CMU15445 2021
CMU15445 2021
-
-
- 写在前面
- C++ primer
-
- 语法点
- buffer pool
-
- debug
- Gradescope测试
- 代码修改
- hash index
-
- directory类
- bucket类
- 实现提示
- hash table类
- 自己写的测试用例及说明
- 测试方法说明
- query execution
-
- RID特别说明(更新)
- SEQUENTIAL SCAN
- INSERT / UPDATE / DELETE
- NESTED LOOP JOIN / HASH JOIN
- 其余Executor
- 索引
- 本地测试与gradescope测试
- concurrency control
-
- 中止事务
- 参考代码
- 8-10更新/在线测试文件获取
- 2020 b+树
- 写在后面
-
- 参考博客
-
写在前面
lab地址
讲义地址
推荐书籍:
《数据库系统概念》 / 《Database-System-Concepts》
中文版有许多删减和错误,英文版看起来又费劲。
数据密集型应用设计
《C++ primer》,Google 开源项目风格指南,
Effective系列(Effective c++,Effective STL,Effective modern c++)
由于刚开始不知道咋注册Gradescope,就只通过了本地的测试用例,做完了3个实验后才开始提交Gradescope。Gradescope的注册邀请码为4PR8G5,学校填Carnegie Mellon University就可以了。实际上这个在FAQ提到了,以前没看。CMU 15445 faq
同时可以看看这个博客CMU 15-445:知名教授历时多年打磨,数据库神级课程限时免费!,里面的课程群有相应的测试用例。另外加入Discord Channel看看别人问的问题等等。
代码Q群自取:237108591,如有任何问题,望请告知!
C++ primer
test/primer/starter_test.cpp:测试代码
src/include/primer/p0_starter.h:实现代码
在实现完代码功能后,去掉测试代码中的DISABLED_前缀,进行测试。我一般都是一边看着测试代码,一边看测试输出,看看是代码哪块出了问题。测试成功之后使用以下命令调整代码格式。
# check.sh
make format
make check-lint -j12
make check-clang-tidy -j12
可以把以上这几个命令写成脚本,省的一次一次打,也可以把压缩proj的命令写成脚本,便于执行
模板类继承模板类 子类看不到父类成员
RowMatrix使用Matrix的成员变量需加上Matrix::
C++的模板中的名称会进行两次查找,称为两阶段查找(two-phase lookup)。对于一个非依赖型名称(不以任何方式依赖于模板参数的名称),在模板声明进行解析的时候就会进行查找。但C++标准中规定(14.6.2 3),一个非受限的名称查找的时候将不会考虑依赖型的基类。因为有偏特化,所以一个模板子类其实是不能在实例化之前就知道他的模板父类到底是谁,因此名字也无法resolve,所以只能this->了。不过VC++有个小扩展,允许你不使用this->就可以调用父类的名字,特别方便。由此可见,其实也是完全可以做到的。
Effective C++ 210页:因为base class templates有可能被特化,而那个特化版本可能不提供和一般性template相同的接口。因为编译器往往拒绝在模板化基类内寻找继承而来的名称。(好像仅仅解释了方法,没解释成员变量)
查找不到就会错误。解决办法是把它变成一个依赖型名称:
在x前加
- this->或者Parent::
- 子类中添加using Parent::x;
模板类继承模板类 子类看不到父类成员
提交后发现的问题:
GEMM函数里调用Add函数写成了ADD
语法风格问题
1 条件语句中直接用布尔变量,不需要写布尔值
if(ret==true) -> if(ret)
实际上我觉得加上布尔值加强了可读性(软件工程)

readability-simplify-boolean-expr
2 即使if语句后只有一条语句,也需要用大括号括起来
3 注释后空格再加文字
// comment
语法点
#pragma once
#pragma once一般由编译器提供保证:同一个文件不会被包含多次。这里所说的”同一个文件”是指物理上的一个文件,而不是指内容相同的两个文件。无法对一个头文件中的一段代码作#pragma once声明,而只能针对文件。
nullptr
C语言中常数0和(void*)0都是空指针常量;C++中(暂且忽略C++11)常数0是,而(void*)0 不是。因为C语言中任何类型的指针都可以(隐式地)转换为void*型,反过来也行,而C++中void*型不能隐式地转换为别的类型指针。
#if defined(__cplusplus)
# define NULL 0 // C++中使用0作为NULL的值
#else
# define NULL ((void *)0) // C中使用((void *)0)作为NULL的值
#endif
#include 从字面上来讲,NULL是个空指针常量,我们可能会觉得:既然是个指针,那么应该调用#2。但事实上调用的却是#1,因为C++中NULL扩展为常数0,它是int型。
根本原因就是:常数0既是整数常量,也是空指针常量。
为了解决这种二义性,C++11标准引入了关键字nullptr,它作为一种空指针常量
NULL、0、nullptr的区别
return {}
return {};表示“返回用空 list-initializer 初始化的函数返回类型的对象”。确切的行为取决于返回对象的类型。
Effective modern c++ item21: 优先考虑使⽤std::make_unique和std::make_shared而⾮new
buffer pool
实验背景:
BufferManager运行时内部维护一份高速缓存,其中有些page是正在被使用的,有些page是不被使用但但仍有意义的(unpinned),Repalcer则是维护那些unpinned page,在必要的时候将其中某些page替换出去。
《数据库系统概念》10.8.1缓冲区管理器:
被钉住的块(pinned block):为了使数据库系统能够从系统崩溃中恢复,限制一个块写回磁盘的时间是十分必要的。例如:当一个块上更新操作正在进行时,大多数恢复系统不允许该块写回磁盘。不允许写回磁盘的块称为被钉住的(pinned)的块。
page_id和frame_id:
前者指的是某一个page编号,比如disk上第十个page;后者指的是BufferPoolManager中的页框号码。
前者需要通过disk层获取,后者是BufferPoolManager中固定的,从0开始。
《CMU15445》 && [BufferPoolManager]
在函数中我大多使用lock_guard进行加锁,只是为了图方便,也不知道是否实现了线程安全。但一个持有锁的函数调用另一个加锁的函数会造成死锁,可以使用recursive_mutex解决该问题,但我后面才知道recursive_mutex,懒得再改了。
[c++] 同一线程两次加锁可能导致死锁问题
c++11 std::recursive_mutex
LRU Replacement Policy
根据测试代码推出,对同一个元素调用两次unpin函数,第二次无效
Buffer Pool Manager Instance
这个部分我都是按照给出的提示写的,倒也没太大问题,就是刚开始都没发现要用disk_manager_成员,要修改Page,后面简单看了这两个类的定义才正确实现了函数的功能。
Parallel Buffer Pool Manager
这个部分功能本来是最简单的,调用一下第二部分的代码就结束了。然而当时写的太快,一些符号写错了。
do {
page = instances_[index]->NewPage(page_id);
if (page != nullptr) {
start_index_ = (start_index_ + 1) % num_instances_;
return page;
}
index = (index + 1) % num_instances_;
} while (index != start_index_);
//其中索引加1时 = 写成了 +=
bool ParallelBufferPoolManager::FlushPgImp(page_id_t page_id) {
// Flush page_id from responsible BufferPoolManagerInstance
BufferPoolManager *manager = GetBufferPoolManager(page_id);
return manager->FlushPage(page_id);
}
//其中manager->FlushPage(page_id);写成了manager->FetchPage(page_id);
这就引来了一堆错误,一进行测试就产生段错误(数组越界)。然后就开始了几小时的debug。我觉得这过程还比较有纪念意义的,故记录在此。
debug
1 mkdir build_debug #创建专用于debug的文件夹
2 cmake -DCMAKE_BUILD_TYPE=DEBUG .. #看CMakeLists.txt实际上就是加了一个-g选项,生成调试信息。
# CMakeLists.txt
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -fPIC -Wall -Wextra -Werror -march=native")
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -Wno-unused-parameter -Wno-attributes") #TODO: remove
set(CMAKE_CXX_FLAGS_DEBUG "${CMAKE_CXX_FLAGS_DEBUG} -O0 -ggdb -fsanitize=address -fno-omit-frame-pointer -fno-optimize-sibling-calls")
set(CMAKE_EXE_LINKER_FLAGS "${CMAKE_EXE_LINKER_FLAGS} -fPIC")
set(CMAKE_SHARED_LINKER_FLAGS "${CMAKE_SHARED_LINKER_FLAGS} -fPIC")
set(CMAKE_STATIC_LINKER_FLAGS "${CMAKE_STATIC_LINKER_FLAGS} -fPIC")
3 make parallel_buffer_pool_manager_test -j12
段错误实际上是最好调试的(我gbd就会几个命令)
gdb./test/parallel_buffer_pool_manager_test
r # 执行
bt # 查看调用栈
frame n # 转到栈n的上下文
p var # 输出变量值
通过以上这几个步骤我那个=误写成+=的错误就被找出来了。而FlushPage不小心写成FetchPage的错误就非常难找的(vscode自动补全)。
//parallel_buffer_pool_manager_test.cpp
for (int i = 0; i < 5; ++i) {
EXPECT_EQ(true, bpm->UnpinPage(i, true));
bpm->FlushPage(i);
}
for (int i = 0; i < 5; ++i) {
EXPECT_NE(nullptr, bpm->NewPage(&page_id_temp));
bpm->UnpinPage(page_id_temp, false);
}
测试代码段的大意为:通过5次UnpinPage操作,应该多了5个可被淘汰的页,也就能新建5个新页。
运行测试代码时,EXPECT_NE(nullptr, bpm->NewPage(&page_id_temp));一行报错。在此打断点(b parallel_buffer_pool_manager_test.cpp:73)后发现仅仅第一次时报错,后续4次成功。当然这是74行再次调用UnpinPage函数的结果。这也就是说第一个for循环并没有成功将5页放入replacer中,所以我错误地一直研究UnpinPage函数的调用路径。
gdb./test/parallel_buffer_pool_manager_test
b parallel_buffer_pool_manager_test.cpp:73
r # 执行
n # 下一步,但不进入函数
s # 下一步,进入函数
c # 下一个断点
在设置许多个printf语句,通过n或s进入UnpinPage函数内部执行路径,一直没有发现问题。而后直接在测试代码处查看UnpinPage是否改变了相应replacer的size,没想到居然改变了,而执行完bpm->FlushPage(i);
后又变成0了,我就知道是FlushPage函数的问题,稍微检查一下后即发现是拼写错误。流程如下
gdb ./test/parallel_buffer_pool_manager_test
b parallel_buffer_pool_manager_test.cpp:69
r
#69 EXPECT_EQ(true, bpm->UnpinPage(i, true));
p bpm->instances_ [0]->replacer_ ->Size()
#0
n
#70 bpm->FlushPage(i);
p bpm->instances_ [0]->replacer_ ->Size()
#1
n
#68 for (int i = 0; i < 5; ++i) {
p bpm->instances_ [0]->replacer_ ->Size()
#0
这也算一次比较奇葩的经历。在debug这个之后,编译器提示内存泄漏,显示我在构造函数申请的空间没有释放,这是因为我析构函数刚开始只有delete[] instances_;,我以为这样能顺带把指针数组里指向的对象也释放掉呢。实际上用了多少次new,就要使用多少次delete。
ParallelBufferPoolManager::ParallelBufferPoolManager(size_t num_instances, size_t pool_size, DiskManager *disk_manager,
LogManager *log_manager) {
// Allocate and create individual BufferPoolManagerInstances
num_instances_ = num_instances;
pool_size_ = pool_size;
start_index_ = 0;
instances_ = new BufferPoolManagerInstance *[num_instances];
for (size_t i = 0; i < num_instances; i++) {
instances_[i] = new BufferPoolManagerInstance(pool_size, num_instances, i, disk_manager, log_manager);
}
}
ParallelBufferPoolManager::~ParallelBufferPoolManager() {
for (size_t i = 0; i < num_instances_; i++) { //释放指针所指对象空间
delete instances_[i];
}
delete[] instances_; //释放指针空间
}
Gradescope测试
在知道如何注册Gradescope后, 我将我的代码提交到Gradescope,结果只得了85分。分别是
// test_build显示的报错信息
#RoundRobinNewPage
Expected equality of these values:
unpin_page + num_instances
Which is: 11
page_id_temp
Which is: 13
起始索引问题
#test_memory_safety
Timeout Happened during valgrind
执行时间太长?
#ParallelBufferPoolManager_HardTestD
由于我的FlushPgImp中只对脏页进行写入,而该测试中并未将需写回的页设置为脏页,故使得预期数据不一致
page = bpm->NewPage(&temp_page_id, nullptr);
while (page == nullptr) {
page = bpm->NewPage(&temp_page_id, nullptr);
}
EXPECT_NE(nullptr, page);
ASSERT_NE(nullptr, page);
strcpy(page->GetData(), std::to_string(temp_page_id).c_str()); // NOLINT
// FLush page instead of unpining with true
EXPECT_EQ(1, bpm->FlushPage(temp_page_id, nullptr));
EXPECT_EQ(1, bpm->UnpinPage(temp_page_id, false, nullptr));
3个测试没通过
如果编译通过但测试一个没过有可能就是死锁了。修改代码后先通过本地样例,再进行格式调整,再进行提交
1 我认为LRUReplacer中的容量是没什么用的,因为replacer_和pages_的大小一样,不可能超过
2 为减少执行时间,将LRUReplacer的实现从普通的链表变成链表+map(降低时间复杂度),但我当时为了通过RoundRobinNewPage,map的value是pair,bool表示该项是否存在,实际上这是没必要的,用iterator当value就可以了
(我后面又改回去了,这种形式可读性不强,还是迭代器为value值更好看)
// using IteratorPair = std::pair::iterator>;
// std::unordered_map map_;
std::mutex lock_;
std::list<frame_id_t> data_;
std::unordered_map<frame_id_t, std::list<frame_id_t>::iterator> map_;
// size_t capacity_;
3 DeletePgImp中同时把replacer里的页删去(好像没影响)
4 NewPgImp中创建新页后立即写入磁盘,防止被淘汰后找不到页号(我没改也过了全部测试)
5 ParallelBufferPoolManager::NewPgImp中的起始索引,我改了半天,最后发现调换个位置就成了。
size_t index = start_index_;
// printf("index is %ld\n",index);
do {
page = instances_[index]->NewPage(page_id);
if (page != nullptr) {
// 原先在这增加起始索引
break;
}
index = (index + 1) % num_instances_;
} while (index != start_index_);
// 改到这里
start_index_ = (start_index_ + 1) % num_instances_;
代码修改
看完Effective系列的书后,回过头来修改之前写过的代码。
push_back()改成 emplace_back()
当给map添加一个元素时,我们断定insert比operator[]好;当更新已经在map里的元素值时operator[]更好
测试存在性时,如果是map,count方法好,multimap的话,find好
在我写代码时,80%的bug来自于while循环最后忘了修改迭代器的值,
所以我觉得for循环比while循环更好一点,这样就不会忘了修改迭代器。
// while循环
auto iter = page_table_.cbegin();
while (iter != page_table_.cend()) {
page_id = iter->first;
frame_id = page_table_[page_id];
if (pages_[frame_id].IsDirty()) {
disk_manager_->WritePage(page_id, pages_[frame_id].data_);
pages_[frame_id].is_dirty_ = false;
}
++iter;
}
// for循环
for (auto iter = page_table_.cbegin(); iter != page_table_.cend(); ++iter) {
page_id = iter->first;
frame_id = page_table_[page_id];
if (pages_[frame_id].IsDirty()) {
disk_manager_->WritePage(page_id, pages_[frame_id].data_);
pages_[frame_id].is_dirty_ = false;
}
}
// 范围for语句
for (const auto &item : page_table_) {
page_id = item.first;
frame_id = page_table_[page_id];
if (pages_[frame_id].IsDirty()) {
disk_manager_->WritePage(page_id, pages_[frame_id].data_);
pages_[frame_id].is_dirty_ = false;
}
}
迭代器用前自增效率更高一点
前自增运算符改变了对象的状态并返回对象改变后的状态,不需要创建临时对象。下面是前自增运算符的例子:
MyOwnClass& operator++()
{
++meOwnField;
return (*this);
}
后自增运算符也改变了对象的状态但是返回的是对象改变前的状态,并且需要创建一个临时对象。下面是后自增运算符重载的例子:
MyOwnClass operator++(int)
{
MyOWnCLass tmp = *this;
++(*this);
return tmp;
}
class Step{
private:
int num;
public:
Step(int num) {this->num = num;}
int getStep() {return num;}
Step& operator++(); //重载前自增运算符
Step operator++(int); //重载后自增运算符
};
Step& Step::operator++(){
num++;
return *this;
}
Step Step::operator++(int){
Step temp = *this;
++ *this;
return temp;
}
DeletePgImp函数需调用DeallocatePage函数,不用写回磁盘
虽然DeallocatePage函数并没有实现
/**
* Deallocate a page on disk.
* @param page_id id of the page to deallocate
*/
void DeallocatePage(__attribute__((unused)) page_id_t page_id) {
// This is a no-nop right now without a more complex data structure to track deallocated pages
}
迭代器记得增加
测试通过截图

attribute
GNU C 的一大特色就是__attribute__ 机制。attribute 可以设置函数属性(Function Attribute)、变量属性(Variable Attribute)和类型属性(Type Attribute)。
其位置约束为: 放于声明的尾部“;” 之前
attribute 书写特征为: attribute 前后都有两个下划线,并切后面会紧跟一对原括弧,括弧里面是相应的__attribute__ 参数。
attribute 语法格式为: attribute ((attribute-list))
attribute((unused)) 其作用是即使没有使用这个函数,编译器也不警告。
hash index
为方便起见,用directory代表HashTableDirectoryPage类,用bucket代表HashTableBucketPage,用hash table表示ExtendibleHashTable类
由于刚开始没看啥是可扩展的动态哈希,一直没看懂第一部分的代码在讲啥,特别是VerifyIntegrity 函数的三个限制:
(1) All LD <= GD.
(2) Each bucket has precisely 2^(GD - LD) pointers pointing to it.
(3) The LD is the same at each index with the same bucket_page_id
在了解可扩展动态哈希是啥后才明白这3个限制的含义参考博客,所以一定要充分理解动态哈希的过程!!!,可以阅读《数据密集型应用设计》存储与检索一章

但我还是没怎么懂为啥local depth和global depth要用不同类型的变量存储。
uint32_t global_depth_{0};
uint8_t local_depths_[DIRECTORY_ARRAY_SIZE];
更新:
《数据库系统概念》11.7 动态散列:
当数据库增大或缩小时,可扩充散列(extendable hash)可以通过桶的分裂或合并来适应数据库大小的变化。这样就可以保持空间的使用效率。此外,由于重组每次仅作用于一个桶,因此所带来的性能开销较低,可以接受。
在更新操作时,如果插入的桶已满,系统必须分裂这个桶并将该桶中现有记录和新记录一起进行重新分配。而后系统再次尝试新记录。通常该尝试会成功。但是,如果桶中所有记录与新插入的记录具有相同的散列值前缀,该桶就必须再次分裂,这是因为所有记录与新记录再次被分配到同一个桶中。
我写完全部代码很久后才知道原来15445还有教科书,代码里也没对上述情况进行处理,也懒得改了。
directory类
测试第一部分的代码是test/container/hash_table_page_test.cpp,我觉得提前阅读一遍测试代码是很有帮助的,可以在测试代码中看类的使用。而且建议在写第一部分的时候就将整个实验介绍看完,有些内容在后面才介绍。第一部分的代码实现过于简单,以至于我一直觉得实现的有问题(CanShrink GetSplitImageIndex两个可选函数未实现,留给第二部分实现)。
CanShrink: 判断是否可以收缩全局深度,即判断是否所有局部深度都小于全局深度
GetSplitImageIndex:当一个桶为空需要合并时,寻找与其对应的桶的索引,即将索引最高位取反(并不准确,应该是局部深度的最高位)
uint32_t HashTableDirectoryPage::GetSplitImageIndex(uint32_t bucket_idx) { // 得到与该桶对应的桶,即将该桶最高位置反
uint32_t local_depth = GetLocalDepth(bucket_idx);
uint32_t local_mask = GetLocalDepthMask(bucket_idx);
if (local_depth == 0) {
return 0;
}
return (bucket_idx ^ (1 << (local_depth - 1))) & local_mask;
// 假设只有两个桶 0 1,深度皆为1,则0 ^ (1<<(1-1)) = 1
// 假设桶11深度为1,,则其实际上用到的位为1,对应的桶即为0 11 ^ 1 & 1 = 0
// 但实际上返回10也无所谓,因为二者深度相等才进行合并操作
// 当只有一个桶时返回本身
}
bucket类
array_[0]为零长数组,其大小为BUCKET_ARRAY_SIZE
#define MappingType std::pair<KeyType, ValueType>
#define BUCKET_ARRAY_SIZE (4 * PAGE_SIZE / (4 * sizeof(MappingType) + 1))
关于零长数组的介绍可看这篇博客blog,另外cmp比较类相等时返回0。
class IntComparator {
public:
inline int operator()(const int lhs, const int rhs) const {
if (lhs < rhs) {
return -1;
}
if (rhs < lhs) {
return 1;
}
return 0;
}
};
occupied_成员表示数组该位是否被使用过,可用来提前结束循环。假设顺序寻找数组中的元素,若occupied_[i]为0代表后面没元素了,可以中止寻找了。
readable_成员表示数组该位当前是否存在元素。当需要删除某个元素时,将readable_置为0,occupied_不变。
将数组类型设置为unsigned char可以避免很多问题
实现提示
Insert方法首先需要遍历数组,看是否存在元素与插入元素一致,而后再寻找插入位置,插入该元素。可以将寻找相同元素和寻找插入位置两件事在一次遍历时完成。
巨坑的点
在我通过全部本地测试,将代码上传到gradescope测试时,开始没啥问题,看测试输出就可以知道哪些方面没有考虑到,在代码到70分时,我无意间改了一小部分,gradescope运行40分钟未出结果,显示运行超时
Your submission timed out. It took longer than 2400 seconds to run.
在我后面排查时我发现原因是一个很小的改动(if 改成 else if)。
if (IsReadable(i) && cmp(array_[i].first, key) == 0 && array_[i].second == value) {
return false;
}
if (!IsReadable(i)) {
if (insert_index == bucket_array_size) {
insert_index = i;
}
if (!IsOccupied(i)) { // 结束寻找
break;
}
}
改成
if (IsReadable(i) && cmp(array_[i].first, key) == 0 && array_[i].second == value) {
return false;
}
else if (!IsReadable(i)) {
if (insert_index == bucket_array_size) {
insert_index = i;
}
if (!IsOccupied(i)) { // 结束寻找
break;
}
}
现在想来有点手贱,但这个改动对代码的执行流程没有任何影响,我一直想不通为什么会超时,在将所有锁都去掉后提交还是显示超时,我认为代码执行超时要么是死锁,要么是死循环,但我把在代码看麻了也没看出哪里出现了问题,而后我放弃hash index,先写后面的部分。而后我在虚拟机里运行这些代码,发现这部分代码竟然报错,也就是前面的readability-simplify-boolean-expr错误
但我之前进行语法检查时并没有报错!!!,所以超时有可能有3个原因:死锁,死循环,语法风格问题,所以说不能太相信语法检查,可以自己检查一下。。。。(因为这个我提交了十几次,气!)
IsOccupied等方法对位进行操作,IsFull NumReadable等方法对数进行操作
NumReadable方法可以用 n & n-1 方法统计数字n中1的数目。
IsFull 需要对最后一个数的部分位进行检查
template <typename KeyType, typename ValueType, typename KeyComparator>
void HASH_TABLE_BUCKET_TYPE::SetUnreadable(uint32_t bucket_idx) {
uint32_t index = bucket_idx / 8;
uint32_t offset = bucket_idx % 8;
readable_[index] &= ~(1 << offset);
}
template <typename KeyType, typename ValueType, typename KeyComparator>
bool HASH_TABLE_BUCKET_TYPE::IsFull() {
uint32_t exact_div_size = BUCKET_ARRAY_SIZE / 8;
for (uint32_t i = 0; i < exact_div_size; i++) {
if (readable_[i] != static_cast<char>(0xff)) {
return false;
}
}
uint32_t rest = BUCKET_ARRAY_SIZE - BUCKET_ARRAY_SIZE / 8 * 8;
// 在这里我觉得BUCKET_ARRAY_SIZE / 8更好,但check-clang-tidy会报错,故使用(BUCKET_ARRAY_SIZE - 1) / 8
// (rest=0时数组越界) check-clang-tidy报redundant boolean literal in conditional return statement错误,只能写成一行了
/*
if (rest != 0 && readable_[(BUCKET_ARRAY_SIZE - 1) / 8] != static_cast((1 << rest) - 1)) {
return false;
}
return true;
*/
return !(rest != 0 && readable_[(BUCKET_ARRAY_SIZE - 1) / 8] != static_cast<char>((1 << rest) - 1));
}
不得不说,语法风格检查有时候挺鸡肋的。
hash table类
在编写这部分的代码时,请记住以下几个要点
- 不能单独增加某一个local depth或bucket_page_ids,需要进行遍历将属于同一个page id的local depth bucket_page_ids全部改变
- 用完页时需要及时释放,当遇到条件分支时,检查是否所有分支都正常释放了
- 桶分裂时按全局深度是否改变两种情况分
- 合并时注意循环合并情况
递归合并的说明:
合并的条件有3个,桶为空,局部深度大于0,对应桶的深度一致。
当对应桶的深度不一致时,这个桶应该什么时候合并呢?例如00 10对应一个桶,01 11对应两个桶,当00 10的桶为空时,其另一半的桶深度与其不一致。那当01 11两桶合并之后,也应该将00 10的桶合并起来。推广便知,这是一个循环的过程(gradescope只测试了单层)
if (ret && bucket_page->IsEmpty()) {
// printf("start merge\n");
Merge(transaction, key, value);
while (ExtraMerge(transaction, key, value)) {
}
}
难点就是桶分裂与桶合并两个函数,其他的注意使用什么锁即可,table_latch锁住目录,(bucket_page)->WLatch锁住bucket。
我认为在table_latch使用写锁时,bucket不用进行加锁,但测试跑不过(一直没出结果,应该是G了),所以还是加上吧,如有懂的望请告知
当table_latch使用写锁时,应该只存在一个进程访问,那桶加锁不加锁不是没啥影响吗?
更新:我的问题,锁顺序问题导致死锁
分裂的大致流程如下:
旧桶指分裂前索引指向的桶
新桶指申请的新桶
将所有仍指向旧桶的位置深度加一
如果不影响目录大小:
将现在指向新桶的位置设置新的page id,深度加一
如果影响目录大小:
目录变成之前的两倍,即上半部与下半部
下半部除新桶以外,与上半部完全一致,新桶设置新的page id
这里需要对下半部的所有位置进行处理
删除旧桶中本该在新桶的元素,并将其插入在新桶中
进行正常的插入操作
合并的大致流程如下:
检查是否可以发生合并
将所有指向空桶的位置都指向对应桶
删除该桶(提前unpin)
将所有指向对应桶的位置深度减一
看是否能降低全局深度
进行额外的合并
合并与分裂需要非常的细心,可以使用后面的测试用例判断执行流程是否符合预期,加油!
测试通过截图:

排名不高,懒得优化了,这部分代码看麻了。。。

怎么哪里都有嘉心糖捏?
其他:
我认为将目录页缓存起来能极大提高性能,避免一次一次访问目录页,但测试代码的逻辑不允许,在析构函数中unpin page会报错(此时已经被delete)
warning "will be initialized after [-Wreorder]
构造函数时,初始化成员变量的顺序要与类声明中的变量顺序相对应,若不对应,则出现如题错误。解决方法就是按照顺序进行初始化。
在处理分裂逻辑时,写过一个这样的代码,我想通过提前申请桶的写锁的方法减小锁的影响范围,但一直死锁
SplitInsert:
table_latch_.WLock();
处理目录相关逻辑
// 申请新桶旧桶的写锁
reinterpret_cast<Page *>(old_bucket_page)->WLatch();
reinterpret_cast<Page *>(new_bucket_page)->WLatch();
table_latch_.WUnlock();
// 对目录的操作完成,持有新桶旧桶的写锁后改用读锁,迁移桶内数据
table_latch_.RLock();
reinterpret_cast<Page *>(old_bucket_page)->WUnlatch();
reinterpret_cast<Page *>(new_bucket_page)->WUnlatch();
table_latch_.RUnlock();
后面才想明白死锁的原因:多个线程同时执行SplitInsert函数,线程1持有WLock请求WLatch,线程2持有WLatch请求RLock。
我一般判断是否发生死锁都与其他函数进行比较,却忽略了相同函数执行时带来的死锁问题。
所以说加锁解锁不对称的顺序很容易造成死锁问题。
自己写的测试用例及说明
在遇到之前提到的超时情况时,由于等gradescope出结果太慢(提交一次20-40分钟),我便产生了自己写测试用例的想法,刚开始想写并发的插入删除,但写完之后发现并不能测出什么东西来,并发时顺序很难控制,而且后面想了想,只要加锁解锁正确,并发访问与普通访问也没啥区别,而加锁的部分也不太复杂,所以应该将重点放在普通的访问上。
以下是我写的两个测试用例,主要是检查分裂合并是否合乎预期,以及是否正确释放页
/*
只测试两个桶
*/
TEST(HashTableTest, MySplitShrinkTest1) {
auto *disk_manager = new DiskManager("test.db");
auto *bpm = new BufferPoolManagerInstance(50, disk_manager);
ExtendibleHashTable<int, int, IntComparator> ht("blah", bpm, IntComparator(), HashFunction<int>());
printf("block size is: %ld\n", (4 * PAGE_SIZE / (4 * sizeof(std::pair<int, int>) + 1))); // 桶容量
// 插入496个值
for (int i = 0; i < 496; i++) {
ht.Insert(nullptr, i, i);
}
ht.PrintDir(); // 输出目录信息
ht.Insert(nullptr, 496, 496); // 桶分裂
EXPECT_EQ(bpm->GetOccupiedPageNum(), 0); // 无论何时,被占用的页都应该为0
EXPECT_EQ(ht.GetGlobalDepth(), 1);
ht.PrintDir();
ht.RemoveAllItem(nullptr, 1); // 删除索引1对应的桶的所有项
EXPECT_EQ(bpm->GetOccupiedPageNum(), 0);
ht.PrintDir();
ht.RemoveAllItem(nullptr, 0); // 删除索引0对应的桶的所有项
EXPECT_EQ(bpm->GetOccupiedPageNum(), 0);
ht.PrintDir();
disk_manager->ShutDown();
remove("test.db");
delete disk_manager;
delete bpm;
}
/*
测试4个桶
*/
TEST(HashTableTest, MySplitShrinkTest2) {
auto *disk_manager = new DiskManager("test.db");
auto *bpm = new BufferPoolManagerInstance(50, disk_manager);
ExtendibleHashTable<int, int, IntComparator> ht("blah", bpm, IntComparator(), HashFunction<int>());
printf("block size is: %ld\n", (4 * PAGE_SIZE / (4 * sizeof(std::pair<int, int>) + 1)));
// 插入1500个值
for (int i = 0; i < 1500; i++) {
ht.Insert(nullptr, i, i);
}
ht.PrintDir();
ht.RemoveAllItem(nullptr, 0); // 删除索引0对应的桶的所有项
EXPECT_EQ(bpm->GetOccupiedPageNum(), 0);
ht.PrintDir();
ht.RemoveAllItem(nullptr, 0); // 再次删除索引0对应的桶的所有项
EXPECT_EQ(bpm->GetOccupiedPageNum(), 0);
bpm->PrintExistPageId(); // 输出缓冲池中页的状态
ht.PrintDir();
ht.RemoveAllItem(nullptr, 1); // 删除索引1对应的桶的所有项,应该发生递归合并
EXPECT_EQ(ht.GetGlobalDepth(), 0);
EXPECT_EQ(bpm->GetOccupiedPageNum(), 0);
ht.PrintDir();
disk_manager->ShutDown();
remove("test.db");
delete disk_manager;
delete bpm;
}
测试方法说明
BufferPoolManagerInstance类设置了两个测试方法,分别输出被占用的页数以及缓冲池中页的状态
size_t GetOccupiedPageNum() { return page_table_.size() - replacer_->Size(); }
void PrintExistPageId() {
for (auto item : page_table_) {
printf("page id is:%d pin count is %d\n", item.first, pages_[item.second].pin_count_);
}
}
page id is:4 pin count is 0
page id is:3 pin count is 0
page id is:2 pin count is 0
page id is:0 pin count is 0
其中PrintDir方法输出内容如下:
// 测试方法
template <typename KeyType, typename ValueType, typename KeyComparator>
void HASH_TABLE_TYPE::PrintDir() {
table_latch_.RLock();
HashTableDirectoryPage *dir_page = FetchDirectoryPage();
uint32_t dir_size = dir_page->Size();
dir_page->PrintDirectory();
printf("dir size is: %d\n", dir_size);
for (uint32_t idx = 0; idx < dir_size; idx++) {
auto bucket_page_id = dir_page->GetBucketPageId(idx);
HASH_TABLE_BUCKET_TYPE *bucket_page = FetchBucketPage(bucket_page_id);
bucket_page->PrintBucket();
buffer_pool_manager_->UnpinPage(bucket_page_id, false, nullptr);
}
assert(buffer_pool_manager_->UnpinPage(directory_page_id_, false, nullptr));
table_latch_.RUnlock();
}
2022-02-28 14:47:41 [root/code/CMU1445/vm/vm-CMU1445/bustub/src/storage/page/hash_table_directory_page.cpp:139:PrintDirectory] DEBUG - ======== DIRECTORY (global_depth_: 2) ========
2022-02-28 14:47:41 [root/code/CMU1445/vm/vm-CMU1445/bustub/src/storage/page/hash_table_directory_page.cpp:140:PrintDirectory] DEBUG - | bucket_idx | page_id | local_depth |
2022-02-28 14:47:41 [root/code/CMU1445/vm/vm-CMU1445/bustub/src/storage/page/hash_table_directory_page.cpp:142:PrintDirectory] DEBUG - | 0 | 3 | 1 |
2022-02-28 14:47:41 [root/code/CMU1445/vm/vm-CMU1445/bustub/src/storage/page/hash_table_directory_page.cpp:142:PrintDirectory] DEBUG - | 1 | 4 | 2 |
2022-02-28 14:47:41 [root/code/CMU1445/vm/vm-CMU1445/bustub/src/storage/page/hash_table_directory_page.cpp:142:PrintDirectory] DEBUG - | 2 | 3 | 1 |
2022-02-28 14:47:41 [root/code/CMU1445/vm/vm-CMU1445/bustub/src/storage/page/hash_table_directory_page.cpp:142:PrintDirectory] DEBUG - | 3 | 2 | 2 |
2022-02-28 14:47:41 [root/code/CMU1445/vm/vm-CMU1445/bustub/src/storage/page/hash_table_directory_page.cpp:144:PrintDirectory] DEBUG - ================ END DIRECTORY ================
dir size is: 4
2022-02-28 14:47:41 [root/code/CMU1445/vm/vm-CMU1445/bustub/src/storage/page/hash_table_bucket_page.cpp:205:PrintBucket] INFO - Bucket Capacity: 496, Size: 352, Taken: 0, Free: 352
2022-02-28 14:47:41 [root/code/CMU1445/vm/vm-CMU1445/bustub/src/storage/page/hash_table_bucket_page.cpp:205:PrintBucket] INFO - Bucket Capacity: 496, Size: 335, Taken: 335, Free: 0
2022-02-28 14:47:41 [root/code/CMU1445/vm/vm-CMU1445/bustub/src/storage/page/hash_table_bucket_page.cpp:205:PrintBucket] INFO - Bucket Capacity: 496, Size: 352, Taken: 0, Free: 352
2022-02-28 14:47:41 [root/code/CMU1445/vm/vm-CMU1445/bustub/src/storage/page/hash_table_bucket_page.cpp:205:PrintBucket] INFO - Bucket Capacity: 496, Size: 496, Taken: 384, Free: 112
最关键的便是RemoveAllItem方法,这个是将桶的所有元素全部删除,首先需要bucket类返回所有元素,然后对这些元素依次调用remove方法。
template <typename KeyType, typename ValueType, typename KeyComparator>
std::vector<MappingType> HASH_TABLE_BUCKET_TYPE::GetAllItem() {
uint32_t bucket_size = BUCKET_ARRAY_SIZE;
std::vector<MappingType> items;
items.reserve(bucket_size);
for (uint32_t i = 0; i < bucket_size; i++) {
if (IsReadable(i)) {
items.emplace_back(array_[i]);
}
}
return items;
}
template <typename KeyType, typename ValueType, typename KeyComparator>
void HASH_TABLE_TYPE::RemoveAllItem(Transaction *transaction, uint32_t bucket_idx) {
table_latch_.RLock();
HashTableDirectoryPage *dir_page = FetchDirectoryPage();
auto bucket_page_id = dir_page->GetBucketPageId(bucket_idx);
HASH_TABLE_BUCKET_TYPE *bucket_page = FetchBucketPage(bucket_page_id);
auto items = bucket_page->GetAllItem();
buffer_pool_manager_->UnpinPage(bucket_page_id, false, nullptr);
table_latch_.RUnlock();
for (auto &item : items) {
Remove(nullptr, item.first, item.second);
}
buffer_pool_manager_->UnpinPage(directory_page_id_, false, nullptr);
}
MySplitShrinkTest2的结果如下:
block size is: 496
2022-02-28 14:47:41 [root/code/CMU1445/vm/vm-CMU1445/bustub/src/storage/page/hash_table_directory_page.cpp:139:PrintDirectory] DEBUG - ======== DIRECTORY (global_depth_: 2) ========
2022-02-28 14:47:41 [root/code/CMU1445/vm/vm-CMU1445/bustub/src/storage/page/hash_table_directory_page.cpp:140:PrintDirectory] DEBUG - | bucket_idx | page_id | local_depth |
2022-02-28 14:47:41 [root/code/CMU1445/vm/vm-CMU1445/bustub/src/storage/page/hash_table_directory_page.cpp:142:PrintDirectory] DEBUG - | 0 | 1 | 2 |
2022-02-28 14:47:41 [root/code/CMU1445/vm/vm-CMU1445/bustub/src/storage/page/hash_table_directory_page.cpp:142:PrintDirectory] DEBUG - | 1 | 4 | 2 |
2022-02-28 14:47:41 [root/code/CMU1445/vm/vm-CMU1445/bustub/src/storage/page/hash_table_directory_page.cpp:142:PrintDirectory] DEBUG - | 2 | 3 | 2 |
2022-02-28 14:47:41 [root/code/CMU1445/vm/vm-CMU1445/bustub/src/storage/page/hash_table_directory_page.cpp:142:PrintDirectory] DEBUG - | 3 | 2 | 2 |
2022-02-28 14:47:41 [root/code/CMU1445/vm/vm-CMU1445/bustub/src/storage/page/hash_table_directory_page.cpp:144:PrintDirectory] DEBUG - ================ END DIRECTORY ================
dir size is: 4
2022-02-28 14:47:41 [root/code/CMU1445/vm/vm-CMU1445/bustub/src/storage/page/hash_table_bucket_page.cpp:205:PrintBucket] INFO - Bucket Capacity: 496, Size: 496, Taken: 429, Free: 67
2022-02-28 14:47:41 [root/code/CMU1445/vm/vm-CMU1445/bustub/src/storage/page/hash_table_bucket_page.cpp:205:PrintBucket] INFO - Bucket Capacity: 496, Size: 335, Taken: 335, Free: 0
2022-02-28 14:47:41 [root/code/CMU1445/vm/vm-CMU1445/bustub/src/storage/page/hash_table_bucket_page.cpp:205:PrintBucket] INFO - Bucket Capacity: 496, Size: 352, Taken: 352, Free: 0
2022-02-28 14:47:41 [root/code/CMU1445/vm/vm-CMU1445/bustub/src/storage/page/hash_table_bucket_page.cpp:205:PrintBucket] INFO - Bucket Capacity: 496, Size: 496, Taken: 384, Free: 112
2022-02-28 14:47:41 [root/code/CMU1445/vm/vm-CMU1445/bustub/src/storage/page/hash_table_directory_page.cpp:139:PrintDirectory] DEBUG - ======== DIRECTORY (global_depth_: 2) ========
2022-02-28 14:47:41 [root/code/CMU1445/vm/vm-CMU1445/bustub/src/storage/page/hash_table_directory_page.cpp:140:PrintDirectory] DEBUG - | bucket_idx | page_id | local_depth |
2022-02-28 14:47:41 [root/code/CMU1445/vm/vm-CMU1445/bustub/src/storage/page/hash_table_directory_page.cpp:142:PrintDirectory] DEBUG - | 0 | 3 | 1 |
2022-02-28 14:47:41 [root/code/CMU1445/vm/vm-CMU1445/bustub/src/storage/page/hash_table_directory_page.cpp:142:PrintDirectory] DEBUG - | 1 | 4 | 2 |
2022-02-28 14:47:41 [root/code/CMU1445/vm/vm-CMU1445/bustub/src/storage/page/hash_table_directory_page.cpp:142:PrintDirectory] DEBUG - | 2 | 3 | 1 |
2022-02-28 14:47:41 [root/code/CMU1445/vm/vm-CMU1445/bustub/src/storage/page/hash_table_directory_page.cpp:142:PrintDirectory] DEBUG - | 3 | 2 | 2 |
2022-02-28 14:47:41 [root/code/CMU1445/vm/vm-CMU1445/bustub/src/storage/page/hash_table_directory_page.cpp:144:PrintDirectory] DEBUG - ================ END DIRECTORY ================
dir size is: 4
2022-02-28 14:47:41 [root/code/CMU1445/vm/vm-CMU1445/bustub/src/storage/page/hash_table_bucket_page.cpp:205:PrintBucket] INFO - Bucket Capacity: 496, Size: 352, Taken: 352, Free: 0
2022-02-28 14:47:41 [root/code/CMU1445/vm/vm-CMU1445/bustub/src/storage/page/hash_table_bucket_page.cpp:205:PrintBucket] INFO - Bucket Capacity: 496, Size: 335, Taken: 335, Free: 0
2022-02-28 14:47:41 [root/code/CMU1445/vm/vm-CMU1445/bustub/src/storage/page/hash_table_bucket_page.cpp:205:PrintBucket] INFO - Bucket Capacity: 496, Size: 352, Taken: 352, Free: 0
2022-02-28 14:47:41 [root/code/CMU1445/vm/vm-CMU1445/bustub/src/storage/page/hash_table_bucket_page.cpp:205:PrintBucket] INFO - Bucket Capacity: 496, Size: 496, Taken: 384, Free: 112
page id is:4 pin count is 0
page id is:3 pin count is 0
page id is:2 pin count is 0
page id is:0 pin count is 0
2022-02-28 14:47:41 [root/code/CMU1445/vm/vm-CMU1445/bustub/src/storage/page/hash_table_directory_page.cpp:139:PrintDirectory] DEBUG - ======== DIRECTORY (global_depth_: 2) ========
2022-02-28 14:47:41 [root/code/CMU1445/vm/vm-CMU1445/bustub/src/storage/page/hash_table_directory_page.cpp:140:PrintDirectory] DEBUG - | bucket_idx | page_id | local_depth |
2022-02-28 14:47:41 [root/code/CMU1445/vm/vm-CMU1445/bustub/src/storage/page/hash_table_directory_page.cpp:142:PrintDirectory] DEBUG - | 0 | 3 | 1 |
2022-02-28 14:47:41 [root/code/CMU1445/vm/vm-CMU1445/bustub/src/storage/page/hash_table_directory_page.cpp:142:PrintDirectory] DEBUG - | 1 | 4 | 2 |
2022-02-28 14:47:41 [root/code/CMU1445/vm/vm-CMU1445/bustub/src/storage/page/hash_table_directory_page.cpp:142:PrintDirectory] DEBUG - | 2 | 3 | 1 |
2022-02-28 14:47:41 [root/code/CMU1445/vm/vm-CMU1445/bustub/src/storage/page/hash_table_directory_page.cpp:142:PrintDirectory] DEBUG - | 3 | 2 | 2 |
2022-02-28 14:47:41 [root/code/CMU1445/vm/vm-CMU1445/bustub/src/storage/page/hash_table_directory_page.cpp:144:PrintDirectory] DEBUG - ================ END DIRECTORY ================
dir size is: 4
2022-02-28 14:47:41 [root/code/CMU1445/vm/vm-CMU1445/bustub/src/storage/page/hash_table_bucket_page.cpp:205:PrintBucket] INFO - Bucket Capacity: 496, Size: 352, Taken: 0, Free: 352
2022-02-28 14:47:41 [root/code/CMU1445/vm/vm-CMU1445/bustub/src/storage/page/hash_table_bucket_page.cpp:205:PrintBucket] INFO - Bucket Capacity: 496, Size: 335, Taken: 335, Free: 0
2022-02-28 14:47:41 [root/code/CMU1445/vm/vm-CMU1445/bustub/src/storage/page/hash_table_bucket_page.cpp:205:PrintBucket] INFO - Bucket Capacity: 496, Size: 352, Taken: 0, Free: 352
2022-02-28 14:47:41 [root/code/CMU1445/vm/vm-CMU1445/bustub/src/storage/page/hash_table_bucket_page.cpp:205:PrintBucket] INFO - Bucket Capacity: 496, Size: 496, Taken: 384, Free: 112
2022-02-28 14:47:41 [root/code/CMU1445/vm/vm-CMU1445/bustub/src/storage/page/hash_table_directory_page.cpp:139:PrintDirectory] DEBUG - ======== DIRECTORY (global_depth_: 0) ========
2022-02-28 14:47:41 [root/code/CMU1445/vm/vm-CMU1445/bustub/src/storage/page/hash_table_directory_page.cpp:140:PrintDirectory] DEBUG - | bucket_idx | page_id | local_depth |
2022-02-28 14:47:41 [root/code/CMU1445/vm/vm-CMU1445/bustub/src/storage/page/hash_table_directory_page.cpp:142:PrintDirectory] DEBUG - | 0 | 2 | 0 |
2022-02-28 14:47:41 [root/code/CMU1445/vm/vm-CMU1445/bustub/src/storage/page/hash_table_directory_page.cpp:144:PrintDirectory] DEBUG - ================ END DIRECTORY ================
dir size is: 1
2022-02-28 14:47:41 [root/code/CMU1445/vm/vm-CMU1445/bustub/src/storage/page/hash_table_bucket_page.cpp:205:PrintBucket] INFO - Bucket Capacity: 496, Size: 496, Taken: 384, Free: 112
query execution
进行实验之前简单了解一下火山模型,并将lab3全文先看一遍,特别是SYSTEM CATALOG与INDEX UPDATES部分。代码的编写顺序依次是查询——》插入——》更新——》删除——》嵌套循环联接 ——》 哈希连接——》聚合——》有限——》唯一
问题最多的会是更新和嵌套循环联接部分,有许多细节。

Query Processing
完成实验最重要的便是仔细阅读TableInfo类,你一定会反复看这几个类成员的。IndexInfo类你会在debug的时候仔细看的
struct TableInfo {
/**
* Construct a new TableInfo instance.
* @param schema The table schema
* @param name The table name
* @param table An owning pointer to the table heap
* @param oid The unique OID for the table
*/
TableInfo(Schema schema, std::string name, std::unique_ptr<TableHeap> &&table, table_oid_t oid)
: schema_{std::move(schema)}, name_{std::move(name)}, table_{std::move(table)}, oid_{oid} {}
/** The table schema */
Schema schema_;
/** The table name */
const std::string name_;
/** An owning pointer to the table heap */
std::unique_ptr<TableHeap> table_;
/** The table OID */
const table_oid_t oid_;
};
explicit Schema(const std::vector<Column> &columns);
Column(std::string column_name, TypeId type, const AbstractExpression *expr = nullptr)
Tuple(std::vector<Value> values, const Schema *schema);

Schema类即表的第一行,也就是模式{colA,colB,colC,colD},它由Column类组成,Column类即每一列的表头{colA},你如何判断两列相同呢?。AbstractExpression类是构成列的表达式,这个可能有点绕,但你阅读完测试代码就懂了。你需要调用很多次这里面的Evaluatexxx方法。
TableHeap类即表实际的数据,有一系列元组Tuple构成,Tuple即每一行的数据{1,2, 3,4},Tuple由Value类{1}组成,Value就是数据库中抽象的值,也就是说啥用没有!Tuple的操作很容易引起数组越界,所以你需要认真阅读Tuple部分的代码,确保自己真的理解参数的意义!

RID特别说明(更新)
class Tuple {
private:
// Get the starting storage address of specific column
const char *GetDataPtr(const Schema *schema, uint32_t column_idx) const;
bool allocated_{false}; // is allocated?
RID rid_{}; // if pointing to the table heap, the rid is valid
uint32_t size_{0};
char *data_{nullptr};
};
class RID {
private:
page_id_t page_id_{INVALID_PAGE_ID};
uint32_t slot_num_{0}; // logical offset from 0, 1...
};
在做lab4时才发现我对于RID的推论全是错的,我之前错误地把RID当做元组的唯一资源ID了,每一个元组都会有一个用来标识他们,但实际上RID只是代表元组在表中的位置而已,所以只有表元组才会RID! 我一开始大方向就错了,虽然最终结果对了
所以以下所有对RID的推导都没必要看,因为输出元组根本没有RID
在把没用的RID计算去掉之后,排名竟然还降了,奇怪。
我觉得把变量名rid_改成location_更易于理解
SEQUENTIAL SCAN
查询的逻辑比较简单,如果有约束,判断元组是否满足,没有约束直接返回。这部分的点在于以下几个问题?
元组从table_schema到output_schema如何转换? 元组模式转换有一成不变的方法吗?
uint32_t GetColIdx(const std::string &col_name) const {
for (uint32_t i = 0; i < columns_.size(); ++i) {
if (columns_[i].GetName() == col_name) {
return i;
}
}
UNREACHABLE("Column does not exist");
}
/** @return the indices of non-inlined columns */
const std::vector<uint32_t> &GetUnlinedColumns() const { return uninlined_columns_; }
Value GetValue(const Schema *schema, uint32_t column_idx) const;
我刚开始就是通过列名,列偏移量这种方式转换元组,但这存在一个隐含的约束是:源元组的模式必须是表元组,而不能是由执行器生成的元组,这是因为output_schema的偏移量都是相对表元组来说,如果用执行器使用子执行器的输出元组时,就会产生数组越界的问题。而列名是可以被更改的,所以最稳妥的办法便是使用模式中每一列的生成表达式生成Value,当然不同的模式转换使用不同的Evaluate方法。可以看AbstractExpression类的几个子类对Evaluatexxx方法的实现。
// Tuple中许多方法都是针对完整模式(table schema)而言的,对切割后的模式使用很容易发生数组越界
// 两模式中两列是一样的是很难判断的,因为列名可以改变,只能通过原始表的列序号,但其隐藏在ColumnValueExpression类中
// 故只能不同类型使用不同的Evaluate函数
// 这些转换函数的大体流程都一样,即使用输出元祖的模式调用Evaluatexxx方法,输出相应列的值
void SeqScanExecutor::TupleSchemaTranformUseEvaluate(const Tuple *table_tuple, const Schema *table_schema,
Tuple *dest_tuple, const Schema *dest_schema) {
auto colums = dest_schema->GetColumns();
std::vector<Value> dest_value;
dest_value.reserve(colums.size());
for (const auto &col : colums) {
dest_value.emplace_back(col.GetExpr()->Evaluate(table_tuple, table_schema));
}
*dest_tuple = Tuple(dest_value, dest_schema);
}
当然可以并不是都需要模式转换,如果模式相同就不需要了。以下通过偏移量和列名判断是否相同,我觉得也不算非常保险。
bool SeqScanExecutor::SchemaEqual(const Schema *table_schema, const Schema *output_schema) {
auto table_colums = table_schema->GetColumns();
auto output_colums = output_schema->GetColumns();
if (table_colums.size() != output_colums.size()) {
return false;
}
int col_size = table_colums.size();
uint32_t offset1;
uint32_t offset2;
std::string name1;
std::string name2;
for (int i = 0; i < col_size; i++) {
offset1 = table_colums[i].GetOffset();
offset2 = output_colums[i].GetOffset();
name1 = table_colums[i].GetName();
name2 = output_colums[i].GetName();
if (name1 != name2 || offset1 != offset2) {
return false;
}
}
return true;
}
通过这一个优化排名就提高了几十名。。。

又看到嘉心糖了捏!
第二个问题便是此时next方法的RID应该哪个元组的RID,表元组还是输出元组?
按概念来说应该是输出元组的RID,但如果这个查询被当做更新的子执行器,那么它需要通过这个RID找到原先的表元组并更新。而且当我阅读SimpleDeleteTest代码时,发现其查询部分的输出模式与表模式不相同,但MarkDelete方法需要表元组的RID找到该元组并标记删除,也就是说,不论输出模式与表模式是否相同,RID都应该是表元组的RID,而不是输出元组的RID。
(更新:输出元组没有RID)
INSERT / UPDATE / DELETE
res = child_executor_->Next(&insert_tuple, &insert_rid);
insert_rid = insert_tuple.GetRid(); // 查询计划返回的不是元组的RID,需自己计算RID
table_info_->table_->UpdateTuple(update_tuple, child_rid, transaction); // 传入old rid
if (!delete_res) { // 抛出异常,需要进行相应处理
throw Exception("delete failed");
}
这三个操作大致相同,没啥讲的,索引部分单独列出来讲。insert执行器调用子计划的next方法RID不是输出元组的RID,需要自己计算,不过用表元组的RID好像也没啥影响 (更新:insert方法不需要RID,调用InsertTuple方法后RID才被赋值)
update执行器提供了GenerateUpdatedTuple方法生成更新元组,需要注意的是UpdateTuple方法传入的是旧元组的RID(找到旧元组)。
delete执行器需要及时判断子执行器的结果,抛出异常,在ExecutionEngine类中处理
NESTED LOOP JOIN / HASH JOIN
这里模式转换使用EvaluateJoin方法,对于NESTED LOOP JOIN,必须严格按照Simple Nested Loop Join(SNLJ)算法实现,不要进行任何优化,gradescope有测试右半部扫描次数的(我觉得左半部右半部更直观一点,而不是内表外表)参考博客
// 伪代码
for (r in R) {
for (s in S) {
if (r satisfy condition s) {
output <r, s>;
}
}
}

bool HashJoinExecutor::Next(Tuple *tuple, RID *rid) {
if (left_need_next_) { // 第一次next,找到第一个在hash表的左半部元组
...
left_need_next_ = false;
}
while (true) {
if (array_index_ >= hash_table_[left_key_].size()) { // 超出右半部value数组范围,重新开始,需要寻找下一个左半部元组
}
TupleSchemaTranformUseEvaluateJoin(&left_tuple_, left_schema, &hash_table_[left_key_][array_index_], right_schema,
tuple, final_schema);
array_index_++; // 指向下一位置
return true;
}
return false;
}
不管是Nested Loop Join还是HASH JOIN,第一次next方法都需要进行特殊处理,因为第一次左半部需要调用next方法,后面调用next方法时左半部需要调用next方法的时机要么在右半部扫描到了末尾(Nested Loop Join),要么是map中value数组到了末尾。
std::map<Value, std::vector<Tuple>, MapComparator> hash_table_; // 不使用unordered_map,需要实现两个方法hash和==
HASH JOIN使用map即可,这样方便一点。另外需要处理左表与右表为空的情况。
其余Executor
std::set<Tuple, SetComparator> tuples_;
AggregationExecutor使用EvaluateAggregate进行模式转换,DistinctExecutor使用set存储元组。
索引
struct IndexInfo {
/**
* Construct a new IndexInfo instance.
* @param key_schema The schema for the index key
* @param name The name of the index
* @param index An owning pointer to the index
* @param index_oid The unique OID for the index
* @param table_name The name of the table on which the index is created
* @param key_size The size of the index key, in bytes
*/
IndexInfo(Schema key_schema, std::string name, std::unique_ptr<Index> &&index, index_oid_t index_oid,
std::string table_name, size_t key_size)
: key_schema_{std::move(key_schema)},
name_{std::move(name)},
index_{std::move(index)},
index_oid_{index_oid},
table_name_{std::move(table_name)},
key_size_{key_size} {}
/** The schema for the index key */
Schema key_schema_;
/** The name of the index */
std::string name_;
/** An owning pointer to the index */
std::unique_ptr<Index> index_;
/** The unique OID for the index */
index_oid_t index_oid_;
/** The name of the table on which the index is created */
std::string table_name_;
/** The size of the index key, in bytes */
const size_t key_size_;
};
索引最坑的一点便是,在提交到gradescope之后我才知道原来DeleteEntry InsertEntry方法中传入的不是整个元组,而是元组的一部分(现在想来也合乎情理),在本地测试中根本没看出来。所以第一个问题便来了,如何生成索引列的元组呢?
答案便是使用KeyFromTuple,这个方法应该就是专门为这个用途而设计的,不过我很好奇的是key_attrs的作用是啥?key_schema不能唯一确定key元组吗?有可能跟Unlined Inlined有关,但我懒得研究了。
// Generates a key tuple given schemas and attributes
Tuple KeyFromTuple(const Schema &schema, const Schema &key_schema, const std::vector<uint32_t> &key_attrs);
索引的第二个问题便是DeleteEntry InsertEntry的RID参数应该传哪个?key元组或表元组 (更新:key元组没有RID)
/**
* Insert an entry into the index.
* @param key The index key
* @param rid The RID associated with the key (unused)
* @param transaction The transaction context
*/
virtual void InsertEntry(const Tuple &key, RID rid, Transaction *transaction) = 0;
/**
* Delete an index entry by key.
* @param key The index key
* @param rid The RID associated with the key (unused)
* @param transaction The transaction context
*/
virtual void DeleteEntry(const Tuple &key, RID rid, Transaction *transaction) = 0;
在看到The RID associated with the key (unused)这个说明时我就没在意,随便传了表元组的RID,然后测试就一直卡在update方法面前
info->index_->DeleteEntry(old_key_tuple, child_rid, transaction);
info->index_->InsertEntry(new_key_tuple, update_rid, transaction);
[ RUN ] GradingExecutorTest.UpdateTableSetWithIndex
2022-03-03 15:06:13 [autograder/bustub/src/storage/disk/disk_manager.cpp:124:ReadPage] DEBUG - Read less than a page
/autograder/bustub/test/execution/grading_update_executor_test.cpp:230: Failure
Value of: table->GetTuple(rids[i], &indexed_tuple, GetTxn())
Actual: false
Expected: true
[ FAILED ] GradingExecutorTest.UpdateTableSetWithIndex (50 ms)
[ RUN ] GradingExecutorTest.UpdateIntegrated
2022-03-03 15:06:13 [autograder/bustub/src/storage/disk/disk_manager.cpp:124:ReadPage] DEBUG - Read less than a page
/autograder/bustub/test/execution/grading_update_executor_test.cpp:317: Failure
Value of: table_info->table_->GetTuple(rids[0], &indexed_tuple, GetTxn())
Actual: false
Expected: true
流程分析
table_info_->table_->UpdateTuple(update_tuple, child_rid, transaction); // 传入old rid
bool TableHeap::UpdateTuple(const Tuple &tuple, const RID &rid, Transaction *txn) {
// Find the page which contains the tuple.
auto page = reinterpret_cast<TablePage *>(buffer_pool_manager_->FetchPage(rid.GetPageId()));
// If the page could not be found, then abort the transaction.
if (page == nullptr) {
txn->SetState(TransactionState::ABORTED);
return false;
}
// Update the tuple; but first save the old value for rollbacks.
Tuple old_tuple;
page->WLatch();
bool is_updated = page->UpdateTuple(tuple, &old_tuple, rid, txn, lock_manager_, log_manager_);
page->WUnlatch();
buffer_pool_manager_->UnpinPage(page->GetTablePageId(), is_updated);
// Update the transaction's write set.
if (is_updated && txn->GetState() != TransactionState::ABORTED) {
txn->GetWriteSet()->emplace_back(rid, WType::UPDATE, old_tuple, this);
}
return is_updated;
}
bool TablePage::UpdateTuple(const Tuple &new_tuple, Tuple *old_tuple, const RID &rid, Transaction *txn,
LockManager *lock_manager, LogManager *log_manager)
在UpdateTuple方法传入旧元组的RID后,并没有更新RID的操作(TablePage::UpdateTuple有点复杂,但没看到有RID更新的内容)。也就是说更新元组的RID并没有用,我们仍然使用旧元组的RID检索更新后的元组。
template <typename KeyType, typename ValueType, typename KeyComparator>
void HASH_TABLE_INDEX_TYPE::InsertEntry(const Tuple &key, RID rid, Transaction *transaction) {
// construct insert index key
KeyType index_key;
index_key.SetFromKey(key);
container_.Insert(transaction, index_key, rid);
}
template <typename KeyType, typename ValueType, typename KeyComparator>
void HASH_TABLE_INDEX_TYPE::DeleteEntry(const Tuple &key, RID rid, Transaction *transaction) {
// construct delete index key
KeyType index_key;
index_key.SetFromKey(key);
container_.Remove(transaction, index_key, rid);
}
DeleteEntry InsertEntry方法就是调用了上一部分的动态哈希,key值为索引列,value值为RID。所以索引的使用方式便如下面所示
/**
* Search the index for the provided key.
* @param key The index key
* @param result The collection of RIDs that is populated with results of the search
* @param transaction The transaction context
*/
virtual void ScanKey(const Tuple &key, std::vector<RID> *result, Transaction *transaction) = 0;
/**
* Read a tuple from a table.
* @param rid rid of the tuple to read
* @param[out] tuple the tuple that was read
* @param txn transaction performing the read
* @param lock_manager the lock manager
* @return true if the read is successful (i.e. the tuple exists)
*/
bool GetTuple(const RID &rid, Tuple *tuple, Transaction *txn, LockManager *lock_manager);
已知一个key元组,想要获取完整元组
通过ScanKey方法得到RID数组,通过GetTuple得到完整元组。
在了解完索引的使用流程后DeleteEntry InsertEntry的RID参数应该是哪个就呼之欲出了,即一直为表元组的RID,既不是索引列元组,也不是更新元组。
info->index_->DeleteEntry(old_key_tuple, child_rid, transaction);
info->index_->InsertEntry(new_key_tuple, child_rid, transaction);
当时我没认真看代码,写成这样试了一下,结果测试报另一个错误。
info->index_->DeleteEntry(old_key_tuple, update_rid, transaction);
info->index_->InsertEntry(new_key_tuple, update_rid, transaction);
rids.size()
Which is: 2
i + 1
Which is: 1
Halloween problem
在1976年的万圣节那一天,IBM的两位程序要需要修改数据库库中内容,其所对应的业务内容是“给所有工资小于25000的员工加薪百分之十”,他们运行的sql语句如下:
UPDATE EMP_TABLE SET SALARY=SALARY*1.1 WHERE SALARY<25000
但是他们执行完这条语句以后发现了一个大问题,那就是数据库中所有员工的工资都至少为25000。后来发现出现这样的结果的主要问题是:所有工资小于25000的哪些记录被无限次数得加薪了百分之十,直到工资大于等于25000为止。
如果更新操作是在选择操作扫描索引的执行过程中完成,一个更新的元组可能会在扫描之前和扫描之后重复插入索引两次;同一个元素的元素可能不正确地更新多次(在上述情况下会更新多次直到工资大于等于25000为止)。上述更新操作本身可能影响自己执行的问题称为万圣节问题(Halloween problem)。如果我们在一个字段上创建了索引,那么元组会按照索引进行排序。假如我们在之前的EMP_TABLE表中的SALARY字段上创建了索引,那么每次更新SALARY字段都会更新索引,然后对元组的位置进行调整。
数据库中的万圣节问题(Database “Halloween problem”)
本地测试与gradescope测试
本地测试时,可以输出元组tuple->ToString(output_schema),验证结果。
首先分析最简单的测试用例
// SELECT col_a, col_b FROM test_1 WHERE col_a < 500
TEST_F(ExecutorTest, SimpleSeqScanTest) {
// Construct query plan
TableInfo *table_info = GetExecutorContext()->GetCatalog()->GetTable("test_1"); // 获取test1表
const Schema &schema = table_info->schema_;
auto *col_a = MakeColumnValueExpression(schema, 0, "colA"); // 构建colA的表达式
auto *col_b = MakeColumnValueExpression(schema, 0, "colB");
auto *const500 = MakeConstantValueExpression(ValueFactory::GetIntegerValue(500));
auto *predicate = MakeComparisonExpression(col_a, const500, ComparisonType::LessThan); // 约束条件
auto *out_schema = MakeOutputSchema({{"colA", col_a}, {"colB", col_b}}); // 输出模式
SeqScanPlanNode plan{out_schema, predicate, table_info->oid_};
// Execute
std::vector<Tuple> result_set{};
GetExecutionEngine()->Execute(&plan, &result_set, GetTxn(), GetExecutorContext());
// Verify
ASSERT_EQ(result_set.size(), 500);
for (const auto &tuple : result_set) {
ASSERT_TRUE(tuple.GetValue(out_schema, out_schema->GetColIdx("colA")).GetAs<int32_t>() < 500);
ASSERT_TRUE(tuple.GetValue(out_schema, out_schema->GetColIdx("colB")).GetAs<int32_t>() < 10);
}
}
// test1表的生成在table_generator.cpp的TableGenerator::GenerateTestTables()中
// 表头
"test_1",
TEST1_SIZE,
{{"colA", TypeId::INTEGER, false, Dist::Serial, 0, 0},
{"colB", TypeId::INTEGER, false, Dist::Uniform, 0, 9},
{"colC", TypeId::INTEGER, false, Dist::Uniform, 0, 9999},
{"colD", TypeId::INTEGER, false, Dist::Uniform, 0, 99999}}},
// 表数据
for (auto &table_meta : insert_meta) {
// Create Schema
std::vector<Column> cols{};
cols.reserve(table_meta.col_meta_.size());
for (const auto &col_meta : table_meta.col_meta_) {
if (col_meta.type_ != TypeId::VARCHAR) {
cols.emplace_back(col_meta.name_, col_meta.type_);
} else {
cols.emplace_back(col_meta.name_, col_meta.type_, TEST_VARLEN_SIZE);
}
}
Schema schema(cols);
auto info = exec_ctx_->GetCatalog()->CreateTable(exec_ctx_->GetTransaction(), table_meta.name_, schema);
FillTable(info, &table_meta);
}
在 SimpleUpdateTest中,结果集应该为空,故需修改ExecutionEngine类的Execute方法,使其在元组未分配内存时不添加到result数组之中。
result_set.clear();
// Execute update for all tuples in the table
GetExecutionEngine()->Execute(update_plan.get(), &result_set, GetTxn(), GetExecutorContext());
// UpdateExecutor should not modify the result set
ASSERT_EQ(result_set.size(), 0);
在SimpleDeleteTest测试中查询后的tuple为"(50, 7, 7664, 76652) Tuple size is 16",元组的大小为16,我刚开始以为这个测试有问题,因为索引大小才为8,会造成数组越界问题,但后面才发现索引列并不是全部的元组。。为此我还专门设计了两个新的测试样例,一个用其他的表,一个用更大的key。但实际上是我理解错了索引的意思。
TEST_F(ExecutorTest, MyDeleteTest) {
// Construct query plan
auto table_info = GetExecutorContext()->GetCatalog()->GetTable("test_3");
using MyKeyType = GenericKey<16>;
using MyValueType = RID;
using MyComparatorType = GenericComparator<16>;
using MyHashFunctionType = HashFunction<MyKeyType>
在进行gradescope测试时,一上传就编译失败,显示使用不完全的类AbstractExpression,即未找到AbstractExpression的定义,但plan头文件中都包含了abstract_expression.h。有点奇怪,好像有的版本plan里面没有abstract_expression.h,也懒得管了,在各个Executor里加上abstract_expression.h头文件。
报错集
索引使用输出元组而不是key元组
==2424== Process terminating with default action of signal 6 (SIGABRT)
==2424== at 0x6159FB7: raise (raise.c:51)
==2424== by 0x615B920: abort (abort.c:79)
==2424== by 0x61A4966: __libc_message (libc_fatal.c:181)
==2424== by 0x624FB60: __fortify_fail_abort (fortify_fail.c:33)
==2424== by 0x624FB21: __stack_chk_fail (stack_chk_fail.c:29)
==2424== by 0x4FA2388: bustub::ExtendibleHashTableIndex<bustub::GenericKey<8ul>, bustub::RID, bustub::GenericComparator<8ul> >::DeleteEntry(bustub::Tuple const&, bustub::RID, bustub::Transaction*) (in /autograder/bustub/build/lib/libbustub_shared.so)
连接时未考虑左表 右表为空的情况
[ RUN ] GradingExecutorTest.NestedLoopJoinEmptyOuterTable
==2464== Memcheck, a memory error detector
==2464== Copyright (C) 2002-2017, and GNU GPL'd, by Julian Seward et al.
==2464== Using Valgrind-3.13.0 and LibVEX; rerun with -h for copyright info
==2464== Command: ./grading_nested_loop_join_executor_test
==2464==
grading_nested_loop_join_executor_test: /autograder/bustub/src/storage/table/tuple.cpp:92: bustub::Value bustub::Tuple::GetValue(const bustub::Schema*, uint32_t) const: Assertion `data_' failed.
==2464==
==2464== Process terminating with default action of signal 6 (SIGABRT)
==2464== at 0x5F56FB7: raise (raise.c:51)
==2464== by 0x5F58920: abort (abort.c:79)
==2464== by 0x5F48489: __assert_fail_base (assert.c:92)
==2464== by 0x5F48501: __assert_fail (assert.c:101)
==2464== by 0x4FB7E15: bustub::Tuple::GetValue(bustub::Schema const*, unsigned int) const (in /autograder/bustub/build/lib/libbustub_shared.so)
==2464== by 0x12EAB8: bustub::ColumnValueExpression::EvaluateJoin(bustub::Tuple const*, bustub::Schema const*, bustub::Tuple const*, bustub::Schema const*) const (in
==2464==
IOcost问题,即使多一次都不行
// 第一次
[ RUN ] GradingExecutorTest.NestedLoopJoinIOCost
/autograder/bustub/test/execution/grading_nested_loop_join_executor_test.cpp:443: Failure
Expected equality of these values:
scan0_size * scan1_size
Which is: 100
scan1->PollCount()
Which is: 10
[ FAILED ] GradingExecutorTest.NestedLoopJoinIOCost (752 ms)
// 第二次
/autograder/bustub/test/execution/grading_nested_loop_join_executor_test.cpp:443: Failure
Expected equality of these values:
scan0_size * scan1_size
Which is: 100
scan1->PollCount()
Which is: 101
update executor索引RID问题
[ RUN ] GradingExecutorTest.UpdateTableSetWithIndex
2022-03-03 15:06:13 [autograder/bustub/src/storage/disk/disk_manager.cpp:124:ReadPage] DEBUG - Read less than a page
/autograder/bustub/test/execution/grading_update_executor_test.cpp:230: Failure
Value of: table->GetTuple(rids[i], &indexed_tuple, GetTxn())
Actual: false
Expected: true
[ FAILED ] GradingExecutorTest.UpdateTableSetWithIndex (50 ms)
[ RUN ] GradingExecutorTest.UpdateIntegrated
2022-03-03 15:06:13 [autograder/bustub/src/storage/disk/disk_manager.cpp:124:ReadPage] DEBUG - Read less than a page
/autograder/bustub/test/execution/grading_update_executor_test.cpp:317: Failure
Value of: table_info->table_->GetTuple(rids[0], &indexed_tuple, GetTxn())
Actual: false
Expected: true
测试通过截图

其他:
unordered_map与map的对比: 见《effective stl 》关联容器
存储时是根据key的hash值判断元素是否相同,即unordered_map内部元素是无序的,而map中的元素是按照二叉搜索树存储(用红黑树实现),进行中序遍历会得到有序遍历。所以使用时map的key需要定义operator<。而unordered_map需要定义hash_value函数并且重载operator==。但是很多系统内置的数据类型都自带这些。
总结:结构体用map重载<运算符,结构体用unordered_map重载==运算符。
template < class Key, // unordered_map::key_type
class T, // unordered_map::mapped_type
class Hash = hash<Key>, // unordered_map::hasher
class Pred = equal_to<Key>, // unordered_map::key_equal
class Alloc = allocator< pair<const Key,T> > // unordered_map::allocator_type
> class unordered_map;
详细介绍C++STL:unordered_map
报错use of deleted function
关于c ++:比较对象可作为const调用
concurrency control
这部分实验是关于事务,隔离级别与死锁的,建议先看《数据密集型应用设计》事务一章与《数据库系统概念》15.1 基于锁的协议一节,了解背景知识。实验主要实现四个函数:请求读锁,请求写锁,升级锁,解锁。
事务的隔离级别有读未提交,读己提交,可重复读/快照隔离三种。这几个隔离级别分别能避免一些问题
脏写:写入会覆盖一个尚未提交的值
脏读:事务可以看到未提交的数据
读偏差:观察数据库处于不一致的状态

读未提交:脏写
读己提交:脏写,脏读
可重复读:脏写,脏读,读偏差
落到实现上,读未提交只有写锁,也只加写锁,读己提交 每读取一个元组加读锁,读取完即释放,可重复读使用两阶段锁定(2PL),只有可重复读持有shrink状态,读取时统一加读锁,事务提交时才释放。如果拥有了读锁请求写锁记得使用升级锁。
在又看完一遍事务一节后,我发现了一个问题。在快照隔离中读不阻塞写,写不阻塞读,在2PL中,写入不仅会阻塞其他写入,也会阻塞读,读则只会阻塞写入。那在实验的读己提交隔离级别中,读锁需要阻塞写锁吗?阻塞的意义在哪呢?,脏写只需要写阻塞写,脏读只需要写阻塞读,也就是说加读锁只是为了被阻塞,而不是为了阻塞谁
unique_lock与condition_variable的组合,wait时会自动释放锁,唤醒后再获取锁,非常方便
第一部分的实现比较简单,主要就是维持事务的state,处理一些异常。
实验最难也最坑的地方就是第二部分,我觉得是存在很多问题的。
死锁的四个条件互斥,不可剥夺,请求和保持,循环等待。
Wound-Wait (“Young Waits for Old”): If the requesting transaction has a higher priority than the
holding transaction, the holding transaction aborts and releases the lock. Otherwise, the requesting
transaction waits.
这个 Wound-Wait也就是是年轻事务需等待老事务释放,而老事务可以直接杀死年轻事务,这就破除了循环等待条件。
我以为的:
看到事务ID为优先级的特性,RID的请求队列我就会选择一些可以自动排序的数据结构,由于优先队列不能访问任意位置,所以我采用了set。
class LockRequestQueue {
struct SetpComparator { // 重载map的key值排序方式
bool operator()(const LockRequest &lhs, const LockRequest &rhs) const { return lhs.txn_id_ < rhs.txn_id_; }
};
public:
std::set<LockRequest, SetpComparator> request_queue_;
// for notifying blocked transactions on this rid
std::condition_variable cv_;
// txn_id of an upgrading transaction (if any)
txn_id_t upgrading_ = INVALID_TXN_ID;
int share_req_cnt_{0}; // 当前持有S锁的事务个数
RIDStatus status_; // 当前RID上的锁
};
我以为的逻辑大致如下:
S锁:
避免重复加锁以及一些异常处理
插入请求
杀死比其年轻事务持有锁的写请求
如果当前RID为空闲状态:
获得锁
如果当前RID为写锁状态: // 代表持有锁的事务更老
等待锁的释放直到事务中止或得到锁的保证
如果当前RID为读锁状态:
如果在其前面存在写锁请求或者更新锁请求,则等待锁的释放直到事务中止或得到锁的保证 // 不能使老事务的写/更新请求等待年轻事务的读
否则获得锁
X锁:
避免重复加锁以及一些异常处理
插入请求
杀死比其年轻事务持有锁的请求
等待锁的释放直到事务中止或得到锁的保证
升级锁:
杀死比其年轻事务持有锁的读请求
等待直到事务中止或得到只剩下它这一个读请求
升级成写锁
解锁:
在请求队列删除该请求
如果是写锁请求或最后一个读锁解锁,则需要给一些请求保证
如果队列第一个是写锁请求,只给这一个锁保证
如果队列第一个是读锁请求,给予连续的读锁请求保证
唤醒等待的线程
实现这些逻辑之后,我通过了本地测试,但gradescope4个Wound测试一直无法通过,在阅读了博客CMU15-445 数据库实验全满分通过笔记 2021 Fall bustub-cmudb lab 才知道gradescope的逻辑是大致这样的
S锁:
避免重复加锁以及一些异常处理
插入请求
杀死比其年轻事务写请求
如果当前RID为空闲状态:
获得锁
如果当前RID为写锁状态: // 代表持有锁的事务更老
等待锁的释放直到事务中止或得到锁的保证
如果当前RID为读锁状态:
如果在其前面存在写锁请求或者更新锁请求,则等待锁的释放直到事务中止或得到锁的保证 // 不能使老事务的写/更新请求等待年轻事务的读
否则获得锁
X锁:
避免重复加锁以及一些异常处理
插入请求
杀死比其年轻事务的请求
等待锁的释放直到事务中止或得到锁的保证
升级锁:
杀死比其年轻事务的请求
等待直到事务中止或得到只剩下它这一个读请求
升级成写锁
解锁:
在请求队列删除该请求
如果是写锁请求或最后一个读锁解锁,则需要给一些请求保证
如果队列第一个是写锁请求,只给这一个锁保证
如果队列第一个是读锁请求,给予连续的读锁请求保证
唤醒等待的线程
年轻事务未持有锁,为什么需要被杀死呢?
这种实现逻辑实际上是和请求队列的数据结构绑定的,实验希望请求队列使用list,或者说FIFO。但我觉得将测试与具体实现对应而不与接口或者说功能对应是很奇怪的一件事情,所以得60分就够了。

中止事务
第二部分最复杂的地方在于对中止事务的处理。中止事务分为持有锁的中止事务与未持有锁的中止事务
第一个问题:未持有锁的中止事务什么时候可以停止等待
while (txn->GetState() != TransactionState::ABORTED && !(request_location->granted_)) { // 事务中止或得到保证
lock_table_[rid].cv_.wait(lock);
}
在这种结构中,如果没有调用notify_all方法,则这个线程一直会阻塞在这个地方,所以在加锁函数杀死请求之后,都在其后加上notify_all语句,使得中止的事务尽可能快地结束等待,而不是只在解锁函数中唤醒线程。
第二个问题:可以对中止事务调用unlock方法吗?
auto request_location = lock_table_[rid].request_queue_.emplace(req).first;
auto iter = lock_table_[rid].request_queue_.begin();
auto next_iter = iter;
while (iter != lock_table_[rid].request_queue_.end()) { // 杀死所有年轻事务
++next_iter;
if (iter->txn_id_ > txn_id) {
iter->transation_->SetState(TransactionState::ABORTED);
}
if (iter->transation_->GetState() == TransactionState::ABORTED) { // 删除队列中中止事务的请求
if (iter->granted_) {
lock.unlock();
Unlock(iter->transation_, rid); // 将请求从请求队列移除
lock.lock();
} else {
lock_table_[rid].request_queue_.erase(iter);
}
}
iter = next_iter;
}
lock_table_[rid].cv_.notify_all();
注意内存重分配(vector),删除元素带来的迭代器 指针 引用失效
V1: 我最开始的方法是这样的,因为对中止事务的处理有点麻烦,为了省事,我直接删除队列中的中止事务。这段代码看起来是没有问题的,gradescope也能通过全部测试(不知道是运气还是什么的),但实际上是存在问题的。
测试代码中:
auto otask = [&](Transaction *tx) {
while (tx->GetState() != TransactionState::ABORTED) {
}
txn_mgr.Abort(tx);
};
其中Abort方法调用ReleaseLocks函数
void ReleaseLocks(Transaction *txn) {
std::unordered_set<RID> lock_set;
for (auto item : *txn->GetExclusiveLockSet()) {
lock_set.emplace(item);
}
for (auto item : *txn->GetSharedLockSet()) {
lock_set.emplace(item);
}
for (auto locked_rid : lock_set) {
lock_manager_->Unlock(txn, locked_rid);
}
}
两个线程同时对事务的shared_lock_set_,exclusive_lock_set_数据结构进行操作,可能会使得ReleaseLocks函数中的迭代器指向错误的位置(heap-use-after-free,一个线程删除,一个线程访问)。那么结论便是:不能对中止事务进行解锁操作,所以队列中永远可能有持有锁的中止事务(未持有锁的中止事务可以移除)
那么啥都不干,等事务管理器来释放中止事务拥有的锁,可行吗?
从测试代码看也不可行,所以说只能释放锁后再将事务设置为中止。
这个事务管理器真是啥用没有。。。
auto request_location = lock_table_[rid].request_queue_.emplace(req).first;
auto iter = lock_table_[rid].request_queue_.begin();
auto next_iter = iter;
while (iter != lock_table_[rid].request_queue_.end()) { // 杀死比其年轻的写锁请求
++next_iter;
if (iter->lock_mode_ == LockMode::EXCLUSIVE && iter->txn_id_ > txn_id &&
iter->transation_->GetState() != TransactionState::ABORTED) {
transaction = iter->transation_; // 记录事务指针,先解锁再中止事务
if (iter->granted_) {
lock.unlock();
Unlock(iter->transation_, rid); // 持有锁的请求立即解锁
lock.lock();
}
transaction->SetState(TransactionState::ABORTED);
} else if (iter->transation_->GetState() == TransactionState::ABORTED &&
!iter->granted_) { // 移除队列中未持有锁的中止事务
lock_table_[rid].request_queue_.erase(iter);
}
iter = next_iter;
}
lock_table_[rid].cv_.notify_all(); // 唤醒请求,防止中止事务一直等待
但在解锁时我碰到了无法解决的问题,在需要唤醒请求后,需要找第一个非中止事务的请求给予保证。
auto next_req_iter = lock_table_[rid].request_queue_.begin();
for (auto iter = lock_table_[rid].request_queue_.begin(); iter != lock_table_[rid].request_queue_.end(); ++iter) {
if (iter->transation_->GetState() != TransactionState::ABORTED) {
exist_normal_request = true;
next_req_mode = iter->lock_mode_;
next_req_iter = iter;
break;
}
}
而这个虽然运行能成功,但valgrind测试通不过,显示Invalid read of size 4,即iter->transation_有一些问题,但我不知道问题出在哪里,以后有机会再回头看看吧。

V2:我换了一个错误的逻辑来写,直接找第一个请求,实际上第一个请求可能是中止事务的等待请求
// 下一个请求
auto next_req_iter = lock_table_[rid].request_queue_.begin();
if (!lock_table_[rid].request_queue_.empty()) {
exist_normal_request = true;
next_req_mode = next_req_iter->lock_mode_;
}
结果gradescope又过了。。。,所以到头来我认为两个错误的版本都过了,我认为正确的版本valgrind 过不了。
更新:valgrind 测试不能通过的原因是因为一些异常中止的事务Transaction已经结束了生命周期,此时其未持有锁的请求仍然在队列
auto wait_die_task = [&]() {
id_mutex.lock();
Transaction wait_txn(id_wait++);
id_mutex.unlock();
bool res;
txn_mgr.Begin(&wait_txn);
res = lock_mgr.LockShared(&wait_txn, rid1);
EXPECT_TRUE(res);
CheckGrowing(&wait_txn);
CheckTxnLockSize(&wait_txn, 1, 0);
try {
res = lock_mgr.LockExclusive(&wait_txn, rid0);
EXPECT_FALSE(res) << wait_txn.GetTransactionId() << "ERR";
} catch (const TransactionAbortException &e) {
} catch (const Exception &e) {
EXPECT_TRUE(false) << "Test encountered exception" << e.what();
}
CheckAborted(&wait_txn);
txn_mgr.Abort(&wait_txn);
};
故iter->transation指针指向了未定义的位置,所以不能让中止事务的未持有锁的请求停留在队列中,此时指针不一定指向合法的地址
所以结论便是这样:如果中止事务持有锁,则不能擅自解锁,可能一直停留在队列中,如果未持有锁,则需要立即移除
V3:故修改代码,如果线程被唤醒后由于事务被中止而退出循环,则立即移除该请求,而不是像前两个版本一样在之前删除未加锁的请求
auto request_location = lock_table_[rid].request_queue_.emplace(req).first;
auto iter = lock_table_[rid].request_queue_.begin();
auto next_iter = iter;
while (iter != lock_table_[rid].request_queue_.end()) { // 杀死比其年轻的请求
++next_iter;
if (iter->txn_id_ > txn_id && iter->transation_->GetState() != TransactionState::ABORTED) {
transaction = iter->transation_; // 记录事务指针
if (iter->granted_) {
lock.unlock();
Unlock(iter->transation_, rid); // 持有锁的请求立即解锁
lock.lock();
}
transaction->SetState(TransactionState::ABORTED);
}
iter = next_iter;
}
lock_table_[rid].cv_.notify_all(); // 唤醒中止事务请求
while (txn->GetState() != TransactionState::ABORTED && !(request_location->granted_)) { // 事务中止或得到保证
lock_table_[rid].cv_.wait(lock);
}
if (txn->GetState() == TransactionState::ABORTED) {
lock_table_[rid].request_queue_.erase(request_location);
return false;
}
所以前两个版本到底为啥没出错,令人费解。
第三部分也不用加几行语句,就update_executor的索引与write sets维护(根本不用维护,InsertTuple方法中已经维护了)比较坑,建议看CMU15-445 数据库实验全满分通过笔记 2021 Fall bustub-cmudb lab,这篇博客写的很好了,懒得写重复的东西。
主要就三点:
- 未等待的事务也需要abort
- 不抛出异常
- update不需要维持索引结构

参考代码
过了几个月再看lab4的博客我自己都快看不懂了,太过抽象了,还是贴一下lock_manager的代码
lab4我也懒得与测试程序反着来了,直接用list实现算了(虽然我觉得用优先队列的方式才是最好的,但测试程序的逻辑太奇怪了),而后把一些功能一致的代码提取成函数,这样看起来就简洁一点了
// lock_manager.h
#pragma once
#include
#include request_queue_;
// 改用list实现
std::list<LockRequest> request_queue_;
// for notifying blocked transactions on this rid
std::condition_variable cv_;
// txn_id of an upgrading transaction (if any)
txn_id_t upgrading_ = INVALID_TXN_ID;
int share_req_cnt_{0}; // 当前持有S锁的事务个数
RIDStatus status_; // 当前RID上的锁
};
public:
/**
* Creates a new lock manager configured for the deadlock prevention policy.
*/
LockManager() = default;
~LockManager() = default;
/*
* [LOCK_NOTE]: For all locking functions, we:
* 1. return false if the transaction is aborted; and
* 2. block on wait, return true when the lock request is granted; and
* 3. it is undefined behavior to try locking an already locked RID in the
* same transaction, i.e. the transaction is responsible for keeping track of
* its current locks.
*/
/**
* Acquire a lock on RID in shared mode. See [LOCK_NOTE] in header file.
* @param txn the transaction requesting the shared lock
* @param rid the RID to be locked in shared mode
* @return true if the lock is granted, false otherwise
*/
auto LockShared(Transaction *txn, const RID &rid) -> bool;
/**
* Acquire a lock on RID in exclusive mode. See [LOCK_NOTE] in header file.
* @param txn the transaction requesting the exclusive lock
* @param rid the RID to be locked in exclusive mode
* @return true if the lock is granted, false otherwise
*/
auto LockExclusive(Transaction *txn, const RID &rid) -> bool;
/**
* Upgrade a lock from a shared lock to an exclusive lock.
* @param txn the transaction requesting the lock upgrade
* @param rid the RID that should already be locked in shared mode by the
* requesting transaction
* @return true if the upgrade is successful, false otherwise
*/
auto LockUpgrade(Transaction *txn, const RID &rid) -> bool;
/**
* Release the lock held by the transaction.
* @param txn the transaction releasing the lock, it should actually hold the
* lock
* @param rid the RID that is locked by the transaction
* @return true if the unlock is successful, false otherwise
*/
auto Unlock(Transaction *txn, const RID &rid) -> bool;
void KillRequest(txn_id_t id, const RID &rid, KillType type);
void AwakeSharedRequest(const RID &rid);
auto ProcessRequest(Transaction *txn, const RID &rid, const LockRequest &req) -> bool;
auto UnlockImp(Transaction *txn, const RID &rid) -> bool;
private:
std::mutex latch_;
/** Lock table for lock requests. */
std::unordered_map<RID, LockRequestQueue> lock_table_;
};
} // namespace bustub
// lock_manager.cpp
#include "concurrency/lock_manager.h"
#include 其他:
notify_one()方法:
Unblocks one of the threads currently waiting for this condition. If no threads are waiting, the function does nothing. If more than one, it is unspecified which of the threads is selected.
notify_one()方法只是随机唤醒一个线程,所以用notify_all方法比较好,只要不给请求保证,即使请求被唤醒,仍然会等待。
auto与类型推导规则类似,会忽略引用
int a = 0;
int b = &a;
auto c = b; // c为int类型
auto& c = b; // c为int&类型
见《efficientive modern c++》第一章
unordered_map<string, int> mymap1;
auto val = mymap1["str"]; // val为0
// 常用于词频统计,存在则加一,不存在则创建后赋值为1
unordered_map<string, int> mymap2;
mymap2["str"]++; // mymap2["str"] = 1
``
Map中使用方括号访问键对应的值map[key]时:
若该key存在,则访问取得value值;
若该key不存在,访问仍然成功,取得value对象默认构造的值。具体如下:
用 []访问,但key不存在时,C++会利用该key及默认构造的value,组成{key,value}对,插入到map中。
value为 string对象,则构造空串;value为int对象,构造为0。
注:因此在访问map元素时,应先用map.find查找该元素,找到后再访问。 同时,用法mymap2["str"]++;常用于词频统计,存在则加一,不存在则创建后赋值为1。
修改set元素的方法
优先队列不能修改任意位置的值,而set不能直接修改值,只能间接地修改(修改后不影响排序的值)
1. 先删除,再插入
2. 将要修改的值存储为指针
class LockRequest {
public:
LockRequest(Transaction *txn, txn_id_t txn_id, LockMode lock_mode) : txn_id_(txn_id), transation_(txn) {
lock_mode_ = std::make_shared<LockMode>(lock_mode);
granted_ = std::make_shared<bool>(false);
}
txn_id_t txn_id_;
Transaction *transation_;
std::shared_ptr<LockMode> lock_mode_;
std::shared_ptr<bool> granted_;
};
3.移除常量性
auto iter = lock_table_[rid].request_queue_.begin(); // 实际上这时候更新请求就在队列第一位
auto& req = const_cast<LockRequest&>(*iter);
等价与相等
等价是基于在一个有序区间中对象值的相对位置。
两个值如果没有哪个在另一个之前(关于某个排序标准),那么它们等价
相等的概念是基于operator==的。如果表达式“x == y”返回true,x和y有相等的值
详细论述见《Effective STL》
gdb调试奇怪的地方
table_info_->table_->InsertTuple(insert_tuple, &insert_rid, transaction); // insert_rid此时才被赋值
std::cout << insert_rid.ToString() << std::endl;
transaction->AppendTableWriteRecord(
TableWriteRecord{insert_rid, WType::INSERT, insert_tuple, table_info_->table_.get()}); // 维护WriteSet
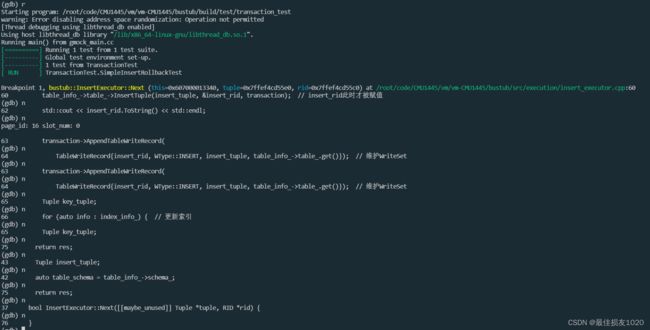
bool TableHeap::InsertTuple(const Tuple &tuple, RID *rid, Transaction *txn) {
// Update the transaction's write set.
txn->GetWriteSet()->emplace_back(*rid, WType::INSERT, Tuple{}, this);
return true;
}
在不知道InsertTuple实际上已经维护了write set时,我在代码中使用AppendTableWriteRecord语句记录write set。记录两次当事务中止时第二次删除为空,便会报错。当我gdb调试,看为什么为有两个相同的项时,发现gdb的执行顺序非常奇怪,而且AppendTableWriteRecord看起来非常奇怪,而且就算把TableWriteRecord单独拿出来,看起来还是会执行两次(当然实际上只执行了一次)
debug 模式与正常模式
不知道为什么,有时候debug模式测试能通过,正常模式不能通过。有时候正常模式能通过,debug模式不能通过
以下第一种情况我觉得都不应该通过测试
for (const auto &item : lock_table_[rid].request_queue_) { // 在请求队列中删除该请求
if (item.txn_id_ == txn_id) {
lock_table_[rid].request_queue_.erase(item);
}
}
改成
删除一个元素就退出
for (const auto &item : lock_table_[rid].request_queue_) { // 在请求队列中删除该请求
if (item.txn_id_ == txn_id) {
lock_table_[rid].request_queue_.erase(item);
break;
}
}
否则使用这种形式
auto iter = queue.begin();
while(iter!=queue.end()){
if(删除元素){
iter = queue.erase(iter);
}else{
++iter;
}
}
一个加锁的函数调用另一个需要加锁的函数便会产生死锁
8-10更新/在线测试文件获取
1 可以通过以下函数获取在线测试文件
#pragma once
#include all_filenames = {
"/autograder/bustub/test/primer/grading_starter_test.cpp",
"/autograder/bustub/test/execution/grading_update_executor_test.cpp",
"/autograder/bustub/test/execution/grading_nested_loop_join_executor_test.cpp",
"/autograder/bustub/test/execution/grading_limit_executor_test.cpp",
"/autograder/bustub/test/execution/grading_executor_benchmark_test.cpp",
"/autograder/bustub/test/concurrency/grading_lock_manager_3_test.cpp",
"/autograder/bustub/test/buffer/grading_parallel_buffer_pool_manager_test.cpp",
"/autograder/bustub/test/buffer/grading_lru_replacer_test.cpp",
"/autograder/bustub/test/execution/grading_executor_integrated_test.cpp",
"/autograder/bustub/test/execution/grading_sequential_scan_executor_test.cpp",
"/autograder/bustub/test/concurrency/grading_lock_manager_1_test.cpp",
"/autograder/bustub/test/execution/grading_distinct_executor_test.cpp",
"/autograder/bustub/test/buffer/grading_buffer_pool_manager_instance_test.cpp",
"/autograder/bustub/test/concurrency/grading_lock_manager_2_test.cpp",
"/autograder/bustub/test/concurrency/grading_transaction_test.cpp",
"/autograder/bustub/test/buffer/grading_leaderboard_test.cpp",
"/autograder/bustub/test/container/grading_hash_table_verification_test.cpp",
"/autograder/bustub/test/concurrency/grading_rollback_test.cpp",
"/autograder/bustub/test/container/grading_hash_table_concurrent_test.cpp",
"/autograder/bustub/test/container/grading_hash_table_page_test.cpp",
"/autograder/bustub/test/concurrency/grading_lock_manager_detection_test.cpp",
"/autograder/bustub/test/container/grading_hash_table_leaderboard_test.cpp",
"/autograder/bustub/test/container/grading_hash_table_scale_test.cpp",
"/autograder/bustub/test/container/grading_hash_table_test.cpp",
"/autograder/bustub/test/execution/grading_aggregation_executor_test.cpp",
"/autograder/bustub/test/execution/grading_insert_executor_test.cpp",
"/autograder/bustub/test/execution/grading_delete_executor_test.cpp",
"/autograder/bustub/test/execution/grading_hash_join_executor_test.cpp"
"/autograder/bustub/test/execution/grading_sequential_scan_executor_test.cpp",
"/autograder/bustub/test/execution/grading_update_executor_test.cpp",
"/autograder/bustub/test/execution/grading_executor_test_util.h",
"/autograder/bustub/src/include/execution/plans/mock_scan_plan.h",
};
*/
std::vector<std::string> filenames = {
"/autograder/bustub/test/execution/grading_executor_integrated_test.cpp",
"/autograder/bustub/test/execution/grading_executor_benchmark_test.cpp",
};
std::ifstream fin;
for (const std::string &filename : filenames) {
fin.open(filename, std::ios::in);
if (!fin.is_open()) {
std::cout << "cannot open the file:" << filename << std::endl;
continue;
}
char buf[200] = {0};
std::cout << filename << std::endl;
while (fin.getline(buf, sizeof(buf))) {
std::cout << buf << std::endl;
}
fin.close();
}
first_enter = false;
}
}
但不知道为什么打印在线的测试文件输出不会换行,只能复制至vscode,而后全局替换\n,代码中有些还需要进行少量修改
2 重写时发现的问题,其中许多与gradesope测试程序有关,我倒不怎么觉得是我的问题
buffer实验中flush/flush all不需要判断是否dirty,HardTestD有时候错误就是因为这个
/*
if (pages_[frame_id].IsDirty()) {
disk_manager_->WritePage(page_id, pages_[frame_id].data_);
pages_[frame_id].is_dirty_ = false;
}
我本来以为只有dirty时才进行页的写入,但parallel_buffer_pool_manager_test.cpp 942-944行的逻辑表明不是这样的
strcpy(page->GetData(), std::to_string(temp_page_id).c_str()); // NOLINT
// FLush page instead of unpining with true
EXPECT_EQ(1, bpm->FlushPage(temp_page_id, nullptr));
EXPECT_EQ(1, bpm->UnpinPage(temp_page_id, false, nullptr));
*/
disk_manager_->WritePage(page_id, pages_[frame_id].data_);
pages_[frame_id].is_dirty_ = false;
return true;
hash实验中HashTableBucketPage的数组类型改成unsigned char,这样就能直接与0xff之类的进行比较,而不用强制转换
ExtendibleHashTable中直接缓存目录页,使用更简单的方式寻找桶
// 首先遍历一遍目录,将仍指向旧桶的位置深度加一
// for (uint32_t i = 0; i < dir_size; i++) {
// if ((i & new_local_mask) == old_local_hash) {
// dir_page_->IncrLocalDepth(i);
// }
// }
// 实现与上面代码一样的功能
for (uint32_t i = old_local_hash; i < dir_size; i += new_local_mask + 1) {
dir_page_->IncrLocalDepth(i);
}
3 最近拉取的代码与我之前拉取的代码有挺大的不同,最近拉取的代码都使用auto fun() -> type的形式,不知道为啥使用这种方式,并且AppendTableWriteRecord IndexWriteRecord接口也发生了改变,之前update不能更新索引的问题也得到了解决。
class IndexWriteRecord {
public:
IndexWriteRecord(RID rid, table_oid_t table_oid, WType wtype, const Tuple &tuple, const Tuple &old_tuple,
index_oid_t index_oid, Catalog *catalog)
: rid_(rid),
table_oid_(table_oid),
wtype_(wtype),
tuple_(tuple),
old_tuple_(old_tuple),
index_oid_(index_oid),
catalog_(catalog) {}
/** The rid is the value stored in the index. */
RID rid_;
/** Table oid. */
table_oid_t table_oid_;
/** Write type. */
WType wtype_;
/** The tuple is used to construct an index key. */
Tuple tuple_;
/** The old tuple is only used for the update operation. */
Tuple old_tuple_;
/** Each table has an index list, this is the identifier of an index into the list. */
index_oid_t index_oid_;
/** The catalog contains metadata required to locate index. */
Catalog *catalog_;
};
但由于虽然本地代码接口变了,但测试程序没变,故打包时需加上src/include/concurrency/transaction.h
error: The left operand of ‘==’ is a garbage value: 需加上src/include/storage/page/tmp_tuple_page.h
4 lab4我也懒得与测试程序反着来了,直接用list实现算了(虽然我觉得用优先队列的方式才是最好的,但测试程序的逻辑太奇怪了),而后把一些功能一致的代码提取成函数,这样看起来就简洁一点了
5 lab4提交时出现heap-buffer-overflow问题
==3699== Invalid read of size 4
==3699== at 0x4FB8C4A: bustub::IntegerType::DeserializeFrom(char const*) const (in /autograder/bustub/build/lib/libbustub_shared.so)
==3699== by 0x4F9FAD0: bustub::Value::DeserializeFrom(char const*, bustub::TypeId) (in /autograder/bustub/build/lib/libbustub_shared.so)
==3699== by 0x4FAC077: bustub::Tuple::GetValue(bustub::Schema const*, unsigned int) const (in /autograder/bustub/build/lib/libbustub_shared.so)
==3699== by 0x4FAC163: bustub::Tuple::KeyFromTuple(bustub::Schema const&, bustub::Schema const&, std::vector<unsigned int, std::allocator<unsigned int> > const&) (in
对照TransactionManager::Abort可以看出IndexWriteRecord中tuple是元组而不是索引
// Rollback index updates
auto index_write_set = txn->GetIndexWriteSet();
while (!index_write_set->empty()) {
auto &item = index_write_set->back();
auto catalog = item.catalog_;
// Metadata identifying the table that should be deleted from.
TableInfo *table_info = catalog->GetTable(item.table_oid_);
IndexInfo *index_info = catalog->GetIndex(item.index_oid_);
auto new_key = item.tuple_.KeyFromTuple(table_info->schema_, *(index_info->index_->GetKeySchema()),
index_info->index_->GetKeyAttrs());
if (item.wtype_ == WType::DELETE) {
index_info->index_->InsertEntry(new_key, item.rid_, txn);
} else if (item.wtype_ == WType::INSERT) {
index_info->index_->DeleteEntry(new_key, item.rid_, txn);
} else if (item.wtype_ == WType::UPDATE) {
// Delete the new key and insert the old key
index_info->index_->DeleteEntry(new_key, item.rid_, txn);
auto old_key = item.old_tuple_.KeyFromTuple(table_info->schema_, *(index_info->index_->GetKeySchema()),
index_info->index_->GetKeyAttrs());
index_info->index_->InsertEntry(old_key, item.rid_, txn);
}
index_write_set->pop_back();
}
2020 b+树
CMU15445 2020 B+TREE简单记录
写在后面
参考博客
CMU15-445 数据库实验全满分通过笔记 2021 Fall bustub-cmudb
CMU数据库(15-445)实验1-BufferPoolManager
CMU 15445 Project 1 Buffer Pool | 手摸手带你撸一个内存管理池
CMU-15445-proj3(QueryExecutor)
其中对我帮助最大的便是CMU15-445 数据库实验全满分通过笔记 2021 Fall bustub-cmudb这篇