Scrapy框架介绍
文章目录
- Scrapy框架介绍
-
- 1.简介
- 2.架构
- 3.数据流
- 4.项目结构

Scrapy框架介绍
Scrapy 是一个基于 Python 开发的爬虫框架,可以说它是当前Python爬虫生态中最流行的爬虫框架,该框架提供了非常多爬虫相关的基础组件,架构清晰,可扩展性极强。基于Scrapy,我们可以灵活高效地完成各种爬虫需求。
1.简介
在学习,我们大多是基于requests 或 aiohttp 来实现爬虫的整个逻辑的。可以发现,在整个过程中,我们需要实现爬虫相关的所有操作,例如爬取逻辑、异常处理、数据解析、数据存储等,但其实这些步骤很多都是通用或者重复的。既然如此,我们完全可以把这些步骤的逻辑抽离出来,把其中通用的功能做成一个个基础的组件。
抽离出基础组件以后,我们每次写爬虫只需要在这些组件基础上加上特定的逻辑就可以实现爬取的流程了,而不用再把爬虫每个细小的流程都实现一遍。比如说我们想实现这样一个爬取逻辑:遇到服务器返回403 状态码的时候就发起重试,遇到404 状态码的时候就直接跳过。这个逻辑其实很多爬虫都是类似的,那么我们就可以把这个逻辑封装成一个通用的方法或类来直接调用,而不用每次都把这个过程再完整实现一遍,这就大大简化了开发成本,同时在慢慢积累的过程中,这个通用的方法或类也会变得越来越健壮,从而进一步保障了项目的稳定性,框架就是基于这种思想逐渐诞生出来的。
注:Scrapy框架几乎是Python爬虫学习和工作过程中必须掌握的框架,需要好好钻研和掌握。这里给出 Scrapy框架的一些相关资源,包括官网、文档、GitHub地址,建议不熟悉相关知识的读者在阅读之前浏览一下基本介绍。
- 官网:https://scrapy.org/。
- 文档:https://docs.scrapy.org/。
- GitHub:https://github.com/scrapy/scrapy。
2.架构
首先我们先来看一下Scrapy框架的架构,如图所示:
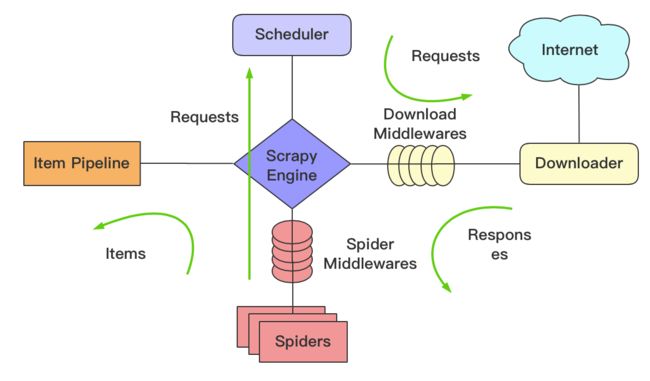
看上去比较复杂,下面我们来介绍一下。
- Engine:图中最中间的部分,中文可以称为引擎,用来处理整个系统的数据流和事件,是整个框架的核心,可以理解为整个框架的中央处理器,负责数据的流转和逻辑的处理。
- Item:它是一个抽象的数据结构,所以图中没有体现出来,它定义了爬取结果的数据结构,爬取的数据会被赋值成Item对象。每个Item就是一个类,类里面定义了爬取结果的数据字段,可以理解为它用来规定爬取数据的存储格式。
- Scheduler:图中上方的部分,中文可以称为调度器,它用来接受Engine发过来的Requests并将其加入队列中,同时也可以将Requests 发回给 Engine供 Downloader 执行,它主要维护Request的调度逻辑,比如先进先出、先进后出、优先级进出等等。
- Spiders:图中下方的部分,中文可以称为蜘蛛,Spiders 是一个复数统称,其可以对应多个Spider,每个 Spider 里面定义了站点的爬取逻辑和页面的解析规则,它主要负责解析响应并生成Item和新的请求然后发给Engine进行处理。
- Downloader:图中右侧部分,中文可以称为下载器,即完成“向服务器发送请求,然后拿到响应”的过程,得到的响应会再发送给Engine 处理。
- Item Pipelines:图中左侧部分,中文可以称为项目管道,这也是一个复数统称,可以对应多个Item Pipeline。Item Pipeline 主要负责处理由 Spider 从页面中抽取的Item,做一些数据清洗、验证和存储等工作,比如将Item的某些字段进行规整,将Item存储到数据库等操作都可以由Item Pipeline来完成。
- Downloader Middlewares:图中 Engine 和 Downloader 之间的方块部分,中文可以称为下载器中间件,同样这也是复数统称,其包含多个 Downloader Middleware, 它是位于 Engine 和Downloader之间的Hook框架,负责实现 Downloader 和Engine 之间的请求和响应的处理过程。
- Spider Middlewares:图中 Engine和 Spiders之间的方块部分,中文可以称为蜘蛛中间件,它是位于Engine 和 Spiders 之间的Hook 框架,负责实现 Spiders和 Engine之间的Item、请求和响应的处理过程。
以上便是Scrapy中所有的核心组件,初看起来可能觉得非常复杂并且难以理解,但上手之后我们会慢慢发现其架构设计之精妙,后面让我们来一点点了解和学习。
3.数据流
上文我们了解了Scrapy的基本组件和功能,通过图和描述我们可以知道,在整个爬虫运行的过程中,Engine负责了整个数据流的分配和处理,数据流主要包括Item、Request、Response这三大部分,那它们又是怎么被Engine控制和流转的呢?
下面我们结合图来对数据流做一个简单说明。
(1)启动爬虫项目时,Engine 根据要爬取的目标站点找到处理该站点的Spider,Spider会生成最初需要爬取的页面对应的一个或多个Request,然后发给 Engine。
(2)Engine 从 Spider 中获取这些 Request,然后把它们交给 Scheduler 等待被调度。
(3)Engine 向 Scheduler 索取下一个要处理的Request,这时候 Scheduler 根据其调度逻辑选择合适的Request发送给Engine。
(4) Engine 将 Scheduler 发来的 Request 转发给 Downloader 进行下载执行,将 Request 发送给Downloader 的过程会经由许多定义好的Downloader Middlewares的处理。
(5)Downloader 将 Request 发送给目标服务器,得到对应的Response,然后将其返回给 Engine。将 Response 返回 Engine 的过程同样会经由许多定义好的Downloader Middlewares的处理。
(6) Engine 从 Downloader 处接收到的Response里包含了爬取的目标站点的肉容,Engine 会将此Response 发送给对应的 Spider 进行处理,将 Response 发送给 Spider的过程中会经由定义好的Spider Middlewares 的处理。
(7) Spider 处理 Response,解析 Response 的内容,这时候 Spider 会产生一个或多个爬取结果Item或者后续要爬取的目标页面对应的一个或多个Request,然后再将这些Item 或Request发送给 Engine进行处理,将Item或 Request发送给 Engine 的过程会经由定义好的 Spider Middlewares的处理。
(8) Engine 将 Spider发回的一个或多个Item转发给定义好的Item Pipelines进行数据处理或存储的一系列操作,将 Spider 发回的一个或多个Request转发给 Scheduler 等待下一次被调度。
重复第(2)步到第(8)步,直到 Scheduler 中没有更多的Request,这时候 Engine 会关闭 Spider,整个爬取过程结束。
从整体上看来,各个组件都只专注于一个功能,组件和组件之间的耦合度非常低,也非常容易扩展。再由Engine 将各个组件组合起来,使得各个组件各司其职,互相配合,共同完成爬取工作。另外加上 Scrapy 对异步处理的支持,Scrapy还可以最大限度地利用网络带宽,提高数据爬取和处理的效率。
4.项目结构
了解了Scrapy的基本架构和数据流过程之后,我们再来大致一看下其项目代码的整体架构是怎样的。
在这之前我们需要先安装 Scrapy 框架,一般情况下,使用pip3直接安装即可:
pip3 install scrapy
但Scrapy 框架往往需要很多依赖库,如果依赖库没有安装好,Scrapy的安装过程是比较容易失败的。
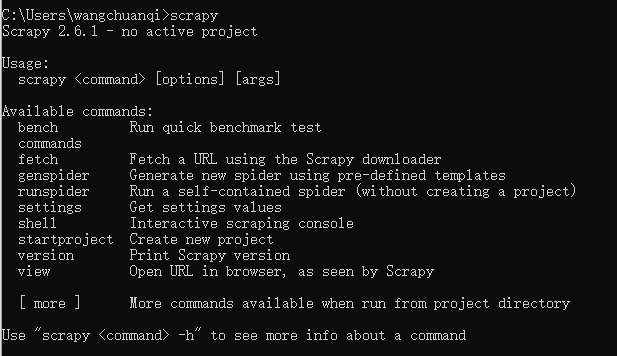
安装成功后,我们就可以使用scrapy命令行了,在命令行输入scrapy可以得到如下结果。
Scrapy 可以通过命令行来创建一个爬虫项目,比如我们要创建一个专门用来爬取新闻的项目,取名为news,那么我们可以执行如下命令:
scrapy startproject news
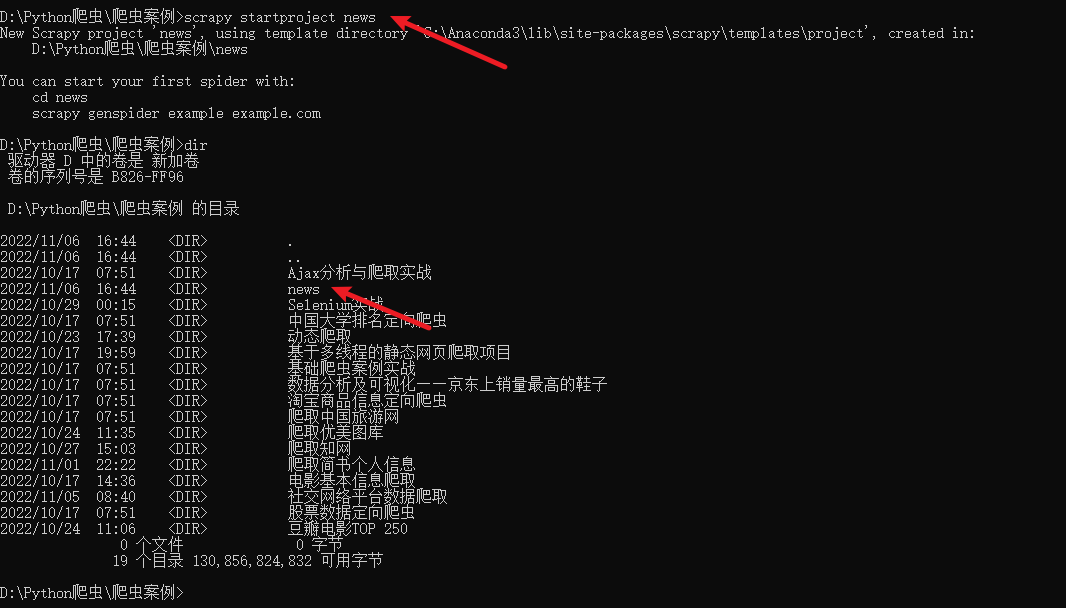
这里我们使用 startproject命令加上项目的名称就创建了一个名为news的Scrapy爬虫项目。执行完毕之后,当前运行目录下便会出现一个名为news的文件夹,该文件夹就对应一个Scrapy爬虫项目。接着进入news文件夹,我们可以再利用命令行创建一个 Spider 用来专门爬取某个站点的新闻,比如新浪新闻,我们可以使用如下命令创建一个Spider:
scrapy genspider sina news.sina.com.cn
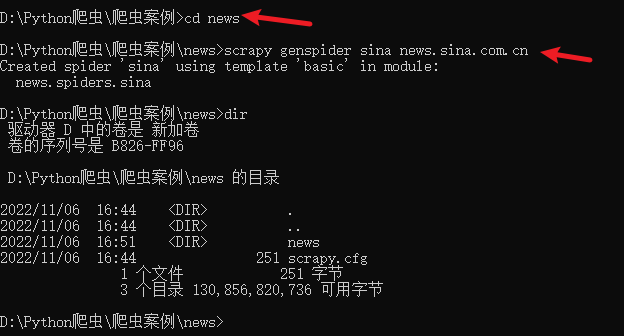
这里我们利用genspider 命令加上Spider 的名称再加上对应的域名,成功创建了一个Spider,这个 Spider会对应一个Python文件,出现在项目的spiders目录下。
我们使用Pycharm打开项目,现在项目文件的结构如下:

在此将各个文件的功能描述如下。
scrapy.cfg:Scrapy 项目的配置文件,其中定义了项目的配置文件路径、部署信息等。items.py:定义了Item 数据结构,所有Item的定义都可以放这里。pipelines.py:定义了 Item Pipeline的实现,所有的Item Pipeline的实现都可以放在这里。settings.py:定义了项目的全局配置。middlewares.py:定义了 Spider Middlewares 和 Downloader Middlewares 的实现。spiders:里面包含一个个 Spider 的实现,每个Spider 都对应一个Python文件。
在此我们仅需要对这些文件的结构和用途做初步的了解,后文会对它们进行深入讲解。