python编程--从入门到实践
第1章 起步
1.1 搭建测试环境
自行CSDN或B站查询,安装好python以及pycharm
第2章 变量和简单数据类型
2.1 运行hello_world.py时发生的情况
- 末尾的.py指出这是有个python程序,因此编辑器将使用Python解释器来运行它;
- Python解释器读取整个程序,确定其中每个单词的含义;
- 【语法突出】编写程序时,编辑器会以各种方式突出程序的不同部分;
2.2 变量
message="Hello python world!"
print(message)
message="hollo world"
print(message)运行这个程序,将看到这两行输出:
Hello python world!
hollo world
在程序中可随时改变量的值,而Python将始终记录变量的最新值。
2.2.1 变量的命名和使用
在python中使用变量时,需要遵守一些规则和指南。违反这些规则将引发错误,而指南旨在让你的代码更容易阅读和理解。
- 变量名只能包含字母、数字和下划线。变量名可以字母或者下划线打头,但不能数字打头;
- 变量名不能包含空格,但可使用下划线分隔其中的单词;
- 不要将python的关键字和函数名用作变量名,即不要使用python保留用于特殊用途的单词;
- 变量名应既简短又具有描述性;
- 慎用小写字母l和大写字母O;
2.2.2 使用变量时编码命名错误
2.3 字符串
字符串就是一系列字符。在python中,用引号括起来的都是字符串,其中的引号可以是单引号,也可以是双引号,如下所示:
'this is a string'
"this is also a string"2.3.1 使用方法修改字符串的大小写
name ="zhouPH"
print(name.title()) #首字母大写
print(name.upper()) #字符串全部大写
print(name.lower()) #字符串全部小写这些代码输出如下:
Zhouph
ZHOUPH
zhouph
2.3.2 合并(拼接字符串)
python使用加号(+)来合并字符串。
first_name = "ph"
last_name ="zhou"
fullname = first_name+" "+last_name
print(fullname)这些代码输出如下:
ph zhou
2.3.3 使用制表符或换行符来添加空白
print("languages:\n\tpython\n\tc\n\tjavaScript")这些代码输出如下:
languages:
python
c
javaScript
2.3.4 删除空白
language=' python '
print(language.rstrip()) #删除末尾空白
print(language.lstrip()) #删除开头空白
print(language.strip()) #删除两端空白这些代码输出如下:
python
python
python
2.3.5 使用字符串时避免语法错误
字符串中含撇号,不可用单引号
2.4数字
2.4.1 整数
- 在python中,可对整数执行加减乘除运算;
- python支持运算优先级;
- 空格不影响python计算表达式的方式;
2.4.2 浮点数
- python将带小数点的数字称为浮点数。
- 很大程度上,使用浮点数时都无需考虑其行为;但需要注意,结果包含的小数位可能是不确定的;
2.4.3 使用函数str避免类型错误
age = 23
messge = "happy " + str(age) + "rd Birthday"
print(messge)这些代码输出如下:
happy 23rd Birthday
2.5 注释
在python中,注释用#标识。#后面的内容都会被python解释器忽略;
第3章 列表简介
3.1 列表是什么
- 列表由一系列按特定顺序排列的元素组成;
- 在python中,用[]来表示列表,并用逗号来分隔其中的元素;
3.1.1 访问列表元素
列表是有序集合,因此要访问列表的任何元素,只需将该元素的位置或者索引告诉python即可;
phone = ['iphone','oppo','huawei','vivo']
print(phone[0])当你请求获取列表元素时,python只返回该元素,而不包含[]和引号:
iphone
3.1.2 索引从0而不是1开始
在python中,第一个列表的索引为0,而不是1;大多数编程语言都是如此,这与列表操作的底层实现相关;
phone = ['iphone','oppo','huawei','vivo']
print(phone[1])
print(phone[3])
print(phone[-2])这些代码返回列表的的第2个元素和第4个元素以及倒数第2个元素:
oppo
vivo
huawei
3.2 修改、添加和删除元素
你创建的大多数列都将是动态的,这意味这列表创建后,将随着程序的运行增删元素;
3.2.1 修改列表元素
phone = ['iphone','oppo','huawei','vivo']
phone[0]= 'ibanana'
print(phone)这些代码输出如下:
['ibanana', 'oppo', 'huawei', 'vivo']
你可以修改任何列表元素的值,而不仅仅是第一个元素的值;
3.2.2 在列表中添加元素
1、在列表末尾添加元素
phone = ['iphone','oppo','huawei','vivo']
phone.append('ibanana')
print(phone)这些代码输出如下:
['iphone', 'oppo', 'huawei', 'vivo', 'ibanana']
2、在列表中插入元素
使用insert()可在列表的任何位置添加新元素;为此你需要制定新元素的索引和值;
phone = ['iphone','oppo','huawei','vivo']
phone.insert(0,'ibanana')
print(phone)
这些代码输出如下:
['ibanana', 'iphone', 'oppo', 'huawei', 'vivo']
3、从列表中删除元素
1.使用del语句删除元素
phone = ['iphone','oppo','huawei','vivo']
del phone[0]
print(phone)这些代码输出如下:
['oppo', 'huawei', 'vivo']
2、使用方法pop删除元素
phone = ['iphone','oppo','huawei','vivo']
xx_phone = phone.pop()
print(phone) #远列表已删除最后一个值
print(xx_phone) #被删除的值保留在变量xx_phone中这些代码输出如下:
['iphone', 'oppo', 'huawei']
vivo
['iphone', 'oppo', 'huawei']
3、弹出列表中任何位置的元素
phone = ['iphone','oppo','huawei','vivo']
first_phone = phone.pop()
print('the first phone I owned was a '+first_phone.title()+'.')当你使用pop()时,被弹出的元素就不再在列表中了,这些代码输出如下:
the first phone I owned was a Vivo.
4、根据值删除元素
- 你不知道要删除的元素在列表中什么位置;
- 知道要删除元素的值,可以使用方法remove;
phone = ['iphone','oppo','huawei','vivo']
phone.remove('huawei') #确定’huawei‘出现在列表什么位置,并将该元素删除;
print(phone)这些代码输出如下:
['iphone', 'oppo', 'vivo']
3.3 组织列表
创建的列表中,元素的排序常常是无法预测的;python提供了很多组织列表的方式,可以根据具体情况使用;
3.3.1 使用方法sort()对列表进行永久性排序
cars=['bwm','audo','toyata','Cadillac']
cars.sort()
print(cars)
cars.sort(reverse=True)
print(cars)这些代码输出如下:
['Cadillac', 'audo', 'bwm', 'toyata']
['toyata', 'bwm', 'audo', 'Cadillac'
3.3.2 使用函数sorted()对列表进行临时排序
- 要保留列表原来的排列顺序,同时以特定的顺序呈现它们,可以使用函数sorted();
- 函数sorted()让你能够按特定的顺序显示列表元素,同时不影响它们在列表中的原始排列顺序;
cars=['bwm','audo','toyata','Cadillac']
print('here is the original list: ')
print(cars)
print("\nhere is the sorted list: ")
print(sorted(cars))
print("\nhere is the original list again")
print(cars)这些代码输出如下:
here is the original list:
['bwm', 'audo', 'toyata', 'Cadillac']here is the sorted list:
['Cadillac', 'audo', 'bwm', 'toyata']here is the original list again
['bwm', 'audo', 'toyata', 'Cadillac']
3.3.3 倒着打印列表
方法revers()永久性地修改元素地排列顺序,但可以恢复到原来地排序顺序,再次调用reverse()即可;
cars=['bwm','audo','toyata','Cadillac']
print(cars)
cars.reverse()
print(cars)这些代码输出如下:
['bwm', 'audo', 'toyata', 'Cadillac']
['Cadillac', 'toyata', 'audo', 'bwm']
3.3.4 确认列表地长度
使用函数len()可快速获取列表地长度;
cars=['bwm','audo','toyata','Cadillac']
print(len(cars))这些代码输出如下:
4
注意:python计算列表元素数时从1开始,因此确认列表长度时,你应该不会遇到差一错误;
3.4 使用列表时避免索引错误
cars=['bwm','audo','toyata','Cadillac']
print(cars[3])注意:列表索引差一的特征,这些代码输出如下:
Cadillac
第4章 操作列表
4.1 遍历 整个列表
用for循环来打印菜单:
meau = ['饺子','小笼包','汤包','油条','烧饼','馄饨']
for food in meau:
print(food)这些代码输出如下:
饺子
小笼包
汤包
油条
烧饼
馄饨
4.1.1 深入地研究循环
for food in meau:这行代码让python获取列表meau中地第一个值('饺子'),并将其存储到变量food中;
接下来,python读取下一行代码:
print(food)它会让python打印的值——依然是'饺子';鉴于该列表还包含其他值,python返回到循环的第一行:
for food in meau:python获取列表中下一个名字——'小笼包',并将它存储到food中,在执行下面这行代码:
print(food)python再次打印变量food的值;接下来执行这个循环;
对列表最后一个值 '馄饨'进行处理,至此,列表再无其他值,因此python接着执行下一行代码,在示例中,for循环没有其他代码,因此程序就此结束。
4.1.2 在for循环中执行更多的操作
meau = ['饺子', '小笼包', '汤包', '油条', '烧饼', '馄饨']
for food in meau:
print(food + ', 真是太美味了!!!')这些代码输出如下:
饺子, 真是太美味了!!!
小笼包, 真是太美味了!!!
汤包, 真是太美味了!!!
油条, 真是太美味了!!!
烧饼, 真是太美味了!!!
馄饨, 真是太美味了!!!
for 循环中,想包含多少行代码都可以。实际上,你会发现使用for循环对每个元素执行众多不同的操作很有用。
4.1.3 在for循环结束后执行一些操作
meau = ['饺子', '小笼包', '汤包', '油条', '烧饼', '馄饨']
for food in meau:
print(food + ', 真是太美味了!!!')
print('哈哈哈哈哈\n')
print('吃了好了东西,撑死我了')这些代码输出如下:
饺子, 真是太美味了!!!
哈哈哈哈哈小笼包, 真是太美味了!!!
哈哈哈哈哈汤包, 真是太美味了!!!
哈哈哈哈哈油条, 真是太美味了!!!
哈哈哈哈哈烧饼, 真是太美味了!!!
哈哈哈哈哈馄饨, 真是太美味了!!!
哈哈哈哈哈
- 吃了好了东西,撑死我了
在for循环后面,没有缩进的代码都只执行一次,而不会重复执行。
4.2 避免缩进错误
- python根据缩进来判断代码行与前一个代码的关系;
- python通过使用缩进让代码更加易读;简单地说,他要求你使用缩进让代码整洁而结构清晰;
- 注意缩进错误;
缩进错误:
-
忘记缩进;
-
忘记缩进额外的代码行;
-
不必要的缩进;
-
循环后不必要的缩进;
-
遗漏冒号
4.3 创建数字列表
列表非常适合用于存储数字集合,而python提供了很多工具,可帮助你高效地处理数字列表;
4.3.1 使用函数range()
python函数range()让你能轻松地生成一系列的数字;
for value in range(1,5):
print(value)这些代码输出如下:
1
2
3
4
示例中,range()只是打印数字1~4,编程语言中常见的差一行为的结果;
4.3.2 使用range()创建数字列表
要创建数字列表,可使用函数list()将range()的结果直接转换为列表;
如果将range()作为list()的参数,输出将为一个数字列表;
numbers = list(range(1,5))
print(numbers)这些代码输出如下:
[1, 2, 3, 4]
使用range()时,还可以指定步长;
下面代码打印1~10以内的偶数:
even_number = list(range(2,11,2))
print(even_number)这些代码输出如下:
[2, 4, 6, 8, 10]
打印1~10值的平方,将结果存储到square,再将平方值附加到列表squares末尾
squares = []
for value in range(1,11):
square = value**2
squares.append(square)
print(squares)这些代码输出如下:
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
4.3.3 对数字列表执行简单的统计计算
digits = list(range(1,11))
print(max(digits))
print(min(digits))
print(sum(digits))这些代码输出如下:
10
1
55
4.3.4 列表解析
squares =[value**2 for value in range(1,11)]
print(squares)结果与之前的一样,经常练习,熟悉建表常规;
4.4 使用列表的一部分
你还可以处理列表的部分元素——python称之为切片;
4.4.1 切片
player =['姚明','易建联','米兰中锋','王治郅','科比']
print(player[0:3])
print(player[:4])
print(player[-3:])
print(player[:-1])这些代码输出如下:
['姚明', '易建联', '米兰中锋']
['姚明', '易建联', '米兰中锋', '王治郅']
['米兰中锋', '王治郅', '科比']
['姚明', '易建联', '米兰中锋', '王治郅']
4.4.2 遍历切片
players =['姚明','易建联','米兰中锋','王治郅','科比']
for player in players[:3]:
print(player)这些代码输出如下:
姚明
易建联
米兰中锋
4.4.3 复制列表
my_foods = ['披萨','蛋糕','麦当劳','蛋挞']
friend_foods = my_foods[:]
print(my_foods)
print(friend_foods)这些代码输出如下:
['披萨', '蛋糕', '麦当劳', '蛋挞']
['披萨', '蛋糕', '麦当劳', '蛋挞']
4.5 元组
- 列表非常适合存储在程序运行期间可能变化的数据集;
- 列表是可以修改的;
- 有时候你需要创建一系列不可修改的元素,元组可以满足这种需求;
- python将不能修改的值称为不可变的额,而不可变的列表被称为元组;
4.5 1 定义元组
元组看起来犹如列表,但用圆括号而不是方括号来标识。定义元组后,就可以使用索引来访问其他元素,就像访问列表元素一样;
dimensions = (200 , 50)
print(dimensions)
print(dimensions[0])
dimensions[0] = 100 #TypeError: 'tuple' object does not support item assignment
print(dimensions)这些代码输出如下:
(200, 50)
200
Traceback (most recent call last):
File "C:\Users\DELL\PycharmProjects\pythonProject\dome4.py", line 58, in
dimensions[0] = 100
TypeError: 'tuple' object does not support item assignment
-
dimensions[0] = 100 试图修改第一个元素的值,导致python返回类型错误消息;
- 试图修改元组的操作是被禁止的,因此python支持不能给元组的元素赋值;
4.5.2 遍历元组中的所有值
像列表一样,也可以使用for循环来遍历元组中的所有值:
dimensions = (200 , 50)
for dimension in dimensions:
print(dimension)这些代码输出如下:
200
50
4.5.3 修改元组的变量
虽然不能修改元组的元素,但可以给存储元组的变量赋值;
dimensions = (200 , 50)
for dimension in dimensions:
print(dimension)
dimensions = (400 , 80)
for dimension in dimensions:
print(dimension)这些代码输出如下:
200
50
400
80
4.6 设置代码格式
4.6.1 格式设置指南
4.6.2 缩进
4.6.3 行长
4.6.4 空行
4.6.5 其他格式设置指南
第5章 IF语句
5.1 一个简单的示例
cars = ['bwm','dudi','subaru','toyota']
for car in cars:
if car =='bwm':
print(car.upper())
else:
print(car.title())这些代码输出如下:
BWM
Dudi
Subaru
Toyota
5.2 条件测试
- 每条if语句的核心都是一个值为True或False的表达式,这种表达式被称为条件测试;
- python根据条件测试的值为True还是False来决定执行if语句中的代码;
- 如果条件测试的值为True,python就执行紧跟在if语句后面的代码;如果为false,python就忽略这些代码;
5.2.1 检查是否相等
car ='bwm'
print(car == 'bwm')
print(car == 'audi')这些代码输出如下:
True
False
5.2.2 检查是否相等时不考虑大小写
在python中检查是否相等时区分大小写,例如,两个大小写不同的值会被视为不相等:
car='Audi'
print(car == 'audi')这些代码输出如下:
False
如果大小写很重要,这种行为有其优点;
但如果大小写无关紧要,而只想检查变量的值,可将变量的值转换为小写,在进行比较;
car='Audi'
print(car.lower() == 'audi')这些代码输出如下:
True
5.2.3 检查是否不相等
要判断两个值是否不等,可使用(!=),其中!表示不,在很多编程语言中都如此;
x1 = 1
if x1 != 2:
print(str(x1)+"这个数字不是2")这些代码输出如下:
1这个数字不是2
你编写的大多数条件表达式都检查两个字是否相等,但有时候检查两个值是否不等效率更高。
5.2.4 比较数字
检查数值非常简单,例如,下面的代码检查一个人是否18岁:
age = 18
print(age == 18)这些代码输出如下:
True
下面代码在提供答应不正确时答应一条消息:
answer = 17
if answer != 42:
print("that is not the correct answer.please try again")这些代码输出如下:
that is not the correct answer.please try again
条件语句可包含各种数学比较:
age = 26
print(age < 21)
print(age <= 21)
print(age >= 21)
print(age > 21)
print(age != 21)这些代码输出如下:
False
False
True
True
True
5.2.5 检查多个条件
- 同时检查多个条件,有时候需要同时为True才能执行;
- 有时候只要求一个条件满足为True就执行相应操作;
- 关键字and和or可助你一臂之力;
1、 使用and检查多个条件
age_0 = 22
age_1 = 33
print(age_0 >= 21 and age_1 <=22)
print(age_0 >= 21 and age_1 <=44)这些代码输出如下:
False
True
为改善可读性,建议改成:
age_0 = 22
age_1 = 33
print((age_0 >= 21) and (age_1 <=22))
print((age_0 >= 21) and (age_1 <=44))2、 使用or检查多个条件
age_0 = 22
age_1 = 18
print((age_0>21)or(age_1>=21))
print((age_0>22)or(age_1>=21))这些代码输出如下:
True
False
5.2.6 检查特定值是否包含在列表中
cars = ['bwm','dudi','subaru','toyota']
print('bwm' in cars)这些代码输出如下:
True
5.2.7 检查特定值是否不包含在列表中
cars = ['bwm','dudi','subaru','toyota']
car ='凯迪拉克'
if car not in cars:
print(car.title()+',这车不在车库里面')这些代码输出如下:
凯迪拉克,这车不在车库里面
5.2.8 布尔表达式
布尔表达式的结果要么为True,要么为False
5.3 if语句
5.3.1 简单的if语句
age =19
if age >= 18:
print("you are old enough to vote!")这些代码输出如下:
you are old enough to vote!
5.3.2 if-else 语句
age =17
if age >= 18:
print("you are old enough to vote!")
else:
print("sorry,you are too young to vote")这些代码输出如下:
sorry,you are too young to vote
5.3.3 if-elif-else结构
age =12
if age <4:
print("your adminssion cast is $0")
elif age <18:
print("your adminssion cost is $5")
else:
print("your adminssion cost is $10")这些代码输出如下:
your adminssion cost is $5
5.3.4 使用多个而立法代码块
age =77
if age <4:
print("your adminssion cast is $0")
elif age <18:
print("your adminssion cost is $5")
elif age <65:
print("your adminssion cost is $10")
else:
print("your adminssion cost is $0")
这些代码输出如下:
your adminssion cost is $0
5.3.5 省略else代码块
- python并不要求if-elif结构后面必须有else代码块;
- 在一些情况下else代码块很有用;
- 而在其他一些情况下,使用一条elif语句来处理特定的情形更清晰;
age =77
if age <4:
print("your adminssion cast is $0")
elif age <18:
print("your adminssion cost is $5")
elif age <65:
print("your adminssion cost is $10")
elif age >65:
print("your adminssion cost is $0")这些代码输出如下:
your adminssion cost is $0
5.3.6 测试多个条件
- if-elif-else结构功能强大,但仅适合用于只有一个条件满足的情况:
- 遇到通过了的测试后,python就会跳过余下的测试。这种行为很好,效率很高,让你能够测试一个特定的条件;
requested_toppings =['mushrooms','extra cheese']
if 'mushrooms' in requested_toppings:
print("adding mushrooms")
if 'pepperoni' in requested_toppings:
print("adding pepperoni")
if 'extra cheese' in requested_toppings:
print("adding extra cheese")
print("\nFinished making your pizza!")这些代码输出如下:
sorry,you are too young to vote
your adminssion cost is $0
your adminssion cost is $0
adding mushrooms
adding extra cheeseFinished making your pizza!
5.4 使用if语句处理列表
5.4.1 检查特殊元素
requested_toppings =['mushrooms','extra cheese','pepperoni']
for requested_topping in requested_toppings:
print("adding "+requested_topping+".")
print("\nFinished making your pizza!")这些代码输出如下:
Finished making your pizza!
adding mushrooms.
adding extra cheese.
adding pepperoni.Finished making your pizza!
5.4.2 确认列表不是空的
requested_toppings = []
if requested_toppings:
for requested_topping in requested_toppings:
print("adding " + requested_topping + ".")
print("\nFinished making your pizza!")
else:
print("are you sure want a plain pazzia")这些代码输出如下:
are you sure want a plain pazzia
5.4.3 使用多个列表
available_toppings = ['mushrooms','olives','green peppers','pepperoni','pineapple','extra cheese']
requested_toppings =['mushrooms','extra cheese','pepperoni']
for available_topping in requested_toppings:
if requested_topping in available_toppings:
print("adding "+requested_topping+".")
else:
print("sorry we don't have "+ requested_topping+".")这些代码输出如下:
adding pepperoni.
adding pepperoni.
adding pepperoni.
5.5 设置if语句的格式
PEP8提供的唯一建议:在诸如==、>=和<=比较运算符两边各添加一个空格,例如 if age < 4比if age<4 好
第6章 字典
6.1 一个简单的字典
alien_0={'color':'green','point':5}
print(alien_0['color'])
print(alien_0['point'])这些代码输出如下:
green
5
6.2 使用字典
- 在python钟,字典是一系列键-值对。每个键都与一个值相关联,你可以使用键来访问;
- 与键相关联的值可以是数字、字符串、列表乃至字典;
- 键-值对是两个相关联的值;
- 指定键时,python将返回与之相关联的值,键与值之间用:分隔,而键-值对之间用逗号分隔;
- 在字典中,你像存储多少个键-值对都可以;
- 最简单的字典只有一个键-值对,如下属所示:alien_0={'color':'green'}
6.2.1 访问字典中的值
要获取与键相关联的值,可依次指定字典名和放在方括号内的键,如下所示:
alien_0={'color':'green'}
print(alien_0['color'])这些代码输出如下:
green
字典中可包含任意数量的键-值对
alien_0={'color':'green','point':5}
new_points = alien_0['point']
print("you just earned " + str(new_points)+"")这些代码输出如下:
you just earned 5
6.2.2 添加键-值对
- 字典是一种动态结构,可随时在其中添加键-值对;
- 要添加键-值对,可以此指定字典名、用方括号[]括起的键和相关联的值;
alien_0={'color':'green','point':5}
alien_0['x_position'] = 0
alien_0['y_position'] = 25
print(alien_0)这些代码输出如下:
{'color': 'green', 'point': 5, 'x_position': 0, 'y_position': 25}
注意:
- 键-值对的排列顺序与添加顺序不同;
- python不关心键-值对的添加顺序,而只关心键和值之间的关联关系;
6.2.3 先创建一个空字典
alien_0 = {}
alien_0['color'] = 'green'
alien_0['point'] = '5'
print(alien_0)这些代码输出如下:
{'color': 'green', 'point': '5'}
使用字典俩存储用户提供的数据或在编写能自动生产大量键-值对的代码时,通常都需要先定义一个空字典;
6.2.4 修改字典中的值
alien_0 = {'color':'green'}
print("the alien is now "+alien_0['color'] + ".")
alien_0['color'] = 'yellow'
print("the alien is now "+alien_0['color'] + ".")这些代码输出如下:
the alien is now green.
the alien is now yellow.
6.2.5 删除键-值对
- 对于字典不再需要的信息,可使用del语句将相应的键-值对彻底删除;
- 用del语句时,必须指定字典名和要删除的键;
alien_0={'color':'green','point':5}
print(alien_0)
del alien_0['point']
print(alien_0)这些代码输出如下:
{'color': 'green', 'point': 5}
{'color': 'green'}
删除的键-值对永久消失了
6.2.6 由类似对象组成的字典
favorite_languages ={
'jen':'python',
'sarah':'c',
'edward':'ruby',
'pjil':'python'
}
print("sarah's favorite language is "+favorite_languages['sarah'].title()+".")这些代码输出如下:
sarah's favorite language is C.
6.3 遍历字典
- 一个python的字典可能包含几个键-值对,也可能包含数百万个键值对;
- 鉴于字典可能包含大量数据,python支持各自方式存储信息;
- 因此有多种遍历字典的方式:可遍历字典的所有键-值对、键或值;
6.3.1 遍历所有的键-值对
for key,value in user_0.items():
print("\nkey: "+key)
print("key: "+value)这些代码输出如下:
key: username
key: bananakey: first
key: enricokey: last
key: fermi
6.3.2 遍历字典中所有的键
favorite_languages ={
'jen':'python',
'sarah':'c',
'edward':'ruby',
'pjil':'python'
}
for name in favorite_languages.keys():
print(name.title())这些代码输出如下:
Jen
Sarah
Edward
Pjil
- 遍历字典时候,会默认遍历所有的键;
- 因此,如果将上述代码中的for name in favorite_languages.keys(): 替换成 for name in favorite_languages:,输出将不变;
friends = ['phil','sarah']
for name in favorite_languages.keys():
print("\n"+name.title())
if name in friends:
print(" hi "+name.title()+", I see your favorite language is "+favorite_languages[name].title()+"!")这些代码输出如下:
Jen
Sarah
hi Sarah, I see your favorite language is C!Edward
Pjil
6.3.3 按顺序遍历字典中的所有键
- 字典总是明确的记录键和值之间的关联关系,但获取字典的元素时,获取的顺序是可以预测的;
- 要以特定的顺序返回元素,一种办法是在for循环在对返回的键进行排序;为此,可用函数sorted()来获得按特定顺序排列的键列表的副本;
favorite_languages ={
'jen':'python',
'sarah':'c',
'edward':'ruby',
'pjil':'python'
}
for name in sorted(favorite_languages.keys()):
print(name.title()+" ,thank you fir taking the poll.")这些代码输出如下:
Edward ,thank you fir taking the poll.
Jen ,thank you fir taking the poll.
Pjil ,thank you fir taking the poll.
Sarah ,thank you fir taking the poll.
6.3.4 遍历字典中的所有值
如果你感兴趣的主要是字典包含的值,可使用values(),它返回一个值列表,而不包含任何键;
favorite_languages ={
'jen':'python',
'sarah':'c',
'edward':'ruby',
'pjil':'python'
}
print("the following langguages have been mentioned:")
for language in favorite_languages.values():
print(language.title())这些代码输出如下:
the following langguages have been mentioned:
Python
C
Ruby
Python
- 这种做法提取字典中所有的值,而没有考虑是否重复;
- 涉及的值很少时,这不是问题,但被调查者很多,最终的列表可能包含大量重复;
- 为剔除重复项, 可使用集合(set);集合类似于列表,但每个元素都必须是独一无二的;
favorite_languages ={
'jen':'python',
'sarah':'c',
'edward':'ruby',
'pjil':'python'
}
print("the following langguages have been mentioned:")
for language in set(favorite_languages.values()):
print(language.title())这些代码输出如下:
the following langguages have been mentioned:
Ruby
Python
C
结果是一个不重复的列表,其中列出了被调查者提及的所有语言。
6.4 嵌套
有时候,需要将一系列字典存储在列表中,或将列表作为值存储在字典中,这称为嵌套;
6.4.1 字典列表
alien_0 = {'color':'green','points':5}
alien_1 = {'color':'yellow','points':10}
alien_2 = {'color':'red','points':15}
aliens =[alien_0,alien_1,alien_2]
for alien in aliens:
print(alien)这些代码输出如下:
{'color': 'green', 'points': 5}
{'color': 'yellow', 'points': 10}
{'color': 'red', 'points': 15}
用range()生成30个外星人:
aliens =[]
for alien_number in range(30):
new_alien = {'color':'green','points':5,'speed':'slow'}
aliens.append(new_alien)
#显示前五个外星人
for alien in aliens[:5]:
print(alien)
print("tatal bumber if aliens: "+ str(len(aliens)))这些代码输出如下:
{'color': 'green', 'points': 5, 'speed': 'slow'}
{'color': 'green', 'points': 5, 'speed': 'slow'}
{'color': 'green', 'points': 5, 'speed': 'slow'}
{'color': 'green', 'points': 5, 'speed': 'slow'}
{'color': 'green', 'points': 5, 'speed': 'slow'}
tatal bumber if aliens: 30
修改前三个外星人为黄色、速度中且值10个点:
aliens =[]
for alien_number in range(30):
new_alien = {'color':'green','points':5,'speed':'slow'}
aliens.append(new_alien)
for alien in aliens[0:3]:
if alien['color'] == 'green':
alien['color'] = 'yellow'
alien['point'] = 10
alien['speed'] = 'medium'
for alien in aliens[0:5]:
print(alien)这些代码输出如下:
{'color': 'yellow', 'points': 5, 'speed': 'medium', 'point': 10}
{'color': 'yellow', 'points': 5, 'speed': 'medium', 'point': 10}
{'color': 'yellow', 'points': 5, 'speed': 'medium', 'point': 10}
{'color': 'green', 'points': 5, 'speed': 'slow'}
{'color': 'green', 'points': 5, 'speed': 'slow'}
6.4.2 在字典中存储列表
有时候,需要将列表存储在字典中,而不是字典存储在列表中;
6.4.3 在字典中存储字典
可在字典中嵌套字典,但这样做,代码可能很快复杂起来;
例如:如果有多个网址用户,每个人都有独特的用户名,可在字典中将用户名作为键,然后将每位用户的信息存储到一个字典中,并将改字典作为用户名相关联的值。
users = {
'aeinstein' : {
'first' : 'albert',
'last' : 'einstein',
'location' : 'princeton',
} ,
'mcurie' : {
'first' : 'marie',
'last' : 'curie',
'location' : 'paris'
}
}
for username , user_info in users.items():
print("\nUsername: "+ username)
full_name = user_info['first'] + " " + user_info['last']
location = user_info['location']
print("\tFull name: " + full_name.title())
print("\tLocation: " + location.title())这些代码输出如下:
Username: aeinstein
Full name: Albert Einstein
Location: PrincetonUsername: mcurie
Full name: Marie Curie
Location: Paris
第7章 用户输入和while循环
7.1 函数 input()的工作原理
- 函数input()让程序暂停运行,等待用户输入一些文本。获取用户输入后,python将其存储在一个变量中,以方便你使用;
message = input("tell me something, and I will repeat it back to you: ")
print(message)这些代码输出如下:
tell me something, and I will repeat it back to you: 所有的伟大都源于一次勇敢的开始
所有的伟大都源于一次勇敢的开始
函数input() 接受一个参数:即要向用户显示的提示或说明,让用户知道改如何做;
7.1.1 编写清晰的程序
每当你使用函数input()时,都应该指定清晰而易于明白的指示,准确地指出你希望用户提供什么样地信息——任何指出用户改输入何种信息地提示都行,如下所示:
name = input("please enter your name :")
print("hello, "+name + "!")这些代码输出如下:
please enter your name :周周周
hello, 周周周!
7.1.2 使用int()来获取数值输入
使用函数int()时,python将用户输入读为字符串。请看下面让用户输入其年龄地解释器会话:
age = input("how old are you? ")
print(age>21)这些代码输出如下:
how old are you? 21
Traceback (most recent call last):
File "C:\Users\DELL\PycharmProjects\pythonProject\demo7.py", line 8, in
print(age>21)
TypeError: '>' not supported between instances of 'str' and 'int'
- 用户输入地是数字21,但我们请求python提供变量age的值时,它返回的是'21'——用户输入的数值的字符串表示;
- 我们只想打印输入,这没有问题;但试图将输入作为数字使用,就会引发错误;
age = input("how old are you? ")
age = int(age)
print(print(age>21))这些代码输出如下:
how old are you? 21
False
7.1.3 求模运算符
处理数值信息时,求模运算符(%)是一个很有用的工具,它将两个数相除并返回余数;
print(4%3)
print(7%3)
print(8%3)
print(9%3)
print(10%3)这些代码输出如下:
1
1
2
0
1
- 求模运算符不会指出一个数是另一个数的多少倍,而之指出余数是多少;
- 一个数可悲另一个数整除,余数就为0,因此求模运算符将返回0;你可以利用这点来判断一个数是奇数还是偶数:
number = input('enter a number,and I will tell you if it is even or odd: ')
number = int(number)
if number%2 == 0:
print("\nthe number " +str(number) + "is even")
else:
print("\nthe number " +str(number) + "is odd ")这些代码输出如下:
enter a number,and I will tell you if it is even or odd: 9999
the number 9999 is odd
7.2 while 循环简介
for循环用于针对集合中的每个元素的一个代码块,而while循环不断地运行,直到指定地条件不满足为止;
7.2 1 使用while循环
number = 1
while number <= 5:
print(number)
number +=1这些代码输出如下:
1
2
3
4
5
7.2.2 让用户选择何时退出
- 可使用while循环让程序在用户愿意时不断地运行,如下面地程序所示;
- 我们在其中定义了一个退出值,只要用户输入地不是这个值,程序就接着运行;
number = 1
while number <= 5:
print(number)
number +=1;
prompt = "\ntell me something, and I will repeat it back to you: "
prompt += "\nEnter 'quit' to end the program ."
message = ""
while message!='quit':
message = input(prompt)
print(message)
这些代码输出如下:
tell me something, and I will repeat it back to you:
Enter 'quit' to end the program .哈哈哈哈
哈哈哈哈tell me something, and I will repeat it back to you:
Enter 'quit' to end the program .哈哈哈
哈哈哈tell me something, and I will repeat it back to you:
Enter 'quit' to end the program .quit
quitProcess finished with exit code 0
7.2.3 使用标志
在前一个示例中,我们让程序在满足指定条件时就执行特定地任务。但在更复杂地程序中,很多不同地事件都会导致程序停止运行;在这种情况下,该怎么办呢?
在要求很多条件地满足才继续运行地程序中,定义一个变量,用于判断整个程序是否处于活动状态;这个变量称之为标志,充当了程序地交通信号灯。
可以让程序标准为True时继续运行,并在任何事件导致标准为False时让程序停止运行;这样while语句中就只需要检查一个条件——标志地当前值是否为True,并将所有测试测试都放在其他地方,从而让程序编程更为整洁;
prompt = "\ntell me something, and I will repeat it back to you: "
prompt += "\nEnter 'quit' to end the program ."
active = True
while active:
message = input(prompt)
if message == 'quit':
active = False
else:
print(message)这些代码输出如下:
tell me something, and I will repeat it back to you:
Enter 'quit' to end the program .xx
xxtell me something, and I will repeat it back to you:
Enter 'quit' to end the program .xxxx
xxxxtell me something, and I will repeat it back to you:
Enter 'quit' to end the program .quitProcess finished with exit code 0
7.2.4 使用break推出循环
- 要立刻退出while循环,不再运行循环中余下地代码,也不管条件测试地结果如何,可使用break语句;
- break语句用于控制程序流程,可使用它来控制哪些代码将执行,哪些代码不执行,从而让程序按你地要求执行你要执行地代码;
prompt = "\nplease enter the name of a city you have visited: "
prompt += "\nEnter 'quit' to end the program ."
while True:
city = input(prompt)
if city == 'quit':
break
else:
print("I'd love to go to "+ city.title() + "!")这些代码输出如下:
please enter the name of a city you have visited:
Enter 'quit' to end the program .杭州
I'd love to go to 杭州!please enter the name of a city you have visited:
Enter 'quit' to end the program .上海
I'd love to go to 上海!please enter the name of a city you have visited:
Enter 'quit' to end the program .北京
I'd love to go to 北京!please enter the name of a city you have visited:
Enter 'quit' to end the program .
- 以while True 打头地循环将不断进行,直到遇到break语句;
- 这个程序中地循环不断输入用户到过地城市名字,知道他输入'quit'为止;
- 用户输入‘quit’后,将执行break语句,导致python退出循环;
注意:在任何Python循环中都可以使用break语句。例如,可使用break语句来退出遍历列表或字典地for循环。
7.2.5 在循环中使用continue
- 要返回循环开头,并根据条件测试结果决定是否继续执行循环,可使用continue语句;
- 不像break语句那样不在执行余下地代码并退出整个循环;
例如从1数到10,值打印其中技术地循环:
number = 0
while number < 10:
number += 1
if number % 2 == 0:
continue
print(number)这些代码输出如下:
1
3
5
7
9
- 首先我们将number设置成了0,由于它小于10,python进入了while循环;
- 进入循环后,我们以步长1往上数,因此number为1;
- 接下来if 语句检查number与2的求模运算,如果结果为0,就执行continue语句,让python忽略余下的代码,并返回到循环的开头;
- 如果当前数字不能被2整除,就执行循环中的余下代码,Python将这个数字打印出来;
7.2.6 避免无限循环
每个while循环都必须有停止运行的途径,这样才不会没完没了的执行下去;
注意:有些编辑器内嵌了输出窗口,这可能导致难以接受无限循环,因此不得不关闭编辑器来结束无限循环。
7.3 使用while 循环来处理列表和字典
- 到目前为止,我们每次都处理了一项用户信息:获取用户的输入,再将输入打印出来或做出应答;
- 循环再次运行时,我们获悉另一个输入值并作出响应;
- 然而,要记录大量的用户和信息,需要再while循环中使用列表和字典;
7.3.1 再列表之间移动元素
假设有一个列表,其中包含新注册但还未验证的网站客户;
验证这些用户后,如何将他们移到另一个已验证用户列表中
#首先,创建一个待验证的用户列表
#和一个用于存储已验证用户的空列表
unconfirmed_users = ['alice','brian','candace']
confirmed_users = []
while unconfirmed_users:
current_user = unconfirmed_users.pop()
print("verifying user: " + current_user.title())
confirmed_users.append(current_user)
#显示所有已验证的用户
print("\nthe following user have been confirmed:")
for confirmed_user in confirmed_users:
print(confirmed_user.title())这些代码输出如下:
the following user have been confirmed:
Candace
Brian
Alice7.3.2 删除包含特定值的所有列表元素
在第3章,我们使用方法remove()来删除列表中的特定值,这之所以可行,是因为要删除的值再列表中只出现了一次;如果要删除列表中所有包含特定值的元素,该怎么办?
pets = ['dog','cat','dog','goldfish','cat','rabbit','cat']
print(pets)
while 'cat' in pets:
pets.remove('cat')
print(pets)
print(pets)这些代码输出如下:
['dog', 'cat', 'dog', 'goldfish', 'cat', 'rabbit', 'cat']
['dog', 'dog', 'goldfish', 'cat', 'rabbit', 'cat']
['dog', 'dog', 'goldfish', 'rabbit', 'cat']
['dog', 'dog', 'goldfish', 'rabbit']
['dog', 'dog', 'goldfish', 'rabbit']
7.3.3 使用用户输入来填充字典
可使用while 循环提示用户输入任意数量的信息;
responses ={}
polling_active =True
while polling_active:
name = input("\nwhat is your name? ")
response = input("which moutain would you like to climb somday? ")
responses[name] = response
repeat = input("would you like to let anther person resond?(yes/no)")
if repeat =='no':
polling_active =False
print("\n--- Poll Results ---")
for name, response in responses.items():
print(name +"would like to climb "+ response +".")这些代码输出如下:
what is your name? 爸爸
which moutain would you like to climb somday? 泰山
would you like to let anther person resond?(yes/no)yeswhat is your name? 妈妈
which moutain would you like to climb somday? 泰山
would you like to let anther person resond?(yes/no)no--- Poll Results ---
爸爸would like to climb 泰山.
妈妈would like to climb 泰山.
第8章 函数
8.1 定义函数
def greet_user():
print("hello 哒哒哒")
greet_user()这些代码输出如下:
hello 哒哒哒
8.1.1 向函数传递信息
def greet_username(username):
print("Hello, " + username.title() + "!")
greet_username('dada')这些代码输出如下:
Hello, Dada!
8.1.2 实参和形参
基本定义
- 形参:形式参数,在定义函数时,函数名后面括号中的参数;
- 实参:实际参数,在调用函数时,函数名后面括号内的参数,也就是将函数的调用者提供给函数的参数成为实际参数。
两种情况
- 值传递
- 将实际参数的值传递给形式参数;
- 当实际参数为不可变对象时,进行的是值传递
- 引用传递
- 将实际参数的引用传递给形式参数;
- 当实际参数为可变对象时,进行的是引用传递。
值传递和引用传递的基本区别是,进行值传递后,形式参数的值发生改变,实际参数的值不变;而进行应用传递后,形式参数的值发生改变,实际参数的值也一样发生改变。
由此可见值传递和引用传递的关键是可变对象和不可变对象
可变对象和不可变对象
- 所谓可变对象是指,对象的内容可变,而不可变对象是指对象内容不可变。
- 所以,在python中哪些是可变数据类型,哪些是不可变数据类型就尤为关键。
- 可变数据类型:列表list和字典dict,set,自己定义的类对象,numpy中的ndarray对象,具体参考:NumPy:拷贝和视图。
- 不可变数据类型:整型int、浮点型float、字符串型string和元组tuple,以及frozenset。(注意:字典的key只能是不可变对象,即字典的key只能是整型int、浮点型float、字符串型string和元组tuple)。
8.2 传递实参
- 鉴于函数定义中可能包含多个形参,因此函数调用中也可能包含多个实参;
- 向函数传递实参的方式有很多,可使用位置实参,这要求实参的顺序与形参的顺序相同;
- 也可使用关键字实参,其中每个实参都由变量名和值组成;还可以使用列表和字典
8.2.1 位置实参
- 你调用函数时,python必须将函数调用中的每个实参都关联到函数定义中的形参;
- 为此最简单的关联方式是基于实参的顺序,这种关联方式被称为位置实参;
1、调用函数多次
def describe_pet(animal_type,pet_name):
print("\nI have a " + animal_type + ".")
print("My " + animal_type + "'s name is " + pet_name.title() + ".")
describe_pet('hamster','harry')这些代码输出如下:
I have a hamster.
My hamster's name is Harry.
2、位置实参的顺序很重要
使用位置实参来调用函数时,如果实参的顺序不正确,结果可能出乎意料;
8.2.2 关键字实参
- 关键字实参是传递给函数的名称-值对
- 你直接在实参中将名称和值关联起来了,因此向函数传递实参时不会混淆;
- 关键字实参让你无需开了函数调用中的实参顺序,还清晰指出了函数调用中各个值的用途;
def describe_pet(animal_type,pet_name):
print("\nI have a " + animal_type + ".")
print("My " + animal_type + "'s name is " + pet_name.title() + ".")
describe_pet(animal_type='hamster',pet_name='harry')
describe_pet(pet_name='wangcai',animal_type='dog')这些代码输出如下:
I have a hamster.
My hamster's name is Harry.I have a dog.
My dog's name is Wangcai.
注意:使用关键字实参时,无比准确地指定函数定义中的形参值。
8.2.3 默认值
- 编写函数时,可给每个形参指定默认值。
- 在调用函数中给形参提供了实参是,python将使用指定的实参值,否则将使用形参的默认值;
- 因此给形参指定默认值后,可在函数调用中省略相应的实参;
- 使用默认值可简化函数调用,还可以清楚的指出函数的典型用法;
#使用默认值时,在形参列表中必须先列出没有默认值的形参,在列出有默认值的形参,这让Python依然能够正确地解读位置实参;
def describe_pet(pet_name,animal_type = 'dog'):
print("\nI have a " + animal_type + ".")
print("My " + animal_type + "'s name is " + pet_name.title() + ".")
describe_pet(pet_name='harry')
describe_pet(pet_name='wangcai',animal_type='cat')这些代码输出如下:
I have a dog.
My dog's name is Harry.I have a cat.
My cat's name is Wangcai.
注意:使用默认值时,在形参列表中必须先列出没有默认值的形参,在列出有默认值的形参,这让Python依然能够正确地解读位置实参;
8.2.4 等效地函数调用
- 鉴于可混合使用位置实参,关键字实参和默认值,通常由多种等下地函数调用方式
- 使用哪种调用方式无关紧要,只要函数调用能生产你希望地输出就行;使用对你来说最容易理解地调用方式即可;
8.2.5 避免实参错误
- 等你开始使用参数后,如果发现实参不匹配错误;
- 你提供地实参多余活小于函数完成其工作所需地信息时,将出现实参不匹配地错误;
8.3 返回值
- 函数并非总是直接显示输出,相反,他可以处理一些数据,并返回一个或一组值;
- 函数返回的值被称为返回值;
- 在函数中,可使用return语句将值返回到调用函数的代码行;返回值让你能够将程序大部分繁重的工作移到函数中去完成,从而简化主程序;
8.3.1 返回简单值
musician = get_formatted_name('jimi','hendrix')
print(musician)这些代码输出如下:
Jimi Hendrix
8.3.2 让实参变成可选的
有时候,需要让实参变成可选的,这样使用函数的人就只需要在必要是才提供额外的信息;可以使用默认值让实参编程可选的;
def get_formatted_name(first_name,middle_name,last_name):
"""返回整洁的名字"""
full_name = first_name + ' ' + middle_name + ' ' + last_name
return full_name.title()
musician = get_formatted_name('jimi','lee','hendrix')
print(musician)这些代码输出如下:
Jimi Lee Hendrix
8.3.3 返回字典
- 函数可返回任何类型的值,包括列表和字典等较复杂的数据结构
def build_person(first_name,last_name):
person = {'first':first_name,'last':last_name}
return person
musician = build_person('jimi','hendrix')
print(musician)这些代码输出如下:
{'first': 'jimi', 'last': 'hendrix'}
- 函数build_person()接受名和姓,并将这些值封装到字典中;
- 存储first_name的值时,使用的键为’first‘,而存储last_name的值时,使用的键为'last',返回表示人的整个字典;
8.3.4 结合使用函数和while循环
可将函数同书本前面介绍任何python结构结合起来使用;
def get_formatted_name(first_name,last_name):
"""返回整洁的名字"""
full_name = first_name + ' ' + last_name
return full_name.title()
while True:
print("\nPlease tell me your name: ")
f_name = input("First name:")
l_name = input("Last name:")
formatted_name = get_formatted_name(f_name,l_name)
print("\nhello, " + formatted_name + "!")这些代码输出如下:
Please tell me your name:
First name:zhou
Last name:zhouzhouhello, Zhou Zhouzhou!
Please tell me your name:
First name:
- 但是这个while循环存在一个问题:没有定义退出条件;
- 我们应该提醒用户输入时,都提供退出途径;
- 每次提示用户输入时,都可使用break语句提供退出循环的简单途径;
def get_formatted_name(first_name,last_name):
"""返回整洁的名字"""
full_name = first_name + ' ' + last_name
return full_name.title()
while True:
print("\nPlease tell me your name: ")
f_name = input("First name:")
if f_name == 'q':
break
l_name = input("Last name:")
if l_name == 'q':
break
formatted_name = get_formatted_name(f_name,l_name)
print("\nhello, " + formatted_name + "!")这些代码输出如下:
Please tell me your name:
First name:zhou
Last name:zhouzhouhello, Zhou Zhouzhou!
Please tell me your name:
First name:q
8.4 传递列表
- 向函数传递列表很有用;
- 将列表传递给函数后,函数就能直接访问其内容;
def greet_users(names):
"""向列表中的每位用户都发出简单的问候"""
for name in names:
msg = "Hello, " + name.title() + "!"
print(msg)
usernames = ['hannah','ty','margot']
greet_users(usernames)
这些代码输出如下:
Hello, Hannah!
Hello, Ty!
Hello, Margot!
8.4.1 在函数中修改列表
- 在列表传递给函数后,函数就可以对其进行修改;
- 在函数中对这个列表所做的任何修改都是永久性的;
unprinted_designs = ['iphone case','robot pendant','dodecahedron']
completed_models = []
while unprinted_designs:
cuurrent_design = unprinted_designs.pop()
print("priting model: " + cuurrent_design)
completed_models.append(cuurrent_design)
print("\nThe following moedls have been printed:")
for completed_model in completed_models:
print(completed_model)这些代码输出如下:
priting model: dodecahedron
priting model: robot pendant
priting model: iphone caseThe following moedls have been printed:
dodecahedron
robot pendant
iphone case
- 为了重新组织这些代码,我们可编写两个函数,每个都做一件具体的工作;
- 大部分代码都与原来相同,至少效率更高;
- 第一个函数将负责处理打印设计的工作;
- 第二个将概述打印了哪些设计;
def print_models(unprinted_designs,comleted_moedls):
"""
模拟打印每个设计,直到没有未打印的设计为止
打印每个设计后,都将其移到列表completed_models中
"""
while unprinted_designs:
cuurrent_design = unprinted_designs.pop()
print("Printing model: " + cuurrent_design)
completed_models.append(cuurrent_design)
def show_completed_models(completed_models):
"""显示打印好的所有模型"""
print("\nThe following models have been printed: ")
for completed_model in completed_models:
print(completed_model)
unprinted_designs = ['iphone case','robot pandant','dodecaheron']
completed_models = []
print_models(unprinted_designs,completed_models)
show_completed_models(completed_models)这些代码输出如下:
Printing model: dodecaheron
Printing model: robot pandant
Printing model: iphone caseThe following models have been printed:
dodecaheron
robot pandant
iphone case
8.4.2 禁止函数修改列表
有时候,需要禁止函数修改列表;
8.5 传递任意数量的实参
有时候, 你预先不知道函数需要接受多少个实参,好在python允许函数从调用语句中收集任意数量的实参。
def make_pizza(*toppings):
"""打印顾客点的所有配料"""
print(toppings)
make_pizza('peppereoni')
make_pizza('mushrooms','green peppers','extra cheese')
这些代码输出如下:
('peppereoni',)
('mushrooms', 'green peppers', 'extra cheese')
现在我们可以将print语句换为一个循环,对配料表进行遍历,并对顾客点的披萨进行描述:
def make_pizza(*toppings):
"""概述要制作的披萨"""
print("\n Making a pizza with the following toppings:")
for topping in toppings:
print("- " + topping)
make_pizza('peppereoni')
make_pizza('mushrooms','green peppers','extra cheese')这些代码输出如下:
Making a pizza with the following toppings:
- peppereoniMaking a pizza with the following toppings:
- mushrooms
- green peppers
- extra cheese
不管收到的实参是多少个,这种语法都是管用的;
8.5.1 结合使用位置实参和任意数量实参
- 如果让函数接受不同类型的实参,必须在函数定义中将接纳任意数量实参的形参放在最后;
- python先匹配位置实参和关键字实参,再将余下的实参都收集到最后一个形参中;
def make_pizza(size,*toppings):
"""概述要制作的披萨"""
print("\nMaking a " + str(size) + "-inch pizza with the following toppings:")
for topping in toppings:
print("- " + topping)
make_pizza(16,"pepperoni")
make_pizza(12,'mushrooms','green peppers','extra cheese')这些代码输出如下:
Making a 16-inch pizza with the following toppings:
- pepperoniMaking a 12-inch pizza with the following toppings:
- mushrooms
- green peppers
- extra cheese
8.5.2 使用任意数量的关键字实参
有时候,需要接受任意数量的实参,但预先不知道传递给函数的会是什么样的信息;
在这种情况下,可将函数编写出能够接受任意数量的键-值对——调用语句提供了多少就接受多少;
def build_profile(first,last,**user_info):
profile = {}
profile['first_name'] = first
profile['last_name'] = last
for key, value in user_info.items():
profile[key] =value
return profile
user_profile = build_profile('albert','einsterin',
loaction = 'princeton',
field = 'physics')
print(user_profile)这些代码输出如下:
{'first_name': 'albert', 'last_name': 'einsterin', 'loaction': 'princeton', 'field': 'physics'}
8.6 将函数存储在模块中
- 函数的优点之一是,使用它们可将代码块和主程序分离;
- 通过 给函数指定描述性名称,可让主程序容易理解得多;
- 你还可以进一步将函数存储在被称为模块的独立文件中,再将模块导入主程序中;
- import语句允许在当前运行的程序文件在使用模块在的代码;
8.6.1 导入整个模块
- 要让函数是可导入的,得先创建模块;
- 模块是扩展名为.py的文件,包含要导入到程序中的代码;
pizza.py
def make_pizza(size,*toppings):
print("\nMaking a " + str(size) + "-inch pizza with the following toppongs: ")
for topping in toppings:
print("- " + topping)import pizza
pizza.make_pizza(16,"peperoni")
pizza.make_pizza(21,'mushrooms','green peppers','extra cheese')这些代码输出如下:
Making a 16-inch pizza with the following toppongs:
- peperoniMaking a 21-inch pizza with the following toppongs:
- mushrooms
- green peppers
- extra cheese
8.6.2 导入特定的函数
你还可以导入模块中的特定函数,这种导入方法的语法如下:
from pizza import make_pizza
通过用逗号分隔函数名,可根据需要从模块中导入任意数量的函数:
from pizza import make_pizza,make_pizza2,make_pizza38.6.3 使用as给函数指定别名
如果要导入的函数名称可能与程序中现有的名称冲突,或者函数名称太长,可指定简短而独一无二的别名——函数的另一个名称;
from pizza import make_pizza as mp
mp(16,"peperoni")
mp(21,'mushrooms','green peppers','extra cheese')这些代码输出如下:
Making a 16-inch pizza with the following toppongs:
- peperoniMaking a 21-inch pizza with the following toppongs:
- mushrooms
- green peppers
- extra cheese
8.6.4 使用as给模块指定别名
你还可以给模块指定别名;通过给模块指定简短的别名,让你更加轻松调用模块中的函数;
import pizza as p
p.make_pizza(16,"peperoni")
p.make_pizza(21,'mushrooms','green peppers','extra cheese')这些代码输出如下:
Making a 16-inch pizza with the following toppongs:
- peperoniMaking a 21-inch pizza with the following toppongs:
- mushrooms
- green peppers
- extra cheese
8.6.4 导入模块中的所有函数
使用星号(*)运算符可让python导入模块中的所有函数:
from pizza import *
make_pizza(16,"peperoni")
make_pizza(21,'mushrooms','green peppers','extra cheese')这些代码输出如下:
Making a 16-inch pizza with the following toppongs:
- peperoniMaking a 21-inch pizza with the following toppongs:
- mushrooms
- green peppers
- extra cheese
8.7 函数编写指南
- 给形参指定默认值时,等号两边不要由空格;
- 对于函数调用中的关键字实参,也应遵循这种约定;
第9章 类
- 面向对象编程是最有效的编程编写方法之一;
- 根据类来创建对象被称为实例化;
9.1 创建和使用类
使用类几乎可以模拟任何东西;
9.1.1 创建Dog类
根据Dog类创建的每个示例都将存储名字和年龄;我们赋予了每条小狗蹲下(sit())和打滚(roll_over())的能力:
Dog.py
class Dog():
"""一次模拟小狗的简单尝试"""
def __init__(self,name,age):
"""初始化属性name和age"""
self.name = name
self.age = age
def sit(self):
"""模拟小狗被命令是蹲下"""
print(self.name.title() + "is now sitting.")
def roll_over(self):
"""模拟小狗被命令时打滚"""
print(self.name.title() + " rolled over!")
- 这里需要注意的对方很多,但你也不用担心;
- 在Python中,首字母大写的名称指的是类,这个类定义的括号是空的;
1、方法_init()_
类中的函数称为方法;你前面学到的有关函数的一切都适用于方法,就目前而言,唯一重要的差别是调用方法的方式;
9.1.2 根据类创建实例
可将类视为有关如何创建实例的说明;
class Dog():
"""一次模拟小狗的简单尝试"""
def __init__(self,name,age):
"""初始化属性name和age"""
self.name = name
self.age = age
def sit(self):
"""模拟小狗被命令是蹲下"""
print(self.name.title() + "is now sitting.")
def roll_over(self):
"""模拟小狗被命令时打滚"""
print(self.name.title() + " rolled over!")
my_dog = Dog('whllie',6)
print("My dos's name is " + my_dog.name.title() + ".")
print("My dog is " + str(my_dog.age) + "years old.")
这些代码输出如下:
My dos's name is Whllie.
My dog is 6years old.
1、访问属性
要访问实例的属性,可使用句点表示法;
2.调用方法
根据Dog类创建实例后,就可以使用句点来调用Dog类中定义的任何方法
class Dog():
"""一次模拟小狗的简单尝试"""
def __init__(self,name,age):
"""初始化属性name和age"""
self.name = name
self.age = age
def sit(self):
"""模拟小狗被命令是蹲下"""
print(self.name.title() + " is now sitting.")
def roll_over(self):
"""模拟小狗被命令时打滚"""
print(self.name.title() + " rolled over!")
my_dog = Dog('whllie',6)
print("My dos's name is " + my_dog.name.title() + ".")
print("My dog is " + str(my_dog.age) + "years old.")
my_dog = Dog('whille',6)
my_dog.sit()
my_dog.roll_over()这些代码输出如下:
My dos's name is Whllie.
My dog is 6years old.
Whille is now sitting.
Whille rolled over!
9.2 使用类和实例
- 你可以使用类来模拟现实世界中的很多情景;
- 类编写好后,你大部分的时间都将华仔使用根据类创建的实例中;
- 你需要执行的一个重要任务是修改实例;
- 你可以直接修改实例的属性,也可以编写方法以特定的方式进行修改;
9.2.1 Car类
class Car():
"""一次模拟汽车的简单尝试"""
def __init__(self,make,model,year):
"""初始化描述汽车属性"""
self.make = make
self.model = model
self.year = year
def get_descriptive_name(self):
"""返回整洁的描述性"""
long_name = str(self.year) + ' ' + self.make + ' ' + self.model
return long_name.title()
my_new_car = Car('audi','a4',2016)
print(my_new_car.get_descriptive_name())这些代码输出如下:
2016 Audi A4
9.2.2 给属性指定默认值
- 类中的每个属性都必须由初始值,哪怕这个值是0或空字符串;
- 在有些情况下,如设置默认值时,在方法_init()_内指定这种初始值是可行的;如果你对某个属性这样做了,就无需包含为它提供初始值的形参;
class Car():
"""一次模拟汽车的简单尝试"""
def __init__(self,make,model,year):
"""初始化描述汽车属性"""
self.make = make
self.model = model
self.year = year
self.odometer_reading = 0
def get_descriptive_name(self):
"""返回整洁的描述性"""
long_name = str(self.year) + ' ' + self.make + ' ' + self.model
return long_name.title()
def read_odometer(self):
"""打印一条指出汽车理财的消息"""
print("This car has " + str(self.odometer_reading) + " miles on it")
my_new_car = Car('audi','a4',2016)
print(my_new_car.get_descriptive_name())
my_new_car.read_odometer()
这些代码输出如下:
2016 Audi A4
This car has 0 miles on it
9.2.3 修改属性的值
有三种不同的方式修改属性的值:
- 直接通过实例进行修改;
- 通过方法进行设置;
- 通过方法进行递增
1、直接修改属性的值
要修改属性的值,最简单的方式是通过实例直接访问到它;
class Car():
"""一次模拟汽车的简单尝试"""
def __init__(self,make,model,year):
"""初始化描述汽车属性"""
self.make = make
self.model = model
self.year = year
self.odometer_reading = 0
def get_descriptive_name(self):
"""返回整洁的描述性"""
long_name = str(self.year) + ' ' + self.make + ' ' + self.model
return long_name.title()
def read_odometer(self):
"""打印一条指出汽车理财的消息"""
print("This car has " + str(self.odometer_reading) + " miles on it")
my_new_car = Car('audi','a4',2016)
print(my_new_car.get_descriptive_name())
my_new_car.odometer_reading = 23
my_new_car.read_odometer()这些代码输出如下:
2016 Audi A4
This car has 23 miles on it
2、通过方法修改属性的值
如果有替你更新属性的方法,将大有裨益;这样你就午休直接访问属性,而可将值传递给一个方法,由它在内部进行更新;
class Car():
"""一次模拟汽车的简单尝试"""
def __init__(self,make,model,year):
"""初始化描述汽车属性"""
self.make = make
self.model = model
self.year = year
self.odometer_reading = 0
def get_descriptive_name(self):
"""返回整洁的描述性"""
long_name = str(self.year) + ' ' + self.make + ' ' + self.model
return long_name.title()
def update_odometer(self,mileage):
"""将里程表读数设置为指定的值"""
self.odometer_reading = mileage
print("This car has " + str(self.odometer_reading) + " miles on it")
my_new_car = Car('audi','a4',2016)
print(my_new_car.get_descriptive_name())
my_new_car.update_odometer(23)
这些代码输出如下:
2016 Audi A4
This car has 23 miles on it
3、通过方法对属性的值进行递增
class Car():
"""一次模拟汽车的简单尝试"""
def __init__(self,make,model,year):
"""初始化描述汽车属性"""
self.make = make
self.model = model
self.year = year
self.odometer_reading = 0
def get_descriptive_name(self):
"""返回整洁的描述性"""
long_name = str(self.year) + ' ' + self.make + ' ' + self.model
return long_name.title()
def update_odometer(self,mileage):
"""将里程表读数设置为指定的值"""
self.odometer_reading = mileage
print("This car has " + str(self.odometer_reading) + " miles on it")
def increment_odometer(self,miles):
"""将里程表读数设置为指定的值"""
self.odometer_reading += miles
print("This car has " + str(self.odometer_reading) + " miles on it")
my_used_car = Car('SUBARU','OUTBACK',2013)
print(my_used_car.get_descriptive_name())
my_used_car.update_odometer(23500)
my_used_car.increment_odometer(100)这些代码输出如下:
2013 Subaru Outback
This car has 23500 miles on it
This car has 23600 miles on it
9.3 继承
- 编写类时,并非总是要从空白开始;
- 如果你要编写的类是另一个现成类的特殊版本,可使用继承;
- 一个类继承另一个类时,它将自动获取另一个类的所有属性和方法;
- 原本的类称为父类,而新类称为子类;
- 子类继承了其父亲的所有属性和方法,同时定义自己的属性和方法;
9.3.1 子类的方法_init_()
创建子类实例时,python首先需要完成的任务时给父亲的所有属性赋值;为此,子类的方法_init_()需要父类施以援手;
class Car():
"""一次模拟汽车的简单尝试"""
def __init__(self,make,model,year):
"""初始化描述汽车属性"""
self.make = make
self.model = model
self.year = year
self.odometer_reading = 0
def get_descriptive_name(self):
"""返回整洁的描述性"""
long_name = str(self.year) + ' ' + self.make + ' ' + self.model
return long_name.title()
def update_odometer(self,mileage):
"""将里程表读数设置为指定的值"""
self.odometer_reading = mileage
print("This car has " + str(self.odometer_reading) + " miles on it")
def increment_odometer(self,miles):
"""将里程表读数设置为指定的值"""
self.odometer_reading += miles
print("This car has " + str(self.odometer_reading) + " miles on it")
class ElectricCar(Car):
"""电动车的独特之处"""
def __init__(self,make,mddel,year):
"""初始化父类的属性"""
super().__init__(make,mddel,year)
my_tesla = ElectricCar('tesla','model s',2016)
print(my_tesla.get_descriptive_name())这些代码输出如下:
2016 Tesla Model S
9.3.3 给子类定义属性和方法
让一个类继承另一个类后,可添加区分子类和父类所需的新属性和方法;
class Car():
"""一次模拟汽车的简单尝试"""
def __init__(self,make,model,year):
"""初始化描述汽车属性"""
self.make = make
self.model = model
self.year = year
self.odometer_reading = 0
def get_descriptive_name(self):
"""返回整洁的描述性"""
long_name = str(self.year) + ' ' + self.make + ' ' + self.model
return long_name.title()
def update_odometer(self,mileage):
"""将里程表读数设置为指定的值"""
self.odometer_reading = mileage
print("This car has " + str(self.odometer_reading) + " miles on it")
def increment_odometer(self,miles):
"""将里程表读数设置为指定的值"""
self.odometer_reading += miles
print("This car has " + str(self.odometer_reading) + " miles on it")
class ElectricCar(Car):
"""电动车的独特之处"""
def __init__(self,make,mddel,year):
"""初始化父类的属性"""
super().__init__(make,mddel,year)
self.battery_size = 70
def describe_battery(self):
"""打印一条描述电瓶容量的消息"""
print("this car has a " + str(self.battery_size) + "-KWh battery.")
my_tesla = ElectricCar('tesla','model s',2016)
print(my_tesla.get_descriptive_name())
my_tesla.describe_battery()这些代码输出如下:
2016 Tesla Model S
this car has a 70-KWh battery.
注意:注意缩进!注意缩进!注意缩进!
9.3.5 将实例用作属性
不断给ElectricCar类添加细节时,我们可能会发现其中包含很多专门针对汽车电瓶的属性和方法;
9.4 导入类
- 随着你不断地给类添加功能,文件会变得很长,即使你妥善地使用了继承亦是如此;
- 为遵循Python的总体理念,应让文件尽可能地整洁;
- 为在这方面提供帮助,Python允许你将类存储在模块中,然后在主程序中导入所需地模块;
9.4.1 导入单个类
9.4.2 在一个模块中存储多个类
9.4.3 从一个模块中导入多个类
9.4.4 导入整个模块
9.4.5 导入模块中的所有类
9.4.6 在一个模块中导入另一个模块
9.4.7 自定义工作流程
- 一开始应让代码结构尽可能简单;
- 先尽可能在一个文件中完成所有工作,确定一切都能正常运行后,再将类移到独立的模块中;
- 如果你喜欢模块和文件交互方式,可在项目开始时就尝试将类存储到模块中;
- 先找出让你能够编写出可行代码的方式,在尝试让代码更为组织有序;
第10章 文件和异常
至此,你掌握了编写组织有序而易于使用的程序所需的基本技能,该考虑让程序目标更明确、用途更大了。
10.1 从文件中读取数据
文本文件可存储的数据量多的难以置信:天气数据、交通数据、、社会经济数据、文学作品等;
10.1.1 读取整个文件
- 要读取文件,需要一个包含几行文本的文件;
- 下面首先来创建一个文件,它包含精确到小数点后30位的圆周率值,且在小数点后每10位处都换行:
pi.digits
3.1415926535 8979323846 2643383279
with open('pi_digits') as file_object:
contents = file_object.read()
print(contents)- 关键字with在不再需要访问文件后将其关闭;在这个过程中,注意到我们调用了open(),但是没用调用close();
- 你也可以调用open()和close()来打开和关闭文件,但这样做时,如果程序存在bug,导致close语句未执行,文件将不会关闭;
- 这看似微不足道,但未能妥善的关闭文件可能会丢失会受损;
- 在前面的示例中,你只管打开文件,并在需要时使用它,python会在适合的适合自动将其关闭;
10.1.2 文件路径
当你将类似pi_digit这样的简单文件名传递给函数open()时,Python将在执行的文件所载的目录中查询文件;
在Windows系统中,在文件路径中使用反斜杠(\)而不是(/):
#coding=utf8
with open(r'C:\Users\DELL\Desktop\pi_digits.txt') as file_object:
contents = file_object.read()
print(contents)这些代码输出如下:
3.1415926535
8979323846
2643383279
10.1.3 逐行读取
读取文件时,常常需要检查其中每一行:
#coding=utf8
file_name = (r'C:\Users\DELL\Desktop\pi_digits.txt')
with open(file_name) as file_object:
for line in file_object:
print(line)这些代码输出如下:
3.1415926535
8979323846
2643383279
我们打印每一行时,发现空白行更多了;
#coding=utf8
file_name = (r'C:\Users\DELL\Desktop\pi_digits.txt')
with open(file_name) as file_object:
for line in file_object:
print(line.rstrip())这些代码输出如下:
3.1415926535
8979323846
2643383279
10.1.4 创建一个包含文件各行内容的列表
- 使用关键字with时,open()返回的文件对象只在with代码块内可用;
- 如果要在with代码块外访问文件的内容,可在with代码块内将文件的隔行存储在一个列表中,并在with代码块外使用该列表;
- 你可以立刻处理文件的各个部分,也可以推迟到查询后面在处理;
#coding=utf8
file_name = (r'C:\Users\DELL\Desktop\pi_digits.txt')
with open(file_name) as file_object:
lines = file_object.readlines()
for line in lines:
print(line.rstrip())这些代码输出如下:
3.1415926535
8979323846
2643383279
10.1.5 使用文件的内容
将文件读取到内存中后,就可以以任何方式使用这些数据了;
#coding=utf8
file_name = (r'C:\Users\DELL\Desktop\pi_digits.txt')
with open(file_name) as file_object:
lines = file_object.readlines()
pi_string = ''
for line in lines:
pi_string += line.rstrip()
print(pi_string)
print(len(pi_string))这些代码输出如下:
3.1415926535 8979323846 2643383279
38
注意 读取文本文件时,Python将其中的所有文本都解读为字符串,如果你读取的时数字,并要将其作为数值使用,就必须使用函数int()将其转换为整数,或使用函数float()将其转化为浮点数
10.1.6 包含一百位的大型文件
- 前面我们分析的都是一个只有三行的文本文件,但这些代码示例也可以处理大得多的文件;
- 对于你可处理的数据量,Python没有做任何限制;只要系统内存足够多,你想处理多少数据都可以;
10.1.7 圆周率中包含你的生日吗
#coding=utf8
file_name = (r'C:\Users\DELL\Desktop\python_work\《Python编程》源代码文件\chapter_10\pi_million_digits.txt')
with open(file_name) as file_object:
lines = file_object.readlines()
pi_string = ''
for line in lines:
pi_string += line.rstrip()
birthday = input("Enter your birthday,in the form mmddyy: ")
if birthday in pi_string:
print("your birthday appears in the first million digits of pi!")
else:
print("your birthday does not appear in the first million digits of pi")这些代码输出如下:
Enter your birthday,in the form mmddyy: 19950813
your birthday does not appear in the first million digits of pi
10.2 写入文件
- 保存数据的最简单的方式之一是将其写入文件中;
- 通过将输入写入文件,即便关闭包含程序输出的终端窗口,这些输出依然存在:
- 你可以在程序结束后查询这些输出,可与别人分享输出文件,还可以编写程序来将这些输出读取到内存中并进行处理;
10.2.1 写入空文件
要将文本写入文件 ,你在调用open()时需要另一个实参,告诉Python你要写入打开的文件;
明白其中的工作原理,我们来将一条简单的消息存储到文件中,而不是将其打印到屏幕上:
filename = 'programing.txt'
with open(filename,'w') as file_object:
file_object.write("I lvoe programing.")这些代码输出如下:
programing.txt
I lvoe programing.
- 在这个示例中,调用open()时提供了两个实参,第一个实参也是要打开的文件的名称;
- 第二个实参('w')告诉python,我们写入模式打开这个文件;
- 打开文件时,可指定读取模式('r')、写入模式('w')、附加模式('a')或让你能够读取和写入文件的模式('r+');
- 如果你省略了模式实参,Python将以默认的只读模式打开文件;
10.2.2 写入多行
函数write()不会在你写入的文本末尾添加换行符,因此如果你写入多行时没用指定换行符,文件看起来可能不是你希望的那样;
filename = 'programing.txt'
with open(filename,'w')as file_object:
file_object.write("I love programing.")
file_object.write("I love creating new games.")这些代码输出如下:
programing.txt
I love programing.I love creating new games.
如果你打开programing.txt,将发现两行内容挤在一起;
要让每个字符串都单独占用一行,需要在write()语句中包含换行符:
filename = 'programing.txt'
with open(filename,'w')as file_object:
file_object.write("I love programing.\n")
file_object.write("I love creating new games.\n")
这些代码输出如下:
programing.txt
I love programing. I love creating new games.
像显示到终端输出一样,还可以使用空格、制表符和空行来设置这些输出的格式;
10.2.3 附加到文件
- 如果你要给文件添加内容,而不是覆盖原有内容,可以附加模式打开文件,你以附加模式打开文件时,Python不会在返回文件对象前清空文件,而你写入文件的行都将添加到文件末尾;
- 如果指定的文件不存在,Python将为你创建一个空文件;
filename = 'programing.txt'
with open(filename,'a') as file_object:
file_object.write("I also lvoe finding meaning in large datasets.\n")
file_object.write("I love creating apps that can run in a brower.\n")programing.txt
I love programing. I love creating new games. I also lvoe finding meaning in large datasets. I love creating apps that can run in a brower.
最终的结果是,文件原来的内容还在,它们后面是我们刚添加的内容;
10.3 异常
- Python使用被称为异常的特殊对象来管理程序执行期间发生的错误;
- 每当发生让Python不知所措的错误时,它都会创建有个异常对象;
- 如果你编写了处理该异常的代码,程序将会继续运行;
- 如果你未对异常进行处理,程序将停止,并显示一个traceback,其中包含有关异常的报告;
10.3.1 处理ZeroDivisionError
print(5/0)显然,Python无法这样做,因此你将会看到一个traceback:
Traceback (most recent call last):
File "C:\Users\DELL\PycharmProjects\pythonProject\hollo_world.py", line 1, in
print(5/0)
ZeroDivisionError: division by zero
10.3.2 使用try-except代码块
当你认为可能发生了错误时,可编写一个try-except代码块来处理可能引发的异常;
10.3.3 使用异常避免崩溃
- 发生错误时,如果程序还有工作没有完成,妥善地处理错误就尤其重要;
- 这种情况经常会出现现在要求用户提供输入地程序中;
- 如果程序能过妥善地处理无效输入,就能再提示用户提供有效地输入,而不至于崩溃;
print("give me two numbers , I'll divide them.")
print("Enter 'q' to quit.")
while True:
first_number = input("\n First number: ")
if first_number == 'q':
break
second_number = input("\n Second number:")
if second_number == 'q':
break
answer = int(first_number) / int(second_number)
print(answer)
这些代码输出如下:
give me two numbers , I'll divide them.
Enter 'q' to quit.First number: 88
Second number:0
Traceback (most recent call last):
File "C:\Users\DELL\PycharmProjects\pythonProject\hollo_world.py", line 10, in
answer = int(first_number) / int(second_number)
ZeroDivisionError: division by zero
10.3.4 else代码块
- 通过将可能引发错误地代码块放在try-except代码块中,可提高这个程序抵御错误地能力;
- 错误是执行除法运算代码行导致地,因此我们需要将它放大try-except代码块中;
print("give me two numbers , I'll divide them.")
print("Enter 'q' to quit.")
while True:
first_number = input("\n First number: ")
if first_number == 'q':
break
second_number = input("\n Second number:")
try:
answer = int(first_number) / int(second_number)
except ZeroDivisionError:
print("you can't divide by 0")
else:
print(answer)这些代码输出如下:
give me two numbers , I'll divide them.
Enter 'q' to quit.First number: 99
Second number:0
you can't divide by 0First number: 5
Second number:2
2.5First number: q
10.3.5 处理FileNotFoundError
filename = 'alice.txt'
with open(filename) as f-obj:
contents = f_obj.read()这些代码输出如下:
File "C:\Users\DELL\PycharmProjects\pythonProject\demo12.py", line 2
with open(filename) as f-obj:
^^^^^
SyntaxError: cannot assign to expression
10.3.6 分享文本
你可以分享包含整本书地文本文件;很多经典地文学作品都是以简单地文本文件地方式提供地,因为他们不受版权限制;
#coding=utf8
filename = r'C:\Users\DELL\Desktop\xxx.txt'
try:
with open(filename,"rb") as f_obj:
contents = f_obj.read()
except FileNotFoundError:
msg = "Sorry, the file " + filename + "does not exist."
print(msg)
else:
words = contents.split()
num_words = len(words)
print("the file " + "has about " + str(num_words) + "words.")这些代码输出如下:
the file has about 45410words.
10.3.7 使用多个文件
10.3.8失败时一声不吭
10.3.9 决定报告那些错误
10.4 存储数据
- 很多程序都要求用户输入某种信息,如让用户存储游戏首选项或提供要提供要可视化地数据;
- 不管专注的是什么,程序都把用户提供的信息存储到列表和字典等数据结构中;
- 用户关闭程序时,你几乎总是要保存他们提供的信息;
- 一种简单的方式是使用模块json来存储数据;
模块json让你能够将简单的python数据结构转储到文件中,并在程序再次运行时加载该文件中的数据;
注意:json(JavaScript object notation)格式最初是为JavaScript开发的,但随后成了一种常见格式,被包括在python在内的众多语言采用;
10.4.1 使用json.dump()和json.load()
- 我们来编写一个存储一组数字的简单程序,在编写一个将这些数字读取到内存的程序;
- 第一个程序将使用json.dump()来存储这组数字,而第二个程序将使用json.load()
函数json.dump接受了两个实参:要存储的数据以及可用于存储数据的文件对象:
import json
numbers = [2,3,5,7,11,13]
filename = 'numbers.json'
with open(filename,'w')as f_obj:
json.dump(numbers,f_obj)这些代码输出如下:
number.json
[2, 3, 5, 7, 11, 13]
10.4.2 保存和读取用户生成的数据
对于用户生成的数据,使用json保存它们大有裨益,因为如果不以某种方式进行存储,等程序停止运行时用户的信息将都丢失;
import json
username = input("what is your name ? ")
filename = 'username.json'
with open(filename,'w')as f_obj:
json.dump(username,f_obj)
print("We'll remember you when you come back," + username + "!")
这些代码输出如下:
username.json
"zhouzhouzhou"
10.4.3 重构
- 你经常会遇到这样的情况:代码能够正确地运行,但可做进一步地改进——将代码划分为一系列完成具体工作地函数。这样地过程被称为重构;
- 重构让代码清晰、更易于理解、更容易扩展;
import json
def greet_user():
"""问候用户,并指出其姓名"""
filename = 'username.json'
try:
with open(filename) as f_obj:
username = json.load(f_obj)
except FileNotFoundError:
username = input("what is your name? ")
with open(filename,'w') as f_obj:
json.dump(username,f_obj)
print("We'll remnmber you when you came back," + username + "!")
else:
print("Welcome back, " + username + "!")
greet_user()
这些代码输出如下:
Welcome back, zhouzhouzhou!
- 下面来重构greet_user()
import json
def get_stored_username():
"""如果存储了用户名,就获取它"""
filename = 'username.json'
try:
with open(filename) as f_obj:
username = json.load(f_obj)
except FileNotFoundError:
return None
else:
return username
def greet_user():
"""问候用户,并指出其姓名"""
username = get_stored_username()
if username:
print("Welcome back, " + username + "!")
else:
username = input("what is your name? ")
filename = 'username.json'
with open(filename,'w') as f_obj:
json.dump(username,f_obj)
print("we'll remember you when you come back, " + username +"!")
print("Welcome back, " + username + "!")
greet_user()
这些代码输出如下:
Welcome back, zhouzhouzhou!
Welcome back, zhouzhouzhou!
第11章 测试代码
11.1 测试函数
要学习测试,得有要测试地代码;
11.1.1 单元测试和测试用例
- Python标准库中的模块unittest提供了代码测试工具;
- 单元测试用于核实函数的某个方面没有问题;
- 测试用例是一组单元测试,这些单元测试核实函数在各种情形下的行为都符合要求;
- 良好的测试用例考虑到了函数可能收到的各种输入,包含正对所有这些情形的测试;
- 全覆盖测试用例包含了一整套单元测试,涵盖了各种困难的函数使用方式;
- 针对大型项目,要实现全覆盖困难很难;
- 通常,最初只要针对代码的重要行为编写测试即可,等项目被广泛使用时在考虑全覆盖;
11.1.2可通过的测试
创建测试用例的语法需要一段时间才能习惯,但测试用例创建后,在添加针对函数的单元测试就很简单了;
要为函数编写用例,可先导入模块unittest以及要测试的函数,在创建一个继承unittest.testcase的类,并编写一系列方法对函数的不同方面进行测试;
11.1.3 不能通过的测试
测试未通过时结果是怎么样的呢?
11.1.4 测试未通过时怎么办
11.1.5 添加新测试
11.2 测试类
11.2.1 各种断言方法
11.2.2 一个要测试的类
11.2.3 测试AnonumousSurvey类
11.2.4 方法setUp()
第12章
第13章
第14章
第15章 生成数据
数据可视化化指的是通过可视化表示来探索数据,它与数据挖掘紧密相关,而数据挖掘指的是使用代码来探索数据集的规律和关联;
15.1 安装matplotlib
pycharm下载安装第三方库
用pycharm下载过第三方库。用的是在pycharm中点击
file -> Settings->Project untitled ->Project Interpreter
然后点击“+”号
需要下载什么输入对话框,点击Install Package 即可

成功如下图所示:

15.2 绘制简单的折线图
import matplotlib.pyplot as plt
squares = [1,4,9,16,25]
plt.plot(squares)
plt.show()- 我们首先导入类模块pyplot,并给它指定了别名plt,以免反复输入pyplot;
- 模块pyplot包含很对用于生成图表的函数;
- 我们创建了一个列表,在其中存储了前述平方数,再将这个列表传递给函数plot(),这个函数尝试根据这些数字绘制有意义的图形;
- plt.show()打开matplotlib查看器,并绘制的图形;如下图所示,查看器你能够缩放和导航图形,另外单击磁盘图标可将图形保存下来;

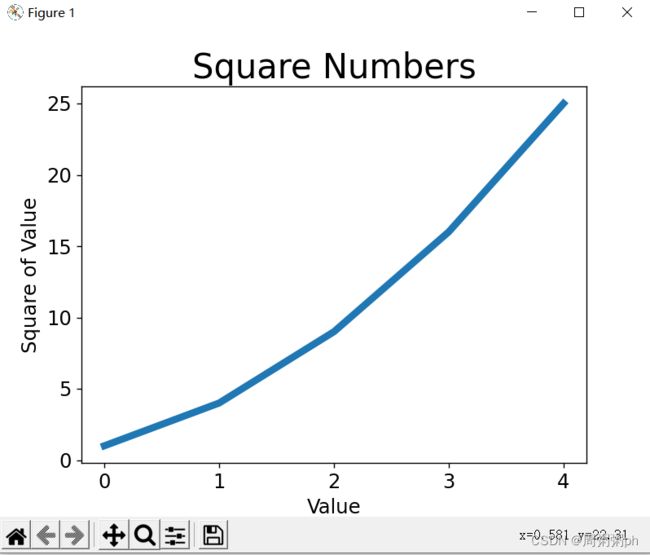
15.2.1 修改标签文字和线条粗细
上图图形表明数字是越来越大的,但标签文字太小,线条太细;
所幸matplotlib让你能够调整可视化的各个方面;
import matplotlib.pyplot as plt
squares = [1,4,9,16,25]
plt.plot(squares,linewidth = 5)
#设置图表标题,并给坐标轴加上标签
plt.title("Square Numbers",fontsize = 24)
plt.xlabel("Value",fontsize = 14)
plt.ylabel("Square of Value",fontsize = 14)
# 设置刻度标记的大小
plt.tick_params(axis='both' , labelsize = 14)
plt.show()如下图所示:
15.2.2 校正图形
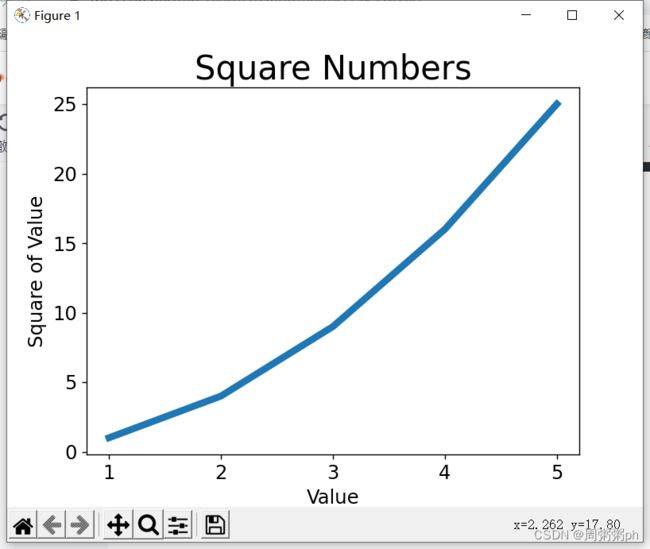
图形更容易阅读后,我们发现没有正确地绘制数据:折线图地终点指出4.0的平方为25!下面来修复这个问题:
当你向plot()提供一系列数字时,它假设第一个数据点对应的x坐标轴为0,但我们的第一个点对应的x值为1;
为改变这种默认行为,我们可以提供给plot()同时提供输入值和输出值;
import matplotlib.pyplot as plt
input_values = [1,2,3,4,5]
squares = [1,4,9,16,25]
plt.plot(input_values,squares,linewidth = 5)
#设置图表标题,并给坐标轴加上标签
plt.title("Square Numbers",fontsize = 24)
plt.xlabel("Value",fontsize = 14)
plt.ylabel("Square of Value",fontsize = 14)
# 设置刻度标记的大小
plt.tick_params(axis='both' , labelsize = 14)
plt.show()输出如下图所示:
15.2.3 使用scatter()绘制散点图并设置各个数据点的样式;
有时候,需要绘制散点图并设置各个数据点的样式;
import matplotlib.pyplot as plt
plt.scatter(2,4)
plt.show()输出如下图所示:
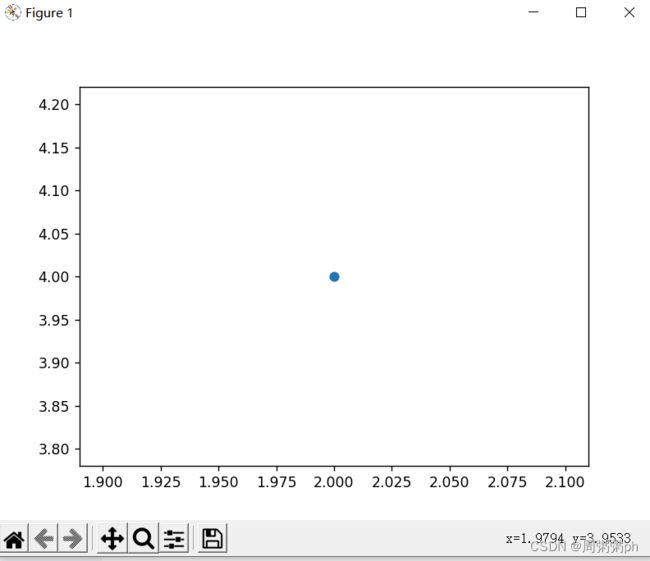
15.2.4 使用scatter()绘制一系列点
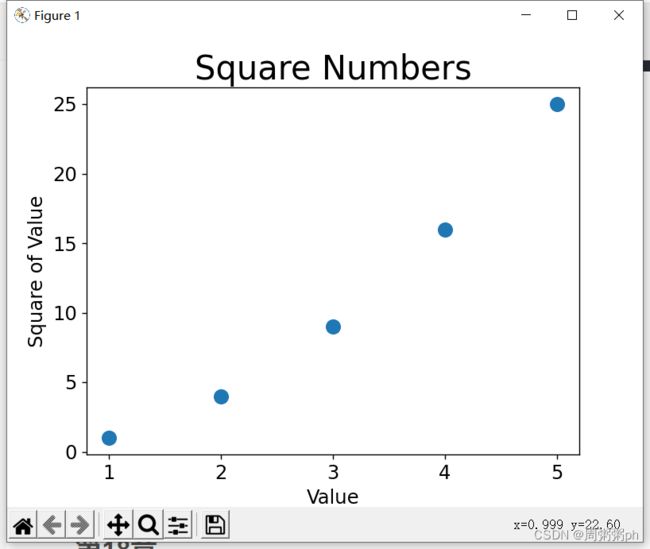
要绘制一系列的点,可向scatter()传递两个分别包含x值和y值的列表,如下图所示:
import matplotlib.pyplot as plt
x_values = [1,2,3,4,5]
y_values = [1,4,9,16,25]
plt.scatter(x_values,y_values,s=100)
#设置图表标题,并给坐标轴加上标签
plt.title("Square Numbers",fontsize = 24)
plt.xlabel("Value",fontsize = 14)
plt.ylabel("Square of Value",fontsize = 14)
# 设置刻度标记的大小
plt.tick_params(axis='both' , labelsize = 14)
plt.show()输出如下图所示:
15.2.5 自动计算数据
import matplotlib.pyplot as plt
x_values = list(range(1,1001))
y_values = [x**2 for x in x_values]
plt.scatter(x_values,y_values,s=20)
#设置图表标题,并给坐标轴加上标签
plt.title("Square Numbers",fontsize = 24)
plt.xlabel("Value",fontsize = 14)
plt.ylabel("Square of Value",fontsize = 14)
# 设置刻度标记的大小
plt.tick_params(axis='both' , labelsize = 14)
plt.show()输出如下图所示:

15.2.6 删除数据点的轮廓
- matplatib允许你给散点图中各个点指定颜色;默认为蓝色点和黑色轮廓,在散点图包含的数据点不多时效果很好;
- 但绘制很多点时,黑色轮廓可能会粘连在一起;
- 要删除数据点的轮廓,可在调用scatter()是传递实参edgecolor = 'none'
import matplotlib.pyplot as plt
x_values = list(range(1,1001))
y_values = [x**2 for x in x_values]
plt.scatter(x_values,y_values,edgecolors= 'none',s=20)
#设置图表标题,并给坐标轴加上标签
plt.title("Square Numbers",fontsize = 24)
plt.xlabel("Value",fontsize = 14)
plt.ylabel("Square of Value",fontsize = 14)
# 设置刻度标记的大小
plt.tick_params(axis='both' , labelsize = 14)
plt.show()输出如下图所示:

15.2.7 自定义颜色
要修改数据点的颜色,可向scatter()传递参数c,并将其设置为要使用的颜色的名称,如下所示:
import matplotlib.pyplot as plt
x_values = list(range(1,1001))
y_values = [x**2 for x in x_values]
plt.scatter(x_values,y_values,c=(0,0.5,0.2),edgecolors= 'none',s=20)
#设置图表标题,并给坐标轴加上标签
plt.title("Square Numbers",fontsize = 24)
plt.xlabel("Value",fontsize = 14)
plt.ylabel("Square of Value",fontsize = 14)
# 设置刻度标记的大小
plt.tick_params(axis='both' , labelsize = 14)
plt.show()- 可以使用RGB颜色模式自定义颜色;要制定颜色,可传递参数C,并将其设置为一个元组,其中包含三个0~1的小数值,它们分别代表红色,绿色,蓝色的分量;
- 值越接近0,指定的颜色越深,值越接近1,指定的颜色越浅;
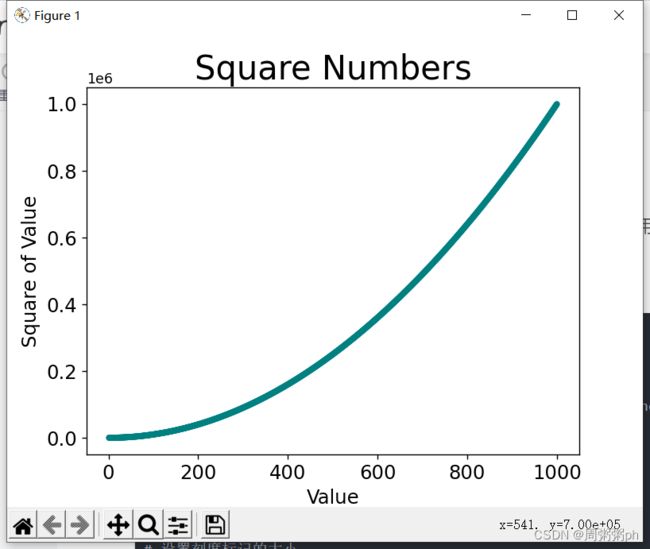
15.2.8 使用颜色映射
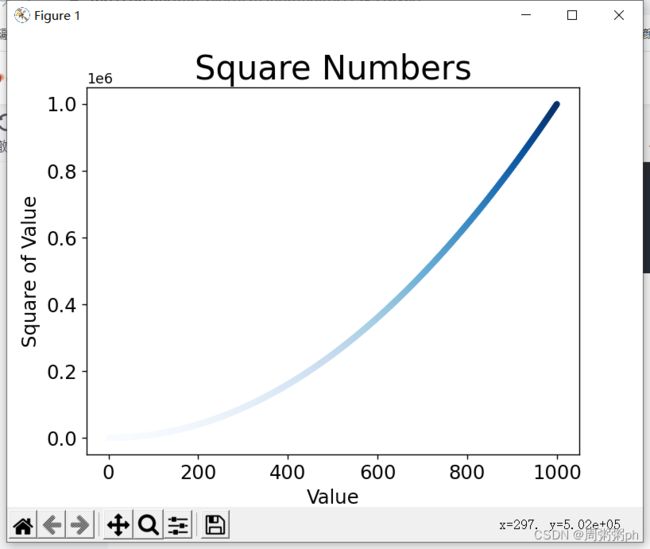
- 颜色映射是一系列颜色,它们从起始颜色渐变到结束颜色;
- 在可视化中,颜色的映射用于突出数据的规律;
import matplotlib.pyplot as plt
x_values = list(range(1,1001))
y_values = [x**2 for x in x_values]
plt.scatter(x_values,y_values,c=y_values,cmap=plt.cm.Blues,edgecolors= 'none',s=20)
#设置图表标题,并给坐标轴加上标签
plt.title("Square Numbers",fontsize = 24)
plt.xlabel("Value",fontsize = 14)
plt.ylabel("Square of Value",fontsize = 14)
# 设置刻度标记的大小
plt.tick_params(axis='both' , labelsize = 14)
plt.show()输出如下图所示:
12.2.9 自动保存图表
要让程序自动将图表保存到文件中,可将plt.show()的调用替换为plt.savefig()的调用:
import matplotlib.pyplot as plt
x_values = list(range(1,1001))
y_values = [x**2 for x in x_values]
plt.scatter(x_values,y_values,c=y_values,cmap=plt.cm.Blues,edgecolors= 'none',s=20)
#设置图表标题,并给坐标轴加上标签
plt.title("Square Numbers",fontsize = 24)
plt.xlabel("Value",fontsize = 14)
plt.ylabel("Square of Value",fontsize = 14)
# 设置刻度标记的大小
plt.tick_params(axis='both' , labelsize = 14)
plt.savefig('squares_plot.png',bbox_inches = 'tight')- 第一个实参指定要以什么样的文件名保存图表,这个文件将存储到 scatter_squares.py所载的目录中;
- 第二个实参指定将图表多余的空白区域裁剪掉;
- 如果要保留图表周围多余的空白区域,可省略这个实参;
15.3 随机漫步
在本节中,我们将使用Python来生成随机漫步数据,再使用matplotlib以引人瞩目的方式将这学数据呈现出来;
随机漫步是这样行走得到路径:每次形状都完全是随机的,没有明确的方向,结果是由一系列随机决策决定的;
15.3.1 创建Randomwalk()类
- 为模拟随机漫步,我们将创建一个名为Randomwalk的类,它随机的选择前进方向;
- 这个类需要三个属性,其中一个是存储随机漫步次数的变量,其他两个是列表,分别存储随机漫步经过的每个点的x和y坐标;
- Randomwalk类只包含两个方法:_init_()和fill_walk(),其中后者计算随机漫步经过的所有点;
下面先来看看init(),如下所示:
from random import choice
class RandomWalk():
"""一个生成随机漫步数据的类"""
def __init__(self,num_points=5000):
"""初始化随机漫步的属性"""
self.num_points = num_points
#所有随机漫步都始于(0,0)
self.x_values = [0]
self.x_values = [0]为做出随机决策,我们将所有可能选择都存储在一个列表中,并在每次做决策时都使用choice()来决定使用哪种选择;
15.3.2 选择方向
我们将使用fill_walk()来生成漫步包含的点,并决定每次漫步的方向,如下所示,请将这个方法添加到random_walk.py中:
from random import choice
class RandomWalk:
"""一个生成随机漫步数据的类"""
def __init__(self,num_points=5000):
"""初始化随机漫步的属性"""
self.num_points = num_points
# 所有随机漫步都始于(0,0)
self.x_values = [0]
self.y_values = [0]
def fill_walk(self):
"""计算随机漫步包含的所有点"""
# 不断漫步,直到列表达到指定长度
while len(self.x_values) < self.num_points:
x_direction = choice([1,-1])
x_distance = choice([0,1,2,3,4])
x_step = x_direction * x_distance
y_direction = choice([1,-1])
y_distance = choice([0, 1, 2, 3, 4])
y_step = y_direction * y_distance
# 拒绝原地踏步
if x_step == 0 and y_step == 0:
continue
#计算下一个点的x和y值
next_x = self.x_values[-1] + x_step
next_y = self.y_values[-1] + y_step
self.x_values.append(next_x)
self.y_values.append(next_y)
15.3.3 绘制随机漫步图
下面的代码将随机漫步的所有点都绘制出来:
import matplotlib.pyplot as plt
from random_walk import RandomWalk
#创建一个RandomWalk实例,并将其包含的点都绘制出来
rw = RandomWalk()
rw.fill_walk()
plt.scatter(rw.x_values,rw.y_values,s=15)
plt.show()输出如下图所示:

15.3.4 模拟多次随机漫步
每次随机漫步都不同,因此探索可能生成的各种模式很有趣;
要在不多次运行程序的情况下使用前面的代码模拟多次随机漫步,一种方法是将这些代码放在一个while循环中:
import matplotlib.pyplot as plt
from random_walk import RandomWalk
#只要程序处于活动状态,就不断的模拟随机漫步
while True:
#创建一个RandomWalk实例,并将其包含的点都绘制出来
rw = RandomWalk()
rw.fill_walk()
plt.scatter(rw.x_values,rw.y_values,s=15)
plt.show()
keep_runing = input("Make anther walk?(y/n): ")
if keep_runing == 'n':
breakMake anther walk?(y/n): y
Make anther walk?(y/n): y
Make anther walk?(y/n): n

15.3.6 给点着手
- 我们将用颜色映射来指出漫步中各点的先后顺序,并删除每个点的黑色轮廓,让它们的颜色更明显;
- 为了根据漫步中各点的先后顺序进行着色,我们传递参数c,并将其设置为一个列表,其中包含各点的先后顺序;
- 由于这些点是按顺序绘制的,因此参数c指定的列表只需要包含数字1~5000,如下所示:
import matplotlib.pyplot as plt
from random_walk import RandomWalk
#只要程序处于活动状态,就不断的模拟随机漫步
while True:
#创建一个RandomWalk实例,并将其包含的点都绘制出来
rw = RandomWalk()
rw.fill_walk()
point_bumbers = list(range(rw.num_points))
plt.scatter(rw.x_values,rw.y_values,c=point_bumbers,cmap=plt.cm.Blues,edgecolors='none',s=15)
plt.show()
keep_runing = input("Make anther walk?(y/n): ")
if keep_runing == 'n':
break输出如下图所示:

15.3.7 重新绘制起点和终点
import matplotlib.pyplot as plt
from random_walk import RandomWalk
#只要程序处于活动状态,就不断的模拟随机漫步
while True:
#创建一个RandomWalk实例,并将其包含的点都绘制出来
rw = RandomWalk()
rw.fill_walk()
point_bumbers = list(range(rw.num_points))
plt.scatter(rw.x_values,rw.y_values,c=point_bumbers,cmap=plt.cm.Blues,edgecolors='none',s=15)
#突出起点和终点
plt.scatter(0,0,c='green',edgecolors='none',s=100)
plt.scatter(rw.x_values[-1],rw.y_values[-1],c='red',edgecolors='none',s=100)
plt.show()
keep_runing = input("Make anther walk?(y/n): ")
if keep_runing == 'n':
break输出如下图所示:

15.3.8 隐藏坐标轴
import matplotlib.pyplot as plt
from random_walk import RandomWalk
#只要程序处于活动状态,就不断的模拟随机漫步
while True:
#创建一个RandomWalk实例,并将其包含的点都绘制出来
rw = RandomWalk()
rw.fill_walk()
point_bumbers = list(range(rw.num_points))
plt.scatter(rw.x_values,rw.y_values,c=point_bumbers,cmap=plt.cm.Blues,edgecolors='none',s=15)
#突出起点和终点
plt.scatter(0,0,c='green',edgecolors='none',s=100)
plt.scatter(rw.x_values[-1],rw.y_values[-1],c='red',edgecolors='none',s=100)
#隐藏坐标,注意书上代码错误!!!
plt.xticks([])
plt.yticks([])
plt.show()
keep_runing = input("Make anther walk?(y/n): ")
if keep_runing == 'n':
break输出如下图所示:

注意:书上隐藏坐标轴的代码存在问题
15.3.9 增加点数
import matplotlib.pyplot as plt
from random_walk import RandomWalk
#只要程序处于活动状态,就不断的模拟随机漫步
while True:
#创建一个RandomWalk实例,并将其包含的点都绘制出来
rw = RandomWalk(50000)
rw.fill_walk()
point_bumbers = list(range(rw.num_points))
plt.scatter(rw.x_values,rw.y_values,c=point_bumbers,cmap=plt.cm.Blues,edgecolors='none',s=15)
#突出起点和终点
plt.scatter(0,0,c='green',edgecolors='none',s=1)
plt.scatter(rw.x_values[-1],rw.y_values[-1],c='red',edgecolors='none',s=1)
#隐藏坐标,注意书上代码错误!!!
plt.xticks([])
plt.yticks([])
plt.show()
keep_runing = input("Make anther walk?(y/n): ")
if keep_runing == 'n':
break输出如下图所示:

15.3.10 调整尺寸以适合屏幕
import matplotlib.pyplot as plt
from random_walk import RandomWalk
#只要程序处于活动状态,就不断的模拟随机漫步
while True:
#创建一个RandomWalk实例,并将其包含的点都绘制出来
rw = RandomWalk(50000)
rw.fill_walk()
#设置绘图窗口的尺寸
plt.figure(figsize=(10, 6))
point_bumbers = list(range(rw.num_points))
plt.scatter(rw.x_values,rw.y_values,c=point_bumbers,cmap=plt.cm.Blues,edgecolors='none',s=15)
#突出起点和终点
plt.scatter(0,0,c='green',edgecolors='none',s=1)
plt.scatter(rw.x_values[-1],rw.y_values[-1],c='red',edgecolors='none',s=1)
#隐藏坐标,注意书上代码错误!!!
plt.xticks([])
plt.yticks([])
plt.show()
keep_runing = input("Make anther walk?(y/n): ")
if keep_runing == 'n':
break输出如下图所示:

15.4 使用Pygal模拟骰子
15.4.1 安装Pygal
同之前操作,不在赘述
15.4.3 创建Die类
from random import randint
class Die():
"""表示一个骰子的类"""
def __init__(self,num_sides=6):
"""骰子默认为6面"""
self.num_sides = num_sides
def roll(self):
"""返回一个位于1和骰子面试之间的随机值"""
return randint(1,self.num_sides)15.4.4 掷骰子
使用这个类来创建图表前,先来掷D6骰子,将结果打印出来,并检查是否合理:
from die import Die
#创建一个D6
die =Die()
#掷几次骰子,并将结果存储再一个列表中
results = []
for roll_num in range(100):
result = die.roll()
results.append(result)
print(results)输出如下所示:
[1, 1, 3, 3, 5, 5, 6, 6, 3, 5, 2, 4, 4, 2, 2, 4, 5, 1, 4, 1, 1, 1, 5, 4, 3, 5, 2, 5, 3, 4, 4, 6, 6, 1, 4, 5, 2, 6, 3, 1, 4, 2, 6, 4, 5, 3, 3, 3, 4, 2, 6, 6, 3, 3, 5, 6, 3, 4, 2, 6, 1, 5, 1, 5, 6, 6, 1, 5, 2, 4, 4, 3, 5, 2, 5, 4, 2, 5, 3, 2, 5, 3, 1, 5, 6, 3, 3, 2, 3, 4, 5, 1, 6, 2, 4, 6, 4, 6, 2, 6]
15.4.5 分析结果
为分析掷一个D6骰子的结果,我们计算每个点数出现的次数:
from die import Die
#创建一个D6
die =Die()
#掷几次骰子,并将结果存储再一个列表中
results = []
for roll_num in range(1000):
result = die.roll()
results.append(result)
#分析结果
frequencies = []
for value in range(1,die.num_sides+1):
frequency = results.count(value)
frequencies.append(frequency)
print(frequencies)
输出如下所示:
[182, 179, 132, 185, 171, 151]
15.4.6 绘制直方图
有了频率列表后,我们就可以绘制一个表示结果的直方图;
import pygal
from die import Die
#创建一个D6
die =Die()
#掷几次骰子,并将结果存储再一个列表中
results = []
for roll_num in range(1000):
result = die.roll()
results.append(result)
#分析结果
frequencies = []
for value in range(1,die.num_sides+1):
frequency = results.count(value)
frequencies.append(frequency)
print(frequencies)
hist = pygal.Bar()
hist.title = "Results of rolling one D6 1000 times."
hist.x_labels = ['1','2','3','4','5','6']
hist.x_title = 'Result'
hist.y_title = 'Frequency of Result'
hist.add('D6',frequencies)
hist.render_to_file('die_visual.svg')
要查看生成的直方图,最简单的方式是使用Web浏览器;

15.4.7 同时掷两个骰子
import pygal
from die import Die
#创建一个D6
die_1 = Die()
die_2 = Die()
#掷骰子多次,并将结果存储再一个列表中
results = []
for roll_num in range(1000):
result = die_1.roll()+die_2.roll()
results.append(result)
#分析结果
frequencies = []
max_result = die_1.num_sides +die_2.num_sides
for value in range(2,max_result+1):
frequency = results.count(value)
frequencies.append(frequency)
print(frequencies)
hist = pygal.Bar()
hist.title = "Results of rolling two D6 1000 times."
hist.x_labels = ['2','3','4','5','6','7','8','9','10','11','12']
hist.x_title = 'Result'
hist.y_title = 'Frequency of Result'
hist.add('D6+D6',frequencies)
hist.render_to_file('die_visual.svg')
要查看生成的直方图,最简单的方式是使用Web浏览器;
[26, 52, 89, 121, 142, 160, 133, 102, 78, 62, 35]

15.4.8 同时掷面数不同骰子
from die import Die
import pygal
#创建一个D6和一个D10
die_1 = Die()
die_2 = Die(10)
#掷骰子多次,并将结果存储再一个列表中
results = []
for roll_num in range(50000):
result = die_1.roll() + die_2.roll()
results.append(result)
#分析结果
frequencies = []
max_result = die_1.num_sides +die_2.num_sides
for value in range(2,max_result+1):
frequency = results.count(value)
frequencies.append(frequency)
print(frequencies)
hist = pygal.Bar()
hist.title = "Results of rolling a D6 and a D10 50000 times."
hist.x_labels = ['2','3','4','5','6','7','8','9','10','11','12','13','14','15','16']
hist.x_title = 'Result'
hist.y_title = 'Frequency of Result'
hist.add('D6+D10',frequencies)
hist.render_to_file('die_visual.svg')[803, 1660, 2495, 3377, 4164, 5017, 4962, 5048, 5019, 5023, 4213, 3368, 2425, 1629, 797]
要查看生成的直方图,最简单的方式是使用Web浏览器;

第16章 下载数据
16.1 csv文件格式
要在文本中存储数据,最简单的方式是将数据作为一系列以逗号分隔的值(CSV)写入文件
import csv
filename = r'C:\Users\DELL\Desktop\python_work\《Python编程》源代码文件\chapter_16\sitka_weather_07-2014.csv'
with open(filename) as f:
reader =csv.reader(f)
header_row = next(reader)
print(header_row)输出为:
['AKDT', 'Max TemperatureF', 'Mean TemperatureF', 'Min TemperatureF', 'Max Dew PointF', 'MeanDew PointF', 'Min DewpointF', 'Max Humidity', ' Mean Humidity', ' Min Humidity', ' Max Sea Level PressureIn', ' Mean Sea Level PressureIn', ' Min Sea Level PressureIn', ' Max VisibilityMiles', ' Mean VisibilityMiles', ' Min VisibilityMiles', ' Max Wind SpeedMPH', ' Mean Wind SpeedMPH', ' Max Gust SpeedMPH', 'PrecipitationIn', ' CloudCover', ' Events', ' WindDirDegrees']
注意:
- 文件头的格式并非总是一致的,空格和单位可能出现再奇怪的地方;
- 这再原始数据文件中很常见,但不会带来任何问题;
16.1.2 打印文件头及其位置
import csv
filename = r'C:\Users\DELL\Desktop\python_work\《Python编程》源代码文件\chapter_16\sitka_weather_07-2014.csv'
with open(filename) as f:
reader =csv.reader(f)
header_row = next(reader)
for index,column_header in enumerate(header_row):
print(index,column_header)输出为:
0 AKDT
1 Max TemperatureF
2 Mean TemperatureF
3 Min TemperatureF
4 Max Dew PointF
5 MeanDew PointF
6 Min DewpointF
7 Max Humidity
8 Mean Humidity
9 Min Humidity
10 Max Sea Level PressureIn
11 Mean Sea Level PressureIn
12 Min Sea Level PressureIn
13 Max VisibilityMiles
14 Mean VisibilityMiles
15 Min VisibilityMiles
16 Max Wind SpeedMPH
17 Mean Wind SpeedMPH
18 Max Gust SpeedMPH
19 PrecipitationIn
20 CloudCover
21 Events
22 WindDirDegreesProcess finished with exit code 0
16.1.3 提取并读取数据
知道需要那些列中的数据后,我们来读取一些数据;首先读取每天的最高气温:
import csv
filename = r'C:\Users\DELL\Desktop\python_work\《Python编程》源代码文件\chapter_16\sitka_weather_07-2014.csv'
with open(filename) as f:
reader =csv.reader(f)
header_row = next(reader)
highs = []
for row in reader:
highs.append(row[1])
print(highs)输出为:
['64', '71', '64', '59', '69', '62', '61', '55', '57', '61', '57', '59', '57', '61', '64', '61', '59', '63', '60', '57', '69', '63', '62', '59', '57', '57', '61', '59', '61', '61', '66']
下面使用int()将这些字符串转化为数字
import csv
filename = r'C:\Users\DELL\Desktop\python_work\《Python编程》源代码文件\chapter_16\sitka_weather_07-2014.csv'
with open(filename) as f:
reader =csv.reader(f)
header_row = next(reader)
highs = []
for row in reader:
high = int(row[1])
highs.append(row[1])
print(highs)输出为:
['64', '71', '64', '59', '69', '62', '61', '55', '57', '61', '57', '59', '57', '61', '64', '61', '59', '63', '60', '57', '69', '63', '62', '59', '57', '57', '61', '59', '61', '61', '66']
16.1.4 绘制气温图表
为可视化这些气温数据,我们首先使用matplotlib创建一个显示每日最高气温的简单图形:
import csv
from matplotlib import pyplot as plt
filename = r'C:\Users\DELL\Desktop\python_work\《Python编程》源代码文件\chapter_16\sitka_weather_07-2014.csv'
with open(filename) as f:
reader =csv.reader(f)
header_row = next(reader)
highs = []
for row in reader:
high = int(row[1])
highs.append(high)
#根据数据绘制图形
fig = plt.figure(dpi=128, figsize=(10, 6))
plt.plot(highs, c='red')
#设置图形的格式
plt.title("Daily high temperatures,July 2014")
plt.xlabel('', fontsize=16)
plt.ylabel("Temperature(F)")
plt.tick_params(axis='both', which='major', labelsize=16)
plt.show()输出为:

15.1.5 模块datatime
下面在图表添加日期,使其更有用;
import csv
from matplotlib import pyplot as plt
from datetime import datetime
filename = r'C:\Users\DELL\Desktop\python_work\《Python编程》源代码文件\chapter_16\sitka_weather_07-2014.csv'
with open(filename) as f:
reader =csv.reader(f)
header_row = next(reader)
dates,highs = [],[]
for row in reader:
current_date = datetime.strptime(row[0],'%Y-%m-%d')
dates.append(current_date)
high = int(row[1])
highs.append(high)
#根据数据绘制图形
fig = plt.figure(dpi=128, figsize=(10, 6))
plt.plot(dates,highs, c='red')
#设置图形的格式
plt.title("Daily high temperatures,July 2014", fontsize=16)
plt.xlabel('', fontsize=16)
fig.autofmt_xdate()
plt.ylabel("Temperature(F)", fontsize=16)
plt.tick_params(axis='both', which='major', labelsize=16)
plt.show()输出为:

模块datetime中设置日期和时间格式的实参

16.1.7 涵盖更长的时间
import csv
from matplotlib import pyplot as plt
from datetime import datetime
filename = r'C:\Users\DELL\Desktop\python_work\《Python编程》源代码文件\chapter_16\sitka_weather_2014.csv'
with open(filename) as f:
reader =csv.reader(f)
header_row = next(reader)
dates,highs = [],[]
for row in reader:
current_date = datetime.strptime(row[0],'%Y-%m-%d')
dates.append(current_date)
high = int(row[1])
highs.append(high)
#根据数据绘制图形
fig = plt.figure(dpi=128, figsize=(10, 6))
plt.plot(dates,highs, c='red')
#设置图形的格式
plt.title("Daily high temperatures - 2014", fontsize=16)
plt.xlabel('', fontsize=10)
fig.autofmt_xdate()
plt.ylabel("Temperature(F)", fontsize=16)
plt.tick_params(axis='both', which='major', labelsize=16)
plt.show()输出为:

16.1.8 再绘制一个数据系统
import csv
from matplotlib import pyplot as plt
from datetime import datetime
filename = r'C:\Users\DELL\Desktop\python_work\《Python编程》源代码文件\chapter_16\sitka_weather_2014.csv'
with open(filename) as f:
reader =csv.reader(f)
header_row = next(reader)
dates,highs,lows= [],[],[]
for row in reader:
current_date = datetime.strptime(row[0],'%Y-%m-%d')
dates.append(current_date)
high = int(row[1])
highs.append(high)
low = int(row[3])
lows.append(low)
#根据数据绘制图形
fig = plt.figure(dpi=128, figsize=(10, 6))
plt.plot(dates,highs, c='red')
plt.plot(dates,lows,c='blue')
#设置图形的格式
plt.title("Daily high and low temperatures - 2014", fontsize=24)
plt.xlabel('', fontsize=10)
fig.autofmt_xdate()
plt.ylabel("Temperature(F)", fontsize=16)
plt.tick_params(axis='both', which='major', labelsize=16)
plt.show()输出为:

16.1.9 给图标区域着色
import csv
from matplotlib import pyplot as plt
from datetime import datetime
filename = r'C:\Users\DELL\Desktop\python_work\《Python编程》源代码文件\chapter_16\sitka_weather_2014.csv'
with open(filename) as f:
reader =csv.reader(f)
header_row = next(reader)
dates,highs,lows= [],[],[]
for row in reader:
current_date = datetime.strptime(row[0],'%Y-%m-%d')
dates.append(current_date)
high = int(row[1])
highs.append(high)
low = int(row[3])
lows.append(low)
#根据数据绘制图形
fig = plt.figure(dpi=128, figsize=(10, 6))
plt.plot(dates,highs, c='red',alpha=0.5)
plt.plot(dates,lows,c='blue',alpha=0.5)
plt.fill_between(dates,highs,lows,facecolor='blue',alpha=0.1)
#设置图形的格式
plt.title("Daily high and low temperatures - 2014", fontsize=16)
plt.xlabel('', fontsize=10)
fig.autofmt_xdate()
plt.ylabel("Temperature(F)", fontsize=16)
plt.tick_params(axis='both', which='major', labelsize=16)
plt.show()输出为:

16.1.10 错误检查
16.2 制作交易收盘价走势图:JSON格式
16.2.1 下载收盘价数据
16.2.2 提取相关数据
16.2.3 将字符串转化为数字值
第17章 使用API
17.1 使用Web API
Web API是网站的一部分,用于于使用非常具体的URL请求特定信息的程序交互,这种请求称为API调用;
请求的数据将易于出来的格式(如JSON或CSV)返回;