【Python】SVM分类 特征标准化+网格搜索最优模型参数+十折交叉验证
scikit-learn中文文档
scikit-learn英文官网
from sklearn import svm # svm函数需要的
import pandas as pd
import numpy as np # numpy科学计算库
from sklearn import model_selection
import matplotlib.pyplot as plt # 画图的库
from sklearn.metrics import accuracy_score
from sklearn import metrics
import seaborn as sns
import mpld3
from sklearn import preprocessing
%matplotlib inline
#导入数据
#df = pd.read_csv(r'C:\Users\Administrator\Desktop\leosun\振动paper\ZHENDONG\数据\BFW_feature.csv')
df= pd.read_excel(r'C:\Users\Administrator\Desktop\aa.xlsx',sheet_name=1,index_col=None)
#设置y值
x = df.drop(["Type"],axis=1)
y = df["Type"]
#Z-Score标准化
#建立StandardScaler对象
zscore = preprocessing.StandardScaler()
# 标准化处理
x = pd.DataFrame(zscore.fit_transform(x))
#训练集和测试集划分
x_train, x_test, y_train, y_test = model_selection.train_test_split(x, y, test_size=0.2, random_state=1, shuffle=True)
#搭建模型
clf = svm.SVC(kernel='rbf',gamma=0.01, # 核函数
decision_function_shape='ovo', # one vs one 分类问题
C=100)
clf.fit(x_train, y_train) # 训练
# y_train_hat=clf.predict(x_train)
# y_test_hat=clf.predict(x_test)
# 预测
train_predict = clf.predict(x_train)
test_predict = clf.predict(x_test)
#准确率
train_acc = accuracy_score(y_train, train_predict)
test_acc = accuracy_score(y_test, test_predict)
# train_acc=clf.score(x_train, y_train) #训练集的准确率
# test_acc=clf.score(x_test,y_test) #测试集的准确率
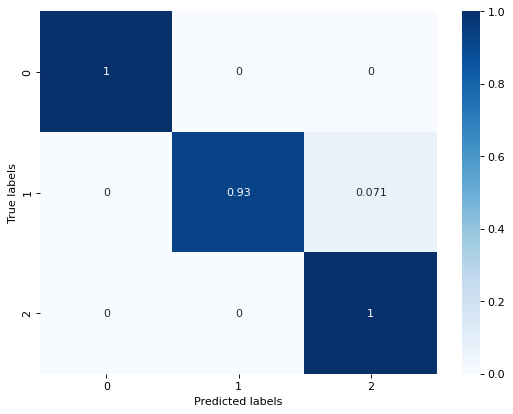
print ("SVM训练集准确率: {0:.3f}, SVM测试集准确率: {1:.3f}".format(train_acc, test_acc))
## 查看混淆矩阵 (预测值和真实值的各类情况统计矩阵)
confusion_matrix_result = metrics.confusion_matrix(test_predict,y_test)
np.set_printoptions(precision=2)
confusion_matrix = confusion_matrix_result.astype('float') / confusion_matrix_result.sum(axis=1)[:, np.newaxis]
plt.figure(figsize=(8,6), dpi=80)
sns.heatmap(confusion_matrix,annot=True, cmap='Blues')
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
#print(confusion_matrix)
plt.show()
out:
SVM训练集准确率: 1.000, SVM测试集准确率: 0.979
# K折交叉验证模块
from sklearn.model_selection import cross_val_score
#使用K折交叉验证模块
scores = cross_val_score(clf, x, y, cv=10, scoring='accuracy')
#将10次的预测准确率打印出
print(scores)
# [0.92 1. 0.83 0.88 0.91 0.96 1. 1. 0.78 0.74]
#将10次的预测准确平均率打印出0.901630434782608
print(scores.mean())
out:
[1. 1. 1. 1. 1. 1. 1. 0.91 0.91 1. ]
0.9826086956521738
# 基于svm 实现分类 # 基于网格搜索获取最优模型
from sklearn.model_selection import GridSearchCV
model = svm.SVC(probability=True)
params = [
{'kernel':['linear'],'C':[1,10,100,1000]},
{'kernel':['poly'],'C':[1,10],'degree':[2,3]},
{'kernel':['rbf'],'C':[1,10,100,1000],
'gamma':[1,0.1, 0.01, 0.001]}]
model = GridSearchCV(estimator=model, param_grid=params, cv=5)
model.fit(x, y)
# 网格搜索训练后的副产品
print("模型的最优参数:",model.best_params_)
print("最优模型分数:",model.best_score_)
print("最优模型对象:",model.best_estimator_)
out:
模型的最优参数: {'C': 100, 'gamma': 0.01, 'kernel': 'rbf'}
最优模型分数: 0.9744680851063829
最优模型对象: SVC(C=100, gamma=0.01, probability=True)