C++实现高并发Web服务器
1.服务器编程基本框架
服务器程序种类繁多,但其基本框架都是一样的,它们的不同之处在于逻辑处理。如图所示是服务器的基本框架。
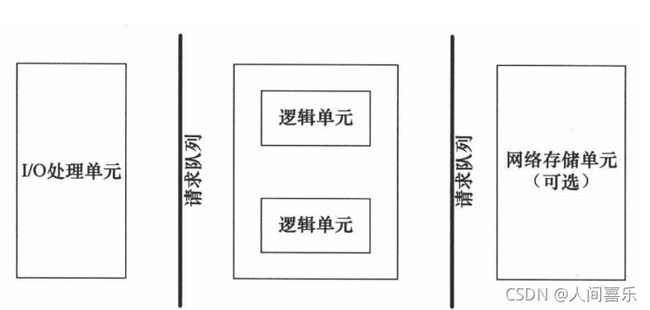
该图既能用来描述一台服务器,也能用来描述一个服务器机群。如下是各个部件的含义和功能。
| 模块 |
单个服务器程序 |
服务器机群 |
| IO处理单元 |
处理客户连接,读写网络数据 |
作为接入服务器,实现负载均衡 |
| 逻辑单元 |
业务进程或线程 |
逻辑服务器 |
| 网络存储单元 |
本地数据库、文件或缓存 |
数据库服务器 |
| 请求队列 |
各单元之间的通信方式 |
各服务器之间的永久TCP连接 |
IO处理单元是服务器管理客户连接的模块。它通常要完成以下工作:等待并接受新的客户链接,接收客户数据,将服务器响应数据返回给客户端。但是,数据的收发不一定再IO处理单元中执行,也可能再逻辑单元中执行,具体在何处执行取决于事件处理模式(Reactor模式/Proactor模式)。对于服务器机群来说,IO处理单元是一个专门的接入服务器。它实现负载均衡,从所有逻辑服务器中选取负荷最小的一台来为新客户服务。
一个逻辑单元通常是一个进程或者线程。它分析并处理客户数据,然后将结果传给IO处理单元或者直接发送给客户端(具体哪种方式取决于事件处理模式)。
网络存储单元可以是数据库、缓存和文件,甚至是一台独立的服务器。但它不是必须的,比如ssh、telnet等登陆服务就不需要这个单元。
请求队列是各单元之间的通信方式的抽象方式的抽象。IO处理单元接收到客户请求时,需要以某种方式通知一个逻辑单元来处理该请求。同样,多个逻辑单元同时访问一个存储单元时,也需要采用某种机制来协调处理竟态条件。请求队列通常被实现为池的一部分。
2.两种高效的事件处理模式
服务器程序通常需要处理三类事件:IO事件、信号及定时事件。
两种高效的事件处理模式:Reactor和Proactor。
随着网络设计模式的兴起,Reactor和Proactor事件处理模式应运而生。同步IO模型通常用于实现Reactor模式,异步IO模式则用于实现Proactor模式。
1.Reactor模式
Reactor是这样一种模式,它要求主线程(IO处理单元)只负责监听文件描述符上是否有事件发生,有的话就立即将该事件通知给工作线程(逻辑单元)。除此之外,主线程不做任何其他性质的工作。读写数据,接受新的连接,以及处理客户请求均在工作线程中完成。
使用同步IO模型(以epoll为例)实现的Reactor模式的工作流程如下:
1.主线程往epoll内核事件表中注册socket上的读就绪事件。
2.主线程调用epoll_wait等待socket有数据可读。
3.当socket上有数据可读时,epoll_wait通知主线程。主线程则将socket的可读事件放入请求队列。
4.睡眠在请求队列上的某个工作线程被唤醒,它从socket读取数据,并处理客户请求,然后往epoll内核事件中注册该socket上的写就绪事件。
5.当主线程调用epol_wait等待socket可写。
6.当socket可写时,epoll_wait通知主线程。主线程将socket可写事件放入请求队列。
7.睡眠在请求队列上的某个工作线程被唤醒,它往socket上写入服务器处理客户请求的结果。
Reactor模式的工作流程:
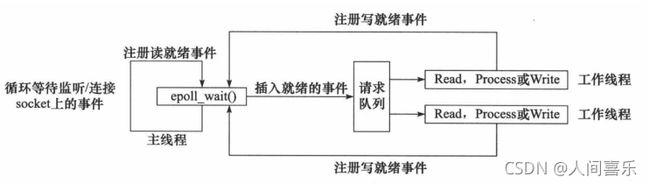
工作线程从请求队列中取出事件后,将根据事件的类型来决定如何处理它:对于可读事件,执行读数据和处理请求的操作;对于可写事件,执行写数据操作。因此,如图示的Reactor模式中,没有必要区分读工作线程和写工作线程。
2.Proactor模式
与Reactor模式不同,Proactor模式将所有的IO操作都交给主线程和内核来处理,工作线程仅仅负责逻辑业务。因此,Proactor模式更符合上面所提到的服务器编程框架。
现在我们使用同步IO来模拟Proactor模式。其原理是:主线程执行读写操作,读写完成之后,主线程向工作线程通知这一完成事件。那么从工作线程的角度来看,它们就直接获得了数据读写的结果,接下来要做的只是对读写结果进行逻辑处理。
使用同步IO模型(epoll_wait为例)模拟Proactor模式的工作流程:
1.主线程往epoll内核事件表中注册socket上的读就绪事件。
2.主线程调用epoll_wait等待socket上有数据可读。
3.当socket上有数据可读时,epoll_wait通知主线程。主线程从socket循环读取数据,直到没有更多数据可读,然后将读取到的数据封装成一个请求对象并插入请求队列。
4.睡眠在请求队列上的某个工作线程被唤醒,它将获得请求对象并处理客户请求,然后往epoll内核事件表中注册socket上的写就绪事件。
5.主线程调用epoll_wait等待socket可写。
6.当socket可写时,epoll_wait通知主线程。主线程往socket上写入服务器处理客户请求的结果。
同步IO模拟Proactor模式的工作流程:

3.线程同步机制包装类
锁机制的功能
实现多线程同步,通过锁机制,确保任一时刻只能有一个线程能进入关键代码段.
#include
#include
#include
//封装信号量的类
class sem
{
public:
//创建并初始化信号量
sem()
{
if (sem_init(&m_sem, 0, 0) != 0)
{
//构造函数没有返回值,可以通过抛出异常来报告错误
throw std::exception();
}
}
//销毁信号量
~sem()
{
sem_destroy(&sm_em);
}
//等待信号量
bool wait()
{
return sem_wait(&m_sem) == 0;
}
//增加信号量
bool post()
{
return sem_post(&m_sem) == 0;
}
private:
sem_t m_sem;
};
//封装互斥锁的类
class locker
{
//创建并初始化互斥锁
public:
locker()
{
if (pthread_mutex_init(&m_mutex, NULL) != 0)
{
throw std::exception();
}
}
//销毁互斥锁
~locker()
{
pthread_mutex_destroy(&m_mutex);
}
//获取互斥锁
bool lock()
{
return pthread_mutex_lock(&m_mutex) == 0;
}
//释放互斥锁
bool unlock()
{
return pthread_mutex_unlock(&m_mutex)==0;
}
private:
pthread_mutex_t m_mutex;
};
//封装条件变量的类
class cond {
public:
//创建并初始化条件变量
cond()
{
if (pthread_mutex_init(&m_mutex, NULL) != 0)
{
throw std::exception();
}
if (pthread_mutex_init(&m_cond, NULL) != 0)
{
//构造函数中一旦出现问题,就应该立即释放已经成功分配了的资源
pthread_mutex_destroy(&m_mutex);
throw std::exception();
}
}
//销毁条件变量
~cond()
{
pthread_mutex_destroy(&m_mutex);
pthread_cond_destroy(&m_cond);
}
//等待条件变量
bool wait()
{
int ret = 0;
pthread_mutex_lock(&m_mutex);
ret = pthread_cond_wait(&m_cond,&m_mutex);
pthread_mutex_unlock(&m_mutex);
return ret == 0;
}
//唤醒等待条件变量的线程
bool signal()
{
return pthread_cond_signal(&m_cond)==0;
}
private:
pthread_mutex_t m_mutex;
pthread_cond_t m_cond;
};
4.线程池
采用动态创建进程或线程的方法来实现并发服务器存在如下缺点:
1.动态创建进程或线程是比较耗费时间的,这将导致较慢的客户响应。
2.动态创建子进程或子线程通常只用来为一个客户服务,这将导致系统上产生大量的细微进程或线程。进程或线程之间的切换将消耗大量的CPU时间。
3.动态创建的子进程是当前进程的完整映像。当前进程必须谨慎地管理其分配的文件描述符和堆内存等系统资源,否则子进程可能复制这些资源,从而使系统的可用资源急剧下降,进而影响服务器的性能。
线程池是由服务器预先创建一组子线程。线程池中所有子线程都运行着相同的代码,并具有相同的属性。因为线程池在服务器启动之处就创建好了,所以每个子线程相对都比较“干净”,即它们没有打开不必要的文件描述符,也不会错误地使用大块的堆内存。
当有新的任务来到时,主线程将通过某种方式选择线程池中的某一个线程来为止服务。相比于动态创建子进程来说,选择一个已经存在的线程的代价显然要小得多。
主线程使用某种算法来主动选择子线程。最简单、最常用的算法是随机算法和Round Robin(轮流选取)算法。
主线程和所有子线程通过一个共享的工作队列来同步,子进程都睡眠在该工作队列上。当有新的任务到来时,主线程将任务添加到工作队列中去。这将唤醒正在等待任务的子线程,不过只有一个子线程将获得新任务的接管权,它可以从工作队列中取出任务并执行,而其他子进程将继续睡眠在工作队列上。
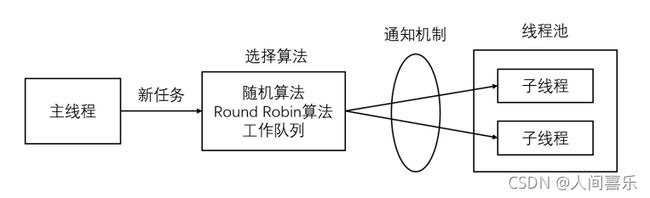
1.空间换时间,浪费服务器的硬件资源,换取运行效率。
2.池是一组资源的集合,这组资源在服务器启动之初就被完全创建好并且初始化,这称为静态资源。
3.当服务器进入正式运行阶段,开始处理客户请求的时候,如果它需要相关的资源,可以直接从池中获取,无需动态分配。
4.当服务器处理完一个客户连接后,可以把相关的资源放回池中,无需执行系统调用释放资源。
半同步/半反应堆线程池实现:该线程池通用性要高得多,因为它使用一个工作队列完全解除了主线程和工作线程的耦合关系:主线程往工作队列中插入任务,工作线程通过竞争来取得任务并执行它。
#include
#include
#include
#include
#include
#include
#include
#include
#include "locker.h"//互斥锁类
/*线程池类,将它定义为模板类是为了代码复用,模板参数T是人物类*/
template
class threadpool
{
public:
/*参数thread_number是线程池中线程的数量,max_requests是请求队列中最多允许的、等待处理的请求的数量*/
threadpool(int thread_number = 0, int max_requests = 10000);
~threadpool();
//往请求队列中添加任务
bool append(T* request);
private:
//工作线程运行的函数,它不断从工作队列中取出任务并执行
static void* worker(void* arg);
void run();
private:
int m_thread_number;//线程池中的线程数
int m_max_requests;//请求队列中允许的最大请求数
pthread_t* m_threads;//描述线程池的数组,其大小为m_thread_number
std::listm_workqueue;//请求队列
locker m_queuelocker;//保护请求队列的互斥锁
sem m_queuestat;//是否有任务需要处理
bool m_stop;//是否结束线程
};
template
threadpool< T >::threadpool(int thread_number, int max_requests) :
m_thread_number(thread_number), m_max_requests(max_requests),
m_stop(false), m_threads(NULL)
{
//参数错误,掷出错误
if ((thread_number <= 0) || (max_requests <= 0))
{
throw std::exception();
}
m_threads = new pthread_t[m_thread_number];
if (!m_threads)
{
throw std::exception();
}
//创建thread_number个线程,并将它们都设置为脱离线程
for (int i = 0; i < thread_number; ++i)
{
printf("create the %dth thread\n",i);
if (pthread_create(m_thread + i, NULL, worker, this) != 0)
{
delete[]m_threads;
throw std::exception();
}
}
}
template
threadpool::~threadpool()
{
delete[] m_threads;
m_stop = true;
}
template
bool threadpool::append(T* request)
{
//操作工作队列时一定要加锁,因为它被所有线程共享
m_queuelocker.lock();
if (m_workqueue.size() > m_max_requests)
{
m_queuelocker.unlock();
return false;
}
m_workqueue.push_back(request);
m_queuelocker.unlocker();
//添加一个任务,信号量加一
m_queuestat.post();
return true;
}
template
void* threadpool::worker(void* arg)
{
threadpool* pool = (threadpool*)arg;
pool->run();
return pool;
}
template
void threadpool::run()
{
while (!m_stop)
{
//需要执行任务,信号量减一
m_queuestat.wait();
m_queuelocker.lock();
if (m_workqueue.empty())
{
m_queuelocker.unlocker();
continue;
}
T* request = m_workqueue.front();
m_workqueue.pop_front();
m_queuelocker.unlocker();
if (!request)
{
continue;
}
request->process();//执行具体业务的函数
}
}
3.有限状态机
逻辑单元内部的一种高效编程方法:有限状态机。
有的应用层协议头部包含数据包类型字段,每种类型可以映射为逻辑单元的一种执行状态,服务器可以根据它来编写相应的处理逻辑。
//状态独立的有限状态机
STATE_MACHINE(Package _pack)
{
PackageType _type = _pack.GetType();
switch (_type)
{
case type_A:
process_package_A(_pack);
break;
case type_B:
process_package_B(_pack);
break;
}
}这就是一个简单的有限状态机,只不过该状态机的每个状态都是相互独立的,即状态之间没有相互转移。状态之间的转移是需要状态机内部驱动的。
//带状态转移的有限状态机
STATE_MACHINE(Package _pack)
{
State cur_State=type_A;
While( cur_State!=type_c)
{
switch (cur_State)
{
case type_A:
process_package_A(_pack);
cur_State=type_B;
break;
case type_B:
process_package_B(_pack);
cur_State=type_C;
break;
}
}
}
HTTP请求的读取和分析。很多网络协议,包括TCP协议和IP协议,都在其头部中提供头部长度字段。程序根据该字段的值就可以知道是否接收到一个完整的协议头部。但HTTP协议并未提供这样的头部长度字段,并且其头部长度变化也很大,可以只有十几字节,也可以有上百字节。根据协议规定,我们判断HTTP头部结束的依据是遇到一个空行,该空行仅包括一对回车换行符(
/*
解析客户端请求时,主状态机的状态:
主状态机的三种可能状态,分别表示:
当前正在分析请求行:CHECK_STATE_REQUESTLINE
当前正在分析头部字段:CHECK_STATE_HEADER
当前正在解析请求体:CHECK_STATE_CONTENT
*/
enum CHECK_STATE
{
CHECK_STATE_REQUESTLINE = 0,
CHECK_STATE_HEADER,
CHECK_STATE_CONTENT
};
/*
从状态机的三种可能状态,即行的读取状态,分别表示:
读取到一个完整的行:LINE_OK
行出错:LINE_BAD
行数据尚且不完整:LINE_OPEN
*/
enum LINE_STATUS {
LINE_OK = 0,
LINE_BAD,
LINE_OPEN
};
/*
服务器处理HTTP请求的可能结果,报文解析的结果:
表示请求不完整,需要继续读取客户数据:NO_REQUEST
表示获得了一个完整的客户请求:GET_REQUEST
表示客户请求有语法错误:BAD_REQUEST
表示客户对资源没有足够的访问权限:FORBINNEN_REQUEST
表示服务器内部错误:INTERNAL_ERROR
表示客户端已经关闭连接了:CLOSED_CONNECTION
*/
enum HTTP_CODE {
NO_REQUEST=0,
GET_REQUEST,
BAD_REQUEST,
FORBINNEN_REQUEST,
INTERNAL_ERROR,
CLOSED_CONNECTION
};
4.HTTP请求报文格式

GET / HTTP/1.1
Host: www.baidu.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:86.0) Gecko/20100101 Firefox/86.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,/;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate, br
Connection: keep-alive
Cookie: BAIDUID=6729CB682DADC2CF738F533E35162D98:FG=1;
BIDUPSID=6729CB682DADC2CFE015A8099199557E; PSTM=1614320692; BD_UPN=13314752;
BDORZ=FFFB88E999055A3F8A630C64834BD6D0;
__yjs_duid=1_d05d52b14af4a339210722080a668ec21614320694782; BD_HOME=1;
H_PS_PSSID=33514_33257_33273_31660_33570_26350;
BA_HECTOR=8h2001alag0lag85nk1g3hcm60q
Upgrade-Insecure-Requests: 1
Cache-Control: max-age=0
HTTP请求由 请求行(request line)、请求头(header)、空行和请求数据四个部分组成。
请求行:用来说明请求类型,要访问的资源以及所使用的HTTP版本。
请求方法:
GET:向指定资源发出“显示”请求。使用GET方法应该只用在读取数据,而不应该被用于产生“副作用”的操作中。
POST:向指定资源提交数据,请求服务器处理(例如提交表单或者上传文件)。数据被包含在请求文本中。这个请求可能会创建新的资源或者修改现有资源,或两者皆有。
请求头部:紧接着请求行(第一行)之后的部分,用来说明服务器要使用的附加信息。
HOST:给出请求资源所在服务器的域名。
User-Agent:HTTP客户端程序的信息,该信息由你发出请求使用的浏览器来定义,并且在每个请求中自动发送等。
Accept:说明用户代理可处理的媒体类型。
Accept-Encoding:说明用户代理支持的内容编码。
Accept-Language:说明用户代理能够处理的自然语言集。
Content-Type:说明实现主体的媒体类型。
Content-Length:说明实现主体的大小。
Connection:连接管理,可以是Keep-Alive或close。
空行:请求头部后面的空行是必须的,即使第四部分的请求数据为空 ,也必须有空行。
请求数据:也叫主体,可以添加任意的其他数据。
HTTP状态码
所有HTTP响应的第一行都是状态行,依次是当前HTTP版本号,3位数字组成的状态代码,以及描述状态 的短语,彼此由空格分隔。 状态代码的第一个数字代表当前响应的类型:
1XX : 信息类状态码(表示接收请求状态处理)
2XX : 成功状态码(表示请求正常处理完毕)
3XX : 重定向(表示需要进行附加操作,已完成请求)
4XX : 客户端错误(表示服务器无法处理请求)
5XX : 服务器错误状态码(表示服务器处理请求的时候出错
5.HTTP类
浏览器端发出http连接请求,主线程创建http对象接收请求并将所有数据读入对应的buffer,将该对象插入任务队列,工作线程从任务队列中取出一个任务进行处理。
工作线程取出任务后,调用process_read函数,通过主、从状态机对请求报文进行解析。
解析完成之后,跳转do_request函数生成响应报文,通过process_write写入buffer,返回给浏览器。
class http_conn
{
public:
//文件名的最大长度
static const int FILENAME_LEN = 200;
//读缓冲区的大小
static const int READ_BUFFER_SIZE = 2048;
//写缓冲区的大小
static const int WRITE_BUFFER_SIZE = 1024;
//HTTP请求方法,我们仅支持GET
enum METHOD {
GET = 0,
POST,
HEAD,
PUT,
DELETE,
TRACE,
OPTIONS,
CONNECT,
PATCH
};
//解析客户请求时,主状态机所处的状态
enum CHECK_STATE {
CHECK_STATE_REQUESTLINE=0,
CHECK_STATE_HEADER,
CHECK_STATE_CONNTENT,
};
//服务器处理HTTP请求的可能结果
enum HTTP_CODE {
NO_REQUEST,
GET_REQUEST,
BAD_REQUEST,
NO_RESQUACE,
FORBIDDEN_REQUEST,
FILE_REQUEST,
INTERNAL_ERROR,
CLOSED_CONNECTION, };
//行的读取状态
enum LINE_STATUS {
LINE_OK=0,
LINE_BAD,
LINE_OPEN
};
public:
http_conn() {};
~http_conn() {};
public:
//初始化新接受的连接
void init(int sockfd, const sockaddr_in&addr);
//关闭连接
void close_conn(bool real_close=true);
//处理客户请求
void process();
//非阻塞读操作
bool read();
//非阻塞写操作
bool write();
private:
//初始化连接
void init();
//解析HTTP请求
HTTP_CODE process_read();
//填充HTTP应答
bool process_write(HTTP_CODE ret);
//下面这组函数被process_read调用以分析HTTP请求
HTTP_CODE parse_request_line(char* text);
HTTP_CODE parse_headers(char* text);
HTTP_CODE parse_content(char* text);
HTTP_CODE do_request();
char* get_line()
{
return m_read_buf + m_start_line;
}
LINE_STATUS parse_line();
//下面这一组函数被process_write调用以填充HTTP应答
void unmap();
bool add_response(const char* format, ...);
bool add_content(const char* content);
bool add_status_line(int status, const char* title);
bool add_headers(int content_length);
bool add_content_length(int content_length);
bool add_linger();
bool add_blank_line();
public:
//所有socket上的事件都被注册到同一个epoll内核时间表中,所以将epoll文件描述符设置为静态的
static int m_epollfd;
//统计用户数量
static int m_user_count;
private:
//该HTTP连接的socket和对方的socket地址
int m_sockfd;
sockaddr_in m_address;
//读缓冲区
char m_read_buf[READ_BUFFER_SIZE];
//标识读缓冲区中已经读入的客户数据的最后一个字节的下一个位置
int m_read_idx;
//当前正在分析的字符再读缓冲区中的位置
int m_check_idx;
//当前正在解析的行的起始位置
int m_start_line;
//写缓冲区
char m_write_buf[WRITE_BUFFER_SIZE];
//写缓冲区中待发送的字节数
int m_write_idx;
//主状态机当前所处的状态
CHECK_STATE m_check_state;
//请求方法
METHOD m_method;
//客户请求的目标文件的完整路径,其内容等于doc_root+m_url,doc_root是网站根目录
char m_real_file[FILENAME_LEN];
//客户请求的目标文件的文件名
char* m_url;
//HTTP协议版本号,我们仅支持HTTP/1.1
char* m_version;
//主机名
char* m_host;
//HTTP请求的消息体长度
int m_content_length;
//HTTP请求是否要求保持连接
bool m_linger;
//客户请求的目标文件被mmap到内存中的起始位置
char* m_file_address;
//目标文件的状态。通过它我们可以判断文件是否存在、是否为目录、是否可读、并获取文件大小等信息
struct stat m_file_stat;
//我们将采用writev来执行写操作,所以定义下面两个成员,其中m_iv_count表示被写内存块的数量。
struct iovec m_iv[2];
int m_iv_count;
};6.EPOLL函数
IO多路复用函数有select、poll和epoll。这里我们主要使用多路IO复用的epoll函数来实现服务器的并发处理。
#include
epoll_create函数
int epoll_create(int size)
// 创建一个新的epoll实例。在内核中创建了一个数据,这个数据中有两个比较重要的数据,一个是需要检 测的文件描述符的信息(红黑树),还有一个是就绪列表,存放检测到数据发送改变的文件描述符信息(双向 链表)。
int epoll_create(int size);
- 参数:
size : 目前没有意义了。随便写一个数,必须大于0
- 返回值:
-1 : 失败
> 0 : 文件描述符,操作epoll实例的
epoll_ctl函数
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event)
// 对epoll实例进行管理:添加文件描述符信息,删除信息,修改信息
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
- 参数:
- epfd : epoll实例对应的文件描述符
- op : 要进行什么操作
EPOLL_CTL_ADD: 添加
EPOLL_CTL_MOD: 修改
EPOLL_CTL_DEL: 删除
- fd : 要检测的文件描述符
- event : 检测文件描述符什么事情
上述event是epoll_event结构体指针类型,表示内核所监听的事件,具体定义如下:struct epoll_event {
__uint32_t events; /* Epoll events */
epoll_data_t data; /* User data variable */
}
epoll_data_t是一个联合类型,定义如下:
typefd union epoll_data
{
void *ptr;
int fd;
uint32_t u32;
uint64_t u64;
}epoll_data_t;
event描述事件:
EPOLLIN:表示对应的文件描述符可以读(包括对端SOCKET正常关闭);
EPOLLOUT:表示对应的文件描述符可以写;
EPOLLPRI:表示对应的文件描述符有紧急的数据可读(这里应该表示有带外数据到来);
EPOLLERR:表示对应的文件描述符发生错误;
EPOLLHUP:表示对应的文件描述符被挂断;
EPOLLET: 将EPOLL设为边缘触发(Edge Triggered)模式,这是相对于水平触发(Level Triggered)来说的。
EPOLLONESHOT:只监听一次事件,当监听完这次事件之后,如果还需要继续监听这个socket的话,需要再次把这个socket加入到EPOLL队列里EPOLLRDHUP:对端描述符产生一个挂断事件
epoll_wait函数
// 检测函数
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
- 参数: - epfd : epoll实例对应的文件描述符
- events : 传出参数,保存了发送了变化的文件描述符的信息
- maxevents : 第二个参数结构体数组的大小
- timeout : 阻塞时间 - 0 : 不阻塞 - -1 : 阻塞,直到检测到fd数据发生变化,解除阻塞 - > 0 : 阻塞的时长(毫秒)
- 返回值:
- 成功,返回发送变化的文件描述符的个数 > 0
- 失败 -1
设置非阻塞模式:
//对文件描述符设置非阻塞
int setnonblocking(int fd)
{
int old_option = fcntl(fd, F_GETFL);
int new_option = old_option | O_NONBLOCK;
fcntl(fd, F_SETFL, new_option);
return old_option;
}条件触发(LT)和边沿触发(ET):
ET:当epoll_wait检测到fd上有事件发生并将此事件通知给应用程序后,应用程序必须立即处理该事件,因为后续的epoll_wait调用将不再向应用程序通知这一事件。
LT:与ET相反,会不断通知,直到处理此事件。
EPOLLONESHOT事件:
一个线程读取某个socket上的数据后开始处理数据,在处理过程中该socket上又有新数据可读,此时另一个线程被唤醒读取,此时出现两个线程处理同一个socket。
我们期望的是一个socket连接在任一时刻都只被一个线程处理,通过epoll_ctl对该文件描述符注册epolloneshot事件,一个线程处理socket时,其他线程将无法处理,当该线程处理完后,需要通过epoll_ctl重置epolloneshot事件。
6.实现HTTP类
在实现HTTP类的过程中,我们还需要调用一些函数和结构体去完成这个工作。
stat函数
stat函数用于取得指定文件的文件属性,并将文件属性存储在结构体stat里,这里仅对其中用到的成员进行介绍。
#include
//获取文件属性,存储在statbuf中
int stat(const char *pathname, struct stat *statbuf);
struct stat
{
mode_t st_mode; /* 文件类型和权限 */
off_t st_size; /* 文件大小,字节数*/
}
writev函数
writev函数用于在一次函数调用中写多个非连续缓冲区,有时也将这该函数称为聚集写。
#include
ssize_t writev(int filedes, const struct iovec *iov, int iovcnt);
filedes表示文件描述符
iov为前述io向量机制结构体iovec
iovcnt为结构体的个数
这个函数一般需要和下面的结构一起使用。
iovec
定义了一个向量元素,通常,这个结构用作一个多元素的数组。
struct iovec {
void *iov_base; /* starting address of buffer */
size_t iov_len; /* size of buffer */
};
iov_base指向数据的地址
iov_len表示数据的长度
这个结构体通常用来当作缓冲区用来写入、读出数据。
va_list函数
VA_LIST 是在C语言中解决变参问题的一组宏,变参问题是指参数的个数不定,可以是传入一个参数也可以是多个;可变参数中的每个参数的类型可以不同,也可以相同;可变参数的每个参数并没有实际的名称与之相对应,用起来是很灵活。
VA_LIST的用法:
(1)首先在函数里定义一具VA_LIST型的变量,这个变量是指向参数的指针;
(2)然后用VA_START宏初始化变量刚定义的VA_LIST变量;
(3)然后用VA_ARG返回可变的参数,VA_ARG的第二个参数是你要返回的参数的类型(如果函数有多个可变参数的,依次调用VA_ARG获取各个参数);
(4)最后用VA_END宏结束可变参数的获取。
vsnprintf函数
vsnprintf用来将可变参数格式化输出到一个字符数组,常和va_start和va_end一起使用。
函数功能:将可变参数格式化输出到一个字符数组。
头文件:#include
函数声明:int vsnprintf(char *str, size_t size, const char *format, va_list ap);
参数:
str
保存输出字符数组的存储区。
size
存储区的大小。
format
包含格式字符串的C字符串,其格式字符串与printf中的格式相同
arg
变量参数列表,用va_list 定义。
#include"http_conn.h"
//定义HTTP响应的一些状态信息
const char* ok_200_title = "OK";
const char* error_400_title = "Bad Request";
const char* error_400_form = "Your request has bad syntax or is inherently impossible to satisfy.\n"
const char* error_403_title = "Forbidden";
const char* error_403_form = "Your request have permission to get file from this server.\n";
const char* error_404_title = "Not Found";
const char* error_404_form = "The request file was not found on this server.\n";
const char* error_500_title = "Internal Error";
const char* error_500_form = "There was unusual problem serving the request file.\n";
//网站的根目录
const char* doc_root = "/var/www/html";
//将文件描述符设置为非阻塞
int setnonblocking(int fd)
{
int old_option = fcntl(fd, F_GETFL);
int new_option = old_option | O_NONBLOCK;
fcntl(fd, F_SETFL, new_option);
return old_option;
}
// 向epoll中添加需要监听的文件描述符,并判断是否触发EPOLL的EPOLLONESHOT事件
void addfd(int epollfd, int fd, bool one_shot)
{
epoll_event event;
event.data.fd = fd;
event.event = EPOLLIN | EPOLLET | EPOLLRDHUP;
if (one_shot)
{
event.events |= EPOLLONESHOT;
}
epoll_ctl(epollfd, EPOLL_CTL_ADD, fd, &event);
setnonblocking(fd);
}
// 从epoll中移除监听的文件描述符
void removefd(int epollfd, int fd)
{
epoll_ctl(epollfd, EPOLL_CTL_DEL, fd, 0);
close(fd);
}
// 修改文件描述符,重置socket上的EPOLLONESHOT事件,以确保下一次可读时,EPOLLIN事件能被触发
void modfd(int epollfd, int fd, int ev)
{
epoll_event event;
event.data.fd = fd;
event.events = ev | EPOLLET | EPOLLONESHOT | EPOLLRDHUP;
epoll(epollfd, EPOLL_CTL_MOD, fd, &event);
}
// 所有的客户数
int http_conn::m_user_count = 0;
// 所有socket上的事件都被注册到同一个epoll内核事件中,所以设置成静态的
int http_conn::m_epollfd = -1;
// 关闭连接
void http_conn::close_conn(bool real_close)
{
if (real_close && (m_sockfd != -1))
{
removefd(m_epollfd, m_sockfd);
m_sockfd = -1;
m_user_count--;//关闭一个连接时,将客户数量-1
}
}
void http_conn::init(int sockfd, const sockaddr_in &addr)
{
m_sockfd = sockfd;
m_address = addr;
//如下两行是为了避免TIME_WAIT状态,仅用于调试,实际使用时应该去掉
int reuse = 1;
setsockopt(m_sockfd, SOL_SOCKET, SO_REUSEADDR, &reuse, sizeof(reuse));
m_user_count++;
init();
}
void http_conn::init()
{
//主状态机当前正在分析请求行
m_check = CHECK_STATE_REQUEST;
//HTTP请求是否要求保持连接,默认不保持链接
m_linger = false;
// HTTP请求方式,默认请求方式为GET
m_method = GET;
//客户请求的目标文件的文件名,默认为0
m_url = 0;
//HTTP协议版本号,默认为0
m_version = 0;
//HTTP请求的消息体长度,默认为0
m_content_length = 0;
//主机名,默认为0
m_host = 0;
//当前正在解析的行的起始位置,默认为0
m_start_line = 0;
//当前正在分析的字符在读缓冲区的位置,默认为0
m_check_idx = 0;
//标识读缓冲区中已经读入的客户数据的最后一个字节的下一个位置,默认为0
m_read_idx = 0;
//写缓冲区中待发送的字节数,默认为0
m_write_idx = 0;
//初始化读缓冲区,写缓冲区,目标文件的完整路径
memset(m_read_buf, '\0', READ_BUFFER_SIZE);
memset(m_write_buf, '\0', WRITE_BUFFER_SIZE);
memset(m_real_file, '\0', FILENAME_LEN);
}
//从状态机,解析一行,判断依据\r\n
http_conn::LINE_STATUS http_conn::parse_line()
{
char temp;
/*
当前正在分析的字符在读缓冲区的位置,默认为0
m_check_idx = 0;
标识读缓冲区中已经读入的客户数据的最后一个字节的下一个位置,默认为0
m_read_idx = 0
*/
for (; m_check_idx < m_read_idx; ++m_checked_idx)
{
temp = m_read_buf[m_check_idx];
if (temp == '\r')
{
//下一个字符达到了buffer结尾,则接收不完整,需要继续接收
if ((m_check_idx + 1) == m_read_idx)
{
return LINE_OPEN;//行数据不完整,因为m_read_idx表示客户数据的最后一个字节的下一个位置
}
//下一个字符是\n,将\r\n改为\0\0
else if (m_read_buf[m_check_idx + 1] == '\n')
{
m_read_buf[m_checked_idx++] = '\0';
m_read_buf[m_checked_idx++] = '\0';
return LINE_OK;//读取到一个完整的行,并将这一行的\r\n变为\0,即结束符,结束这一行
}
return LINE_BAD;//都不符合,行出错
}
//如果当前字符是\n,也有可能读取到完整行
//一般是上次读取到\r就到buffer末尾了,没有接收完整,再次接收时会出现这种情况
else if (temp = '\n')
{
if ((m_checked_idx + 1) && (m_read_buf[m_checked_idx - 1] == '\r'))
{
m_read_buf[m_checked_idx - 1] = '\0';
m_read_buf[m_check_idx++] = '\0';
}
return LINE_BAD;
}
}
//并没有找到\r\n,需要继续接收
return LINE_OPEN;//数据不完整
}
//循环读取客户数据,直到无数据可读或者对方关闭连接
bool http_conn::read()
{
if (m_read_idx >= READ_BUFFER_SIZE)
{
return false;
}
int bytes_read = 0;
while (true)
{
//循环读取发送过来的数据,将已经读取的数据放入读缓冲区,读缓冲区的大小一步步减小
bytes_read = recv(m_sockfd, m_read_buf + m_read_idx, READ_BUFFER_SIZE - m_read_idx, 0);
if (bytes_read = -1)
{
if (errno == EAGAIN || errno == EWOULDBLOCK)
{
break;
}
return false;
}
else if (bytes_read == 0)
{
return false;
}
m_read_idx += bytes_read;
}
return true;
}
//解析HTTP请求行,获得请求方法、目标URL,以及HTTP版本号
http_conn::HTTP_CODE http_conn::parse_request_line(char* text)
{ //例如GET /index.html HTTP/1.1
//请求行中最先含有空格和\t任一字符的位置并返回
m_url = strpbrk(text, "\t");
if (!m_url)
{
return BAD_REQUEST;
}
//例如GET\0/index.html HTTP/1.1
*m_url++ = '\0';
char* method = text;
if (strcasecmp(method, "GET") == 0)
{
m_method = GET;
}
else
{
return BAD_REQUEST;
}
//m_url此时跳过了第一个空格或\t字符,但不知道之后是否还有
//将m_url向后偏移,通过查找,继续跳过空格和\t字符,指向请求资源的第一个字符
m_url += strspn(m_url, "\t");
//使用与判断请求方式的相同逻辑,判断HTTP版本号
// /index.html HTTP/1.1
m_version = strpbrk(m_url, "\t");
if (!m_version)
{
return BAD_REQUEST;
}
*m_version++ = '\0';
m_version += strspn(m_version, "\t");
if (strcasecmp(m_version, "HTTP/1.1") != 0)
{
return BAD_REQUEST;
}
// 目前m_url为/index.html\0HTTP/1.1
if (strncasecmp(m_url, "http://", 7) == 0)
{
//http://192.168.110.129:10000/index.html这种情况下
m_url += 7;
m_url = strchr(m_url, '/');//找/第一次出现的位置,现在m_url为/index.html
}
if (!m_url || m_url[0] != '/')
{
return BAD_REQUEST;
}
//请求行处理完毕,将主状态机转移处理请求头
m_check_state = CHECK_STATE_HEADER;
return NO_REQUEST;//请求不完整,需要继续读取客户数据
}
/*
GET / HTTP/1.1
Host: www.baidu.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:86.0) Gecko/20100101 Firefox/86.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,/;q=0.8
Accept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2
Accept-Encoding: gzip, deflate, br
Connection: keep-alive
Cookie: BAIDUID=6729CB682DADC2CF738F533E35162D98:FG=1;
BIDUPSID=6729CB682DADC2CFE015A8099199557E; PSTM=1614320692; BD_UPN=13314752;
BDORZ=FFFB88E999055A3F8A630C64834BD6D0;
__yjs_duid=1_d05d52b14af4a339210722080a668ec21614320694782; BD_HOME=1;
H_PS_PSSID=33514_33257_33273_31660_33570_26350;
BA_HECTOR=8h2001alag0lag85nk1g3hcm60q
Upgrade-Insecure-Requests: 1
Cache-Control: max-age=0
*/
//解析HTTP请求的头部信息
http_conn::HTTP_CODE http_conn::parse_headers(char* text)
{
//遇到空行,表示头部字段解析完毕
if (text[0] == '\0')
{
//如果HTTP请求有消息体,则还需要读取m_content_length字节的消息体,状态机转移到CHECK_STATE_CONTENT状态
//HTTP请求的消息体长度,默认为0
//m_content_length = 0;
if (m_content_length != 0)
{
m_check_state = CHECK_STATE_CONTENT;
return NO_REQUEST;
}
//否则说明我们已经得到了一个完整的HTTP请求
return GET_REQUEST;
}
//处理Connection头部字段
//Connection: keep-alive
else if (strncasecmp(text, "Connection:", 11) == 0)
{
text += 11;
text += strspn(text, " \t");
if (strcasecmp(text, "keep-alive") == 0)
{
//如果是长连接,则将linger标志设置为true
m_linger = true;
}
}
//处理Content-Length头部字段(解析请求头部内容长度字段)
else if (strncasecmp(text, "Content-Length", 15) == 0)
{
text += 15;
text += strspn(text, "\t");
m_content_lengtg = atol(text); //把字符串转换成长整型数
}
//解析Host头部字段
else if (strncasecmp(text, "Host", 5) == 0)
{
text += 5;
text += strspn(text, "\t");
m_host = text;//主机名
}
else
{
printf("oop!unknow headr:%s\n", text);
}
return NO_REQUEST:
}
//我们没有真正解析HTTP请求的消息体,只是判断它是否被完整读入了
http_conn::HTTP_CODE http_conn::parse_content(char* text)
{
if (m_read_idx >= (m_content_length + m_checked_idx))
{
text[m_content_length] = '\0';
return GET_REQUEST;
}
return NO_REQUEST;
}
//m_start_line当前正在解析的行的起始位置,将该位置后面的数据赋给text
//此时从状态机已提前将一行的末尾字符\r\n变为\0\0,所以text可以直接取出完整的行进行解析
char* get_line()
{
return m_read_buf + m_start_line;
}
//主状态机,解析请求
http_conn::HTTP_CODE http_conn::process_read()
{
//初始化从状态机状态、HTTP请求解析结果
LINE_STATUS line_status = LINE_OK;
HTTP_CODE ret = NO_REQUEST;
char* text = 0;
//parse_line为从状态机的具体实现
while (((m_check_state == CHECK_STATE_CONTENT) && (line_status == LINE_OK)) || ((line_status == parse_line()) == LINE_OK))
{
text = get_line();
//m_start_line是每一个数据行在m_read_buf中的起始位置
// m_checked_idx表示从状态机在m_read_buf中读取的位置
m_start_line = m_checked_idx;
printf("got 1 http line:%s\n", text);
//主状态机的三种状态转移逻辑
switch (m_check_idx)
{
case:CHECK_STATE_REQUESTLINE:
{
//解析请求行
ret = parse_request_line(text);
if (ret == BAD_REQUEST)
{
return BAD_REQUEST;
}
break;
}
case:CHECK_STATE_HEADER:
{
//解析请求头
ret = parse_headers(text);
if (ret == BAD_REQUEST)
{
return BAD_REQUEST;
}
else if (ret == GET_REQUEST)
{
return do_request();
}
break;
}
case:CHECK_STATE_CONTENT:
{
//解析消息体
ret = parse_content(text);
//完整解析POST请求后,跳转到报文响应函数
if (ret == GET_REQUEST)
{
return do_request();
}
//解析完消息体即完成报文解析,避免再次进入循环,更新line_status
line_status = LINE_OPEN;
break;
}
default:
{
return INTERNAL_ERROR;
}
}
}
return NO_REQUSET;
}
/*
当得到一个完整、正确的HTTP请求时,我们就分析目标文件的属性。如果
目标文件存在,对所有用户可读,且不是目录,则使用mmap将其映射到内存地
址m_file_address处,并告诉调用者获取文件成功
*/
//doc_root = "/var/www/html";
//struct stat m_file_stat。目标文件的状态。通过它我们可以判断文件是否存在、是否为目录、是否可读,并获取文件大小等信息
http_conn::HTTP_CODE http_conn::do_request()
{
//初始化的m_real_file赋值为网站根目录
strcpy(m_real_file, doc_root);
int len = strlen(doc_root);
strncp(m_real_file + len, m_url, FILENAME_LEN - len - 1);
// 获取m_real_file文件的相关的状态信息,-1失败,0成功
if (stat(m_real_file, &m_file_stat) < 0)
{
return NO_RESOURCE;
}
// 判断访问权限
if (!(m_file_stat.st_mode&S_IROTH))
{
return FORBIDDEN_REQUEST;
}
// 判断是否是目录
if (S_ISDIR(m_file_stat.st_mode))
{
return BAD_REQUEST;
}
//以只读的方式打开
int fd = open(m_real_file, O_RDONLY);
// 客户请求的目标文件被mmap到内存中的起始位置
m_file_address = (char*)mmap(0, m_file_stat.st_size, PROT_READ, MAP_PRIVATE, fd, 0);
close(fd);
return FILE_REQUEST;
}
//对内存映射区执行munmap操作
void http_conn::unmap()
{
if (m_file_address)
{
munmap(m_file_address, m_file_stat.st.size);
m_file_address = 0;
}
}
//写HTTP响应事件
bool http_conn::write()
{
int temp = 0;
//已经发送的字节
int bytes_have_send = 0;
//将要发送的字节(m_write_idx)写缓冲区中待发送的字节数
int bytes_to_send = m_write_idx;
if (bytes_to_send == 0)
{
//将要发送的字节为0,这一次响应结束
modfd(m_epollfd, m_sockfd, EPOLLIN);
init();
return true;
}
while (1)
{
//分散写
temp = writev(m_sockfd, m_iv, m_iv_count);
if (temp <= -1)
{
/*
如果TCP写缓冲区没有空间,则等待下一轮EPOLLOUT事件。
虽然在此期间,服务器无法立即接收到同一客户的下一个
请求,但这可以保证连接的完整性
*/
if (errno == EAGAIN)
{
modfd(m_epollfd, m_sockfd, EPOLLOUT);
return true;
}
unmap();
return false;
}
bytes_to_send -= temp;
bytes_have_send += temp;
if (bytes_to_send <= bytes_have_send)
{
//发送HTTP响应成功,根据HTTP请求中的Connection字段决定是否立即关闭连接
unmap();
if (m_linger)
{
init();
modfd(m_epollfd, m_sockfd, EPOLLIN);
return true;
}
else
{
modfd(m_epollfd, m_sockfd, EPOLLIN);
return false;
}
}
}
}
//往写缓冲区中写入带发送的数据
bool http_conn::add_response(const char* format, ...)
{
if (m_write_idx >= WRITE_BUFFER_SIZE)
{
return false;
}
//定义可变参数列表
va_list arg_list;
//将变量arg_list初始化为传入参数
va_start(arg_list, format);
int len = vsnprintf(m_write_buf + m_write_idx, WRITE_BUFFER_SIZE - 1 - m_write_idx, format, arg_list);
if (len >= (WRITE_BUFFER_SIZE - 1 - m_write_idx))
{
return false;
}
m_write_idx += len;
va_end(arg_list);
return true;
}
//添加状态行
bool http_conn::add_status_line(int status, const char* title)
{
return add_response("%s %d %s\r\n", "HTTP/1.1", status, title);
}
//添加消息报头,具体的添加文本长度、连接状态和空
bool http_conn::add_headers(int content_len)
{
add_content_length(content_len);
add_linger();
add_blank_line();
}
//添加Content_Length,表示响应报文长度
bool http_conn::add_content_length(int content_len) {
return add_response("Content-Length: %d\r\n", content_len);
}
//添加连接状态,通知浏览器端是保持连接还是关闭
bool http_conn::add_linger()
{
return add_response("Connection: %s\r\n", (m_linger == true) ? "keep-alive" : "close");
}
//添加空行
bool http_conn::add_blank_line()
{
return add_response("%s", "\r\n");
}
//添加文本content
bool http_conn::add_content(const char* content)
{
return add_response("%s", content);
}
//添加文本类型,这里是html
bool http_conn::add_content_type() {
return add_response("Content-Type:%s\r\n", "text/html");
}
//根据服务器处理HTTP请求的结果,决定返回给客户端的内容
bool http_conn::process_write(HTTPCODE ret)
{
switch (ret)
{
//内部错误,500
case INTERNAL_ERROR:
{
//状态行
add_status_line(500, error_500, title);
//消息头
add_headers(strlen(error_500_form));
if (!add_content(error_500_form))
{
return false;
}
break;
}
case BAD_REQUEST:
{
//报文语法有误,404
add_status_line(404, error_404_title);
add_headers(strlen(error_404_form));
if (!add_content(error_404_form))
return false;
break;
}
case NO_REQUEST:
{
//请求报文中存在语法错误
add_status_line(400,error_400_title);
add_headers(strlen(error_400_form));
if (!add_content(error_400_form))
return false;
break
}
case FORBIDDEN_REQUEST:
{
//资源没有访问权限,403
add_status_line(403, error_403_title);
add_headers(strlen(error_403_form));
if (!add_content(error_403_form))
return false;
break;
}
case FILE_REQUEST:
{
// 我们将采用writev来执行写操作,所以定义下面两个成员,其中m_iv_count表示被写内存块的数量
//文件存在,200
add_status_line(200, ok_200_title);
//如果请求的资源存在
if (m_file_stat.st.size1 = 0)
{
add_headers(m_file_stat.st_size);
//第一个iovec指针应当指向响应报文缓冲区,长度指向m_write_idx;
m_iv[0].iov_base = m_write_buf;
m_iv[0].iov_len = m_write_idx;
//第二个iovec指针应当指向mmap返回的文件指针,长度指向文件大小
m_iv[1].iov_base = m_file_address;
m_iv[1].iov_len = m_file_stat.st_size;
m_iv_count = 2;
return true;
}
else
{
//如果请求的资源大小为0,则返回空白的html文件
const char* ok_string = "";
add_headers(strlen(ok_string));
if (!add_content(ok_string))
{
return false;
}
}
}
default:
{
return false;
}
}
//除FILE_REQUEST状态外,其余状态只申请一个iovec,指向响应报文缓冲区
m_iv[0].iov_base = m_write_buf;
m_iv[0].iov_len = m_write_idx;
m_iv_count = 1;
return true;
}
//由线程池中的工作线程调用,这时处理HTTP请求的入口函数
void http_conn::process()
{
HTTP_CODE read_ret = process_read();//主状态机,解析请求
if (read_ret == NO_REQUEST)
{
modfd(m_epollfd,m_sockfd,EPOLLIN);
return;
}
bool write_ret = process_write(read_ret);//根据服务器处理HTTP请求的结果,决定返回给客户端的内容
if (!write_ret)
{
close_conn();
}
modfd(m_epollfd,m_sockfd,EPOLLOUT);
} 从状态机负责读取报文的一行,主状态机负责对该行数据进行解析,主状态机内部调用从状态机,从状态机驱动主状态机。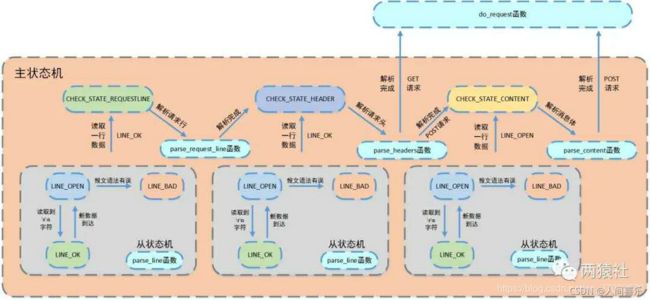
这就是实现http_conn类的代码。通过代码我们可以发现,我们从客户端接收到请求,然后解析客户端的请求,解析请求主要是通过主从状态机来进行推动的。我们在主状态机内部调用从状态机,一步一步的了解客户端的需求。
7.main函数
#include
#include"locker"
#include"threadpool.h"
using namespace std;
//最大文件描述符个数
#define MAX_FD 65536
//监听的最大事件数量
#define MAX_EVENT_NUMBER 10000
//添加文件描述符
extern int addfd(int epollfd, int fd, bool one_shot);
//移除文件描述符
extern int removefd(int epollfd,int fd);
void addsig(int sig, void (handler)(int), bool restart = true)
{
struct sigaction sa;
memset(&sa,'\0',sizeof(sa));
sa.sa_handler = handler;
sigfillset(&sa.sa_mask);
assert(sigaction(sig,&sa,NULL)!=-1);
}
void sho_error(int connfd,const char* info)
{
printf("%s",info);
send(connfd,info,strlen(info),0);
close(connfd);
}
int main(int argc,char* argv[])
{
if (argv <= 2)
{
printf("usage:%s ip_address port_number\n",basename(argv[0]));
return 1;
}
//获得ip地址和port端口号
const char* ip = argv[1];
int port = atoi(argv[2]);
//忽略SIGPIPE信号
addsig(SIGPIPE,SIG_IGN);
//创建线程池
threadpool*pool=NULL;
try {
pool = new threadpool ;
}
catch (...)
{
return 1;
}
//预先为每个可能的客户链接分配一个http_conn对象
http_conn* users = new http_conn[MAX_FD];
int listenfd = socket(PF_INET,SOCK_STREAM,0);
assert(listenfd>=0);
struct linger tmp = { 1,0 };
setsockopt(listenfd,SOL_SOCKET,SO_LINGER,&tmp,sizeof(tmp));
int ret = 0;
struct sockaddr_in address;
bzero(&address,sizeof(address));
address.sin_family = AF_INET;
inet_pton(AF_INET,ip,&address.sin_addr);
address.sin_port = htons(port);
ret = bind(listenfd,(struct sockaddr*)&address,sizeof(address));
assert(ret>=0);
//创建epoll对象和事件数组
epoll_event events[MAX_EVENT_NUMBER];
int epollfd = epoll_event(5);
//添加到epoll对象中
assert(epollfd!=-1);
addfd(epollfd,listenfd,false);
http_conn::m_epollfd = epollfd;
while (true)
{
int number = epoll_wait(epollfd,events,MAX_EVENT_NUMBER,-1);
if ((number < 0) && (errno != EINTR))
{
printf("epoll failure\n");
break;
}
for (int i = 0; i < number; ++i)
{
int sockfd = events[i].data.fd;
if (sockfd == listenfd)
{
struct sockaddr_in client_address;
socklen_t client_addrlength = sizeof(client_address);
int connfd = accept(listenfd,(struct sockaddr*)&client_address,&cilent_addrlength);
if (connfd < 0)
{
printf("errno is:%d\n",errno);
continue;
}
if (http_conn::m_user_count >= MAX_FD)
{
show_error(connfd,"Internal server busy");
continue;
}
//初始化客户连接
users[connfd].init(connfd,client_address);
}
else if (events[i].events&(EPOLLRDHUP | EPOLLHUP | EPOLLERR))
{
//如果有异常,直接关闭客户连接
users[sockfd].close_conn();
}
else if (events[i].events&EPOLLIN)
{
//根据读的结果,决定是否将任务添加到线程池,还是关闭连接
if (users[sockfd].read())
{
pool->append(users+sockfd);
}
else
{
users[sockfd].close_conn();
}
}
else if (events[i].events&EPOLLOUT)
{
//根据写的结果,决定是否关闭连接
if (!users[sockfd].write())
{
uses[sockfd].close_conn();
}
}
else
{ }
}
}
close(epollfd);
close(listenfd);
delete[]users;
delete pool;
return 0;
}