【云计算】知识汇总
【云计算】知识汇总
- 1. 云计算基础
-
- 1.1 云计算的定义
- 1.2 云计算的分类
- 1.3云计算的组成
- 1.4 云计算的关键技术
- 1.5 怎样才算是云计算系统?
- 1.6云计算的特点
- 1.7 大数据的定义及特点
- 1.8 大数据研究的挑战及基本途径
- 2.并行计算
-
- 2.1为什么需要并行计算?
- 2.2 并行计算的分类
- 2.3 并行计算的主要技术问题
- 2.4 MPI的主要功能
- 2.4 MPI的特点和不足
- 2.5 为什么需要海量数据并行处理技术?
- 3. 云计算原理及应用
-
- 3.1 什么是MapReduce?
- 3.2 MapReduce的主要设计思想与特点
- 3.3MapReduce的并行计算模型(以词频统计为例)
- 3.4Google MapReduce并行处理的基本过程
- 3.5 Google GFS的基本设计原则
- 3.6 Google GFS的基本架构和工作原理
- 3.7 BigTable表中的数据通过哪些信息进行索引和定位?
- 3.8BigTable数据存储格式
- 3.9 HDFS基本架构 【 Hadoop】
- 3.10 Hadoop MapReduce基本架构
- 4. 云计算虚拟化技术
-
- 4.1虚拟化的含义
- 4.2网络虚拟化与SDN(软件定义网络)的区别
- 4.3服务器虚拟化的关键特性
- 4.4 内存虚拟化中的三种内存类型
- 4.5内存虚拟化管理单元的两种方法
- 4.6解释DLL地狱
- 4.7应用虚拟化
- 4.8桌面虚拟化
- 5.云计算安全
-
- 5.1云安全与传统信息安全的异同点
- 5.2 云安全威胁有哪些?
- 5.3 虚拟机存在的相关安全问题
- 5.4 云平台为用户提供的服务安全
- 6.亚马逊和微软云计算平台
-
- 6.1非关系型数据库和关系型数据库优缺点
- 6.2 EC2的基本架构【亚马逊】
- 6.3EC2通信时用到三种IP地址
- 6.4SimpleDB中的域、条目、属性、值
- 6.5SimpleDB和DynamoDB的比较
- 6.6微软云计算服务平台各组成部分【微软】
- 6.7Windows Azure应用程序包括的实例
- 6.8Windows Azure存储服务支持的数据类型
- 6.9全局命名空间
- 6.10SQL Azure提供的三种服务
- 6.11SQL Azure与SQL Server的区别
- 6.12AppFabric提供的服务
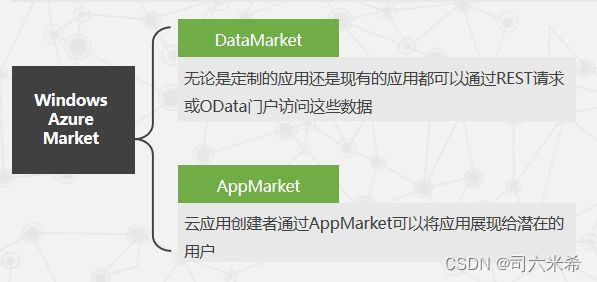
- 6.13Windows Azure Market提供的两种服务
- 7.云计算数据中心
-
- 7.1数据中心的四个特征
- 7.2云数据中心网络体系结构
- 7.3 绿色节能技术
- 7.4自动化管理的特征
- 7.5数据中心容灾备份系统的两个主要技术指标
- 7.6容灾备份的关键技术
1. 云计算基础
1.1 云计算的定义
通过集中式远程计算资源池,以按需分配方式,为终端用户提供强大且廉价的计算服务能力
1.2 云计算的分类
按云计算服务层面进行分类
- SaaS: Software as a Service(软件即服务):提供各种应用软件服务
- PaaS:Platform as a Service(平台即服务):提供软件支撑平台服务
- IaaS:Infrastructure as a Service(基础设施即服务): 提供接近于裸机(物理机或虚拟机)的计算资源和基础设施服务
按云计算系统类型进行分类
- 公用云:提供面向社会大众、公共群体的云计算服务,如Amazon云平台,Google AppEng。公有云有很多优点,但最大的一个缺点是难以保证数据的私密性。
- 私有云:提供面向应用行业/组织内的云计算服务如政府机关、移动通信、学校等内部使用的云平台。私有云可较好地解决数据私密性问题,对移动通信、公安等数据私密性要求特别高的企业或机构,建设私有云将是一个必然的选择。
- 社区云:提供面向社团组织内用户使用的云计算平台,如美国航天局(NASA) Nebula云平台为NASA内的研究人员提供快速的IT访问服务。
- 混合云:包含以上2种以上云计算类型的混合式云平台
1.3云计算的组成
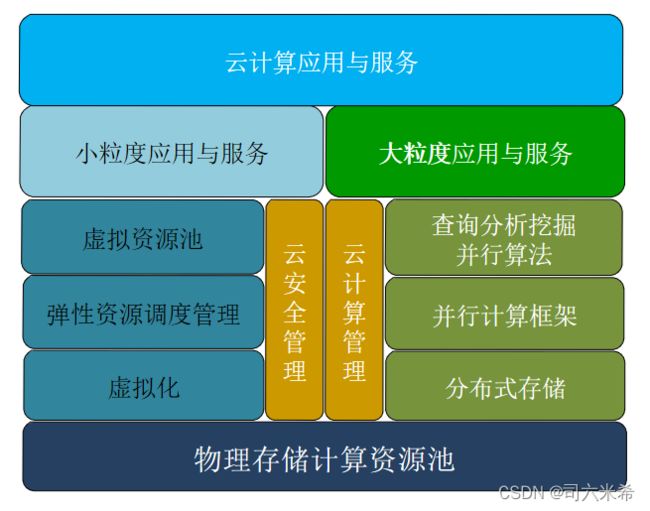
1.4 云计算的关键技术
1.虚拟化技术:虚拟机的安装、设置、调度分配、使用、 故障检测与失效恢复等
2.云计算构架技术:研究解决适合于云计算的系统软硬件构架
3.资源调度技术:解决物理或虚拟计算资源的自动化分配、调度、配置、使用、负载均衡、回收等资源管理
4.并行计算技术:针对大数据或复杂计算应用,解决数据或计算任务切分和并行计算算法设计问题
5.大数据存储技术:解决大数据的分布存储、共享访问、 数据备份等问题
6.云安全技术:解决云计算系统的访问安全性、数据安全性(包括数据私密性)等问题
7.云计算应用:面向各个行业的、不同形式的云计算应用技术和系统
1.5 怎样才算是云计算系统?
一个计算系统必须具备以下两个特征才能算是云计算系统(至少具备第一个特征):
1.资源虚拟化和弹性调度解决小粒度应用资源共享:
基于虚拟化和弹性调度,以按需分配方式,为小粒度应用提供计算资源,实现资源共享
2.大数据存储处理和并行计算服务提供大粒度应用计算能力:
基于云端的强大而廉价的计算能力,为大粒度应用提供传统计算系统或用户终端所无法完成的计算服务。这些计算能力包括海量数据存储能力、以及大规模并行计算能力。
1.6云计算的特点
1.透明的云端计算服务
2.“无限”多的计算资源,提供强大的计算能力
3.按需分配,弹性伸缩,取用方便,成本低廉
4.资源共享,降低企业IT基础设施建设维护费用
5.应用部署快速而容易
6.软件/应用功能更新方便快捷
7.节省能源,绿色环保
8.集计算技术之大成,具有很强的技术性、工程型特点
1.7 大数据的定义及特点
大数据意指一个超大的、难以用现有常规的数据库管理技术和工具 处理的数据集。
大数据的4V特点
-
Volume 大容量的,数据量大(
大数据的起始计量单位至少是PB(1 000个TB)、EB(100万个TB)或ZB(10亿个TB)。非结构化数据的超大规模和增长,比结构化数据增长快10~50倍,是传统数据仓库的10~50倍
-
Variety 多样性
大数据的类型可以包括网络日志、音频、视频、图片和地理位置信息等,具有异构性和多样性的特点,没有明显的模式,也没有连贯的语法和句义,多类型的数据对数据的处理能力提出了更高的要求。 -
Velocity 时效性
处理速度快,时效性要求高,需要实时分析而非批量式分析,数据的输入、处理和分析连贯性地处理,这是大数据区分于传统数据挖掘最显著的特征 -
Veracity 准确性
1.8 大数据研究的挑战及基本途径
挑战
1.数据规模导致难以应对的存储和计算量
2.数据规模导致传统算法失效
3.大数据复杂的数据关联性导致高复杂度的计算
基本途径
1.继续寻找新算法降低计算复杂度
2.降低大数据尺度,寻找数据尺度无关算法
3.大数据并行化处理
2.并行计算
2.1为什么需要并行计算?
1.单核处理器性能提升接近极限
2.应用领域计算规模和复杂度大幅提高
3.单处理器向多核并行计算发展成为必然趋势
2.2 并行计算的分类
按计算特征分类
1.数据密集型并行计算
2.计算密集型并行计算
3.数据密集与计算密集混合型并行计算
按并行程序设计模型/方法分类
1.共享内存变量 (Shared Memory Variables)
2.消息传递方式(Message Passing)
3.MapReduce方式
2.3 并行计算的主要技术问题
在硬件构架、软件构架和并行算法方面
1.多核/多处理器网络互连结构技术【硬件 - 网络互连 】
2.存储访问体系结构【硬件 - 体系结构】
3.分布式数据与文件管理【并行算法 - 文件管理】
4.并行计算任务分解与算法设计【并行算法 - 算法设计】
5.并行程序设计模型和方法【软件 - 程序设计模型】
6.数据同步访问和通信控制【硬件 - 数据同步访问、通信控制】
7.可靠性设计与容错技术【并行算法 - 可靠】
8.并行计算软件框架平台【软件 - 框架平台】
9.系统性能评价和程序并行度评估【并行算法 - 评估】
并行计算技术的分类
- 按数据和指令处理结构:弗林(Flynn)分类
- 按并行类型
- 按存储访问构架
- 按系统类型
- 按计算特征
- 按并行程序设计模型/方法
2.4 MPI的主要功能
MPI (Message Passing Interface,基于消息传递的高性能并行计算编程接口)
1.提供点对点通信(Point-point communication)
提供同步通信功能(阻塞通信)
提供异步通信功能(非阻塞通信)
2.提供节点集合通信(Collective communication) 提供一个进程与多个进程间同时通信的功能
提供一对多的广播通信(数据移动)
提供多节点计算同步控制(同步)
提供对结果的规约(Reduce)计算功能(规约)
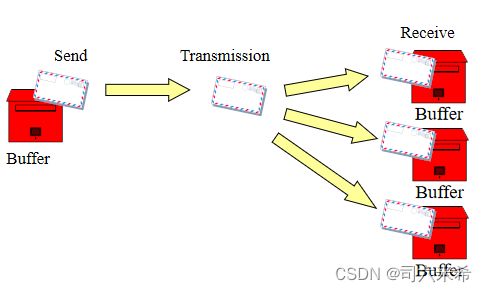
3.提供用户自定义的复合数据类型传输
2.4 MPI的特点和不足
MPI的特点
1.灵活性好,适合于各种计算密集型的并行计算任务
2.独立于语言的编程规范,可移植性好
3.有很多开放机构或厂商实现并支持
MPI的不足
1.无良好的数据和任务划分支持
2.缺少分布文件系统支持分布数据存储管理
3.通信开销大,当计算问题复杂、节点数量很大时,难以处理,性能大幅下降
4.无节点失效恢复机制,一旦有节点失效,可能导致计算过程无效
5.缺少良好的构架支撑,程序员需要考虑以上所有细节问题,程序设计较为复杂
2.5 为什么需要海量数据并行处理技术?
1.海量数据及其处理已经成为现实世界的急迫需求
2.海量数据隐含着更准确的事实
大数据集上的简单算法能比小数据集上的复杂算法产生更好的结果!
3.处理数据的能力大幅落后于数据增长,需要寻找有效的数据密集型并行计算方法
3. 云计算原理及应用
3.1 什么是MapReduce?
MapReduce是Google公司发明的一种面向大规模海量数据处理的高性能并行计算平台和软件编程框架,是目前最为成功和最易于使用的大规模海量数据并行处理技术,广泛应用于搜索引擎(文档倒排索引,网页链接图分析与页面排序等)、Web日志分析、文档分析处理、机器学习、机器翻译等各种大规模数据并行计算应用领域,MapReduce是面向大规模数据并行处理的:
1.基于集群的高性能并行计算平台(Cluster Infrastructure)
2.并行程序开发与运行框架(Software Framework)
3.并行程序设计模型与方法(Programming Model & Methodology)
3.2 MapReduce的主要设计思想与特点
- 1.向“外”横向扩展,而非向“上”纵向扩展
即MapReduce集群的构筑选用价格便宜、易于扩展的大量低端商用服务器,而非价格昂贵、不易扩展的高端服务器(SMP) - 2.失效被认为是常态
MapReduce并行计算软件框架使用了多种有效的机制,如节点自动重启技术,使集群和计算框架具有对付节点失效的健壮性,能有效处理失效节点的检测和恢复 - 3.把处理向数据迁移
减少大规模数据并行计算系统中的数据通信开销,代之以把数据传送到处理节点(数据向处理器或代码迁移),应当考虑将处理向数据靠拢和迁移 - 4.顺序处理数据、避免随机访问数据
- 5.为应用开发者隐藏系统层细节
- 6.平滑无缝的可扩展性
主要包括两层意义上的扩展性:数据扩展和系统规模扩展
3.3MapReduce的并行计算模型(以词频统计为例)

3.4Google MapReduce并行处理的基本过程
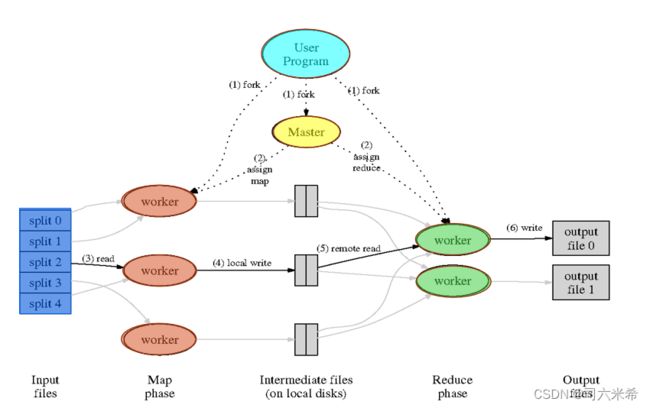
3.5 Google GFS的基本设计原则
海量数据怎么存储?数据存储可靠性怎么解决?
当前主流的分布式文件系统有:
RedHat的GFS
IBM的GPFS
Sun的Lustre等
Google GFS是一个基于分布式集群的大型分布式文件系统,为MapReduce计算框架提供底层数据存储和数据可靠性支撑

1.廉价本地磁盘分布存储
2.多数据自动备份解决可靠性
3.为上层的MapReduce计算框架提供支撑
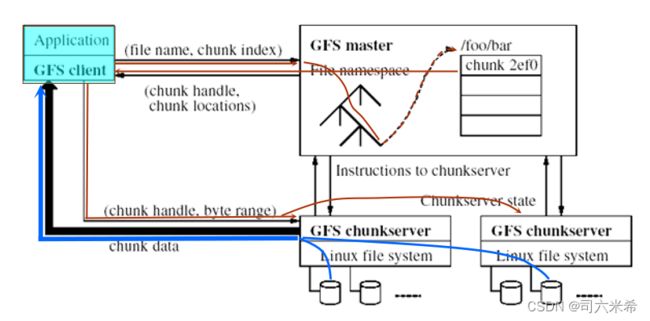
3.6 Google GFS的基本架构和工作原理
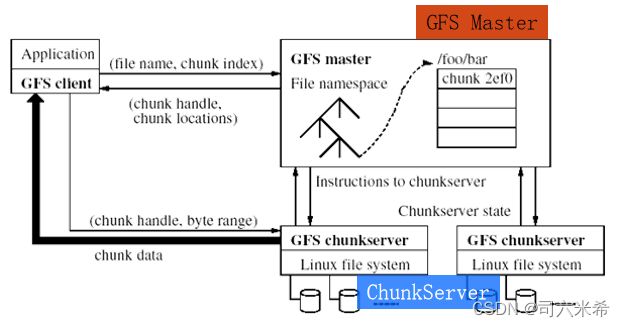
- GFS Master

- GFS Chunk Server

数据访问工作过程
1.在程序运行前,数据已经存储在GFS文件系统中;程序运行时应用程序会告诉GFS Server所要访问的文件名或者数据块索引是什么

2.GFS Server根据文件名或数据块索引在其文件目录空间中查找和定位该文件或数据块,并找数据块在具体哪些ChunkServer上;将这些位置信息回送给应用程序
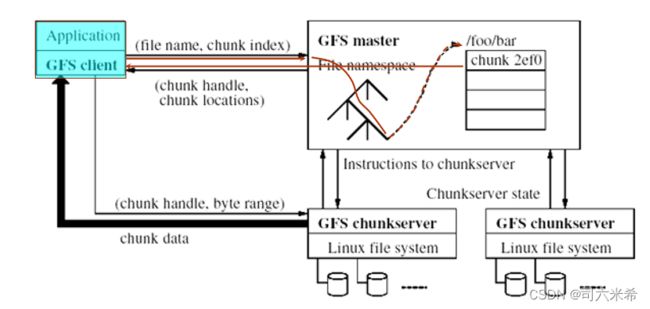
3.应用程序根据GFSServer返回的具体Chunk数据块位置信息,直接访问相应的Chunk Server

4.应用程序根据GFSServer返回的具体Chunk数据块位置信息直接读取指定位置的数据进行计算处理
3.7 BigTable表中的数据通过哪些信息进行索引和定位?
GFS是一个文件系统,难以提供对结构化数据的存储和访问管理。为此,Google在GFS之上又设计了一个结构化数据存储和访问管理系统—BigTable,为应用程序提供比单纯的文件系统更方便、更高层的数据操作能力
1.一个行关键字(row key)
2.一个列关键字(column key)
3.一个时间戳(time stamp)
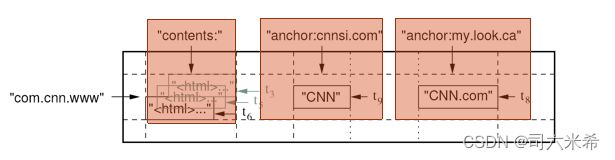
3.8BigTable数据存储格式
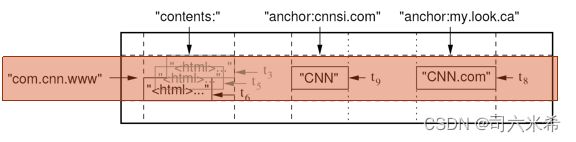
-
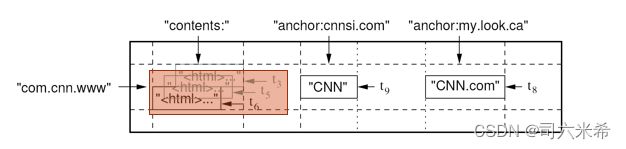
行(Row):大小不超过64KB的任意字符串。表中的数据都是根据行关键字进行排序的。
com.cnn.www就是一个行关键字,指明一行存储数据。URL地址倒排好处是:1)同一地址的网页将被存储在表中连续的位置,便于查找;2)倒排便于数据压缩,可大幅提高数据压缩率 -
子表(Tablet):一个大表可能太大,不利于存储管理,将在水平方向上被分为多个子表-
-
列(Column): BigTable将列关键字组织成为“列族”(column family),每个族中的数据属于同一类别,如anchor是一个列族,其下可有不同的表示一个个超链的列关键字。一个列族下的数据会被压缩在一起存放。因此,一个列关键字可表示为:
族名:列名(family:qualifier)
content、anchor都是族名;而cnnsi.com和my.look.ca则是anchor族中的列名。
-
时间戳(time stamp): 很多时候同一个URL的网页会不断更新,而Google需要保存不同时间的网页数据,因此需要使用时间戳来加以区分。
-
为了简化不同版本的数据管理,BigTable提供给了两种设置:
保留最近的n个版本数据
保留限定时间内的所有不同版本数据
3.9 HDFS基本架构 【 Hadoop】

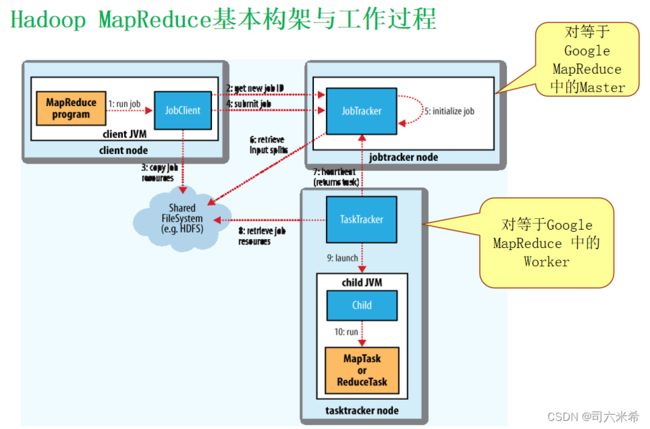
3.10 Hadoop MapReduce基本架构
4. 云计算虚拟化技术
4.1虚拟化的含义
1.虚拟化的对象是各种各样的资源;
2.经过虚拟化后的逻辑资源对用户隐藏不必要的实现细节;
3.用户可以在虚拟环境中实现其在真实环境中的部分或全部功能。
虚拟化本质:物理硬件与软件层分开,实现更高的资源利用和开放性
4.2网络虚拟化与SDN(软件定义网络)的区别
网络虚拟化是云计算驱动:为每一个租户提供完整的网络视图,安全且完全隔离的虚拟的网络环境实现真正的服务模型;SDN是产业开放性驱动:促使网络设备分层,负责转发的硬件、网络操作系统及其上层应用,每层对应更灵活选择的产品。
4.3服务器虚拟化的关键特性
分区:在单一物理服务器上同时运行多个虚拟机
隔离:在同一服务器上的虚拟机之间相互隔离
封装:整个虚拟机都保存在文件中,而且可以通过移动和复制这些文件的方式来移动和复制该虚拟机
独立性:无需修改即可在任何服务器上运行虚拟机
4.4 内存虚拟化中的三种内存类型
1.逻辑内存
2“物理”内存
3.机器内存
4.5内存虚拟化管理单元的两种方法
1.影子页表法:客户OS维护自己的页表,对应“伪”物理内存的地址;虚拟机监视器为每台虚拟机维护一个对应的页表,对应着真实的机器内存地址;虚拟机监视器的页表以1中的页表为蓝本建立,并随之更新而更新,所以称“影子页表”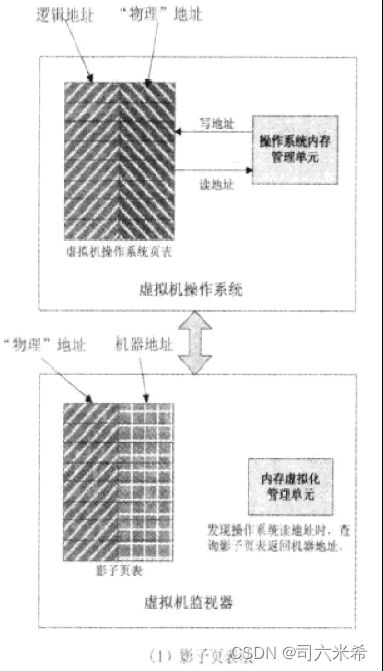
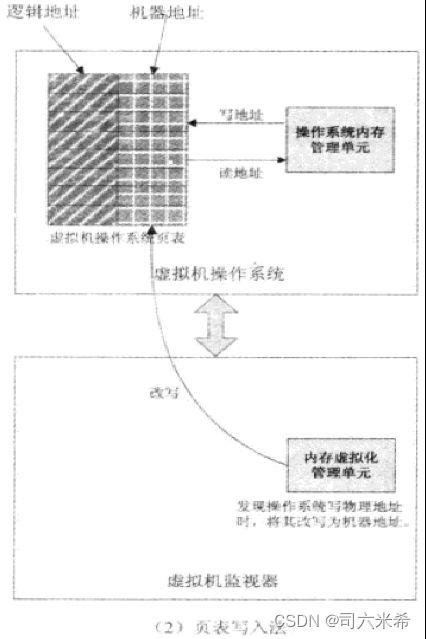
2.页表写入法:客户OS创建一个新页表时,需要向虚拟机监视器注册该页表;虚拟机监视器不允许客户操作系统对页表写权限;虚拟机监视器向该页表写入机器内存地址;客户OS每次对页表的修改都必须陷入虚拟机监视器,由虚拟机监视器来完成更新页表,来保证其页表记录的始终是真实的机器地址。
4.6解释DLL地狱
动态链接库英文为DLL,是Dynamic Link Library的缩写。DLL是一个包含可由多个程序,同时使用的代码和数据的库
DLL地狱,意即同一个DLL的多个版本造成的不兼容。当应用程序需要使用这些DLL时,Windows将它们载入内存;如果替换了DLL,下一次应用程序载入DLL时它可能不是该应用程序所希望的版本。这种不兼容性随着安装更多的新软件而增加。
4.7应用虚拟化
应用虚拟化为应用程序提供一个虚拟的运行环境,在这个虚拟的环境内,不但有应用程序的可执行文件,还包括所需要的运行环境。应用虚拟化把应用对底层系统和硬件的依赖抽象出来,解除应用和操作系统和硬件的耦合关系。程序运行在应用虚拟化环境中,该环境为应用程序屏蔽了底层可能与其他应用产生冲突的内容,如动态链接库。
4.8桌面虚拟化
桌面虚拟化是指将用户的桌面环境与其使用的终端设备解耦,在服务端上以虚拟机的方式存放每个用户的完整的桌面环境。
5.云计算安全
5.1云安全与传统信息安全的异同点
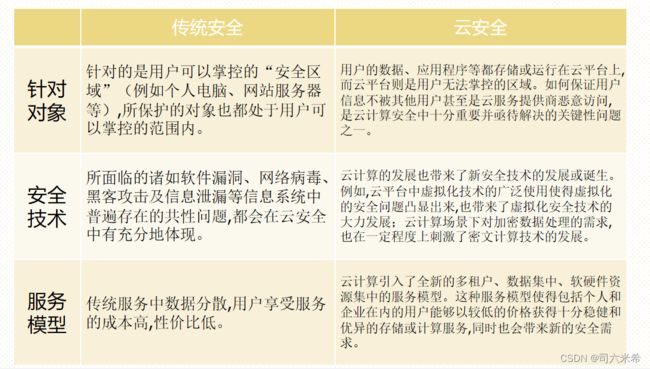
5.2 云安全威胁有哪些?
1.恶意使用
2.数据丢失
3.恶意业内人士
4.账户服务或流量劫持
5.共享技术潜在风险
6.不安全的API
7.系统漏洞
5.3 虚拟机存在的相关安全问题
1.虚拟机自身安全
2.虚拟机镜像安全
3.虚拟网络安全
4.虚拟机监控器安全
5.4 云平台为用户提供的服务安全
1.细粒度访问控制:当用户将自己的数据存储到云端时,云端需要能够阻止非法的用户访问其他用户的资源和数据等,以及细粒度地控制合法用户的访问权限。
2.数据动态完整性:让用户无需将所有数据都下载下来就能够检测自己的数据是否完整,或者说是否丢失或遭到篡改。
3.密文搜索:指用户将数据加密后存储到云端,在搜索时提供加密过的关键字,云根据加密过的关键字和加密的数据进行搜索,得到结果后返回给用户的过程。
6.亚马逊和微软云计算平台
6.1非关系型数据库和关系型数据库优缺点

6.2 EC2的基本架构【亚马逊】
弹性计算云EC2
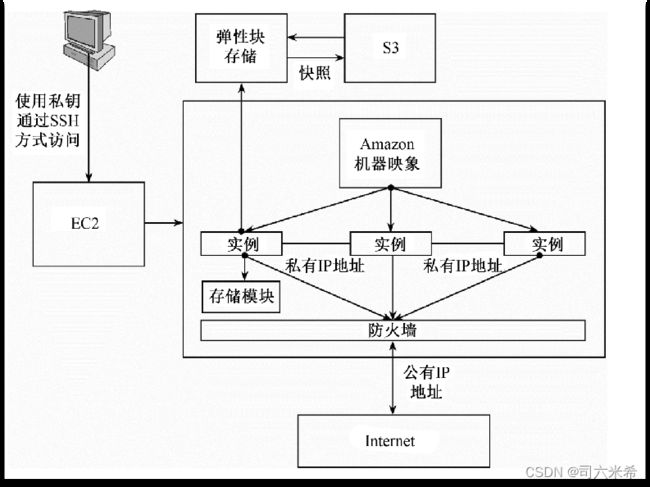
Amazon机器映像(Amazon Machine Image,AMI)是包含了操作系统、服务器程序、应用程序等软件配置的模板
6.3EC2通信时用到三种IP地址
1.公共IP地址
2.私有IP地址
3.弹性IP地址
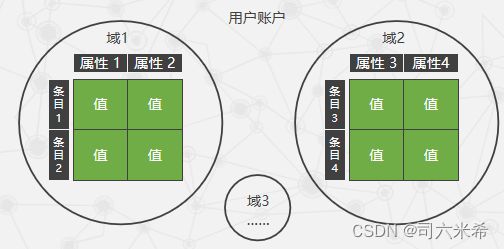
6.4SimpleDB中的域、条目、属性、值
- 域:域是用于存放具有一定关联关系的数据的容器,其中的数据以UTF-8编码的字符串形式存储。
- 条目:条目对应着一条记录,通过一系列属性来描述,即条目是属性的集合。
- 属性:属性是条目的特征,每个属性都用于对条目某方面特性进行概括性描述。
- 值:值用于描述某个条目在某个属性上的具体内容
6.5SimpleDB和DynamoDB的比较

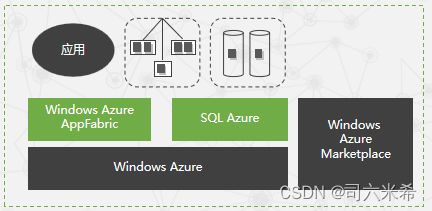
6.6微软云计算服务平台各组成部分【微软】
Windows Azure:作为微软云计算操作系统,提供了一个在微软数据中心服务器上运行应用程序和存储数据的Windows环境
SQL Azure:它是云中的关系数据库,为云中基于SQL Server的关系型数据提供服务
Windows Azure AppFabric:为在云中或本地系统中的应用提供基于云的基础架构服务
Windows Azure Marketplace:为购买云计算环境下的数据和应用提供在线服务
6.7Windows Azure应用程序包括的实例
1.Web Role实例:基于Web Role可以使基于Web的应用创建过程变得简单
2.Worker Role实例:Worker Role设计用来运行各种各样的基于Windows的代码
3.VM Role实例:VM Role运行系统提供的Windows Server 2008 R2镜像。
6.8Windows Azure存储服务支持的数据类型
Table:提供更加结构化的数据存储
Blob:存储二进制数据,可以存储大型的无结构数据,容量巨大,能够满足海量数据存储需求。
Queue:用来支持在Windows Azure应用程序组件之间进行通信

6.9全局命名空间
账户名:DNS主机名的一部分,是客户为访问存储而选择的账户名
分区名:使用账户名定位存储集群后,在集群内将数据访问请求进一步定位到存储节点
对象名:用来对分区中的多个对象进行区分
6.10SQL Azure提供的三种服务
SQL Azure数据库:提供了一个云端的DBMS,这使得本地应用和云应用可以在微软数据中心的服务器上存储数据。
SQL Azure 报表服务:SQL Server Reporting Service(SSRS)的云化版本。主要是用SQL Azure数据库提供报表服务,允许在云数据中创建标准的SSRS报表。
SQL Azure 数据同步:允许同步SQL Azure数据库和本地SQL Server数据库中的数据,也能够在不同的微软数据中心之间同步不同的SQL Azure数据库。
6.11SQL Azure与SQL Server的区别
缺点:
- SQL Azure省略了SQL Server中的一些技术点;
- 用户没有底层管理功能,所有管理功能都由微软实现;
- 用户不能直接关闭自身运行的系统,也不能管理运行应用的硬件设施。
优点:
- SQL Azure运行环境比较稳定;
- 应用获取的服务比较健壮;
- 存储的所有数据均备份了3份。
6.12AppFabric提供的服务
AppFabric为本地应用和云中应用提供了分布式的基础架构服务
AppFabric目前主要提供互联网服务总线(Service Bus)、访问控制(Access Control)服务和高速缓存服务。

- 服务总线:通过云中应用公开的终端使公开应用服务变得简单,这个终端是可以被其他应用访问的。服务总线同样能够处理网络地址转换所带来的挑战,并且可以在没有打开新的公开应用端口的情况下通过防火墙。
- 访问控制:AppFabric访问控制服务简化了支撑身份认证的工作,同时也定义了一定的规则来控制用户的访问。
- 高速缓存:提升应用的访问速率,可以缓存这些经常被访问的信息,从而减少应用查询数据库的次数。
6.13Windows Azure Market提供的两种服务
7.云计算数据中心
7.1数据中心的四个特征
1.高设备利用率:采用虚拟化技术进行系统和数据中心整合,优化资源利用率、简化管理
2.绿色节能:通过先进的供电和散热技术,降低数据中心的能耗
3.高可用性:当网络扩展或升级时,网络能够正常运行,对网络的性能影响不大。
4.自动化管理:云数据中心应是24×7小时无人值守并可远程管理的。
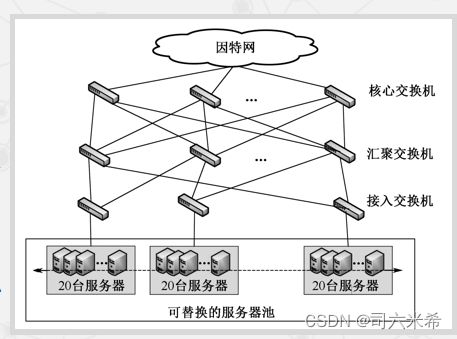
7.2云数据中心网络体系结构
1.改进型树结构
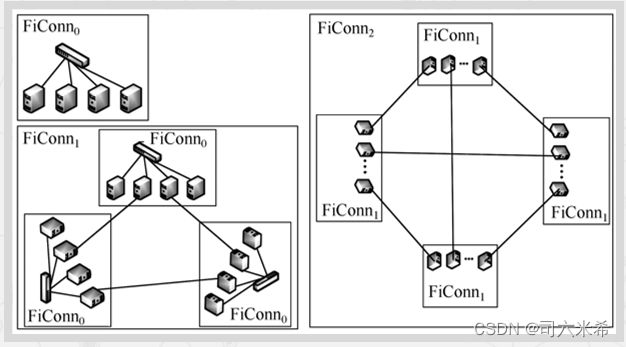
2.递归层次结构
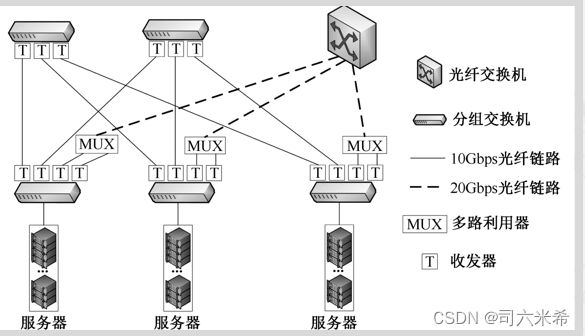
3.光交换网络
4.无线数据中心网络
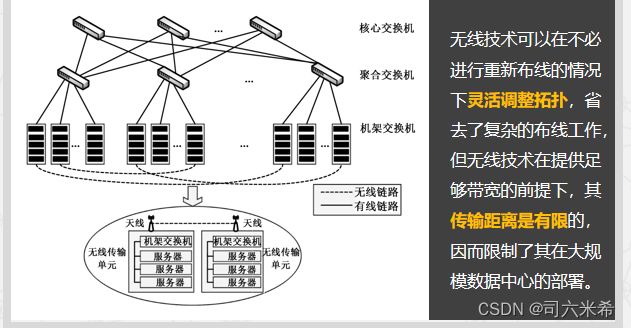
5.软件定义网络

7.3 绿色节能技术
1.配电系统节能技术
2.空调系统节能技术
3.集装箱数据中心节能技术
4.数据中心节能策略和算法
7.4自动化管理的特征
1.全面的可视性
2.自动的控制执行
3.多层次的无缝集成
4.综合与实时的报告
5.全生命周期支持
7.5数据中心容灾备份系统的两个主要技术指标
数据恢复点目标:RPO主要指的是业务系统所能容忍的数据丢失量
恢复时间目标:RTO主要指的是所能容忍的业务停止服务的最长时间
7.6容灾备份的关键技术
