java并发基本概念、线程启动终止
文章目录
-
- 基本概念
-
- 进程和线程
- 进程的通信方式
- CPU核心数与线程数
- 上下文切换
- 并行与并发
- Java线程的启动和终止
-
- 线程的启动
- 线程的中止
基本概念
进程和线程
进程
应用程序其实是由指令和数据组成,而指令需要加载至cpu中执行,数据需要加载至内存,在指令执行过程中还需要用到磁盘、网络等设备。进程就是用来加载指令、管理内存、管理IO的。
进程可以视为一个应用程序的实例,大部分的程序可以同时运行多个实例,比如电脑中的记事本。
线程
程序有非常多个,但是cpu是有限的,也就有了所谓的CPU调度,线程是cpu调度的最小单位。线程必须依赖于进程存在,线程是进程的一个实体,是cpu调度和分配的最小单位
进程的通信方式
同一台计算机中的进程通信叫IPC ((Inter-process communication)),不同计算机中的进程通信叫RPC。
进程间的通信方式有:
- 管道,又分为匿名管道和命名管道,匿名管道可用于父子进程间通信,命名管道除了拥有匿名管道的功能外还允许不是父子进程间的通信
- 信号,用于通知进程有某事件发生,个进程收到一个信号与处理器收到一个中断请求效果上可以说是一致的。
- 消息队列,消息队列是消息的链接表,它克服了上两种通信方式中信号量有限的缺点。具有写权限得进程可以按照一定得规则向消息队列中添加新信息;对消息队列有读权限得进程则可以从消息队列中读取信息。
- 共享内存,最有用的进程间通信方式,多个进程可以访问同一块内存区域,不同进程可以及时看到对方进程中对共享内存中数据的更新。这种方式需要依靠某种同步操作,如互斥锁和信号量等。
- 信号量(semaphore),主要作为进程之间及同一种进程的不同线程之间得同步和互斥手段。
- 套接字(socket):这是一种更为一般得进程间通信机制,它可用于网络中不同机器之间的进程间通信,应用非常广泛。
CPU核心数与线程数
cpu的核心数决定了能够并行运行多少线程,一个CPU核心只能运行一个线程。
但 Intel引入超线程技术后,产生了逻辑处理器的概念,使核心数与线程数形成1:2的关系。
在Java中提供了Runtime.getRuntime().availableProcessors(),可以让我们获取当前的CPU核心数,注意这个核心数指的是逻辑处理器数。
上下文切换
cpu调度中我们知道cpu是频繁切换不同的线程执行的,线程在使用cpu执行时会使用cpu的寄存器与程序计数器的,如果出现了线程切换,那么cpu就会把当前线程在寄存器与程序计数器中的上下文数据拷贝到内存中去,然后再执行另一个的线程,此时会从内存中把另一个线程的上下文在cpu寄存器中进行恢复。
上下文切换通常是计算密集型的,因为涉及一系列数据在各种寄存器、 缓存中的来回拷贝。就CPU时间而言,一次上下文切换大概需要5000~20000个时钟周期,相对一个简单指令几个乃至十几个左右的执行时钟周期。
并行与并发
并行就是同一个时间执行多个任务,并发就是cpu在我们察觉不到的速度去交替执行多个任务。
当谈论并发的时候一定要加个单位时间,也就是说单位时间内并发量是多少?离开了单位时间其实是没有意义的。
两者区别:并发是交替执行,并行是同时执行,
Java线程的启动和终止
Java把操作系统中的线程封装成了Thread类,当我们调用thread.start()方法后才会真正意义上创建一个线程,否则它就是一个普普通通的java对象。
线程的启动
严格意义上来说,java创建线程的方式有两种,继承Thread类或实现Runnable接口
class PrimeThread extends Thread {
public void run() {
// compute primes larger than minPrime
. . .
}
}
PrimeThread p = new PrimeThread();
p.start();
class PrimeRun implements Runnable {
public void run() {
// compute primes larger than minPrime
. . .
}
}
PrimeRun p = new PrimeRun();
new Thread(p).start();
而Callable其实是属于实现Runnable接口这一种,而线程池属于线程预创建与管理。这两种方式并不是严格意义上的创建线程方式。
接下来介绍一下Callable这种方式的实现。
可以发现上面两种创建线程的方式,当线程执行完后都没有返回值,如果想要有返回值那么就可以使用Callable接口,重写call()方法
@FunctionalInterface
public interface Callable<V> {
V call() throws Exception;
}
而Future接口中提供了get()方法来获取线程运行的返回值
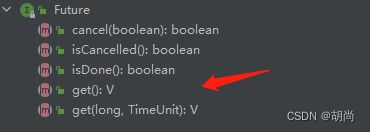
但是Thread并没有任何一个构造函数中能够传Callable类型的对象,只能传Runnable接口类型的对象
所以我们一般是使用RunnableFuture接口的实现类FutureTask类,
// RunnableFuture接口同时实现了Runnable和Future接口
public interface RunnableFuture<V> extends Runnable, Future<V> {
void run();
}
// 而FutureTask又是RunnableFuture接口的实现类
public class FutureTask<V> implements RunnableFuture<V> {
......
}
我们在使用的时候是创建一个FutureTask对象,在构造方法中传一个Callnable接口类型的对象,然后new Thread(futureTask).start();启动一个线程,因为它实现了Runnable接口,所以实际上还是new Thread(Runnable).start();这种方式。
源码中实际上是运行的FutureTask对象的run()方法,在这个方法中会去调用Callnable类型对象中的call()方法并将返回值保存,然后当程序调用FutureTask对象的get()方法获取线程的返回值
线程池部分后续会详细介绍
线程的中止
自然终止
的逻辑代码执行完,线程也就自然终止了
异常终止
当run()方法抛出了一个未处理的异常导致线程提前结束。
stop()与suspend()
这两种方法都是不建议使用的中止线程的方法
stop()方法如果被调用则立刻强制停止该线程的执行,这种方式本身就是不安全的,比如正在往磁盘中写一个文件,强制终止线程运行后那么连文件的结束符都不会写,就造成了文件损坏。
suspend()不会释放任何资源,包括打开的问价、占据的网卡、锁对象,只是这个线程不会再获取到cpu的执行,直到调用resume()方法恢复。
中断
安全的中止则是其他线程通过调用某个线程A的interrupt()方法对其进行中断操作,这个方法只是改变了一个标志位的值,而且线程A也并不是立刻就是中断执行,可能线程A并不理会继续执行,需要线程A自己写业务逻辑代码自己判断自己执行相应的代码。
线程A需要自己调用isInterrupted()方法来进行判断是否被中断,如果返回true则表示中断。也可以调用Thread.interrupted()静态方法,它也是进行判断是否被中断,同时该方法还会同时将中断标识位改写为false。
如果一个线程处于了阻塞状态(如线程调用了thread.sleep、thread.join、thread.wait等),则在线程在检查中断标示时如果发现中断标示为true,则会在这些阻塞方法调用处抛出InterruptedException异常,并且在抛出异常后会立即将线程的中断标示位清除,即重新设置为false。
不建议自定义一个取消标志位来中止线程的运行。因为run方法里有阻塞调用时会无法很快检测到取消标志,线程必须从阻塞调用返回后,才会检查这个取消标志。这种情况下,使用中断会更好,因为,
-
一般的阻塞方法,如sleep等本身就支持中断的检查,
-
检查中断位的状态和检查取消标志位没什么区别,用中断位的状态还可以避免声明取消标志位,减少资源的消耗。
注意:处于死锁状态的线程无法被中断