
- progress:该事件在读取 Blob 时触发
当然,这些方法可以加上前置 on 后在HTML元素上使用,比如onload、onerror、onabort、onprogress。除此之外,由于FileReader对象继承自EventTarget,因此还可以使用 addEventListener() 监听上述事件。
const fileInput = document.getElementById("fileInput");
const reader = new FileReader();
fileInput.onchange = (e) => {
reader.readAsText(e.target.files[0]);
}
reader.onload = (e) => {
console.log(e.target.result);
}
这里,首先创建了一个 FileReader 对象,当文件上传成功时,使用 readAsText() 方法读取 File 对象,当读取操作完成时打印读取结果。
使用上述例子读取文本文件时,就是比较正常的。如果读取二进制文件,比如png格式的图片,往往会产生乱码. 那该如何处理这种二进制数据呢?readAsDataURL() 是一个不错的选择,它可以将读取的文件的内容转换为 base64 数据的 URL 表示。这样,就可以直接将 URL 用在需要源链接的地方,比如 img 标签的 src 属性。
const fileInput = document.getElementById("fileInput");
const reader = new FileReader();
fileInput.onchange = (e) => {
reader.readAsDataURL(e.target.files[0]);
}
reader.onload = (e) => {
console.log(e.target.result);
}
将上传的图片通过以上方式显示在页面上:
<input type="file" id="fileInput" />
<img id="preview" />
const fileInput = document.getElementById("fileInput");
const preview = document.getElementById("preview");
const reader = new FileReader();
fileInput.onchange = (e) => {
reader.readAsDataURL(e.target.files[0]);
};
reader.onload = (e) => {
preview.src = e.target.result;
console.log(e.target.result);
};
当上传大文件时,可以通过 progress 事件来监控文件的读取进度。
四、ArrayBuffer
ArrayBuffer 对象用来表示通用的、固定长度的原始二进制数据缓冲区。ArrayBuffer 的内容不能直接操作,只能通过 DataView 对象或 TypedArrray 对象来访问。这些对象用于读取和写入缓冲区内容。
ArrayBuffer 本身就是一个黑盒,不能直接读写所存储的数据,需要借助以下视图对象来读写:
- TypedArray:用来生成内存的视图,通过9个构造函数,可以生成9种数据格式的视图。
- DataViews:用来生成内存的视图,可以自定义格式和字节序。
TypedArray视图和 DataView视图的区别主要是字节序,前者的数组成员都是同一个数据类型,后者的数组成员可以是不同的数据类型。
那 ArrayBuffer 与 Blob 有啥区别呢?根据 ArrayBuffer 和 Blob 的特性,Blob 作为一个整体文件,适合用于传输;当需要对二进制数据进行操作时(比如要修改某一段数据时),就可以使用 ArrayBuffer。
ArrayBuffer 有哪些常用的方法和属性。
new ArrayBuffer(bytelength)
ArrayBuffer()构造函数可以分配指定字节数量的缓冲区,其参数和返回值如下:
- 参数:它接受一个参数,即 bytelength,表示要创建数组缓冲区的大小(以字节为单位)
- 返回值:返回一个新的指定大小的ArrayBuffer对象,内容初始化为0。
const buffer = new ArrayBuffer(16);
console.log(buffer.byteLength); // 16
ArrayBuffer 实例上还有一个 slice 方法,该方法可以用来截取 ArrayBuffer 实例,它返回一个新的 ArrayBuffer ,它的内容是这个 ArrayBuffer 的字节副本,从 begin(包括),到 end(不包括)。来看例子:
const buffer = new ArrayBuffer(16);
console.log(buffer.slice(0, 8)); // 16
这里会从 buffer 对象上将前8个字节生成一个新的ArrayBuffer对象。这个方法实际上有两步操作,首先会分配一段指定长度的内存,然后拷贝原来ArrayBuffer对象的置顶部分。
ArrayBuffer 上有一个 isView()方法,它的返回值是一个布尔值,如果参数是 ArrayBuffer 的视图实例则返回 true,例如类型数组对象或 DataView 对象;否则返回 false。简单来说,这个方法就是用来判断参数是否是 TypedArray 实例或者 DataView 实例:
const buffer = new ArrayBuffer(16);
ArrayBuffer.isView(buffer) // false
const view = new Uint32Array(buffer);
ArrayBuffer.isView(view) // true
TypedArray 对象一共提供 9 种类型的视图,每一种视图都是一种构造函数
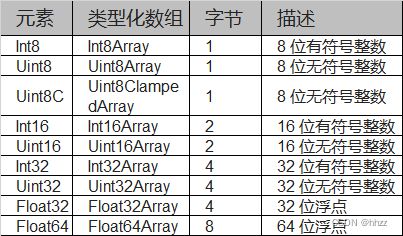
- Uint8Array: 将 ArrayBuffer 中的每个字节视为一个整数,可能的值从 0 到 255 (一个字节等于 8 位)。 这样的值称为“8 位无符号整数”。
- Uint16Array:将 ArrayBuffer 中任意两个字节视为一个整数,可能的值从 0 到 65535。 这样的值称为“16 位无符号整数”。
- Uint32Array: 将 ArrayBuffer 中任何四个字节视为一个整数,可能值从 0 到 4294967295,这样的值称为“32 位无符号整数”。
这些构造函数生成的对象统称为 TypedArray 对象。它们和正常的数组很类似,都有length 属性,都能用索引获取数组元素,所有数组的方法都可以在类型化数组上面使用。
那类型化数组和数组有什么区别呢?
- 类型化数组的元素都是连续的,不会为空;
- 类型化数组的所有成员的类型和格式相同;
- 类型化数组元素默认值为 0;
- 类型化数组本质上只是一个视图层,不会存储数据,数据都存储在更底层的 ArrayBuffer 对象中。
TypedArray 的语法如下(TypedArray只是一个概念,实际使用的是那9个对象):
new Int8Array(length);
new Int8Array(typedArray);
new Int8Array(object);
new Int8Array(buffer [, byteOffset [, length]]);
TypedArray(typeArray) :接收一个视图实例作为参数
const view = new Int8Array(new Uint8Array(6));
view[0] = 10;
view[3] = 6;
console.log(view);
需要注意,TypedArray视图会开辟一段新的内存,不会在原数组上建立内存。当然,这里创建的类型化数组也能转换回普通数组:
Array.prototype.slice.call(view); // [10, 2, 3, 6, 5]
每种视图的构造函数都有一个 BYTES_PER_ELEMENT 属性,表示这种数据类型占据的字节数:
Int8Array.BYTES_PER_ELEMENT // 1
Uint8Array.BYTES_PER_ELEMENT // 1
Int16Array.BYTES_PER_ELEMENT // 2
Uint16Array.BYTES_PER_ELEMENT // 2
Int32Array.BYTES_PER_ELEMENT // 4
Uint32Array.BYTES_PER_ELEMENT // 4
Float32Array.BYTES_PER_ELEMENT // 4
Float64Array.BYTES_PER_ELEMENT // 8
BYTES_PER_ELEMENT 属性也可以在类型化数组的实例上获取:
const buffer = new ArrayBuffer(16);
const view = new Uint32Array(buffer);
console.log(Uint32Array.BYTES_PER_ELEMENT); // 4
五、DataView
说完 ArrayBuffer,下面来看看另一种操作 ArrayBuffer 的方式:DataView。DataView 视图是一个可以从 二进制 ArrayBuffer 对象中读写多种数值类型的底层接口,使用它时,不用考虑不同平台的字节序问题。
DataView视图提供更多操作选项,而且支持设定字节序。本来,在设计目的上,ArrayBuffer对象的各种TypedArray视图,是用来向网卡、声卡之类的本机设备传送数据,所以使用本机的字节序就可以了;而DataView视图的设计目的,是用来处理网络设备传来的数据,所以大端字节序或小端字节序是可以自行设定的。
- buffer:一个已经存在的 ArrayBuffer 对象,DataView 对象的数据源。
- byteOffset:可选,此 DataView 对象的第一个字节在 buffer 中的字节偏移。如果未指定,则默认从第一个字节开始。
- byteLength:可选,此 DataView 对象的字节长度。如果未指定,这个视图的长度将匹配 buffer 的长度。
const buffer = new ArrayBuffer(16);
const view = new DataView(buffer);
console.log(view);
buffer、byteLength、byteOffset
DataView实例有以下常用属性:
- buffer:返回对应的ArrayBuffer对象;
- byteLength:返回占据的内存字节长度;
- byteOffset:返回当前视图从对应的ArrayBuffer对象的哪个字节开始。
DataView 实例提供了以下方法来读取内存,它们的参数都是一个字节序号,表示开始读取的字节位置:
- getInt8:读取1个字节,返回一个8位整数。
- getUint8:读取1个字节,返回一个无符号的8位整数。
- getInt16:读取2个字节,返回一个16位整数。
- getUint16:读取2个字节,返回一个无符号的16位整数。
- getInt32:读取4个字节,返回一个32位整数。
- getUint32:读取4个字节,返回一个无符号的32位整数。
- getFloat32:读取4个字节,返回一个32位浮点数。
- getFloat64:读取8个字节,返回一个64位浮点数。
- const buffer = new ArrayBuffer(24);
- const view = new DataView(buffer);
// 从第1个字节读取一个8位无符号整数
const view1 = view.getUint8(0);
// 从第2个字节读取一个16位无符号整数
const view2 = view.getUint16(1);
// 从第4个字节读取一个16位无符号整数
const view3 = view.getUint16(3);
DataView 实例提供了以下方法来写入内存,它们都接受两个参数,第一个参数表示开始写入数据的字节序号,第二个参数为写入的数据:
- setInt8:写入1个字节的8位整数。
- setUint8:写入1个字节的8位无符号整数。
- setInt16:写入2个字节的16位整数。
- setUint16:写入2个字节的16位无符号整数。
- setInt32:写入4个字节的32位整数。
- setUint32:写入4个字节的32位无符号整数。
- setFloat32:写入4个字节的32位浮点数。
- setFloat64:写入8个字节的64位浮点数。
六、Object URL
其实 Blob URL/Object URL 是一种伪协议,允许将 Blob 和 File 对象用作图像、二进制数据下载链接等的 URL 源。
对于 Blob/File 对象,可以使用 URL构造函数的 createObjectURL() 方法创建将给出的对象的 URL。这个 URL 对象表示指定的 File 对象或 Blob 对象。我们可以在、
<input type="file" id="fileInput" />
<img id="preview" />
再来使用 URL.createObjectURL() 将File 对象转化为一个 URL:
const fileInput = document.getElementById("fileInput");
const preview = document.getElementById("preview");
fileInput.onchange = (e) => {
preview.src = URL.createObjectURL(e.target.files[0]);
console.log(preview.src);
};
const objUrl = URL.createObjectURL(new File([""], "filename"));
console.log(objUrl);
URL.revokeObjectURL(objUrl);
七、Base64
Base64 是一种基于64个可打印字符来表示二进制数据的表示方法。Base64 编码普遍应用于需要通过被设计为处理文本数据的媒介上储存和传输二进制数据而需要编码该二进制数据的场景。这样是为了保证数据的完整并且不用在传输过程中修改这些数据。
在 JavaScript 中,有两个函数被分别用来处理解码和编码 base64 字符串:
- atob():解码,解码一个 Base64 字符串;
- btoa():编码,从一个字符串或者二进制数据编码一个 Base64 字符串。
btoa("JavaScript") // 'SmF2YVNjcmlwdA=='
atob('SmF2YVNjcmlwdA==') // 'JavaScript'
那 base64 的实际应用场景有哪些呢?其实多数场景就是基于Data URL的。比如,使用toDataURL()方法把 canvas 画布内容生成 base64 编码格式的图片:
const canvas = document.getElementById('canvas');
const ctx = canvas.getContext("2d");
const dataUrl = canvas.toDataURL();
除此之外,还可以使用readAsDataURL()方法把上传的文件转为base64格式的data URI,比如上传头像展示或者编辑:
<input type="file" id="fileInput" />
<img id="preview" />
const fileInput = document.getElementById("fileInput");
const preview = document.getElementById("preview");
const reader = new FileReader();
fileInput.onchange = (e) => {
reader.readAsDataURL(e.target.files[0]);
};
reader.onload = (e) => {
preview.src = e.target.result;
console.log(e.target.result);
};
另外,一些小的图片都可以使用 base64 格式进行展示,img标签和background的 url 属性都支持使用base64 格式的图片,这样做也可以减少 HTTP 请求。
看完这些基本的概念,下面就来看看常用格式之间是如何转换的。
- ArrayBuffer → blob
const blob = new Blob([new Uint8Array(buffer, byteOffset, length)]);
- ArrayBuffer → base64
const base64 = btoa(String.fromCharCode.apply(null, new Uint8Array(arrayBuffer))); - base64 → blob
const base64toBlob = (base64Data, contentType, sliceSize) => {
const byteCharacters = atob(base64Data);
const byteArrays = [];
for (let offset = 0; offset < byteCharacters.length; offset += sliceSize) {
const slice = byteCharacters.slice(offset, offset + sliceSize);
const byteNumbers = new Array(slice.length);
for (let i = 0; i < slice.length; i++) {
byteNumbers[i] = slice.charCodeAt(i);
}
const byteArray = new Uint8Array(byteNumbers);
byteArrays.push(byteArray);
}
const blob = new Blob(byteArrays, {type: contentType});
return blob;
}
- blob → ArrayBuffer
function blobToArrayBuffer(blob) {
return new Promise((resolve, reject) => {
const reader = new FileReader();
reader.onload = () => resolve(reader.result);
reader.onerror = () => reject;
reader.readAsArrayBuffer(blob);
});
}
- blob → base64
function blobToBase64(blob) {
return new Promise((resolve) => {
const reader = new FileReader();
reader.onloadend = () => resolve(reader.result);
reader.readAsDataURL(blob);
});
}
- blob → Object URL
const objectUrl = URL.createObjectURL(blob);