【python】class 类;参数传递问题
目录
- 1 Python类的定义与实例的创建
- 2 Python类中的实例属性与类属性
-
- 2.1 实例属性
- 2.2 类属性(这里总结的很好)
- 3 Python类的实例方法
- 4 总结
-
- 5 继承父类
- 6 参数传递的问题
-
- 6.1 可变对象
-
- 1)列表
- 2)字典
- 3)pytorch 的模型
- 4)np.array & 多维的 torch.tensor
- 6.2 不可变对象
-
- 1)维度为1的 torch.tensor
- 6.3 如何判断是可变还是不可变?
- 6.4 操作也会影响参数传递
以圆为例,圆是具有圆周率(pi)和半径®两个相似特征的属性。根据相似特征抽象出圆类,每个圆的半径可以不同,那么半径可以作为圆的实例属性;而每个圆的圆周率pi是相同的,那么圆周率pi就可以作为类属性,这样就定义出了一个圆类。而我们要知道圆的面积,周长等可以通过类方法计算出来。
1 Python类的定义与实例的创建
在Python中,类通过 class 关键字定义,类名通用习惯为首字母大写,Python3中类基本都会继承于object类,语法格式如下,我们创建一个Circle圆类:
class Circle(object): # 创建Circle类,Circle为类名
pass # 此处可添加属性和方法
注意:我们定义的类都会继承于object类,当然也可以不继承object类;两者区别不大,但没有继承于object类使用多继承时可能会出现问题。
有了Circle类的定义,就可以创建出具体的circle1、circle2等实例,circle1和circle2是个实际的圆。创建实例使用 类名+(),类似函数调用的形式创建。
如下我们创建两个Circle类的实例:
circle1= Circle()
circle2= Circle()
2 Python类中的实例属性与类属性
类的属性是用来表明这个类是什么的。
类的属性分为实例属性与类属性两种。
实例属性用于区分不同的实例;
类属性是每个实例的共有属性。
区别:实例属性每个实例都各自拥有,相互独立;而类属性有且只有一份,是共有的属性。
2.1 实例属性
类的属性都是用来指明这个类"是什么",实例属性是用来区分每个实例不同的基础。
在上面我们创建了Circle类,大家都知道所有圆都具备半径这个通用属性,下面我们为circle1、circle2 圆实例添加半径 r 这个属性并赋值。
circle1.r = 1 # r为实例属性
circle2.R= 2
print(circle1.r) # 使用 实例名.属性名 可以访问我们的属性
print(circle2.R)
如上 circle1.r、circle2.R 大小写有区分,两个实例的属性名称不统一不利于后面的访问和使用,而且每次在创建圆后我们要再为实例添加属性会比较麻烦,所以我们可以在创建实例时给类初始属性。
在定义 Circle 类时,可以为 Circle 类添加一个特殊的 init() 方法,当创建实例时,init() 方法被自动调用为创建的实例增加实例属性。
我们在此为每个实例都统一加上我们需要的属性:
class Circle(object): # 创建Circle类
def __init__(self, r): # 初始化一个属性r(不要忘记self参数,他是类下面所有方法必须的参数)
self.r = r # 表示给我们将要创建的实例赋予属性r赋值
注意:init() 方法的第一个参数必须是 self(self代表类的实例,可以用别的名字,但建议使用约定成俗的self),后续参数则可以自由指定,和定义函数没有任何区别。
拓展:init() 方法的用法类似java中的构造方法,但它不是构造方法,Python中创建实例的方法是__new__() ,这个方法在python大多数使用默认方法,不需要重新定义,初学者不用关注__new()__方法。
相应,创建实例时就必须要提供除 self 以外的参数:
circle1 = Circle(1) # 创建实例时直接给定实例属性,self不算在内
circle2 = Circle(2)
print(circle1.r) # 实例名.属性名 访问属性
print(circle2.r) # 我们调用实例属性的名称就统一了
注意:实例名.属性名 circle1.r 访问属性,是我们上面Circle类__init__() 方法中 self.r 的 r 这个实例属性名,而不是__init__(self, r)方法中的 r 参数名,如下更加容易理解:
class Circle(object): # 创建Circle类
def __init__(self, R): # 约定成俗这里应该使用r,它与self.r中的r同名
self.r = R
circle1 = Circle(1)
print(circle1.r) #我们访问的是小写r
面试喜欢问的问题:创建类时,类方法中的self是什么?
self 代表类的实例,是通过类创建的实例 (注意,在定义类时这个实例我们还没有创建,它表示的我们使用类时创建的那个实例)
2.2 类属性(这里总结的很好)
绑定在实例上的属性不会影响其他实例,但类本身也是一个对象,如果在类上绑定属性,则所有实例都可以访问该类的属性,并且所有实例访问的类属性都是同一个!!!记住,实例属性每个实例各自拥有,互相独立,而类属性有且只有一份。
圆周率π为圆的共有属性,我们可以在Circle类添加pi这个类属性,如下:
class Circle(object):
pi = 3.14 # 类属性
def __init__(self, r): # 实例属性
self.r = r
circle1 = Circle(1)
circle2 = Circle(2)
print('----未修改前-----')
print('pi=\t', Circle.pi)
print('circle1.pi=\t', circle1.pi) # 1
print('circle2.pi=\t', circle2.pi) # 2
print('----通过类名修改后-----')
Circle.pi = 3.14159 # 通过类名修改类属性,所有实例的类属性被改变
print('pi=\t', Circle.pi) # 3.14159
print('circle1.pi=\t', circle1.pi) # 3.14159
print('circle2.pi=\t', circle2.pi) # 3.14159
print('----通过circle1实例名修改后-----')
circle1.pi=3.14111 # 实际上这里是给circle1创建了一个与类属性同名的实例属性
print('pi=\t', Circle.pi) # 3.14159
print('circle1.pi=\t', circle1.pi) # 实例属性的访问优先级比类属性高,所以是3.14111
print('circle2.pi=\t', circle2.pi) # 3.14159
print('----删除circle1实例属性pi-----')
仔细观察我们通过类创建的实例修改的类属性后,通过其他实例访问类属性他的值还是没有改变。其实是通过实例修改类属性是给实例创建了一个与类属性同名的实例属性而已,实例属性访问优先级比类属性高,所以我们访问时优先访问实例属性,它将屏蔽掉对类属性的访问。
我们删除circle1实例的实例属性pi,就能访问该类的类属性了。
print('----删除circle1实例属性pi-----')
del circle1.pi
print('pi=\t', Circle.pi)
print('circle1.pi=\t', circle1.pi)
print('circle2.pi=\t', circle2.pi)
输出结果:
----删除circle1实例属性pi-----
pi= 3.14159
circle1.pi= 3.14159
circle2.pi= 3.14159
可见,千万不要在实例上修改类属性,它实际上并没有修改类属性,而是给实例绑定了一个实例属性。
3 Python类的实例方法
方法是表明这个类用是来做什么。
在类的内部,使用 def 关键字来定义方法,与一般函数定义不同,类方法必须第一个参数为 self, self 代表的是类的实例(即你还未创建类的实例),其他参数和普通函数是完全一样。
如下我们给圆类 Circle 添加求面积的方法 get_area :
class Circle(object):
pi = 3.14 # 类属性
def __init__(self, r):
self.r = r # 实例属性
def get_area(self):
""" 圆的面积 """
# return self.r**2 * Circle.pi # 通过实例修改pi的值对面积无影响,这个pi为类属性的值
return self.r**2 * self.pi # 通过实例修改pi的值对面积我们圆的面积就会改变
circle1 = Circle(1)
print(circle1.get_area()) # 调用方法 self不需要传入参数,不要忘记方法后的括号 输出 3.14
注意:示例中的 get_area(self) 就是一个方法,它的第一个参数是 self 。init(self, name)其实也可看做是一个特殊的实例方法。
在方法的内部需要调用实例属性采用 "self.属性名 " 调用。示例中 get_area(self) 对于 pi 属性的引用 Circle.pi 与 self.pi 存在一定区别。
Circle.pi 使用的是类属性 pi,我们通过创建的实例去修改 pi 的值对它无影响。self.pi 为实例的 pi 值,我们通过创建的实例去修改 pi 的值时,由于使用 self.pi 调用的是实例属性,所以 self.pi 是修改后的值。
4 总结
参数的传递图:
5 继承父类
当现在已经定义了一个类,我想在它的基础上进行部分方法(函数)或者属性的添加、重写,就需要用到父类继承这个技术。
直白的说 super().__init__(),就是继承父类的init方法,同样可以使用super()点 其他方法名,去继承其他方法。
测试一、我们尝试下面代码,没有super(A, self).__init__()时调用A的父类Root的属性和方法(方法里不对Root数据进行二次操作)
class Root(object):
def __init__(self):
self.x= '这是属性'
def fun(self):
print('这是方法')
class A(Root): # Root是要继承的父类
def __init__(self):
print('实例化时执行')
test = A() #实例化类
test.fun() #调用方法
test.x #调用属性
out:
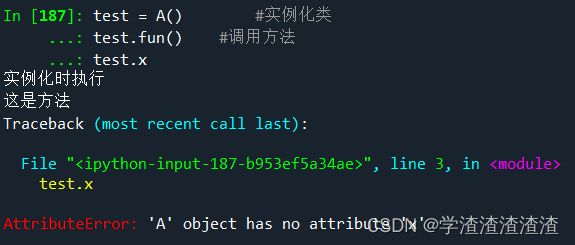
可以发现,Root 的方法(函数)很好的被子类A给继承了,但是父类的属性却不能在子类中继承,因此我们需要引入
super().__init__() 来进行父类方法和属性的继承:
class Root(object):
def __init__(self):
self.x= '这是属性'
def fun(self):
print('这是方法')
class A(Root): # Root是要继承的父类
def __init__(self):
super().__init__()
print('实例化时执行')
test = A() #实例化类
test.fun() #调用方法
test.x #调用属性
out:
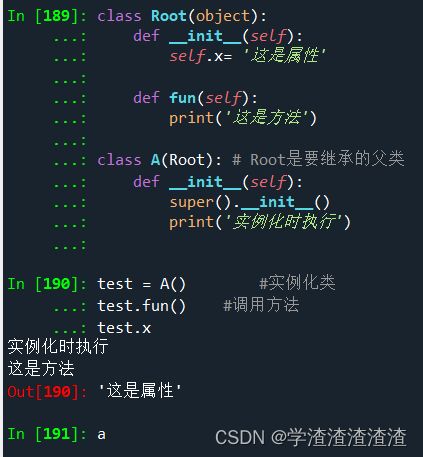
完美运行~
补充, Python 3 可以使用直接使用 super().xxx 代替 super(Class, self).xxx:
python3直接写成 super().方法名(参数)
python2必须写成 super(父类,self).方法名(参数)
比如可以这样使用:
class A:
def add(self, x):
y = x+1
print(y)
class B(A):
def add(self, x):
super().add(x)
b = B()
b.add(2) # 3
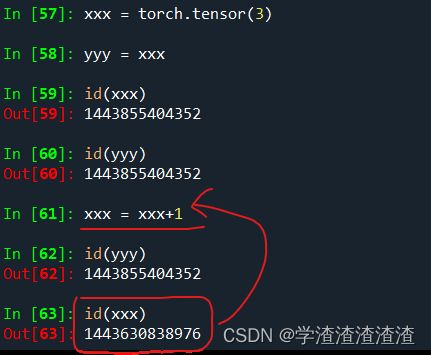
6 参数传递的问题
在c语言中,调用某个函数时,传入函数的实参可以是值传递,也可以是引用传递。
但是在python中,参数的传递都是“引用传递”,不是“值传递”。
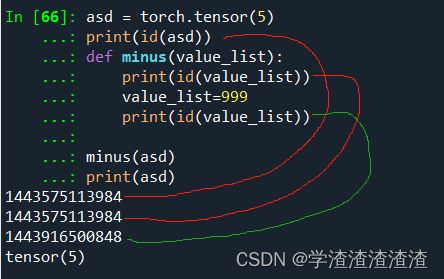
asd = torch.tensor(5)
print(id(asd))
def minus(value_list):
print(id(value_list))
value_list=999
print(id(value_list))
minus(asd)
print(asd)
具体操作时分为以下两类︰
6.1 可变对象
对“可变对象”进行“写操作”,直接作用于原对象本身。
可变对象有:字典、np.array、列表、集合、自定义的对象等,并且要求运算操作只修改对象的部分数据而不是全部(部分赋值)。
可变对象的参数传递如下
1)列表
# 列表是可变对象
asd = [0,1]
print(id(asd))
def minus(value_list):
value_list[0]=999
print(id(value_list))
minus(asd)
print(asd)

2)字典
同样的,字典也是可变对象:
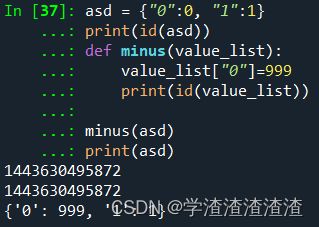
asd = {"0":0, "1":1}
print(id(asd))
def minus(value_list):
value_list["0"]=999
print(id(value_list))
minus(asd)
print(asd)
3)pytorch 的模型
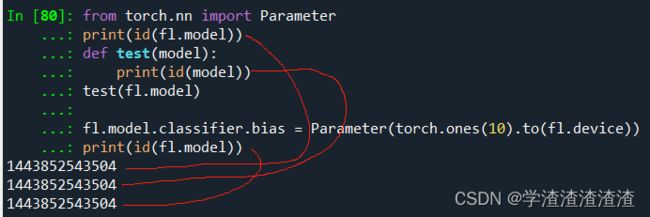
假设之前定义好了某个模型 fl.model,然后对其参数进行修改,观察修改前后 id 是否发生变化。
from torch.nn import Parameter
print(id(fl.model))
def test(model):
print(id(model))
test(fl.model)
fl.model.classifier.bias = Parameter(torch.ones(10).to(fl.device))
print(id(fl.model))
id 没有变化
4)np.array & 多维的 torch.tensor
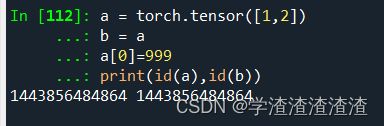
6.2 不可变对象
对“不可变对象”进行“写操作”,会产生一个新的“对象空间”,并用新的值填充这块空间,类似于 copy.deepcopy()和c语言的值传递。
不可变对象有:数字、字符串、元组、function、torch.tensor等,以及一些可变对象的重定义(全部赋值)。
1)维度为1的 torch.tensor
asd = torch.tensor(5)
print(id(asd))
def minus(value_list):
value_list=999
print(id(value_list))
minus(asd)
print(asd)
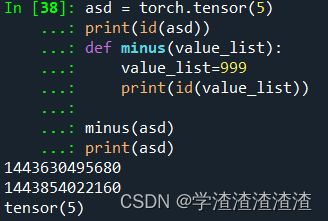
看这里更清楚,只要对xxx做修改,它的id就会发生变化
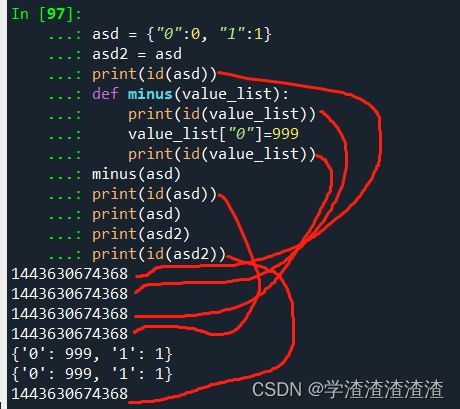
6.3 如何判断是可变还是不可变?
根据 id() 函数可以确定某个对象是否是可变对象,具体做法如下:
asd = {"0":0, "1":1}
asd2 = asd
print(id(asd))
def minus(value_list):
print(id(value_list))
value_list["0"]=999
print(id(value_list))
minus(asd)
print(id(asd))
print(asd)
print(asd2)
print(id(asd2))
因为字典是可变参数,所以其赋值、参数传递的时候地址(id)都是不变的。
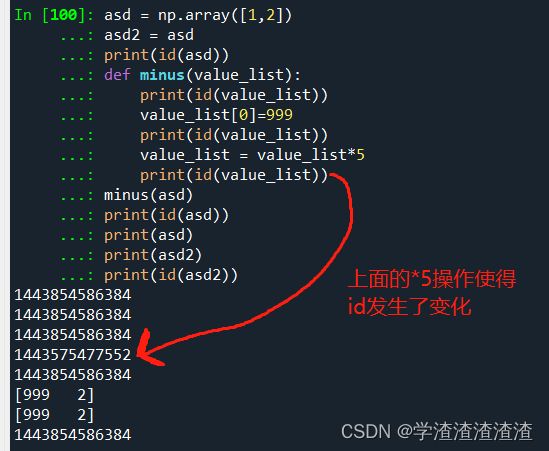
6.4 操作也会影响参数传递
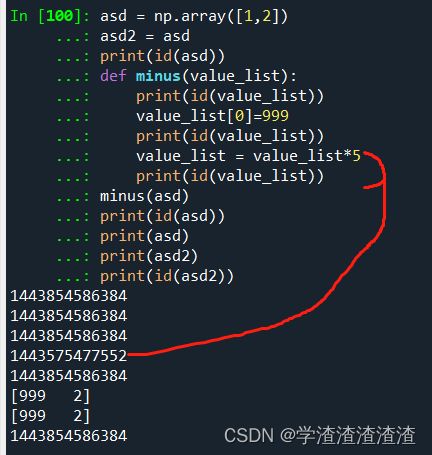
我们知道,数组某个元素的修改不会导致数组的id 发生变化,但是如果是数组整体的赋值,则会发生变化:
asd = np.array([1,2])
asd2 = asd
print(id(asd))
def minus(value_list):
print(id(value_list))
value_list[0]=999
print(id(value_list))
value_list = value_list*5
print(id(value_list))
minus(asd)
print(id(asd))
print(asd)
print(asd2)
print(id(asd2))