YARN基础+Yarn组件+Yarn架构和工作流程+Yarn三种调度器+MR流程+zookeeper
目录
一、YARN是什么
二、YARN主要组件说明
1、ResourceManager(RM)
2、NodeManager(NM)
3、ApplicationMaster(AM)
4、Container
三、YARN的架构和工作流程
1、运行流程图如图
2、运行流程解释
3、几个简单问题
(1)AM在哪个进程所在节点运行?
(2)AM要申请Container吗?向谁申请?
(3)第一个Container运行的什么?
四、YARN的调度器
1、 第一种 FIFO Scheduler 队列调度器
2、第二种Capacity Scheduler 容量调度器 (默认使用的)
3、第三种 Fair Scheduler 公平调度器
五、关于MapReduce流程
六、思考题
1、关于进程和线程的区别
2、关于zookeeper
(1)zookeeper的作用
(2) zookeeper角色及作用
(3)zookeeper有几种状态,分别是什么?
(4)zookeeper选举的流程和算法
一、YARN是什么
YARN负责Hadoop中得资源管理(包括cpu、内存、磁盘、网络IO等),以及调度运行在yarn上的任务。
二、YARN主要组件说明
YARN的主要组件:ResourceManager、NodeManager、ApplicationMaster和Container
1、ResourceManager(RM)
主要负责处理客户端请求对各NM上的资源进行统一调度和管理,给ApplicationMaster分配空闲的Container 运行并监控其运行状态。
主要由两个组件构成 调度器(Scheduler) 和应用程序管理器(Applications Manager)
调度器 ---》根据各个应用程序资源需求进行分配(分配的资源封装在Container 中)。
应用程序管理器--》YARN资源控制框架的中心模块,负责集群中所有资源的统一的管理和分配。
2、NodeManager(NM)
相当于ResourceManager在每台机器上的代理。定时向RM汇报本节点资源的使用情况和Container 的运行状态,它还会处理来自ApplicationMaster的Container 启动或停止请求。
3、ApplicationMaster(AM)
YARN中每启动一个任务就会启动一个AM,它可以负责向RM申请资源,请求NM启动Container,并告诉Container做什么,,它还可以重启失败的任务。
4、Container
(1)container是YARN中资源的抽象,它封装了某个节点上的一定的资源(cpu、内存、磁盘、网络等),YARN中所有的应用都是在其上运行的,包括AM
(2)Container是由AM向RM申请的,由RM中的scheduler分配给AM
三、YARN的架构和工作流程
1、运行流程图如图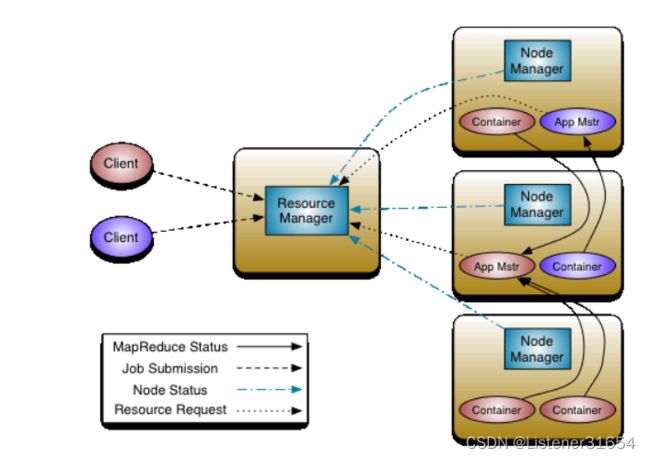

2、运行流程解释
(1)Client向RM提交计算任务,例如wordcount案例
(2)RM收到这个计算任务后,首先会进行权限的检查,再查看一下整个集群的负载情况,判断集群是否有能力承担计算任务
(3)Application Manager找一台NM,在这台主机上启动一个Container,并在Container上启动App Master
(4)AM向RM进行一个注册,使得用户可以直接通过RM来查看程序运行状态
(5)AM计算执行任务所需要资源,并向RM中的Scheduler申请
(6)Scheduler 以Container形式向AM回复资源列表
(7)AM让目标主机分配资源
(8)目标主机启动Container去执行具体的计算任务(可能在不同的Container上有MapTask或者Reduce Task)
(9)在任务执行的同时,执行任务的主机还会向AM汇报任务执行情况
(10)AM收到情况的时候也可以向RM汇报执行情况
(11)在遇到特殊情况时,比如任务失败,AM还可以去重启任务
(12)任务执行成功后,AM收到消息汇报,然后再汇报给RM并申请注销关闭,RM在将结果返回给客户端
总结:简单来说 启动AM并申领资源,然后运行任务直到完成。
3、几个简单问题
(1)AM在哪个进程所在节点运行?
NM
(2)AM要申请Container吗?向谁申请?
要,向RM
(3)第一个Container运行的什么?
AM
四、YARN的调度器
1、 第一种 FIFO Scheduler 队列调度器
先进先出,容易导致大的任务占用集群所有的资源,其它任务被阻塞
2、第二种Capacity Scheduler 容量调度器 (默认使用的)
如下:实现一种动态的分配
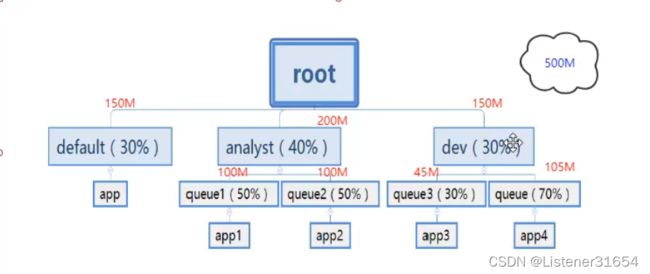
3、第三种 Fair Scheduler 公平调度器
公平分配 ,每个用户平均分配,用户下job也平均分配

五、关于MapReduce流程
map:映射,把一个任务拆解成多个
reduce:聚合,把拆解开的任务做最后的聚合
MR运行中的进程 YarnChild(MapTask ReduceTask)
MRAppMaster MapTask ReduceTask 都是以进程的方式运行的,那么进程申请资源,运行,释放资源,这就是MR慢的一个原因
六、思考题
1、关于进程和线程的区别
(1)进程是执行中的一段程序,而进程中执行的每一个任务即为一个线程。
(2)一个线程 属于一个进程,一个进程可以包含多个线程
(3)线程没有地址空间,它是包含在进程的地址空间里
(4)线程的开销代价比进程小
2、关于zookeeper
(1)zookeeper的作用
它是一个开源的分布式协调服务框架,主要用来解决分布式集群中的应用系统的一致性问题和数据管理问题
(2) zookeeper角色及作用
zookeeper架构如下
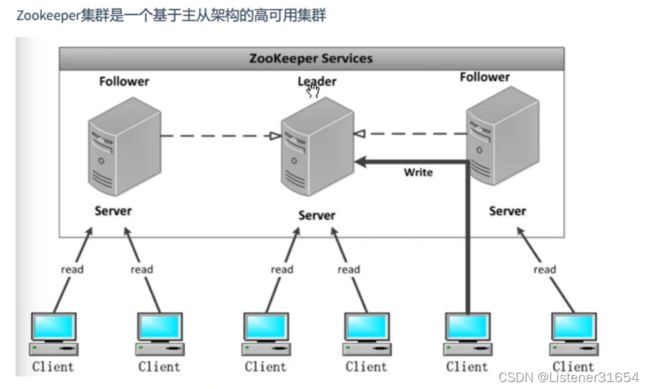
每个服务器承担如下三个角色之一
(1)Leader:一个ZK集只会有一个实际工作的Leader,它会发起并维护与各个Follower及Observe间的心跳。所有的写操作只能Leader完成,并由它广播给其它服务器,也可投票
(2)Follower:一个ZK集群可由多个Follower,它会响应Leader心跳,Follower可处理读请求,对于写请求必须转发给Leader处理,并且负责在Leader处理写请求时,进行投票。
(3)Observe:与Follower类似,但是没有投票权。
注:Follower和Observe统称为Learner
(3)zookeeper有几种状态,分别是什么?
共有四种状态
(1) LOOKING:寻找 Leader 状态。当服务器处于该状态时,它会认为当前服务器没有 Leader,因此需要进入 Leader 选举状态。
(2)FOLLOWING:跟随者状态。表明当前服务器角色是 Follower。
(3)LEADING:领导者状态。表明当前服务器角色是 Leader。
(4)OBSERVING:观察者状态。表明当前服务器角色是 Observer。
(4)zookeeper选举的流程和算法
比如
目前有5台服务器,每台服务器均没有数据,它们的编号分别是1,2,3,4,5,按编号依次启动,它们的选择举过程如下:
- 服务器1启动,给自己投票,然后发投票信息,由于其它机器还没有启动所以它收不到反馈信息,服务器1的状态一直属于Looking(选举状态)。
- 服务器2启动,给自己投票,同时与之前启动的服务器1交换结果,由于服务器2的编号大所以服务器2胜出,但此时投票数没有大于半数,所以两个服务器的状态依然是LOOKING。
- 服务器3启动,给自己投票,同时与之前启动的服务器1,2交换信息,由于服务器3的编号最大所以服务器3胜出,此时投票数正好大于半数,所以服务器3成为领导者,服务器1,2成为小弟。
- 服务器4启动,给自己投票,同时与之前启动的服务器1,2,3交换信息,尽管服务器4的编号大,但之前服务器3已经胜出,所以服务器4只能成为小弟。
- 服务器5启动,后面的逻辑同服务器4成为小弟。