分布式存储学习——HDFS
简介
HDFS(Hadoop Distributed File System)是一种分布式文件系统,属于非结构化的分布式存储类型。其前身是GFS(Google File System),作为一款优秀的分布式文件系统,其集成了传统文件存储的优点,且具备很多创新的地方,是整个Hadoop生态默认的文件存储策略,非常值得学习。值得一提的是,HDFS本身是基于JAVA语言开发的,具有很好的移植性,很多大公司的文件系统都是从开源的HDFS中修改的企业版。
作为Hadoop生态圈的一个重要的成员,HDFS可以说是为了大数据存储和计算而设计的。作为一个分布式存储系统,HDFS具备数据的存储和备份、容灾与恢复、数据一致性和系统扩展性等性质。通过对大的文件进行分块(block,每个块都是相当大的,默认是128MB),以块为单位进行存储和备份。而小的文件 HDFS并不会做太多的优化。
对于大文件的读取,HDFS偏向于将大文件的文件块存储在相对靠近的位置,以便于对一个区域进行连续读取。对于小文件将对其的读取操作进行合并,并按照一定顺序读取,可以发现,这样的处理使得整个流程变成了一种==批处理的方式。==然而实际操作要复杂很多,读取时要保证操作的原子性,考虑并发和一致性,HDFS采取了很多策略来保证整个系统的正确运行。
设计目标
- 硬件容错性:对于大规模集群来说,对于硬件的容错是高可用性的关键部分。
- 数据流访问:在HDFS的系统的应用是采用数据流访问各种数据。HDFS更加关注批处理而不是用户交互。即HDFS是为了提升数据吞吐量而不是降低数据访问的延时。
- 大文件:HDFS存储的文件通常是GB-TB的大小。HDFS应该提供高带宽和高扩展性。
- 数据一致性:HDFS提供写一次读多次模型。文件一旦被创建完成就无法更改,只可以读。
- 让计算任务移动到离数据更近的地方:HDFS提供了一系列接口以便让用户的计算任务迁移到离数据更近的地方,避免大数据的移动。
- 移植性:HDFS从设计开始,就要实现跨平台和跨硬件。(参考JVM的原理)
原理
HDFS是分布式文件系统的缩写,将大文件分解成小文件存储在分布式系统中。需要明确几个概念:文件切块,副本存储,元数据。
HDFS是一个文件系统,通过目录树来定位不同主机上的文件,其文件的大小是一个块(Block)。可以通过修改dfs.blocksize参数来调整块的大小,默认是64M。通过路径名可以查看到目录树:file.data。
1. HDFS构架
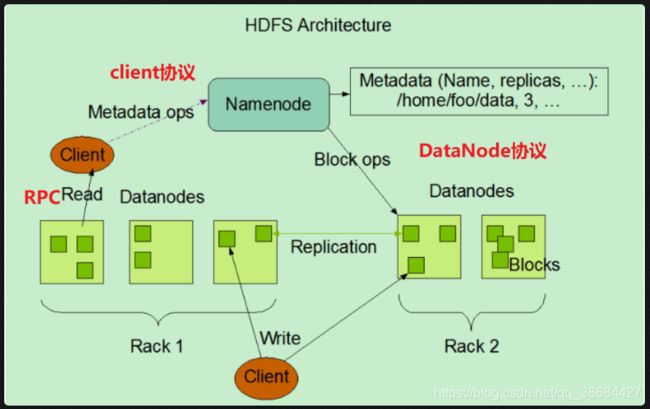
2. 组件介绍
HDFS主要包括两个部分:NameNode和DataNode,NameNode可以理解为包工头,DataNode可以看做是搬砖人,通常包工头是不去搬砖的,但是在某些情况下,比如人手实在是不够了(类比于HDFS的伪分布式),包工头也得去搬砖,即NameNode和DataNode运行在同一台机器上。
2.1 DataNode
每个节点的内容的管理由------datanode完成。每个block可以在多个datanode上存储内容。每个DataNode需要定期向NameNode汇报自己的情况,以便让整个系统保持正常运转。
2.2 NameNode:
对于一个集群来说,需要有一个主节点来标明这个节点的名称-----namenode。namenode负责维护和管理它所在集群的目录树和每个块的信息(包括块的ID和所在服务器的ID)。
NameNode上会管理几种数据:
- 命名空间:即DFS的目录结构。HDFS的目录结构和unix一致,采用树形结构。
- 数据块与DataNode的映射表:每个块的大小默认是64MB,实际常常设置为128MB。默认三个副本。大数据块可以减少寻址开销,HDFS的瓶颈往往在于网络的传输带宽。
- 每个数据块的副本块信息:ASR和ISR会指出该数据块的指定副本块和正在保持同步的副本块的块号,然后通过其块与DataNode的映射表就可以找到数据块的副本了。
文件组织方式:
查看本地磁盘上存储的数据:
NameNode目录结构:通过查看Hadoop的配置文件:hdfs.site.xml中的{dfs.name.dir}指定元数据持久化的位置。
文件夹打开是这样的:

DataNode的目录结构:同一个配置文件中的{dfs.data.dir}来配置。SecondaryNameNode结构:结构上和NameNode一致,但是VERSION文件中可以看出,二者的版本不同,SecondaryNameNode版本较老。
3. HDFS的工作流程
3.1 数据存储策略
HDFS通过一系列策略保证高可用性和节约网络带宽。我们知道,HDFS的存储单位BLOCK是非常大的,这使得传输的主要瓶颈变成了网络带宽。
在说明存储策略之前,我们需要明确几点:
- 距离:指数据传输的长度(代价):以下距离依次递增。 NameNode会根据定义的距离对数据读取、切割和 存放入最近的节点。
- 同一节点上的存储数据
- 同一机架上不同节点上的存储数据
- 同一数据中心不同机架上的存储数据
- 不同数据中心的节点
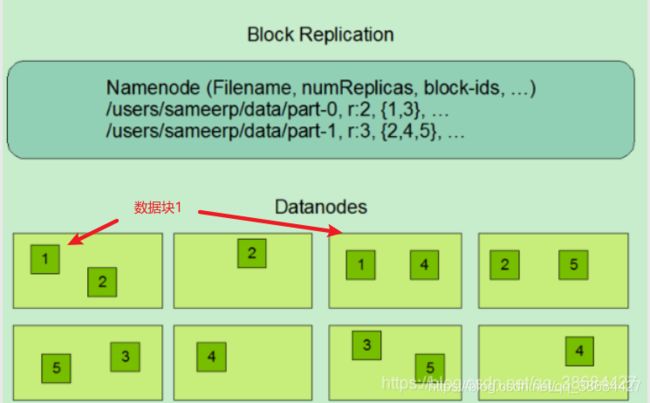
3.1.1 数据备份
机架在HDFS扮演重要的角色。同一个机架的通信是在一条总线上的,所以同一个机架下的节点通信速度会远大于不同机架下的节点通信。NameNode可以决定哪些DataNode在哪些机架上。
在默认三个副本的情况下,通常是本地机架有一个副本,远程机架上有两个副本(同一个机架上的两个node)。
用户在对文件进行操作时会自动选择离操作 的节点相近的副本块,为了节约网络资源的消耗。
数据备份有明显的优缺点,好处是:首先,备份提高数据的安全性,其次,备份可以提高数据的读取速度,当高的并发读取时,我们可以将发起读取的RPC分配到不同的机器上进行读取。(比如经过一个Hash函数)坏处是:数据的更新是一个很困难的过程,当然,如果你需要维持强一致性的话,你需要将所有的副本进行更新。下图是HDFS中的数据备份的说明:
3.1.2 数据输入
HDFS是面向大文件的,每个文件块的默认大小是64MB
HDFS的客户端会缓存文件在一个临时文件中,所有对缓存的文件的访问都会被重定向到这些临时文件。当文件的大小超过一个block的大小,客户端就会通知NameNode,NameNode会为该文件分配一个块号并把该文件插入到文件系统当中。
此时NameNode会告诉客户端为其分配的DataNode编号和块号。接着客户端就把文件写入对应的DataNode,当文件关闭时,临时本地文件中剩余的未刷新数据转移到DataNode, 当文件 传输完成之后,NameNode会将该文件存入磁盘中。
3.1.3 流水线复制
当client的文件累积到一个block大小时,就向NameNode发送写入请求。NameNode会寻找若干个DataNode(取决于复制因子),客户端先向第一个DataNOde写一部分(默认4KB),写完之后再写第二个4KB,此时第一个DataNode就会把第一个4KB写给第二个DataNode,以此类推,这个过程就是多级流水线。
3.1.4 文件删除
用户删除的文件不会立刻被删除,会被存放/trash文件夹下。在/trash中的生命期结束后,NameNode删除文件HDFS名称空间。删除一个文件会导致与该文件相关联的块释放。
3.2 元数据管理
日志:记录文件的操作。对文件的所有的修改都被保存在了EditLog中,这是一种事务性的日志。日志文件被保存在NameNode的本机的LFS上。
FsImage:记录整个命名空间的信息。文件系统的信息包括:数据块的映射和文件系统的相关配置信息。和EditLog一样,FsImage也被存放在NameNode的LFS上。
检查点:当NameNode进程启动时,会对将FsImage和EditLog全部读入到内存中,依照EditLog中执行的事务对FsImage进行更新。接着将FsImage持久化并丢弃旧的EditLog,开始写入新的EditLog。检查点会发生在NameNode启动时,并在运行的过程中会定期执行。
Blockreport:DataNode也将文件块存储在自身的LFS。当一个DataNode进程启动时,它会扫描LFS中存储的块并向NameNode发送自己机器上存储的块信息。
3.3 系统鲁棒性
3.3.1 心跳机制
每个DataNode会定期向NameNode发送自己的心跳,如果在指定时间内没有发送,就认为该DataNode死掉了。一个DataNode 的下线会导致:文件的副本数减少。此时NameNode会启动新的文件复制。
3.3.2 负载均衡
在一个集群中,HDFS会向空闲空间较大的DataNode转移blocks,同时也会对热点文件进行增加副本的操作,以提高读取的效率。
3.3.3 数据完整性校验 (Checksum)
由于文件被分成多个块存储,所以一个块出现错误都会导致文件不可用。**HDFS客户端软件实现对HDFS文件内容的校验和检查。**对文件求一个校验码,当用户读取文件时会比对这个校验码。
3.3.4 元数据管理
FSImage和EditLog是最重要的元数据。二者在NameNode上可能存在多个副本。每次发生修改时都要对所有的副本进行修改。当NameNode启动时,会使用最新版的元数据。
3.3.5 租约
为了防止多个进程同时对一个文件进行写操作,HDFS采用了租约的方式。每次写入一个文件时,客户端必须从NameNode处获取一个**具有一定时限的租约。**租约到期,客户端需要再次申请才可以继续写入这个文件。
参考文献
01.《MapReduce2.0源码分析与实战编程》
02. HDFS Architecture Guide